本篇文章借鉴了我的朋友Jc的报告,他是一个十分优秀的人。
本篇文章记录了第一次完整训练优化的过程
0 关于数据集
在CIFAR-10 dataset的介绍中,cifar-10数据集一共10类图片,每一类有6000张图片,加起来就是60000张图片,每张图片的尺寸是32×32,图片是彩色图,整个数据集被分为5个训练批次和1个测试批次,每一批10000张图片。测试批次包含10000张图片,是由每一类图片随机抽取出1000张组成的集合。剩下的50000张图片每一类的图片数量都是5000张,训练批次是由剩下的50000张图片打乱顺序,然后随机分成5份,所以可能某个训练批次中10个种类的图片数量不是对等的,会出现一个类的图片数量比另一类多的情况。
1数据处理
1.1 加载数据集和归一化
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))的作用
使用Normalize()函数,将数据转换为标准正太分布,使得模型更加容易收敛,其中 mean 和 std 的3个值分表表示图像的3个通道。对于单通道的灰度图,可以写成 transforms.Normalize(mean=[0.5], std=[0.5])。
## 加载数据集归一化
transform = transforms.Compose(
[transforms.ToTensor(),
# transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])# 66.98
transforms.Normalize(mean=[0.5, 0.5, 0.5],std=[0.5, 0.5, 0.5])
]
)
PyTorch 中我们经常看到 mean = [0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225] ,是从 ImageNet 数据集的数百万张图片中随机抽样计算得到的。
train_data = torchvision.datasets.CIFAR10("dataset", train=True, transform=transform,
download=True)
test_data = torchvision.datasets.CIFAR10("dataset", train=False, transform=transform,
download=True)
1.2 把训练的数据二八分成 训练集和验证集
【深度学习】训练集、测试集和验证集的相关概念
train_size = int(0.8 * len(train_data))
val_size = len(train_data) - train_size
train_data, val_data = torch.utils.data.random_split(train_data, [train_size, val_size]
, generator=torch.Generator().manual_seed(123))
1.3利用DataLoader来加载数据集
获得图片数据集后,我们就可以利用torch.utils.data.DataLoader将数据集包装成一个数据加载器
train_dataloader = DataLoader(train_data, shuffle=True, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
val_dataloader = DataLoader(val_data, batch_size=64)
2 模型的搭建
2.1 神经网络模型构建
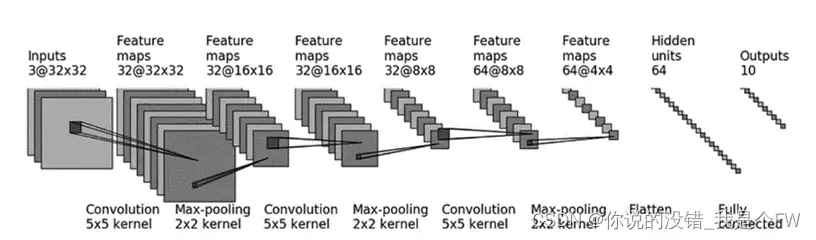
在Pytorch中,可以选择使用Sequential来进行贯序模型的搭建。分析目标神经网络的网络结构,可以得出神经网络各层的具体情况如下表所示。

值得注意的是,通道数为3的32×32的图像,在经过5×5的卷积核时,默认值的情况下输出的图像大小应该为28×28,若想图片的大小仍让为32×32,我们需要计算padding进行填补。
