Meta在论文中发布了新模型Segment Anything Model(SAM),声称说可以分割一切,可以在任何图像中分割任何物体,论文链接https://arxiv.org/abs/2304.02643
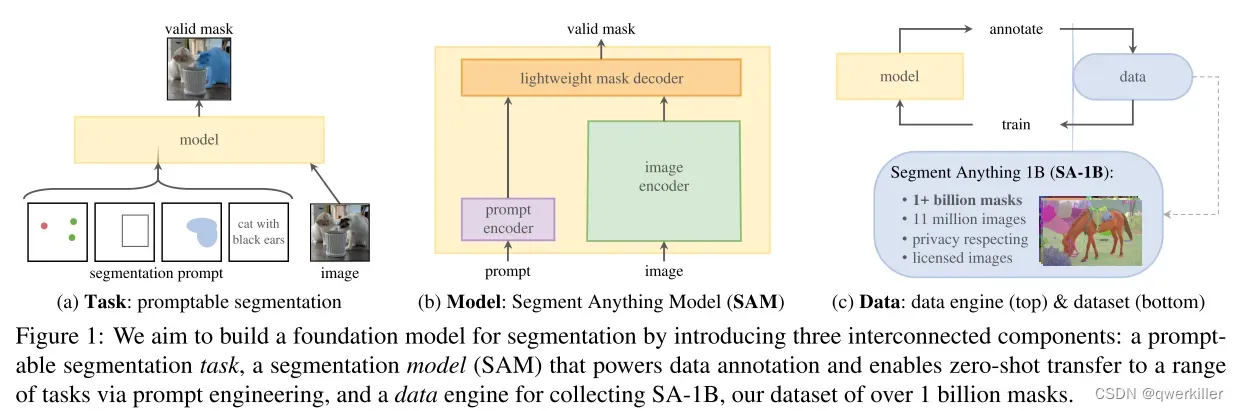
大概看了一遍论文和感受了Meta提供的demo模型,我觉得主要有两个爆点,首先是收集数据的方式,加入了主动学习的形式,因为他的数据集特别大,达到了十亿组数据,那么庞大的数据不可能全部去标注,然后会通过标注一部分然后剩下一部分其他人标,最后加上人工校验部分达到一个区域闭环的效果,当数据集足够庞大时,训练出的模型效果一定就会更好,而且像GPT一样不断更新学习新的数据,模型效果会更好。这个点来说是一个很工程性但是工作量非常大的工作。第二点是有一个prompt的概念,prompt简单来说就是类似于一个“提示词”的概念,其实跟GPT现在那么火和不断提升性能的原因一样。因为ChatGPT用户会给它输入一句话或者一段话来“提示”ChatGPT如何去给出最正确的答案,SAM也同样,在demo示例上SAM首先会自动分割图像中的所有内容,但是如果你输入一个提示词的话,比如一张图片你想让SAM分割出Cat或Dog这个提示词,SAM会自动在照片中猫或者狗周围绘制框并实现分割。
剩下具体的文章内容大家可以点击文章中的链接查看,接下来给大家介绍一下如何使用SAM的demo教程,链接在这https://segment-anything.com/demo
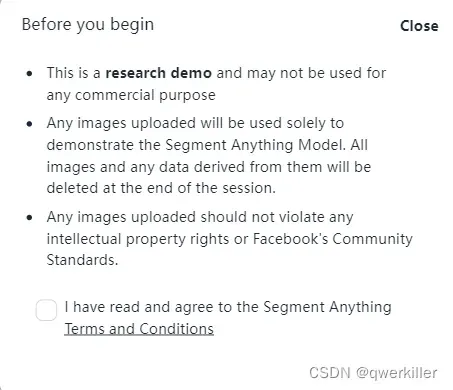
首先我们同意该提示,大概意思是这是一个研究演示,不能用于任何商业目的。上传的任何图像将仅用于演示分段任意模型。在会话结束时,将删除所有图像和从中派生的任何数据。上传的任何图片都不应侵犯任何知识产权或Facebook的社区标准。
之后我们可以随意点击上面的一张示例图,刚才说到了狗狗,我们就点进去一张飞奔的柯基,看看能不能很好的分割出来。点进去之后需要等模型加载一下
加载过之后,会提示你怎么去使用,不过是英文的,可以看我之后的教程,这个是通过添加点来掩盖区域。选择“添加区域”,然后选择对象。通过选择移除区域来细化蒙版,然后选择区域。
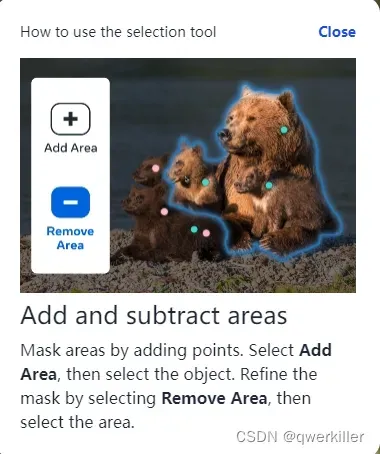

我们可以通过add mask来添加mask点来让模型自动分割,反之remove area可以移除区域,底下的reset可以重置所有标记的点。undo可以撤销刚才标记的点,可以看到这个图片打过点之后分割出来的柯基非常的精准,其实在不click的时候也可以自动分割的特别精准,毕竟也是示例图片。

接下来就是box的选取,就是说选定一个box区域,然后模型会自动分割出来框里面需要的图像,看起来分割的效果也是非常的不错。
接下来就是SAM最厉害的一点了,segment anything,可以看到整张图片中的狗、草坪、树都被很好的分割出来了。

以上就是基本的示例内容,接下来我们可以自定义load图像,会到最开始的地方,点击load。
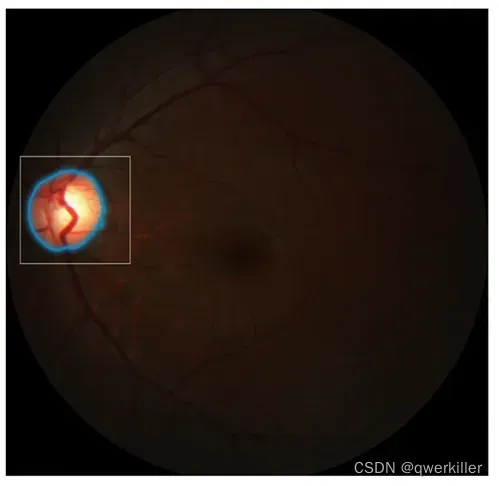
我导入了一张医学图像数据,青光眼杯盘比分割的数据,想看看泛化到医学图像需要高精度分割的数据SAM的表现如何,可以发现我随便打了一个框分割的效果其实就已经特别好了,看来这个大模型确实有着很强的效果,不过可能还是达不到医学图像分割的标准,我在之后的博客会介绍SAM怎么和医学图像进行结合。
论文代码也已经开源,可以在https://github.com/facebookresearch/segment-anything中下载代码,之后也会给大家更新怎么本地调用SAM模型的教程的。
文章出处登录后可见!