本文介绍了一款基于ChatGPT的英语口语练习应用SpokenAi,包括PortAudio的安装流程和核心代码,以及语音合成TextToSpeech的实现。同时提供了配置文件和部署运行示例。 –由ChatGPT总结生成
一.前言
Hi,大家好,我是Baird。最近几个月大火大热的ChatGPT已经发布到ChatGPT4版本了,我也一直在关注ChatGPT的发展,一直在思考能基于ChatGPT或着说openai的能力能做出点什么应用,解决一些问题。
💥在仔细看过openai的API文档后,发现openai不止提供了Chat的能力,还提供了如语音转文字,图片生成等能力。虽然没有ChatGPT那么火,但经过一番试用后,发现和ChatGPT效果一样让人惊艳。索性就直接来一个openai全家桶,通过openai的能力开发一款应用试试。
开发什么呢? 🤔
ChatGPT对英语的语言能力自然不必说,而我们国人当下英语学习面临的一大问题就是哑巴英语,市面上的提供的英语对话机器人和ChatGPT比起来差得不是一星半点。只能请老师一对一真人教学? 🤨 拜托,现在都2023年了,还需要花钱请口语老师么?
来造一款Ai口语练习应用解决这个问题 💯
ChatGPT4是由OpenAI开发的自然语言处理模型,采用了大规模无监督学习的方式进行训练,可用于生成文本、回答问题和聊天等任务。OpenAI是人工智能领域的一家公司,其API文档提供了多种功能,包括语音转文字、图片生成等。
二.需求清单
首选先列出我们需求清单,这个是一个简单版本的英语口语练习功能,先不打算造一个大app,我们只需要解决如下问题
- 读取语音输入
- 语音转文字
- 通过ChatGPT沟通交流
- 文字转音频
- 音频播放
- 持续进行上述1~5步骤
基于上述功能,第一期我打算先做一个终端版本的应用-SpokenAi,看看后续发展再考虑做一个Web或APP版本的程序 (实际上是缺人手缺时间 🤧)
三.系统架构
来,先设计一下我们SpokenAi的系统架构
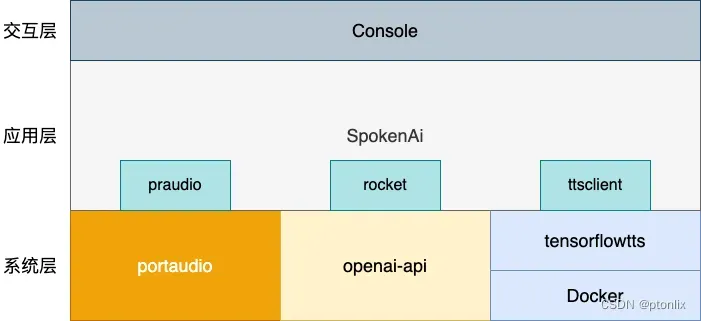
- portaudio: PortAudio是一个跨平台的音频I/O库,提供了简单的API,使得开发人员可以在不同的平台上以相似的方式访问音频硬件。它支持Windows、Mac OS X、Linux和其他主要的操作系统。PortAudio支持多种音频API,包括ASIO、Core Audio、DirectSound、MME / WDM、ALSA和OSS。PortAudio还包括一个流接口,允许开发人员以相同的方式使用不同的音频API和硬件。
- openai-api: 提供了多种API服务,包括但不限于自然语言处理、语音转文字、文字转语音、图像生成等。在OpenAI的API文档中,用户可以申请API密钥,并使用API进行开发和测试。
- tensorflowtts: TensorflowTTS 是一个基于 TensorFlow 的语音合成工具包,它包含了多种语音合成模型和前处理工具,并且支持多种语音合成任务,例如有人声合成(Vocoder)、语音转换、语音增强等。它可以帮助开发者快速搭建语音合成模型,定制自己的语音合成系统。
- Docker: Docker是一种容器化技术,可以将应用程序及其依赖项打包在一个容器中,以便在任何地方运行。容器是一种轻量级的虚拟化技术,可以提供与传统虚拟机相似的隔离性和安全性,但占用的资源更少。Docker还提供了一套工具和平台,使得容器的构建、部署和管理变得更加容易。
- SpokenAi:整体应用层,其中有三个库分别是praudio、rocket、ttsclient,对应如下作用
- praudio: 封装portaudio,对外提供音频录制和音频播放等接口
- rocket: 封装openai-api, 对外提供Chat接口、音频转文字等接口
- ttsclient: 提供调用容器化运行的tensorflowtts的接口
- Console: 终端交互层,用户按提示进行操作,输入信息和进行相关操作
Tips:tensorflowtts 依赖较多,为方便完整,这里采用Docker部署
四.流程设计
接下来,我们设计一下交互流程
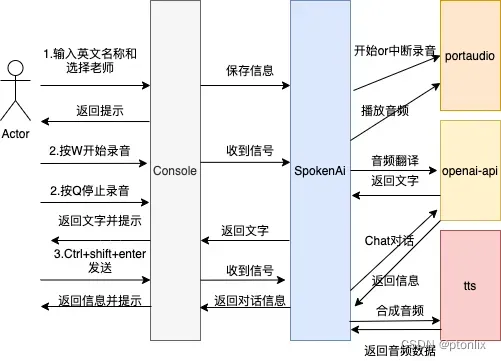
简单概括总体流程有三个步骤,一是输入个人信息 二是录音转文字,三是发送消息,进行对话交互
由于是通过终端访问,主要监听键盘事件,进行不同操作
如 按W键会开始录音,录音过程中按Q停止录音,待录音翻译完成后,按Ctrl+shift+enter发送消息
