文献:Liu R , Piplani R , Toro C . Deep reinforcement learning for dynamic scheduling of a flexible job shop[J].(2022)
https://doi.org/10.1080/00207543.2022.2058432![]() https://doi.org/10.1080/00207543.2022.2058432
https://doi.org/10.1080/00207543.2022.2058432
杂志:International Journal of Production Research
1.Introduction
制造系统的动态事件;实时数据采集与分析;个性化生产
贡献:分布式和分层级的DRL方法求解最小化拖期的DFJSP(作业持续到达)
2.Literature review
Traditional approaches
(1)优先规则:no single priority rule provides strictly stronger performance along all objectives in all scenarios;composite priority rules’ performance is usually better than their building blocks
(2)元启发式:objectives such as flow time, makespan and tardiness, robustness;hybrid approaches to reduce the decisional latency of meta-heuristics
Recent data-driven approaches
(1)传统方法面临效率和质量矛盾的困境;优先规则效率高质量差;元启发式质量好效率低
(2)使用Genetic Programming (GP)创建复合调度规则,充分考虑决策点的实时信息;对于FJSP问题,GP分别给出机器选择和作业顺序的规则
(3)监督学习与元启发式算法的结合,如ML学习参数
Reinforcement learning-based scheduling
(1)表格型RL
(2)DRL
3.Problem formulation
3.1Notations
本文不考虑机器组装时间
SA作业顺序
RA选择机器
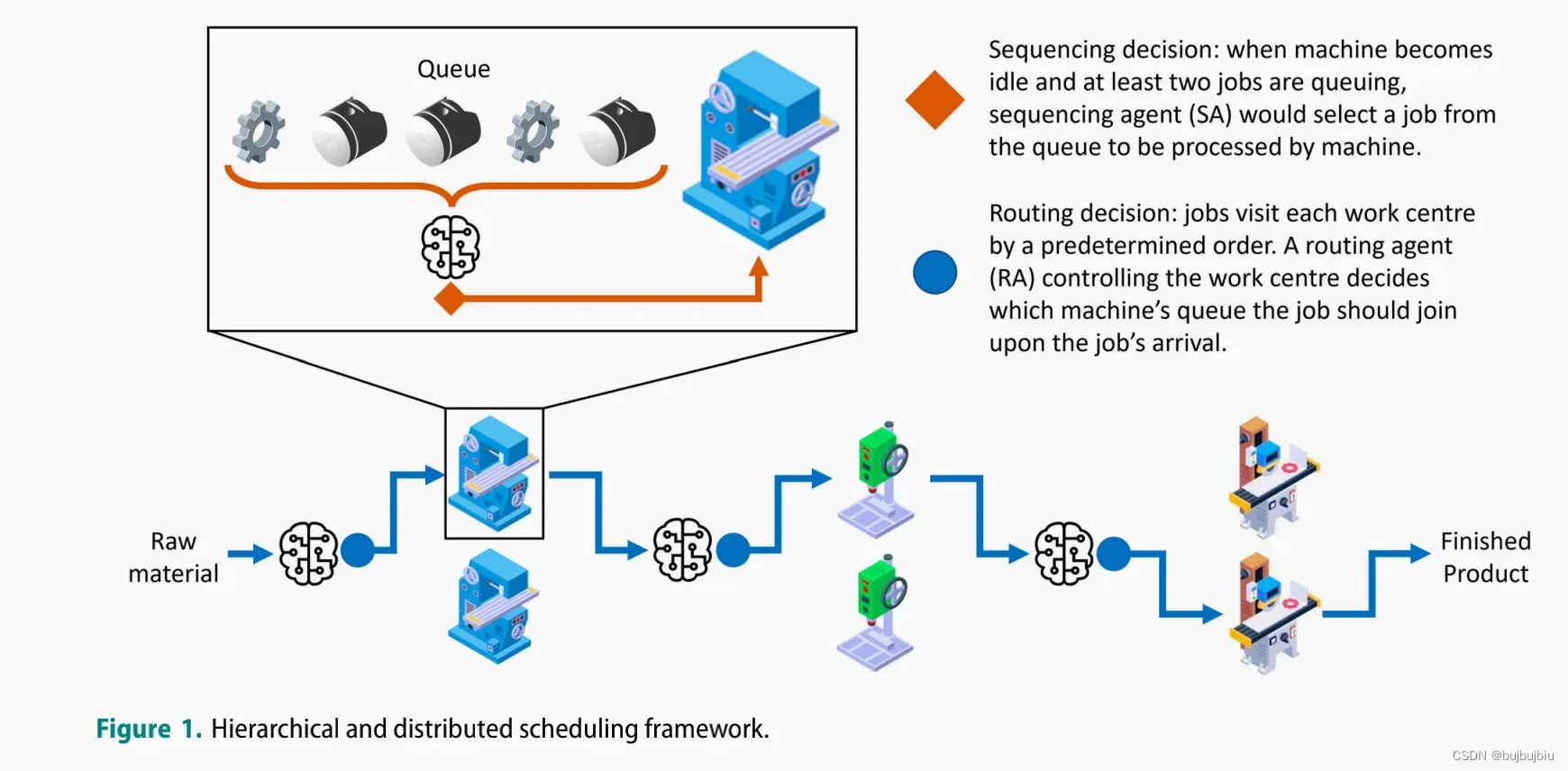
- 作业(Jobs):
n个作业
- 机器(Machines):
w个工作中心,每个工作中心有多台机器
- 序列和操作(Sequence and operations):作业
有

- 加工时间(Processing time):
是作业
上的加工时间,
是操作
的平均加工时间。
是作业
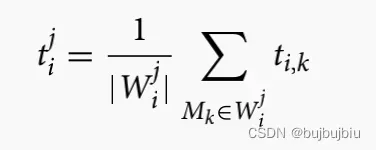
