目录
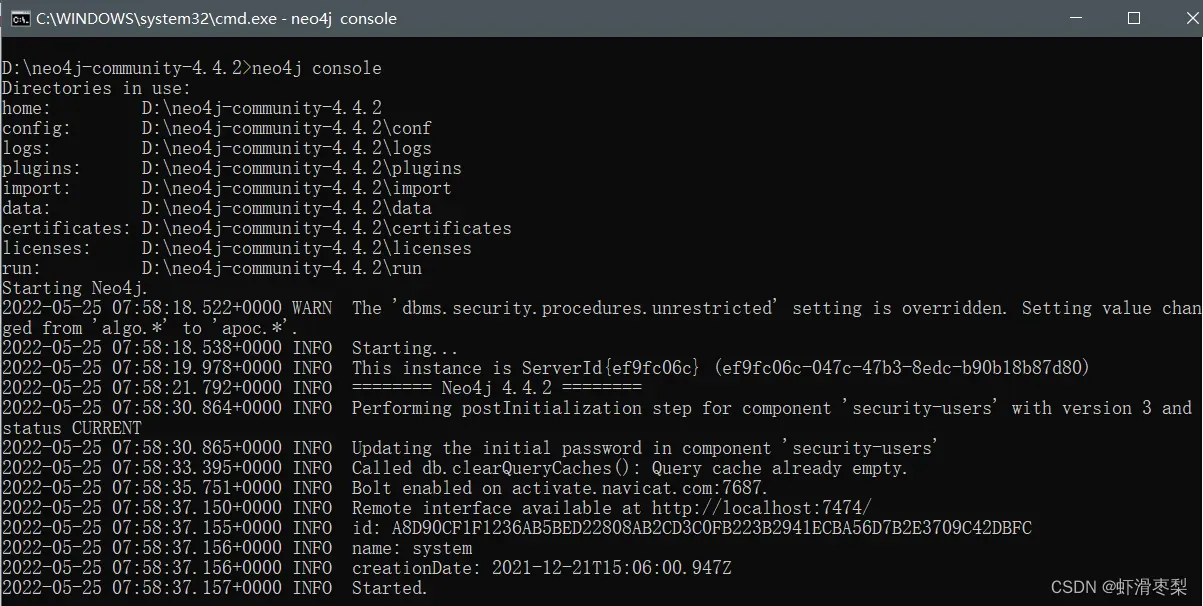
Ps:在使用Neo4j前,需要先在该安装路径文件下cmd运行,输入neo4j console 即可启动,可根据关闭时输入neo4j stop,如下图所示说明已成功启动,此时可打开 http://localhost:7474/进入Neo4j图数据库。
一、需要两组数据
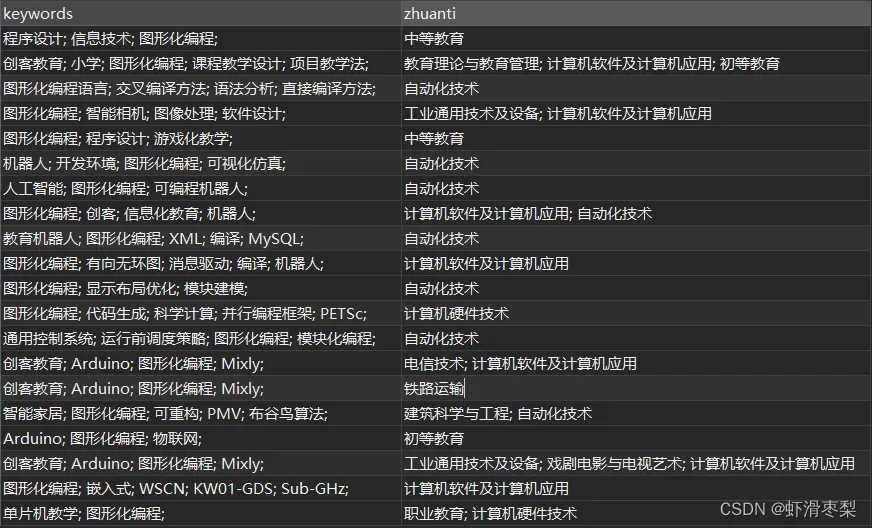
如下图所示,我们需要筛选出关键字中包含有“图形化编程”的专题数据,并以此构建“图形化编程”与各专题之间的关系。下图以20条数据为例(本文使用的数据库为Mysql数据库):
二、提取所需专题数据
利用SQL语句提取所需专题数据,即“图形化编程”存在于keywords中的对应专题数据(本文举的例子中,keywords中皆有“图形化编程”,可以不用使用以下模糊语句;该语句适用于关键词中没有我们需要的,即相应专题也不需要,因此可以过滤掉,提高数据准确性)。SQL模糊查询语句的代码如下:
# 使用的是数据库引擎连接数据库,需导入"from sqlalchemy import create_engine",my_date是数据库名
con = create_engine('mysql+pymysql://root:密码@localhost:3306/my_date charset=utf8')
# 获取test表专题字段,使用pandas库中的数据库查询方法
text = pd.read_sql_query(sql="SELECT distinct zhuanti FROM test where zhuanti is not null and keywords like '%%%%%s%%%%'" % '图形化编程', con=con)三、利用结巴分词将专题数据分词
由于本文举的例子中,有些专题不止只有一个词汇,同时也有部分数据是存在相同专题的情况,因此需要使用结巴分词进行数据分词。例如最后一行的【职业教育;计算机硬件技术】利用结巴分词提取为【职业教育】、【计算机硬件应用】两个词汇。步骤如下:
# 导入自定义的专题分词词典
data = str(text) # 需将读取的文档dataframe格式转为str
jieba.load_userdict('专题词典.txt')
# 去除摘要中的空格、换行等不必要的数据
data = data.replace(';', '')
data = data.replace('\n', '')
data = data.replace(' ', '')
data = data.replace(',', '')
# 结巴分词中的精确模式进行分词
seg_list = jieba.lcut(data)
# 导入自定义的停用词词典
with open('stopwords.txt', 'r+', encoding='utf-8')as fp:
stopwords = fp.read().split('\n')
# 存储过滤停用词后的分词结果
word_list = []
# 如果切出的词不是停用词,则存入列表
for seg in seg_list:
if seg not in stopwords:
word_list.append(seg)
其中自定义的专题分词是为了防止出现,例如【计算机硬件技术】被划分为【计算机】【硬件】【技术】等情况,不满足我们的需求,因此自定义专题分词词典能够提取我们所需的词汇。本文的专题词典【专题词典.text】如下所示:
中等教育
教育理论与教育管理
初等教育
计算机软件及计算机应用
自动化技术
工业通用技术及设备
计算机硬件技术
电信技术
铁路运输
建筑科学与工程
戏剧电影与电视艺术
职业教育
其中自定义的停用词词典是为了过滤一些例如数字、符号等不需要的数据。本文的停用词词典【stopwords.text】如下所示:
;
1
2
3
4
5
6
7
8
9
10
11
12
zhuanti0最终过滤出的分词结果【word_list】如下所示:
['中等教育', '教育理论与教育管理', '计算机软件及计算机应用', '初等教育', '自动化技术', '工业通用技术及设备', '计算机软件及计算机应用', '计算机软件及计算机应用', '自动化技术', '计算机软件及计算机应用', '计算机硬件技术', '电信技术', '计算机软件及计算机应用', '铁路运输', '建筑科学与工程', '自动化技术', '初等教育', '工业通用技术及设备', '戏剧电影与电视艺术', '计算机软件及计算机应用', '职业教育', '计算机硬件技术']PS:突然发现该方法其实不是很必要,就是其实我们上述最终过滤出的数据,结合后面消除重复节点,得到的就是我们定义的专题词典,所以可以针对自己的数据情况酌情使用,这里也是展示一下如何进行结巴分词提取所需数据。
四、连接并绘制知识图谱
分词后便得到了我们绘制图谱的数据,连接Neo4j图数据库,以“图形化编程”为中心节点,将之前分词并清洗后的数据【word_list】用for循环逐个添加,创建节点和关系,并为节点添加属性,最后实例化。打开网址便能看到绘制好的图谱。
# 连接Neo4j
graph = Graph("http://localhost:7474", auth=("neo4j", "密码"))
graph.delete_all() # 清除neo4j中原有的结点
# 创建节点
for i in range(1,len(word_list)):
node = Node('title',name="图形化编程")
relation = Node('zhuanti',name=word_list[i])
graph.create(node)
graph.create(relation)
# 给节点添加属性(两者间的关系)
zhuanti = Relationship(node, '应用于', relation)
# 节点实例化,并显示在neo4j中
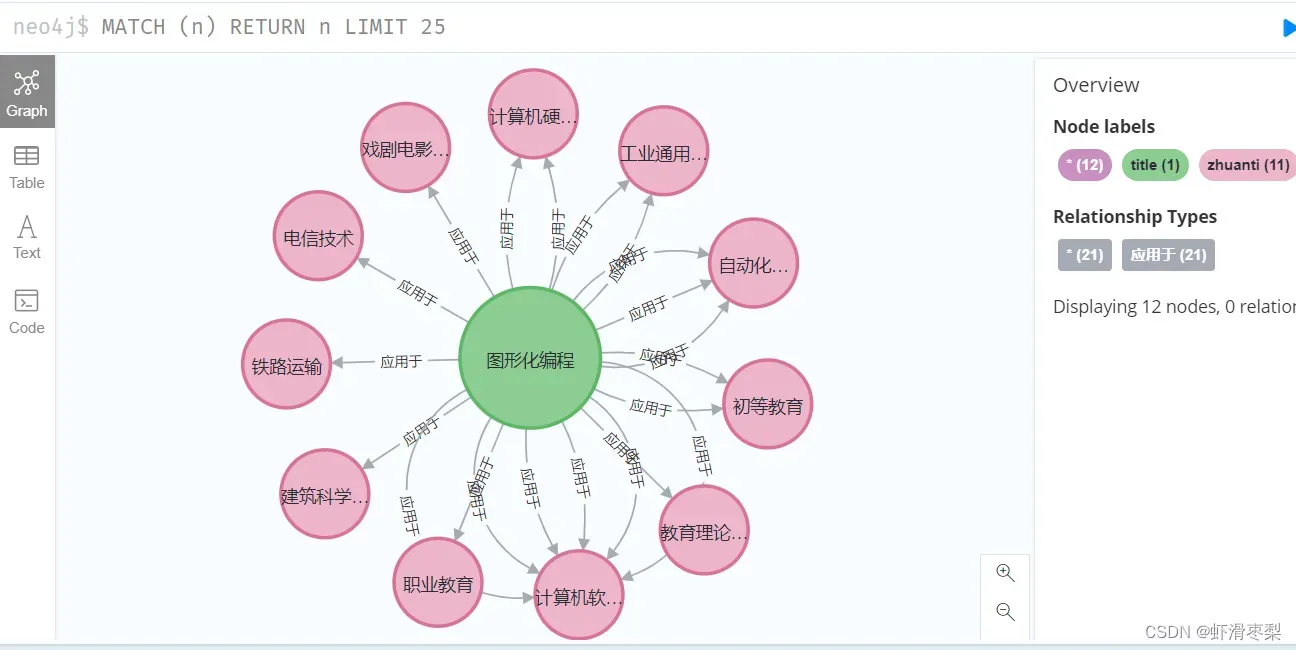
graph.create(zhuanti)打开网址,此时绘制的图谱如下图所示:

但由图可以发现,图谱显示的是构建每个“图形化编程”与各专题节点关系,联系分散了,不是我们想要的只有一个父节点“图形化编程”,拥有多个专题子节点的关系。因此我们需要消除重复节点。
五、消除重复节点及重复关系
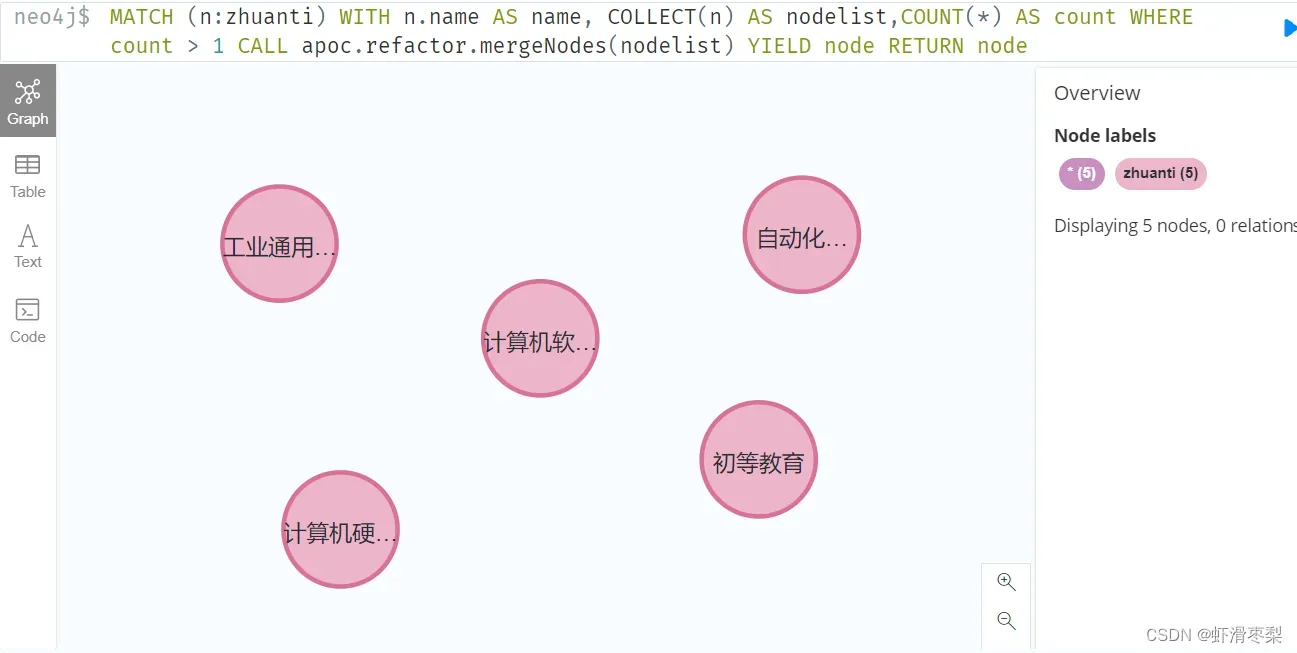
1.消除重复节点:在Neo4j上输入以下语句(注意:不是写在python的代码中,是网址的运行框)
# 删除专题重复的节点
graph.run('MATCH (n:zhuanti) WITH n.name AS name, COLLECT(n) AS nodelist, COUNT(*) AS count WHERE count > 1 CALL apoc.refactor.mergeNodes(nodelist) YIELD node RETURN node')
# 删除“图形化编程”重复的节点
graph.run('MATCH (n:title) WITH n.name AS name, COLLECT(n) AS nodelist, COUNT(*) AS count WHERE count > 1 CALL apoc.refactor.mergeNodes(nodelist) YIELD node RETURN node') 消除专题重复节点,运行结果如下图所示:
消除“图形化编程”重复节点,运行结果如下图所示:

此时绘制的图谱如下图所示:
2.消除重复关系:如上图所示图谱中出现了许多重复关系,因此需要消除。同理在Neo4j上输入以下语句
# 删除重复关系
graph.run('MATCH (a)-[r:应用于]- >(b) WITH a,b,TAIL (COLLECT(r)) as rr WHERE size(rr)>0 FOREACH (r IN rr | DELETE r)')六、结果展示
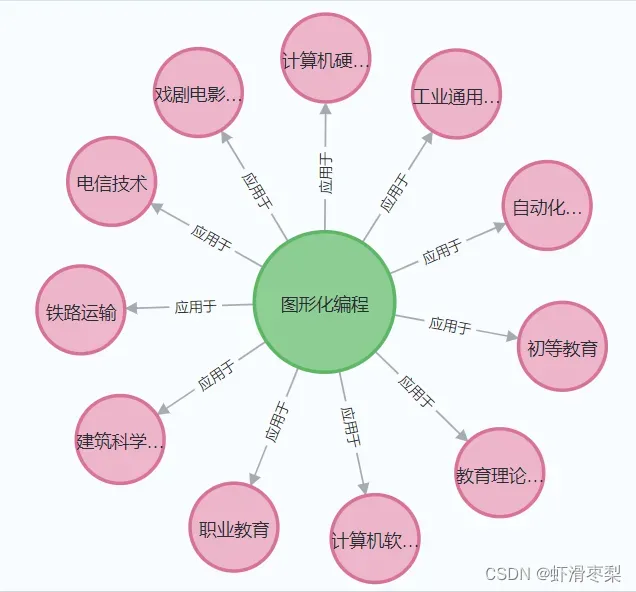
文章出处登录后可见!