五.开发细节
编程语言: Go 1.6+
SpokenAi使用依赖于portaudio,需要提前安装好portaudio否则编译无法通过
PortAudio
一.PortAudio下载地址:
- Windows: http://www.portaudio.com/download.html
- MacOS: brew install portaudio
- Linux: apt-get install portaudio19-dev
Mac和Linux比较好安装,Windows只能源码编译安装,具体流程如下:
PortAudio Window 安装流程
- 下载PortAudio源码:http://www.portaudio.com/download.html
- 安装Visual Studio 2019和CMake
- 将源代码解压缩到 C:\PortAudio 文件夹中
- 打开 CMake,选择 C:\PortAudio 作为源代码文件夹,选择一个输出文件夹,点击 Configure 按钮
- 在生成选项中,选择 Visual Studio 16 2019,点击 Finish 按钮
- 点击 Generate 按钮
- 打开 Visual Studio,选择 Open a project or solution,选择 C:\PortAudio\build\portaudio.sln 文件,点击打开
- 在 Visual Studio 中,右键点击 portaudio_static 项目,选择 Build,等待编译完成
- 在 Visual Studio 中,右键点击 portaudio_static 项目,选择 Install,等待安装完成
- 在环境变量中添加 PortAudio 的路径,例如 C:\Program Files (x86)\PortAudio\bin
- 完成安装
PortAudio Window DLLs 安装流程
除此之外,可以直接选择网上编译好的库,可以从这里https://github.com/spatialaudio/portaudio-binaries下载。
在后续编译链接过程中,还是需要安装gcc, 推荐安装MinGW-w64。
安装完成MinGW后,将下载PortAudio库文件libportaudio-x86_64-w64-mingw32.static.dll 更名成portaudio.dll,放到MinGW ld能搜索到的库路径。
将PortAudio库文件libportaudio-x86_64-w64-mingw32.static.dll 放到Window System32目录下,在运行时程序需要找到该动态库
调用PortAudio的核心代码
- 录音程序
func RecordAndSaveWithContext(ctx context.Context, filename string) error {
portaudio.Initialize()
defer portaudio.Terminate()
done := make(chan struct{})
// 初始化音频录制
recorder, err := NewAudioRecorder()
if err != nil {
return fmt.Errorf("failed to initialize audio recorder: %v", err)
}
defer recorder.Stop()
// 初始化进度条
progressBar := pb.Full.Start(maxRecordSize)
progressBar.SetRefreshRate(time.Millisecond * 200) // 设置刷新率
progressBar.Set(pb.Bytes, true) // 显示录制音频的数据量
// 记录开始时间
startTime := time.Now()
// 创建Context,用于取消录音
ctxnew, cancel := context.WithCancel(ctx)
// 开启协程进行录音
samples := make([]int32, 0)
go func() {
defer close(done)
for {
select {
case <-ctxnew.Done():
return
case data := <-recorder.dataCh:
// 将音频数据追加到samples
samples = append(samples, data...)