- 机器队列和可用时间(Queue and available time of machine)

- TTD,剩余加工时间和松弛时间(Time-till-due (TTD), remaining processing time and slack time)

- 性能指标(Measurement of performance)

3.2Validation scenario and objective
有三个因素影响生产性能:(1)作业到达率:较高的到达率导致更高的机器利用率和更高
系统拥塞(2)作业和机器的不同步:作业因在不同的机器上的处理时间和本身的交货紧急程度而不同,此外,一旦开始生成,作业的剩余操作、空闲时间和TTD都会随时间变化。机器的负载率和可用性也会变化(3)交货紧急度:宽松作业的TTD会导致较低的总延迟和平均延迟,因为作业有更多的空闲时间(平均)来缓解拥堵的负面影响。此外,如果系统中的作业紧急性变化,调度中心也能利用松弛时间调整顺序来保护更关键的作业。
本文设置三个训练和验证的场景:
- 预期到达率和利用率(Expected arrival rate/ utilisation rate):调整作业到达率使其匹配系统的预期利用率。
是所有机器上的所有操作的预期加工时间。
作业预期到达的时间间隔。假设m台机器均匀分布在w个工作中心上,系统的预期使用率为:
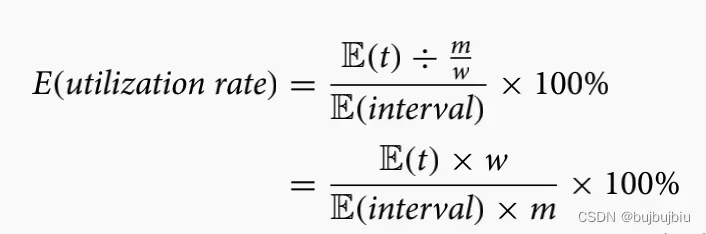
假设随机变量X为作业到达时间间隔,服从泊松分布
- 加工时间异质性(Heterogeneity of processing time):作业在机器上的加工时间服从均匀分布,U[low,high],本文考虑两种情况(1)高异质性:U[5,25](2)低异质性:U[10,20]
- 交货期紧急程度(Due date tightness):比值
表示作业的交货紧急程度,本文考虑两种场景(1)高Due date tightness:
(2)低Due date tightness:
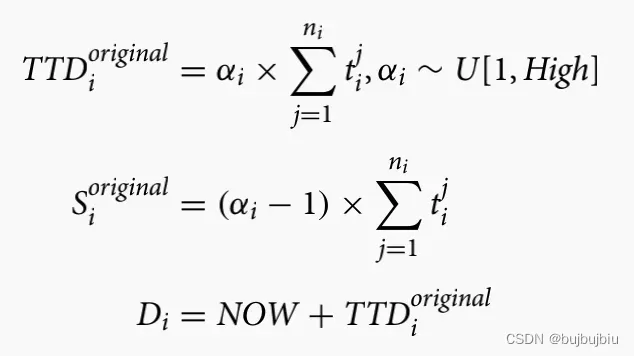
4. Proposed approach
4.1 DRL Preliminaries
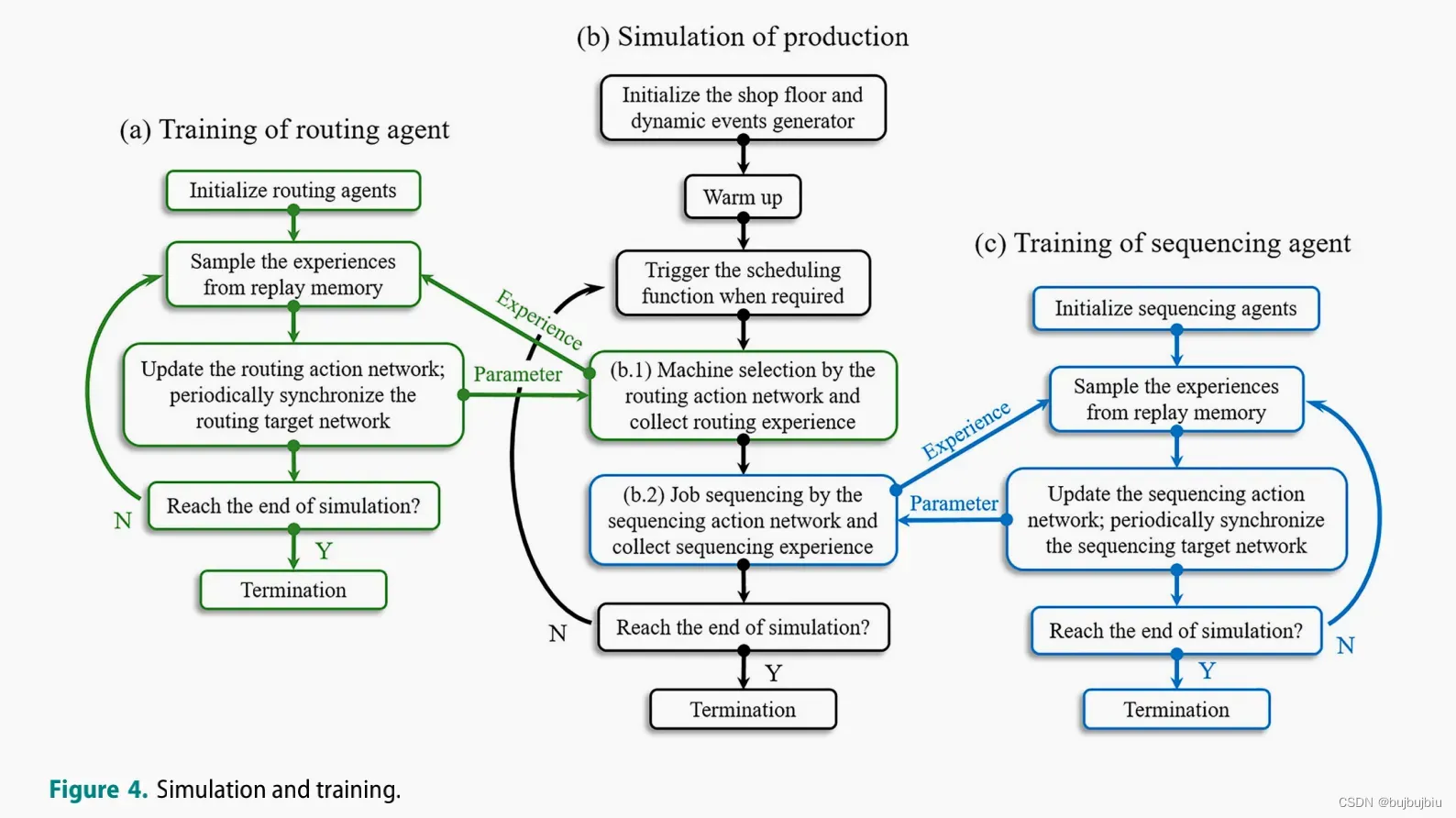
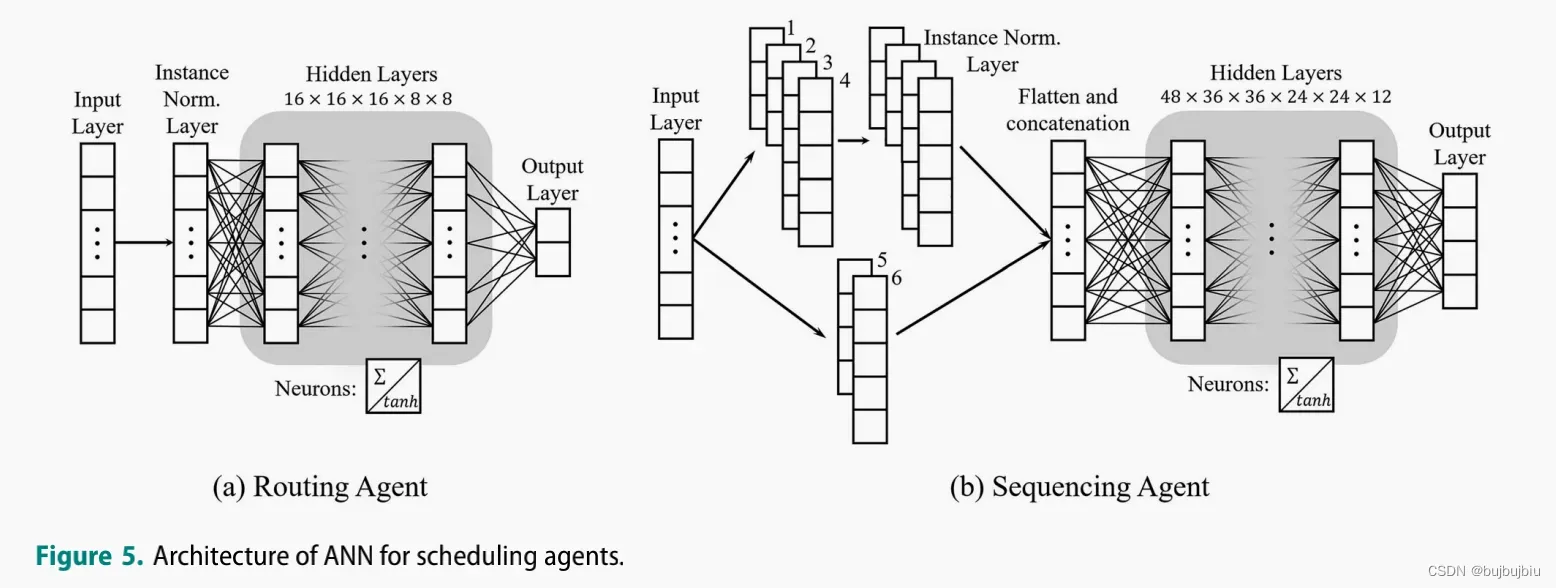
DDQN作为系统中两类智能体的学习器(1)与每个工作中心关联的RA在作业到达时会进行机器选择(2)与每台机器关联的SA会在机器怠速并且队列中有作业时选择一个作业进行加工。
4.2 State representation
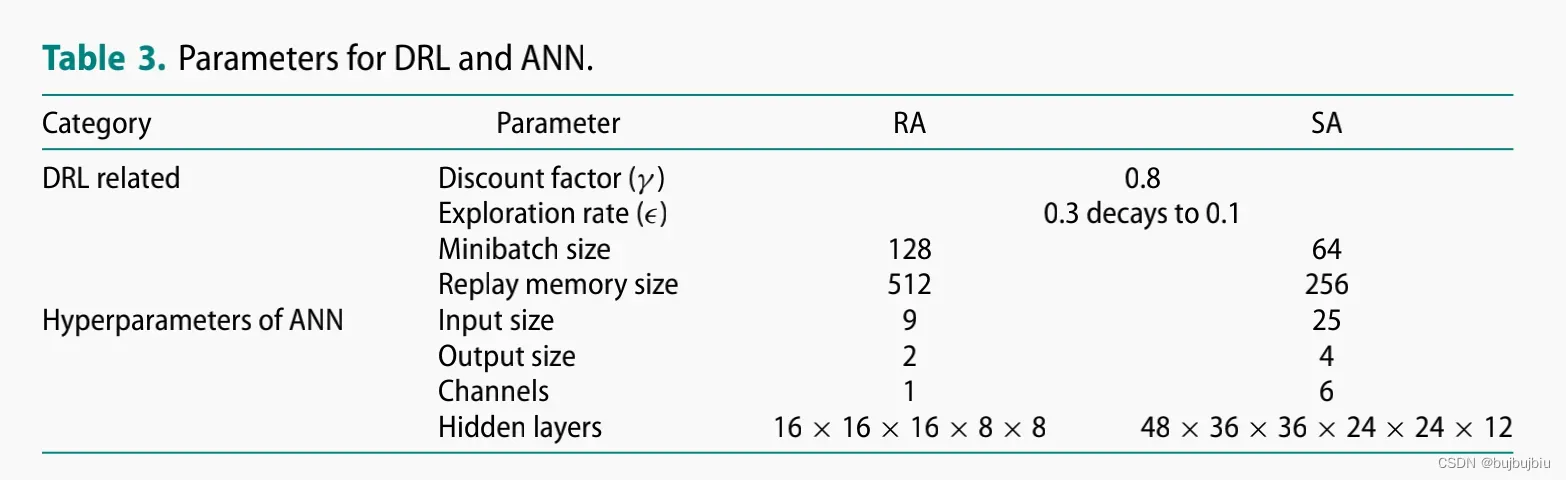
RA的状态空间包括三个:(1)工作中心内的机器信息(2)将被分配的作业信息(3)将要到达的作业信息。RA的状态空间大小为