pytorch的conv2d卷积操作有公式可以进行计算:

使用默认的dilation=1,stride=1,计算得出padding为2,同理宽也一样。
在经过三轮的卷积、最大池化的操作后,需要 Flatten 层作为卷积层与全连接层的过渡,处理后的数据从多维变成一维,尺寸为 1×1024。最后通过两个全连接层,将输出个数从 1024 个降到 64 个再到 10 个并实现十分类的概率输出。
def __init__(self):
super(Model_CIFAR10, self).__init__()
self.model = nn.Sequential(OrderedDict([
("conv1", nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2)),
("maxPool1", nn.MaxPool2d(2)),
("conv2", nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2)),
("maxPool2", nn.MaxPool2d(2)),
("conv3", nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2)),
("maxPool3", nn.MaxPool2d(2)),
("Flatten", nn.Flatten()),
("Linear1", nn.Linear(1024, 64)),
("Linear2", nn.Linear(64, 10))
]))
对于神经网络可以通俗地理解为一个函数近似器,它需要近似一个输入x到输入y的映射函数。我们要训练的网络参数其实就是在拟合这个映射函数的未知量。神经网络的训练可以分为两个步骤,一个是前向传播,另外一个是反向传播。
同时,由于该模型为贯序模型,因此可以直接使用Mudule默认的前向传播函数forward(),可以不进行forward函数的重定义。
def forward(self, x):
x = self.model(x)
return x
前向传播计算出了输出值(也即预测值),就可以根据输出值与目标值的差别来计算损失loss。
而反向传播就是根据损失函数loss来反方向地计算每一层的偏导数,从最后一层逐层向前去改变每一层的权重,也就是更新参数,核心就是损失函数对每一网络层的每一个参数求偏导的链式求导法则。
步骤可以概括为:
1.根据模型的输出与真实的target标签计算误差
2.调动反向传播,得到每个要更新参数的梯度
3.调动优化器,对卷积的一些参数进行调整
这里我们选用的损失函数为交叉熵损失函数 CrossEntropyLoss() ,其结合了nn.LogSoftmax() 和
nn.NLLLoss() 两个函数,在做分类(具体几类)训练的时候是非常有用的。
loss_fn = nn.CrossEntropyLoss()
损失函数上,分别对神经网络参数的常见优化器SGD(stochastic gradient descent 随机梯度下降)、和Adam(Adaptive Moment Estimation 自适应矩估计)两种优化器进行了挑选,在实际效果上,发现SGD随机梯度下降对本实验的优化更好。
# optimizer = torch.optim.Momentum(model_u.parameters(), lr=learning_rate)
optimizer = torch.optim.SGD(model_u.parameters(), lr=learning_rate)
在训练过程中使用反向传播优化网络参数。
在使用pytorch的backward()函数进行计算,网络参数进行反馈,梯度是被积累而不是被替换掉,训练时每一个batch只需要更新网络参数,并不需要将上一个batch的梯度继续叠加到下一个batch。因此在每一轮batch中都需要设置optimizer.zero_grad()对梯度初始化为0,把loss关于weight的导数变为0。
outputs = model_u(imgs)