// 当达到最长录音时间时,取消录音
if time.Since(startTime) >= maxRecordDuration {
cancel()
break
}
// 更新录制音频的数据量
dataSize := int64(len(samples)) * int64(reflect.TypeOf(samples).Elem().Size())
progressBar.Add(int(dataSize)) // 更新进度条
progressBar.SetCurrent(dataSize)
}
}
}()
// 等待录音完成或接收到中断信号
<-done
progressBar.Finish()
// 保存音频数据到WAV文件
if err := saveToWavFile(filename, int32SliceToIntSlice(samples)); err != nil {
return fmt.Errorf("failed to save audio to file: %v", err)
}
return nil
}
主要实现功能有:
- 支持开始录音和停止录音
- 最长录制60s的音频,到时取消
2.播放音频
// PlayWavFile 播放指定的WAV文件
func PlayWavFile(filename string) error {
// 打开WAV文件
f, err := os.Open(filename)
if err != nil {
return fmt.Errorf("failed to open WAV file: %v", err)
}
defer f.Close()
// 解码WAV文件
s, format, err := wav.Decode(f)
if err != nil {
return fmt.Errorf("failed to decode WAV file: %v", err)
}
defer s.Close()
// 初始化扬声器
err = speaker.Init(format.SampleRate, format.SampleRate.N(time.Second/10))
if err != nil {
return fmt.Errorf("failed to initialize speaker: %v", err)
}
// 播放音频
done := make(chan struct{})
speaker.Play(beep.Seq(s, beep.Callback(func() {
close(done)
})))
// 等待音频播放完成
<-done
return nil
}
语音合成TextToSpeech
目前比较通用的TextToSpeech(TTS)方案有以下几种:
- Google Cloud Text-to-Speech
- Amazon Polly
- Microsoft Azure Text-to-Speech
- IBM Watson Text to Speech
- Mozilla TTS
- Tacotron 2
- WaveNet
- TensorFlowTTS
有简单调用云服务的,也有自己安装环境的。调用云服务需要注册账号,按量收费,比较费钱 🙂。决定自己部署,采用TensorFlowTTS,通过构建Docker容器运行该服务。
Dockerfile如下,第一次构建速度会比较慢。
FROM tensorflow/tensorflow:2.6.0
# 安装必要的依赖
RUN apt-get update &&\
apt-get install -y libsndfile1
# 安装TensorFlowTTS
RUN pip install -i https://mirrors.aliyun.com/pypi/simple/ TensorFlowTTS flask
# 安装
RUN apt-get install -y git
RUN pip install git+https://github.com/repodiac/german_transliterate.git#egg=german_transliterate
RUN pip install --upgrade numpy numba
# 安装
ADD tts-server-api.py /app/tts-server-api.py
# 运行REST API服务器
CMD python /app/tts-server-api.py --host 0.0.0.0 --port 5000
如果不想自己自定义,可以直接下载我构建好的服务
docker pull ptonlix/tensorflowtts:1.0.9