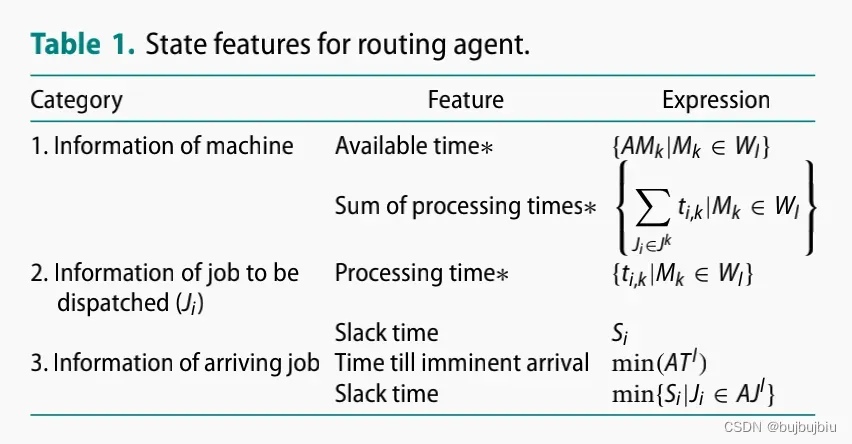
SA的状态空间:25个特征值根据类型和大小分成6个通道

4.3 Action representation
选择四个序列规则作为动作空间的构件实现间接的作业选择:
- 最短加工时间(Shortest Processing Time (SPT)):选择即将进行的操作加工时间最短的作业
- 队列工作(Work in Queue (WINQ)):选择在后续生产阶段中排队作业的总加工时间和最小的作业。WINQ倾向于平衡系统作业分布
- 关键比值(Critical Ratio (CR)):CR是TTD和剩余加工时间的比值,选择最小CR的作业,CR优势在于其不一致性。当可选作业还未延期时,CR规则会选择小TTD和更长的剩余加工时间的作业;当可选作业已经延期,CR规则会选择最小TTD和最短剩余加工时间的作业
- 最小松弛时间(Minimum Slack (MS)):选择最小松弛的作业
4.4 Surrogate reward—shaping
本文目标是最小化拖期,因此常规方法是使用作业已经实现的拖期作为联合奖励。但是多智能体存在奖励分配问题,即智能体可能会收到来自队友行为的虚假奖励信号,因此本文提出一种代理方法来奖励智能体对系统的贡献。
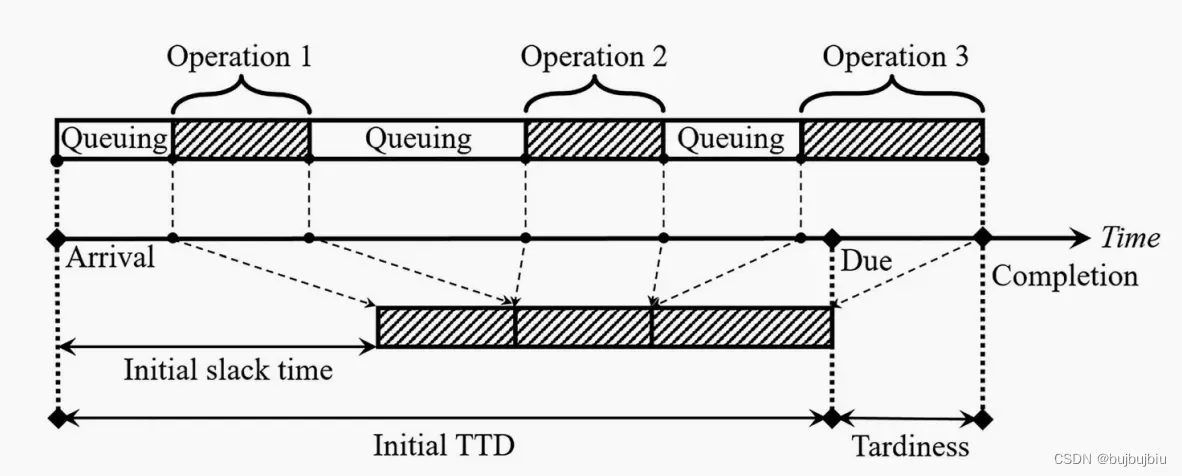