loss = loss_fn(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
2.2 TensorBoard 模型的可视化
我们可以通过安装TensorBoard来进行神经网络结构的可视化。
(1)安装TensorBoard可视化工具
本文在anaconda prompt环境下安装tensorboard,分为两步:
1)激活虚拟环境 activate pytorch-gpu(我自己的环境名)
2)安装tensorboard工具包 pip install tensorboard
(2)利用TensorBoard可视化构建好的模型,生成该卷积网络的图像
1)建立SummaryWriter。用于在log_dir中创建事件文件,将条目直接写入事件文件以供 TensorBoard 使用。
2)模型的数据流和结构的保存。利用SummaryWriter.add_graph()函数来进行模型以及数据流的保存,可视化模型的网络结构图。
pycharm的命令行输入:tensorboard –logdir=log。随后点击超链接访问,得到网络结构图。

我们可以通过writer.add_graph里添加模型以及模型的输入,来检测模型的正确与否。
writer = SummaryWriter('log')
model = Model_CIFAR10()
input = torch.rand(20, 3, 32, 32)
writer.add_graph(model, input_to_model=input)
writer.close()
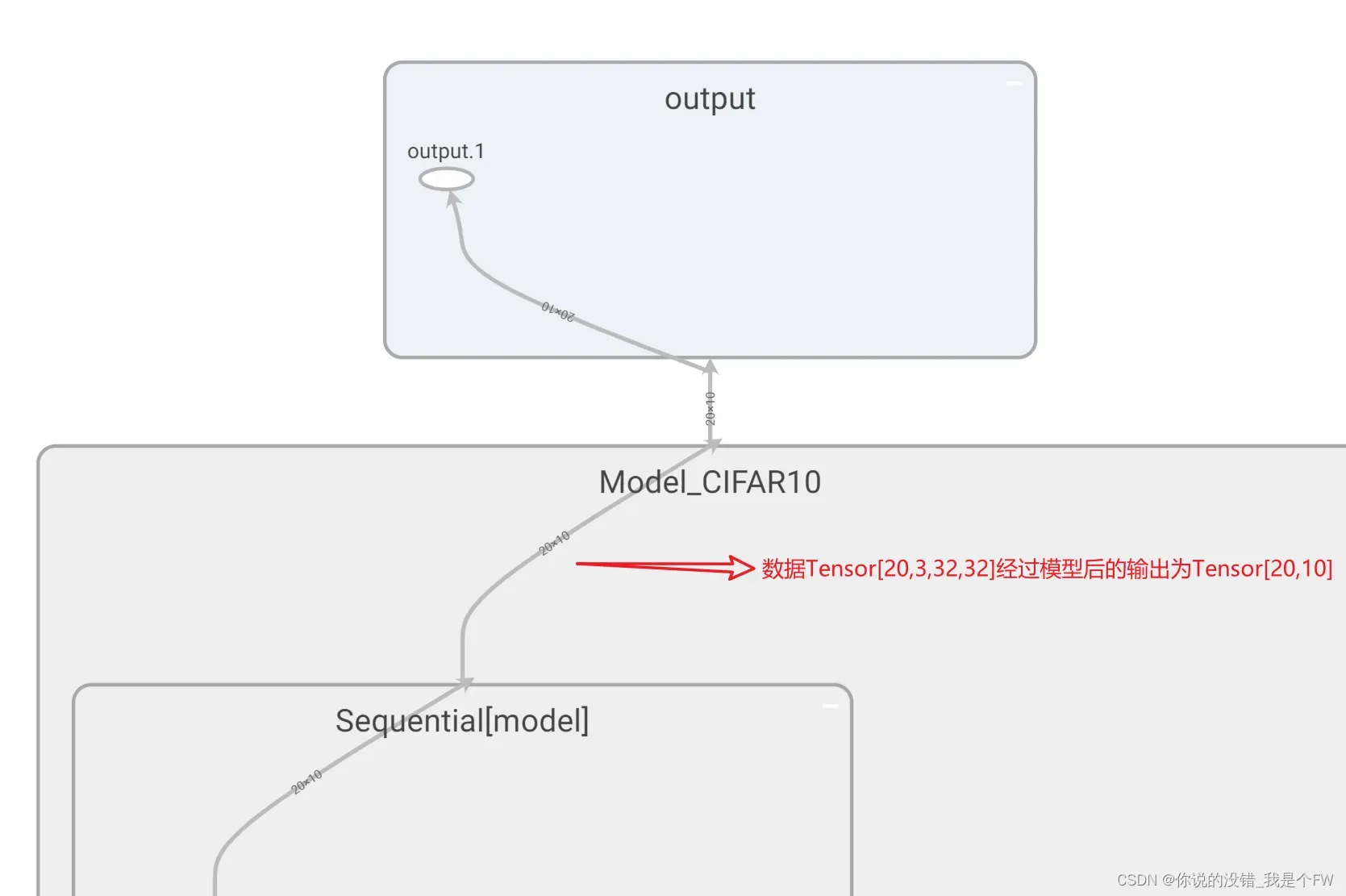
实验中输入模型的torch.rand(20, 3, 32, 32),其torch.Size为[20,3,32,32]
即20个通道数为3的大小为32*32的图像。
那么根据我们的网络结构,输出应该是20个十分类的概率输出,torch.Size为[20.10]
input = torch.rand(20, 3, 32, 32)
print(input.size())
output = model(input)
print(output.size())

TensorBoard的数据流也显示了正确的结果:
3 模型的训练
3.1 定义训练设备
训练模型是个时间较长的过程,如果电脑中有cuda的支持,将可以使用GPU进行训练,减少一定的时间。
在神经网络中,有三个部分可以放到GPU中
分别是在模型、损失函数以及数据上。
首先定义训练设备device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
然后在程序中模型、损失函数、和数据上使用to函数加入到GPU中。
# 模型
model_u = model_u.to(device)
# 损失函数
loss_fn = loss_fn.to(device)
# 数据
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
3.2划分数据集
如果只划分训练集和测试集,那么使用测试集对模型进行测试并观察指标,根据在测试集上获得的效果调整模型,这会导致测试集参与了人工调参的过程,会出现过拟合测试集的问题,因此在训练集中分出一部分作为验证集,用于调整模型的超参数,根据模型在验证集上的表现,决定哪组超参数拥有最好的性能。
测试集只用来评估模型的泛化能力,即之前的模型使用验证集确定了超参数,最后使用一个完全没有见过的新的数据集来判断这个模型是否准确。
在本实验中,将训练集划分成80%的训练集和20%的验证集,即最终训练的样本数为40000,验证集的样本数为10000,测试集样本数为10000。
本实验使用的CIFAR-10数据集是均衡分布的数据集,因此没有样本不平衡的问题。
因此本次实验可以采用了data.random_split()随机划分的方式便可以完成训练集和验证集的划分工作。
# 把训练的数据二八分成 训练集和验证集
train_size = int(0.8 * len(train_data))