减少和预防拖期等同于保护松弛时间。本文量化作业延期的可能性,使用sigmoid函数将松弛时间变成危险因子
,
是自定义参数
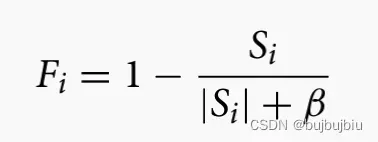
基于此考虑两种提出两种松弛时间驱动的奖励函数
4.4.1 Surrogate reward function for RA
作业到达工作中心准备加工第x个操作,
是t+1时刻估计的松弛时间,还未选择机器,因此其加工时间使用均值
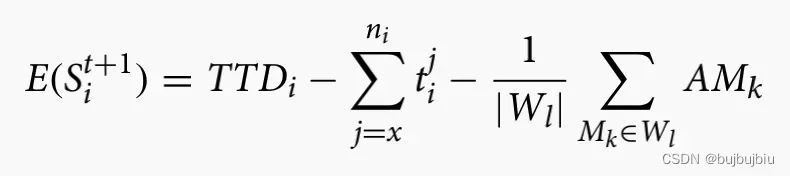
是已经选择完机器完成第x个操作的实际松弛时间
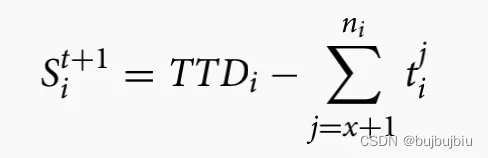
奖励设置为估计松弛时间和时间松弛时间比较差值:
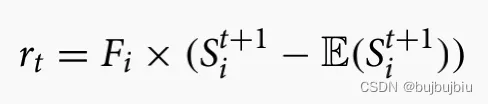
4.4.2 Surrogate reward function for SA
机器从其队列中选择作业后,队列中其它作业的等待时间会增加,
会准备加入到后续操作工作中心的队列中。将节省或延长的排队时间定义为松弛时间增减量。
对于选择的作业来说,松弛时间增减量=其它作业的平均加工时间(调整)— 后续工作中心可用时间(
调整)
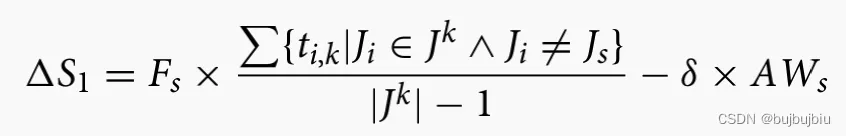
对于未选择的作业,松弛时间增减量=选择作业加工时间(均值调整)— 未选择作业后续
工作中心平均可用时间
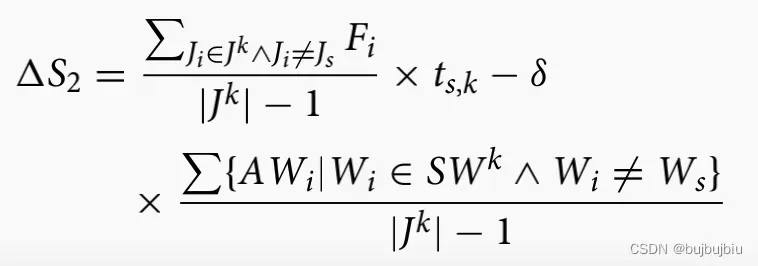
SA奖励函数如下:
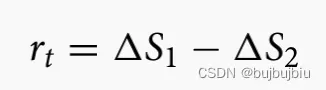
4.5 Asynchronous transition
step t+1不一定与决策点重合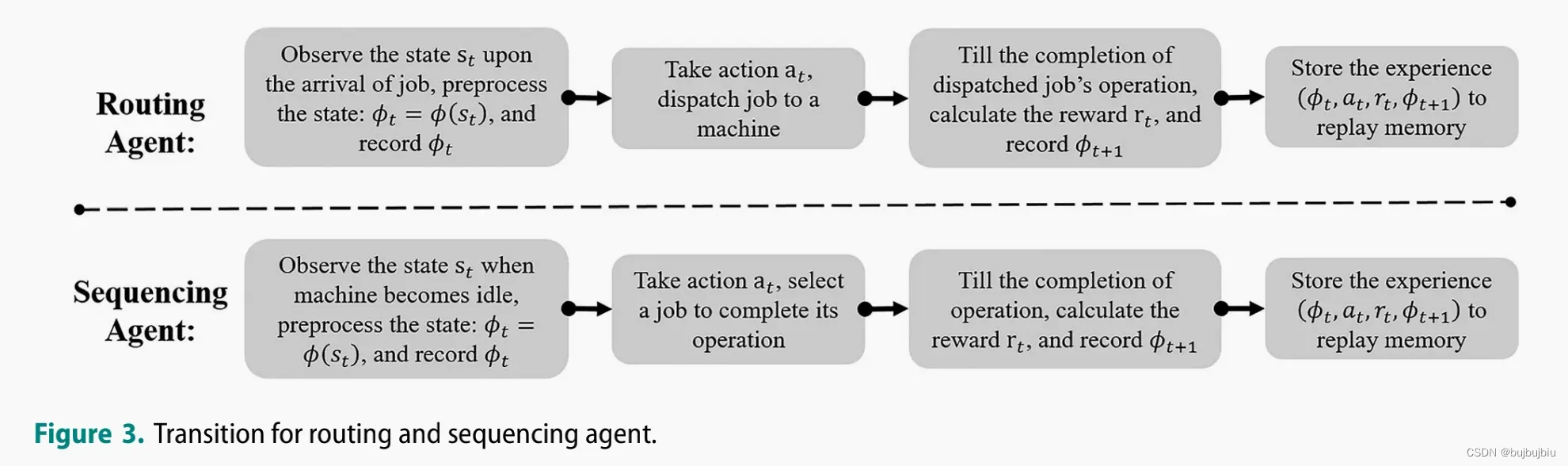
4.6 Parameters and training
仿真时长100 000个单元时间;12 400个作业到达;parameter sharing technique;Instance normalisation technique;tanh;Huber loss;学习率下降;SGD;动量0.9
5.Numerical experiments
主要包括三个部分:独立效用测试,集成DRL测试,可扩展性测试
性能指标:
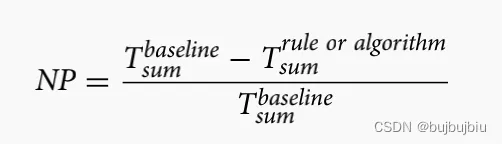
- 标准性能(Normalised performance (NP)):选择一个优先规则作为baseline,其它规则的NP计算公式如下,T是拖期:
- 成功率(Win rate):每次运行一个规则或算法有最低累计拖期的百分比,测试了调度策略在不同生产背景下的适应性
5.1Independent utility test
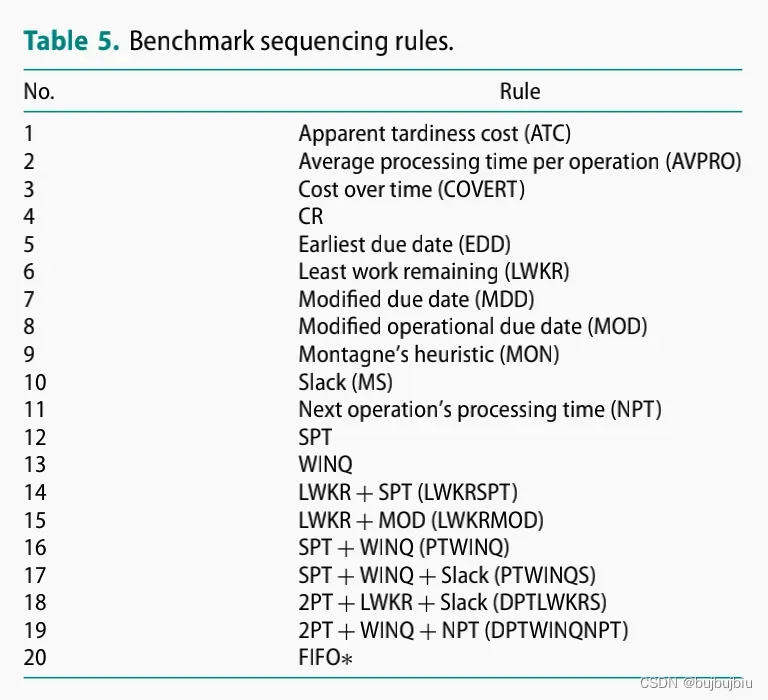
RA和SA的调度规则比较,详细结果见论文