val_size = len(train_data) - train_size
train_data, val_data = torch.utils.data.random_split(train_data, [train_size, val_size]
, generator=torch.Generator().manual_seed(1))

torch.utils.data.Dataset是代表这一数据的抽象类,而DataLoader是Pytorch中用来处理模型输入数据的一个工具类。组合了数据集(dataset) + 采样器(sampler),并在数据集上提供单线程或多线程(num_workers)的可迭代对象
# 利用DataLoader来加载数据集
train_dataloader = DataLoader(train_data, shuffle=True, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
val_dataloader = DataLoader(val_data, batch_size=64)
本实验将加载器批次大小设为64,同时为了增强模型的泛化能力,将训练集数据加载器的 shuffle 设为True,使得每一次迭代时都对数据集重新进行洗牌以尽可能地避免模型过拟合现象。
3.3 训练集训练
Epoch训练轮数,一个epoch表示所有的数据送入到网络中,完成依次前向计算+反向传播的过程,在本次实验中设置训练轮数为50。
由于一个epoch数据常常太大,因此分成多分batch,在本实验中batch_size设置为64。
先将训练集数据读出,并将数据加载到模型中。利用 model 进行前向传播
计算。利用定义好的损失函数 loss_fn()进行损失的计算。
for i in range(epoch):
# 训练步骤开始
model_u.train()
total_train_accuracy = 0
total_train_loss = 0
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = model_u(imgs)
loss = loss_fn(outputs, targets)
total_train_loss += loss.item()
3.3.1 使用优化器优化模型
在使用pytorch的backward()函数进行计算,网络参数进行反馈,梯度是被积累而不是被替换掉,训练时每一个batch只需要更新网络参数,并不需要将上一个batch的梯度继续叠加到下一个batch。因此在每一轮batch中都需要设置optimizer.zero_grad()对梯度初始化为0,把loss关于weight的导数变为0。
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
3.4 验证集验证
正常情况下,测试集是未知的数据集,对模型泛化能力的测试。因此人们在只有训练集的情况下,需要设置一部分的验证集,来人为地调参,获得模型泛化能力的超参数。
然而在本实验中,已知了测试集,因此我们要想获得测试集的高准确率,只需对测试集的结果进行参数的调整,获得超参数,因此训练集中划分出验证集是没有必要的。
///正常情况下
with torch.no_grad():
for data in val_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = model_u(imgs)
loss = loss_fn(outputs, targets)
total_val_loss += loss.item()
val_accuracy = (outputs.argmax(1) == targets).sum()
total_val_accuracy += val_accuracy
测试集带入训练好的模型进行测试
与之前的训练套路相同,均是先将训练集数据读出,并将数据加载到模型中。利用 model 进行前向传播计算。利用定义好的损失函数 loss_fn()进行损失的计算。