5.2Validation of integrated DRL
选择两个表现最好的RA规则和五个表现最好的SA规则组合成10个基准测试规则,两个GP规则,两个同类研究方法,FIFO+EA作为baseline。
没有和元启发式算法比较因为其无法解决动态作业到达问题,不适用于实时调度。结果示意
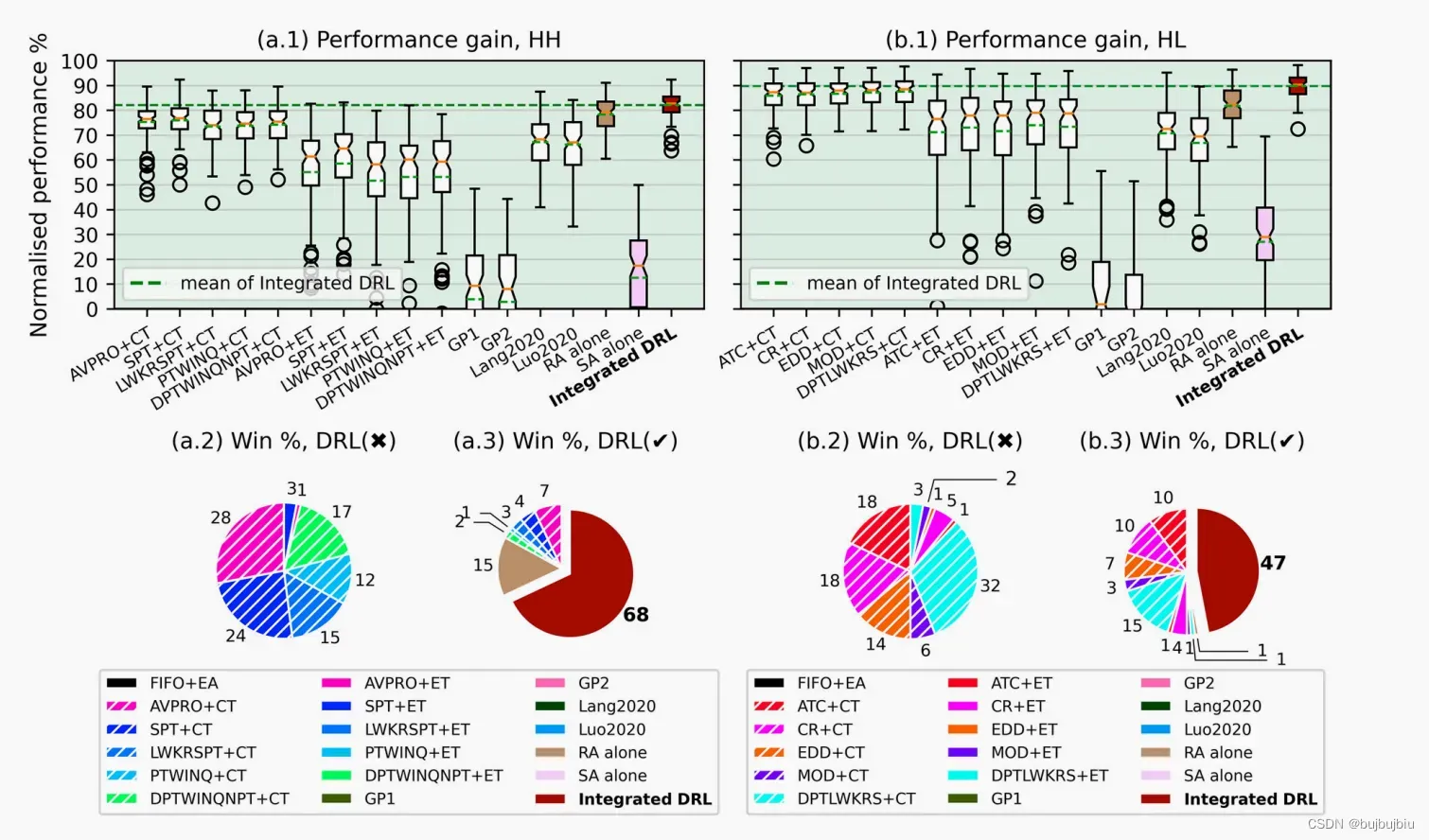
RA比SA对系统性能影响更大,集成DRL表现较好
5.3Scalability
5.3.1 higher flexibility test
比较工作中心3台机器和4台机器的CT,ET和DRL-RA规则,结果示意
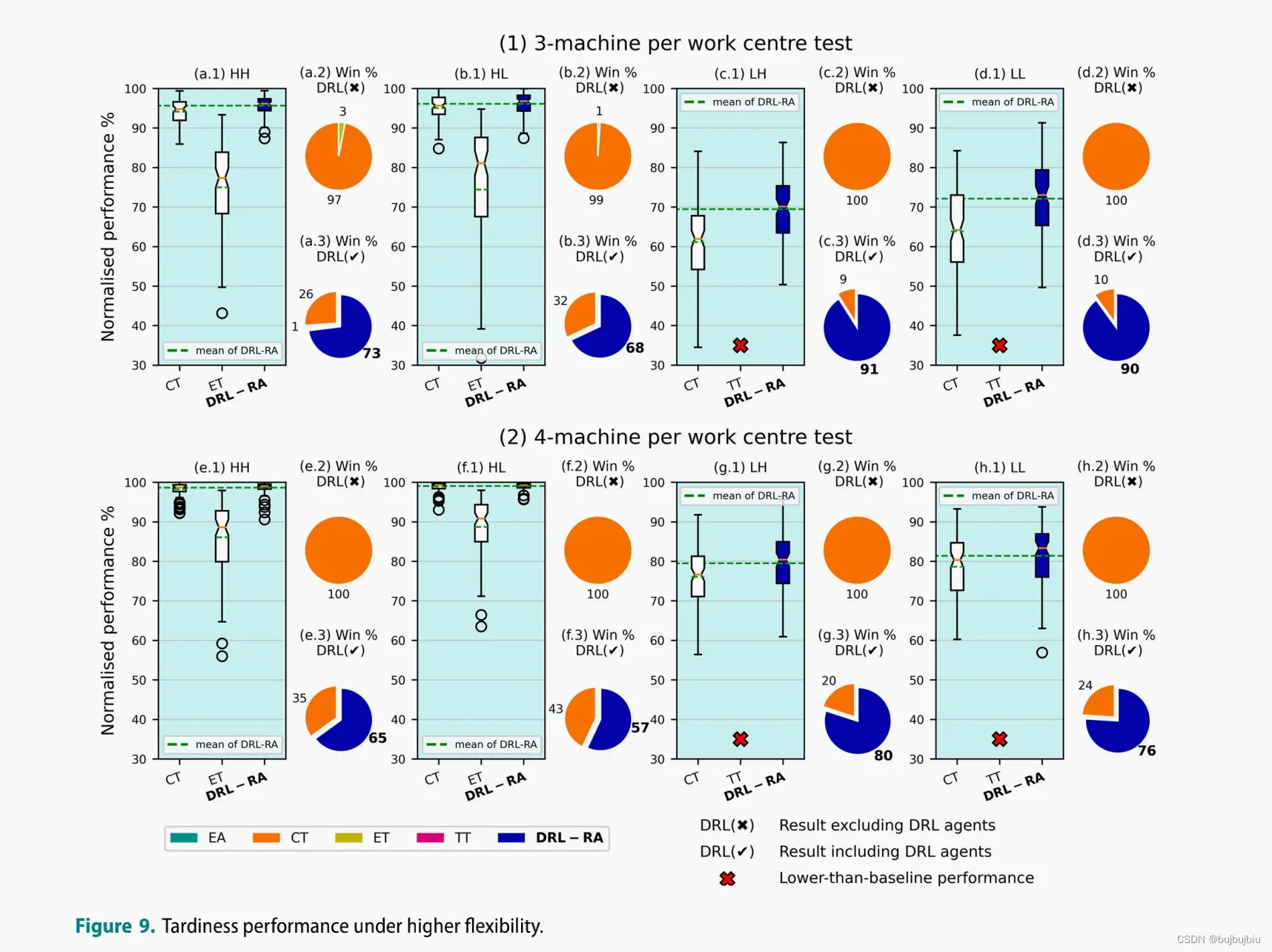
5.3.1 longer sequence test
比较作业操作数为6个和9个的性能,最好的5个优先规则,FIFO作为baseline
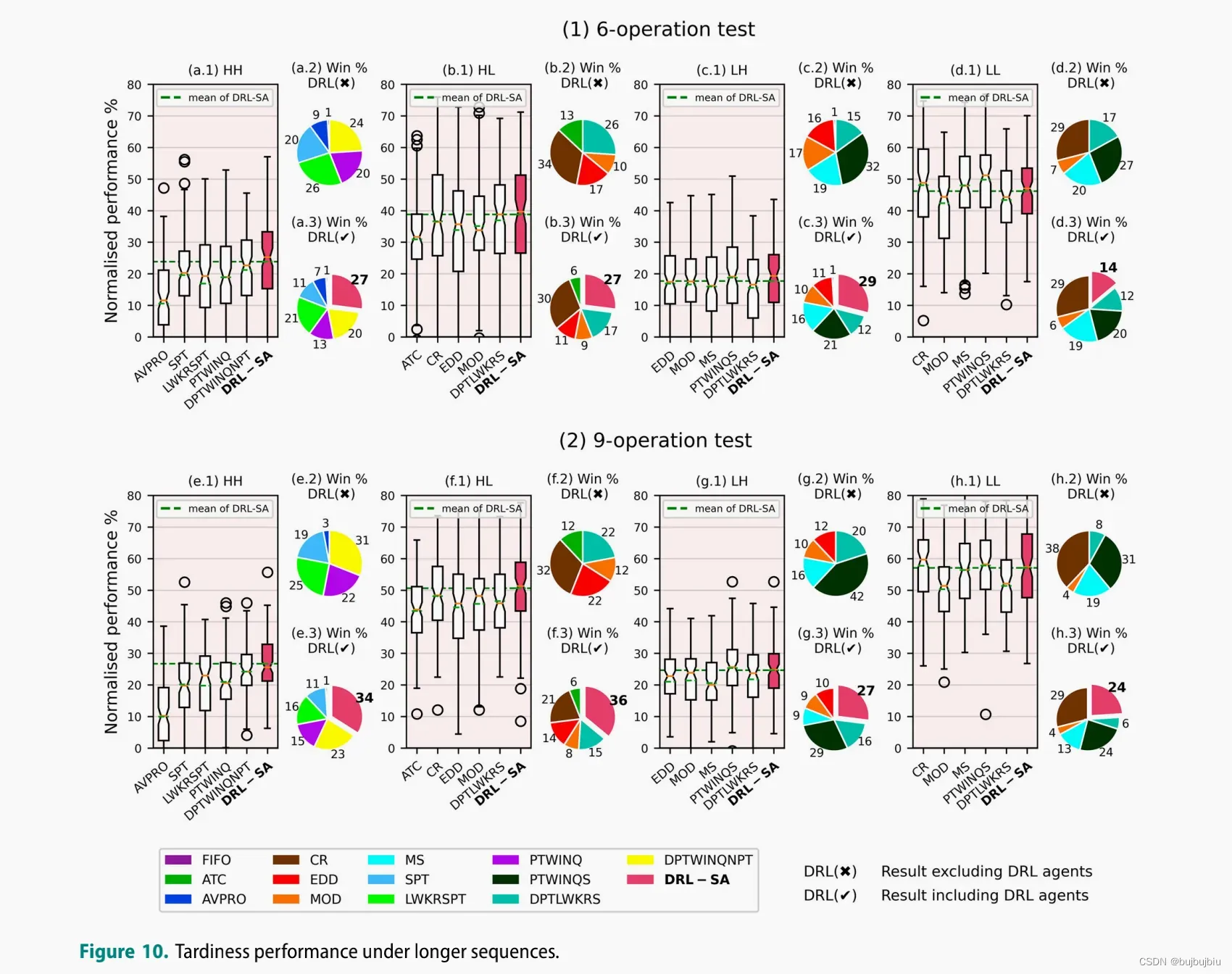
6.Conclusion
本文三大贡献:
- 独特的表示:提出抽象的状态特征和间接的动作表示来处理持续时间长,大规模,动态的调度
- 基于知识的奖励构造:提出代理奖励构造方法来提升训练效率和鼓励合作
- 高效的训练和应用:轻量级的神经网络实现毫秒级的决策
未来:考虑更多的动态事件;使用随机学习探索动作的影响(奖励人工设置的缺陷);多智能体的协同
文章出处登录后可见!