在前面训练的过程中,需要通过训练的损失函数loss来计算每一层的偏导数,再调用优化器逐一改变每一层的权重,来达到模型参数优化的目的,而测试集并不需要反向传播,优化模型,只是起到检验模型泛化能力,因此无需反向传播。
因此使用torch.no_grad()表面当前计算不需要反向传播,使用之后,强制后面的内容不进行计算图的构建。
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = model_u(imgs)
loss = loss_fn(outputs, targets)
total_test_loss += loss.item()
test_accuracy = (outputs.argmax(1) == targets).sum()
total_test_accuracy += test_accuracy
3.5 模型的评估
本实验将每一次迭代过程中的测试集下的模型准确率、模型损失函数值以及每个类别的准确率记录下来并通过tensorboard 进行可视化,以便在训练过程中对模型的泛化能力、是否存在过拟合现象等做出更加精准的判断。
在每一轮epoch下,模型的输出调用argmax(1)函数返回数组中每一行中最大值的索引值,从而获得20张照片十分类下预测最大概率的类别,与真实的标签进行比较,获得预测正确的标签的数量。
3.5.1 计算准确率
计算整体训练集的准确率:
train_accuracy = (outputs.argmax(1) == targets).sum()
total_train_accuracy += train_accuracy
所有预测正确的数量除以训练集的总数量即为本轮训练的准确率
train_accuracy_list.append(float(total_train_accuracy / 40000))
print(total_train_step, " train:", total_train_accuracy / 40000)
计算每个类别的准确率:
c = (outputs.argmax(1) == targets).squeeze()
for ind in range(len(targets)):
_label = targets[ind]
train_class_correct[_label] += c[ind].item()
train_class_total[_label] += 1
通过(outputs.argmax(1) == targets).squeeze()可以获得每一张图片与对应图片标签预测正确与否,再通过一个for循环记录该标签下预测正确的数量与预测的总数量。
在测试集下的总体准确率:
max_acc = total_test_accuracy / 10000
test_loss = total_test_loss
3.5.2 模型的总体损失值
在每个batch都调用损失函数,并且累加
loss = loss_fn(outputs, targets)
total_train_loss += loss.item()
3.5.3 训练时间
训练开始:
start_time = time.time()
训练结束:
end_time = time.time()
print(end_time - start_time)
3.5.4 tensorboard进行可视化
本实验对模型在训练集和测试集下的准确度变化曲线以及相应的模型损失曲线来对模型的泛化能力进行初步评估。
使用add_scalar函数进行可视化
tag (string): Data identifier图像的名字
scalar_value (float or string/blobname): Value to save y轴的描述
global_step (int): Global step value to record x轴的描述
本次采用的优化器为SGD随机梯度优化器,学习率为0.005,训练轮数为80,设备为RTX 3060。
首先对训练集下模型的准确度和损失函数值进行曲线绘制:
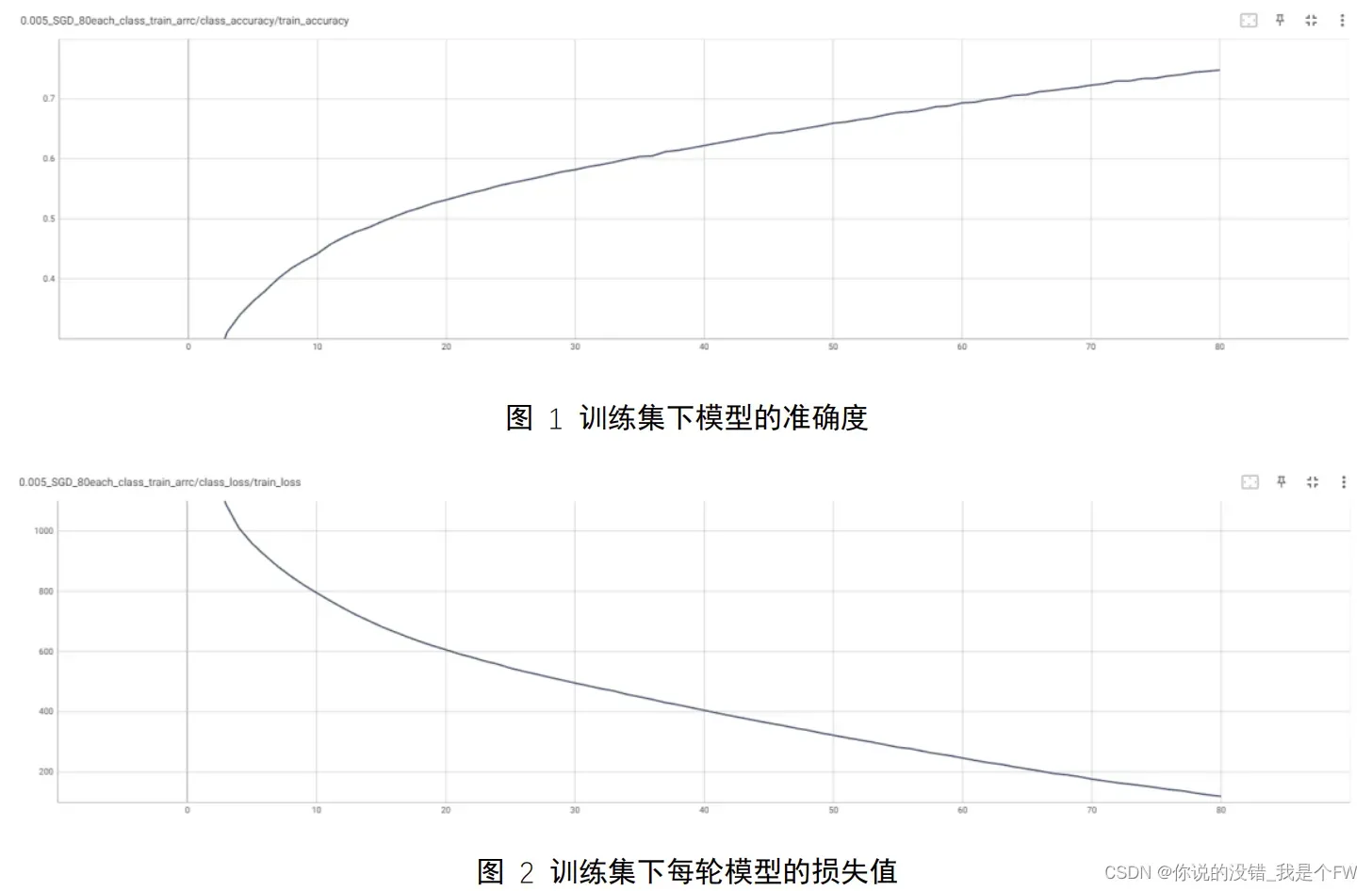
在 80 次迭代训练的情况下,模型在训练集下的准确度不断地升高,只是增
长的趋势放缓,由于学习率的设置为 0.005,因此收敛的速度较慢,未出现训练
集的准确度达到 95%以上的情况(最高只达到了 94.82%)。而每一轮模型的损
失函数值也随着迭代的次数逐步降低,第 80 次迭代完成的模型函数的损失值为
119.20。
接着实验对每一个类别的准确率进行了绘制。
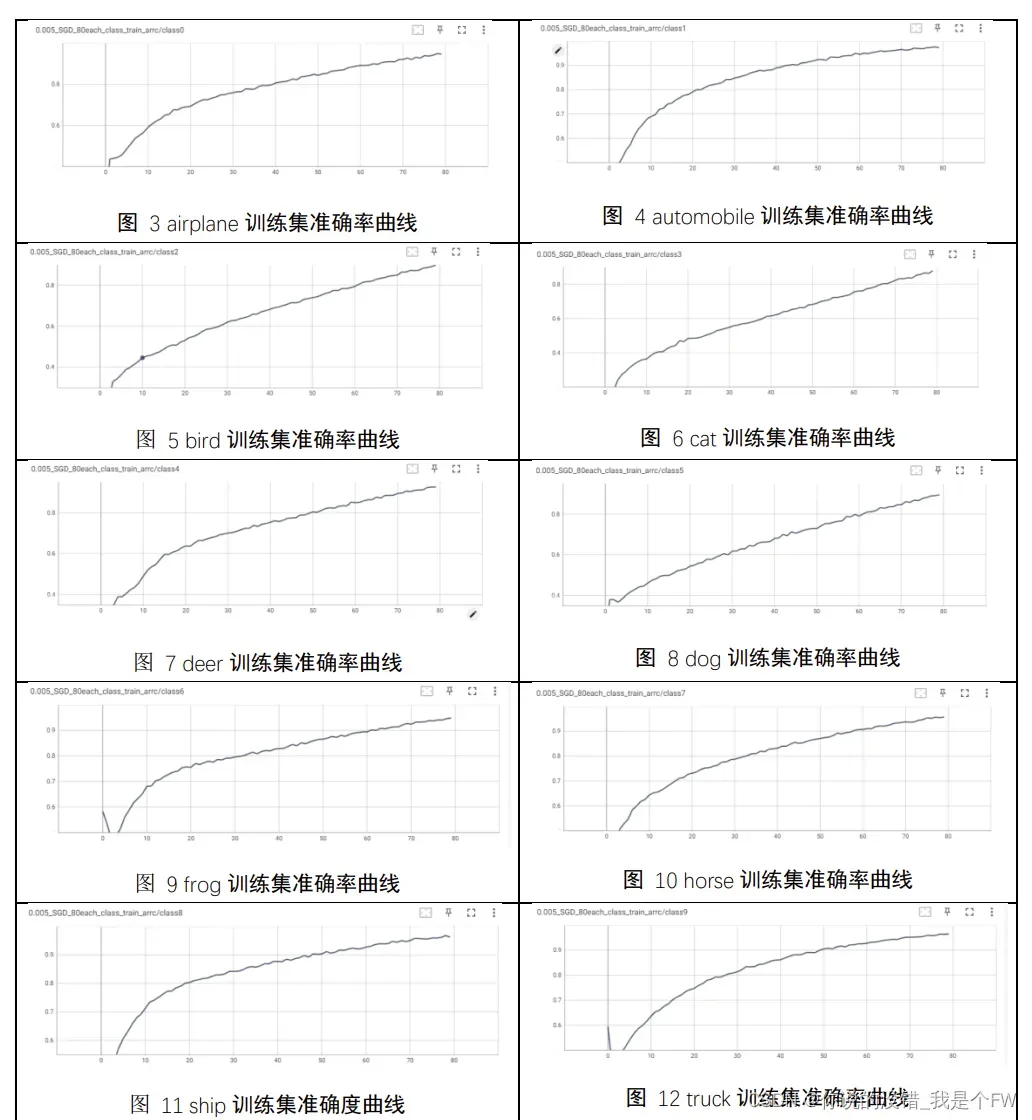
基本趋势与训练集整体的模型相同,值得注意的是,在训练轮数较少时,由
于每一轮的网络参数的优化会有一定的偏向,因此会出现较大的波动,在随着训
练轮数的增加,模型的整体网络参数的优化趋于平衡,因此抖动较小。与训练集
最后的准确度仅为 94%类似,10 个类别单独的类别的准确率,最低达到了 87.02%,
最好的一组识别准确率则达到了 96.47%。
实验对验证集的准确率曲线以及损失函数值曲线如下图所示。

与训练集模型的准确率不断上升不同,在 80 次迭代训练的情况下,验证集
在迭代了 30 轮之后,模型在验证集下的准确度就处在不断的波动,查看
tensorborad 绘制的曲线,验证集的最高准确率达到了 67.33%,而波动的最低准
确率仅仅 65.06%。这种抖动无法收敛的情况可能与设置的学习率 0.005 有关,导
致在网络参数的更改较大,无法收敛。从损失函数也可以看出,测试集的每轮损
失函数值并没有随着迭代的轮数而降低,而是在 30-40 轮之间时损失函数值达到
最低,然后逐步上升。
验证集的十个类别最终的准确率如下表:
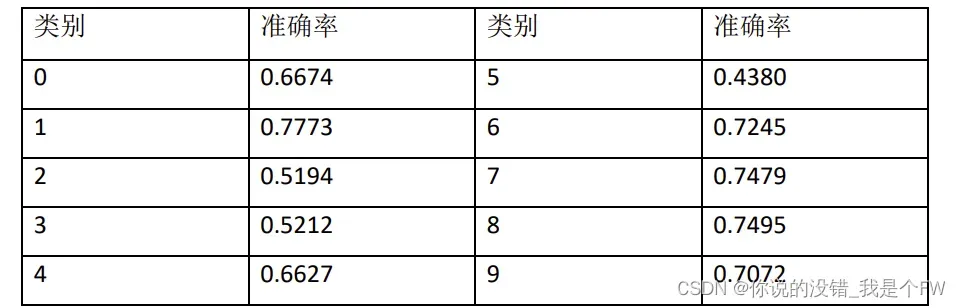
十个类别的准确率曲线类似,因此选取其中一个曲线进行说明:
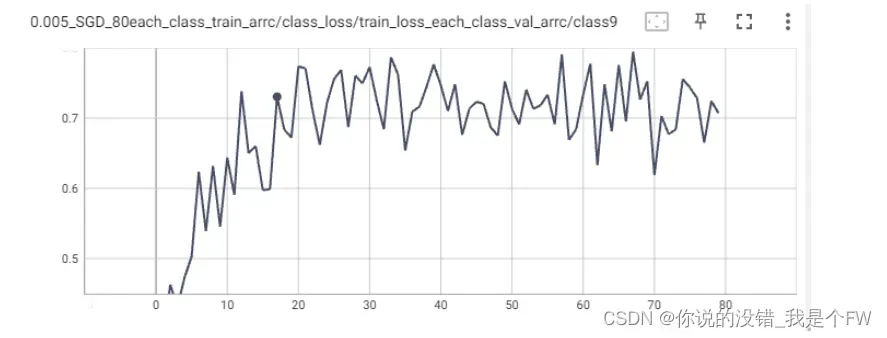
与验证集的整体抖动类似,类别 9 的准确率曲线波动几乎从头到尾,每一轮
反向传播的参数调整对各个类别单独的准确率影响较大。
最终在测试集的准确率为 65.33%。
3.5.5 ROC 曲线的绘制
ROC 曲线将灵敏度与特异性以图示方法结合在一起,可准确反映某分析方
法特异性和敏感性的关系,是试验准确性的综合代表。
AUC 值:AUC(Area Under Curve)被定义为 ROC 曲线下与坐标轴围成的
面积,显然这个面积的数值不会大于 1。又由于 ROC 曲线一般都处于 y=x 这条
直线的上方,所以 AUC 的取值范围在 0.5 和 1 之间。AUC 越接近 1.0,检测方
法真实性越高;等于 0.5 时,则真实性最低,无应用价值。
# 需要先进行热独编码,以便分别绘制ROC曲线
y_test1 = y_test1[10000:]
prediction = prediction[10000:]
prediction1 = DataFrame(prediction.reshape((10000, 10)))
y_test11 = pd.get_dummies(y_test1[:])
for i in range(len(n_classes)):
fpr[i], tpr[i], _ = roc_curve(y_test11.iloc[:, i], prediction1.iloc[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
plt.rcParams['font.family'] = ['calibri']
plt.figure()
lw = 1
colors = ['dimgray', 'rosybrown', 'lightcoral', 'tomato', 'peru',
'burlywood', 'steelblue', 'olive', 'lawngreen', 'lightseagreen']
for i, color in zip(range(len(n_classes)), colors):
plt.plot(fpr[i], tpr[i], color=color, lw=lw,
label='ROC curve of class {0} (AUC = {1:0.3f})'
''.format(i, roc_auc[i]))
plt.plot([0, 1], [0, 1], 'k--', lw=lw)
plt.xlim([-0.05, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic for multi-class data')
plt.legend(loc="lower right")
plt.show()
绘制 ROC 曲线:
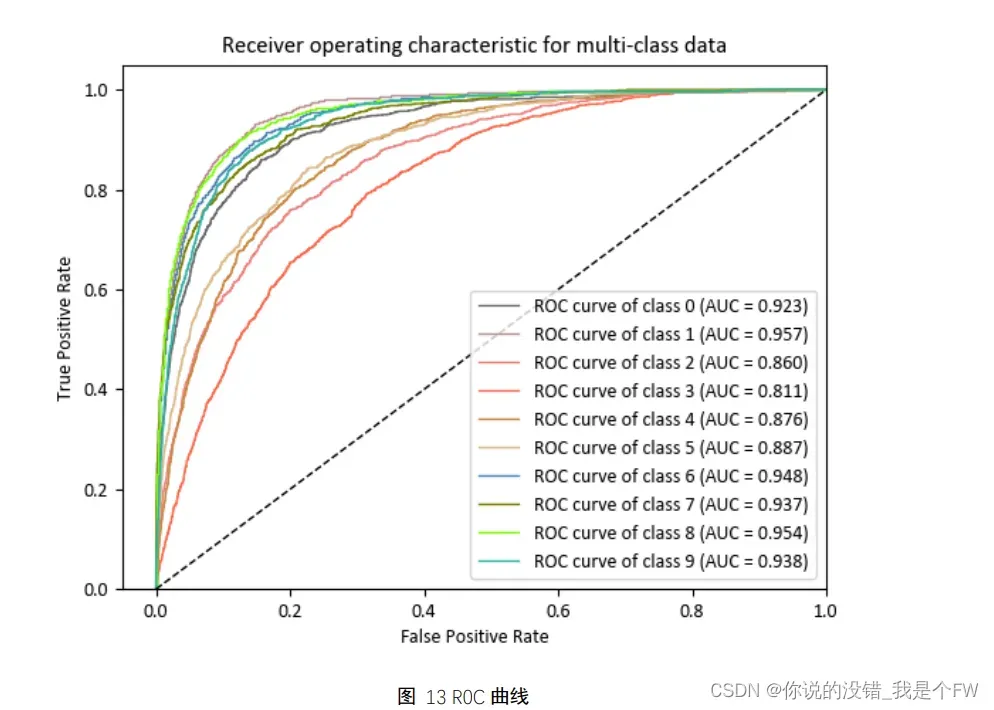
如上图 ROC 曲线以及 AUC 值来看,模型整体的 AUC 值突破 0.8,因此
该模型对数据集的各个类别都有较好的分类性能。但是不同类别的 AUC 也有较
大的差距,在类别 airplane、automobile、frog、horse、ship、truck 的 AUC 值突
破 0.92。相比而言 bird、cat、deer、dog 而言 AUC 值则 0.89 都没有达到,由于
是 cat 类别的 AUC 值仅有 0.811。这可能与不同类别提取特征的难度有关,因此
模型的整体分类器的性能较为不错,但是在不同的类别存在较大的差异。
3.6 模型保存与加载
本次实验使用model.save()的方法,同时保存模型的结构以及网路参数
以训练学习率、优化器、以及训练轮数三者进行命名。
torch.save(model_u, r"trainmodel\test_{}.pth".format(str(learning_rate)+"_SGD_"+str(epoch)))
此时,在模型的测试之前,我们只需要对训练好的模型加载即可,无需再重复训练,可以节省我们大量的时间。
3.7 不同超参数组合下模型性能评估
3.7.1 学习率与迭代次数对模型的影响
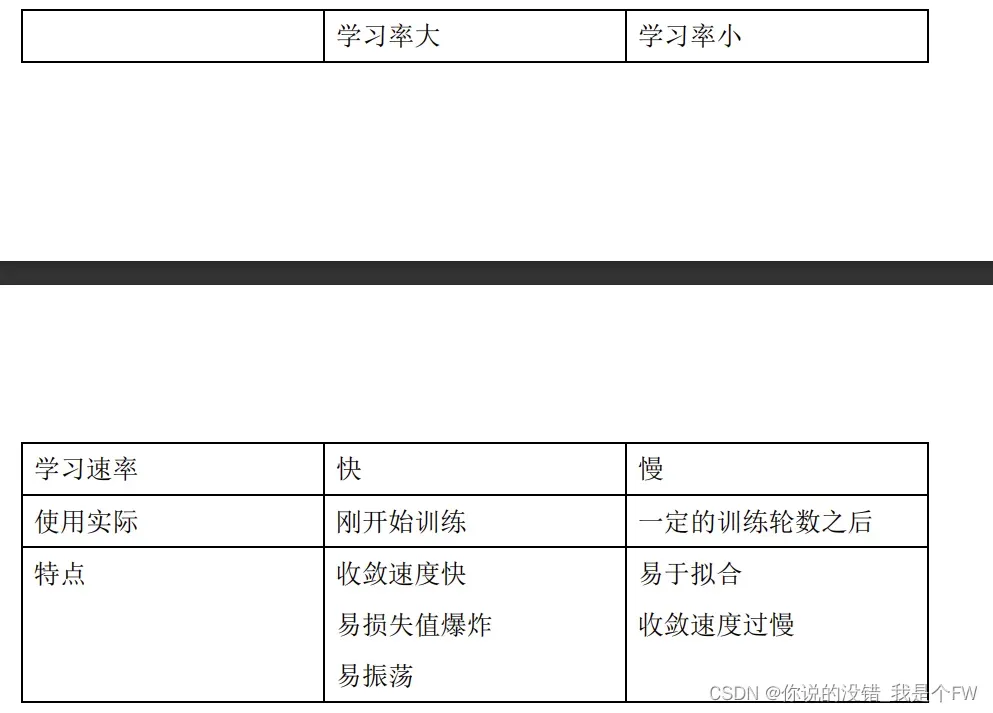
(1)学习率
训练模型输出误差反向传播给网络参数,以此来拟合样本的输出。本质上是一个优化的过程,但每次更新参数参数利用多少误差,就需要通过一个参数来控制,也就是学习率(Learning rate),也称为步长。
通常情况下,学习率的大小有着这样的特点:
(2)迭代次数
一个epoch等于训练集中的全部样本训练一次,完整的数据集在同样的神经网络中传递多次,随着epoch数量的增加,神经网络中的权重的更新次数也在增加,曲线从欠拟合变得过拟合。
3.7.2 不同超参数组合下模型性能的比较
在之前对CIFAR数据集分类模型进行初步分析,本实验将从模型的训练轮数epoch和模型的学习率两方面进行组合,以此研究不同超参数组合对模型性能的影响。
本次实验通过改变模型的训练轮数以及模型的学习率来探究两者不同组合
下对模型性能的影响,此处设置的迭代次数分别为20、40、60、80、100以及
120。设置学习率分别为0.001、0.005、0.010以及0.015。实验将从错误率、准
确率、时间(训练+测试)三个维度评估不同超参设置下的模型泛化性能,并
进行分析总结。
本次采用的优化器为同一个优化器 SGD 随机梯度优化器,设备均为 RTX
3060。
模型训练集下准确率曲线:
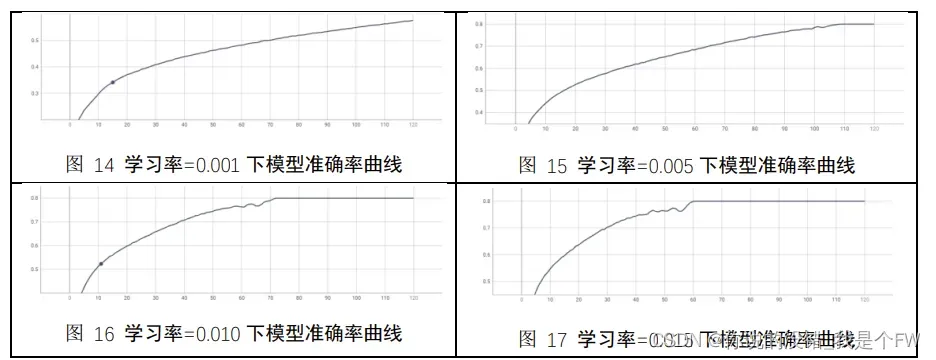
训练集在学习率与训练轮数组合下准确率数据如下:
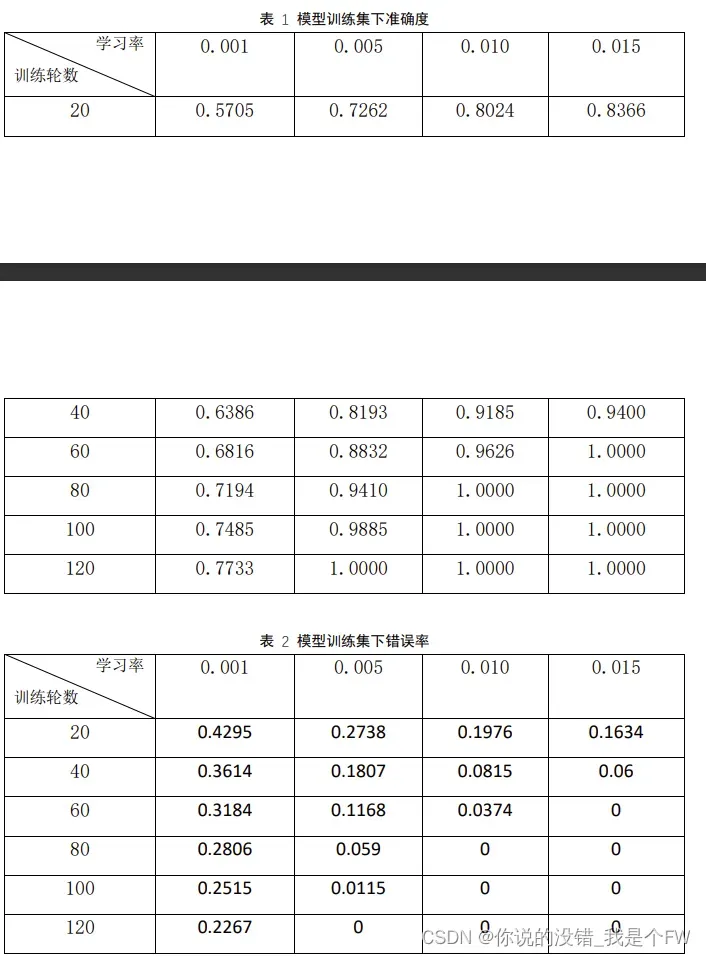
从以上两表可以看出,当学习率相同,迭代的轮数越多,模型的准确率越高,
相应的模型的错误率就越低。当训练轮数相同,那么训练轮数越少,模型的准确
率、错误率差别就越大,而当训练到一定次数,学习率大的模型对于准确率已经
达到 1,没有上升空间,且学习率越大,达到准确率 1 的训练轮数就越少。
为了便于观察,实验在每一轮训练后使用测试集进行测验。训练 120 轮四个
不同学习率的测试集集准确率曲线为:
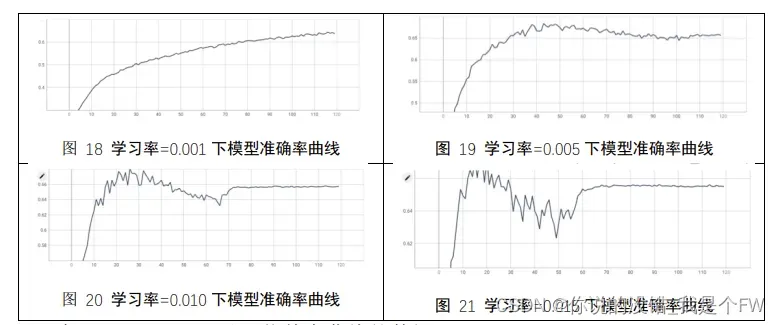
在 Tensorboard 可以下载整个曲线的数据。
测试集在学习率与训练轮数组合下准确率数据如下:
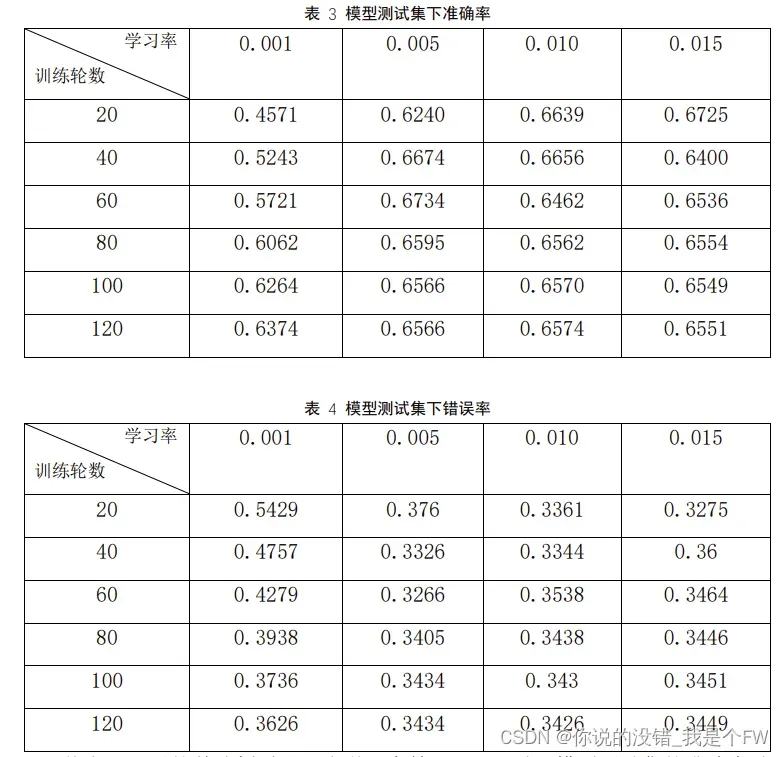
从表 3 可以简单分析看出,当学习率等于 0.001 时,模型测试集的准确率随
着训练轮数的增加而不断地提升。而学习率 0.005、0.010、0.015 三者则均呈现出
了达到高的准确率之后不断下降趋于平缓的情况,并且学习率越大,则越早到达
测试集准确率的最高峰,三者最终完成 120 轮训练后的准确率基本相同,但高于
学习率等于 0.001 时的准确率。因此结合学习率的特点,我们可以合理猜测,学
习率等于 0.001 的模型还并未收敛。因此实验又增加了 80 轮的训练轮数,最终
的准确率为 0.6702。
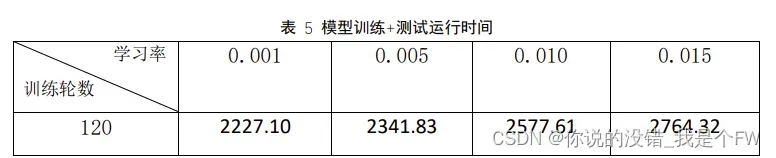
从模型训练和测试时间来看,学习率于总的花费时间成正比关系,即学习率
越大,花费的时间越多。
结合以上所有,得出在学习率和训练轮数24种组合下,学习率为0.005,训
练轮数为60时,模型测试集的准确率达到67.34%,错误率为32.66%,但是我们
发现该情况下,模型训练集的准确率还并未达到100%,仅为88.32%,因此可
以认为此时的模型在训练集上并未收敛,测试集上的高准确率和低错误率,可
能时模型未稳定而导致的异常结果,因此暂时无法认为其对模型泛化能力好的
表现。
因此实验重新对模型设置相同的超参,即设置学习率为0.005,训练轮数为
60。在经过十次重复训练之后,模型测试集的准确率平均值为67.20%,相差无
几,因此本实验认为该超参组合训练下的网络参数对模型泛化能力是稳定且较
为优秀的。
3.7.3 学习率衰减策略进行模型优化

模板如下:


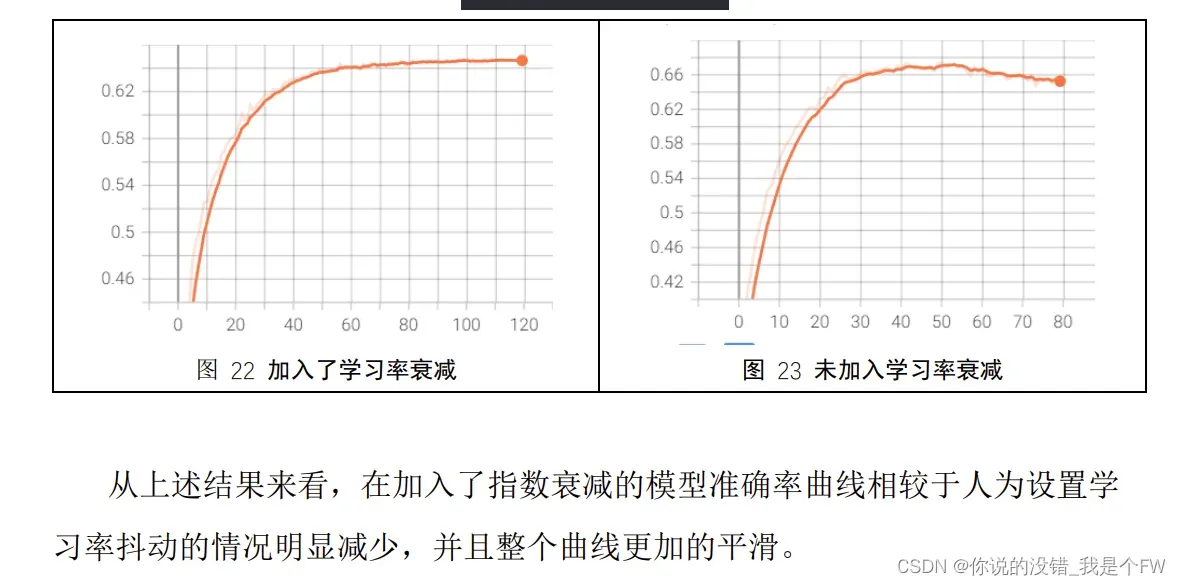
3.7.4 防止过拟合

optimizer = torch.optim.SGD(model_u.parameters(), lr=learning_rate)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.95,last_epoch=-1)
scheduler.step()
class Model_CIFAR10(nn.Module):
def __init__(self):
super(Model_CIFAR10, self).__init__()
self.model = nn.Sequential(OrderedDict([
("conv1", nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2)),
("relu1",nn.ReLU()),
("maxPool1", nn.MaxPool2d(2)),
("conv2", nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2)),
("relu2", nn.ReLU()),
("maxPool2", nn.MaxPool2d(2)),
("conv3", nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2)),
("relu3", nn.ReLU()),
("maxPool3", nn.MaxPool2d(2)),
("Flatten", nn.Flatten()),
("Linear1", nn.Linear(1024, 64)),
("dropout", nn.Dropout(p=0.2)),
("Linear2", nn.Linear(64, 10))
]))
def forward(self, x):
x = self.model(x)
return x
在修改后的网络结构,测试集的准确率为 69.78%,高于修改前的
67.33%。因此在原先神经网络模型结构中加入激活函数以及 dropout 层能够
一定程度上提高模型的准确率,增强模型的泛化能力,起到一定的优化作用
文章出处登录后可见!