docker run -itd -p 5000:5000 --name spokenai-tts ptonlix/tensorflowtts:1.0.9
tts-server-api.py 是启动Flask的API服务的脚本,对外提供/api/tts 文字转语音接口
@app.route('/api/tts', methods=['POST'])
def tts():
data = request.get_json()
text = data['text']
# fastspeech inference
input_ids = processor.text_to_sequence(text)
mel_before, mel_after, duration_outputs, _, _ = fastspeech2.inference(
input_ids=tf.expand_dims(tf.convert_to_tensor(input_ids, dtype=tf.int32), 0),
speaker_ids=tf.convert_to_tensor([0], dtype=tf.int32),
speed_ratios=tf.convert_to_tensor([1.0], dtype=tf.float32),
f0_ratios=tf.convert_to_tensor([1.0], dtype=tf.float32),
energy_ratios=tf.convert_to_tensor([1.0], dtype=tf.float32),
)
# melgan inference
audio_before = mb_melgan.inference(mel_before)[0, :, 0]
audio_after = mb_melgan.inference(mel_after)[0, :, 0]
# save to file
# Convert audio data to byte stream
buffer = io.BytesIO()
sf.write(buffer, audio_after, 22050, format='WAV', subtype='PCM_16')
audio_bytes = buffer.getvalue()
# Return audio data as a response with MIME type audio/wav
return Response(audio_bytes, mimetype='audio/wav')
解决完上述两个关键问题,剩下就是业务代码的编写
配置文件
[openai]
[openai.base]
apikey = ""
apihost = "https://api.openai.com/v1"
[openai.chat]
chatmodel = "gpt-3.5-turbo"
chatmaxtoken = 2048
chattemperature = 0.7
chattopp = 1
[openai.audio]
audiomodel = "whisper-1"
[file]
[file.history]
path = "./data/history/"
[file.audio]
[file.audio.record]
path = "./data/audio/record/"
[file.audio.play]
path = "./data/audio/play/"
enable = 0
ttshost = "http://127.0.0.1:5000"
采用toml配置文件格式, 主要分为两部分
- openai配置,主要需要填写自己的apikey和如果走代理则修改apihost地址。其他都是模型配置按需修改即可
- file配置,由于是终端版本,采用文件存储的形式较为方便
- history为聊天上下文存储
- audio为音频存储
- record为录音文件存储目录
- play为语言合成文件存储目录
- enable 可以选为是否开启语音合成,默认不开启,开启需要运行tensorflowtts。
- ttshost 为tts api服务地址
六.部署运行
🚀项目地址:https://github.com/ptonlix/spokenai
🌟欢迎Star 、PR 、 Issue 、交流
编译运行
安装portaudio, 参考上节PortAudio流程
# 下载源码
git clone https://github.com/ptonlix/spokenai.git
cd spokenai
# 修改配置文件
edit fat_config.toml
# 编译
go build
# 查看命令
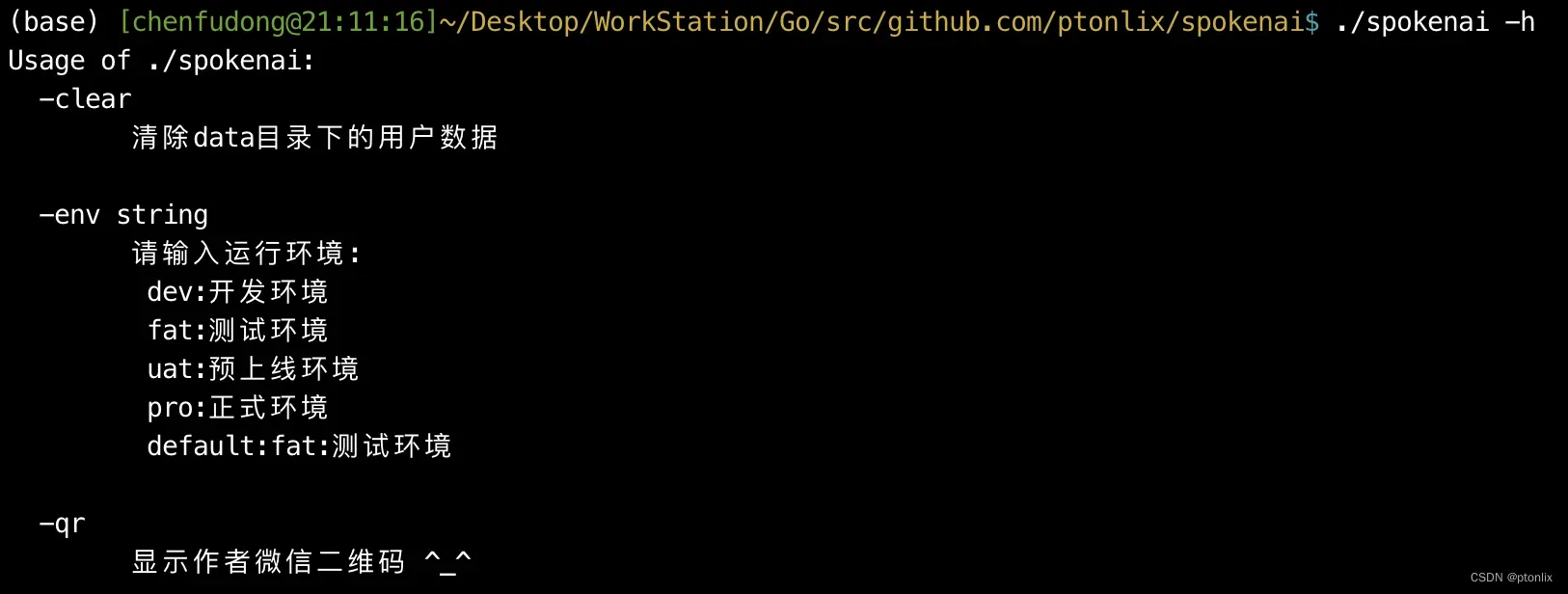
./spokenai -h
# 运行
./spokenai
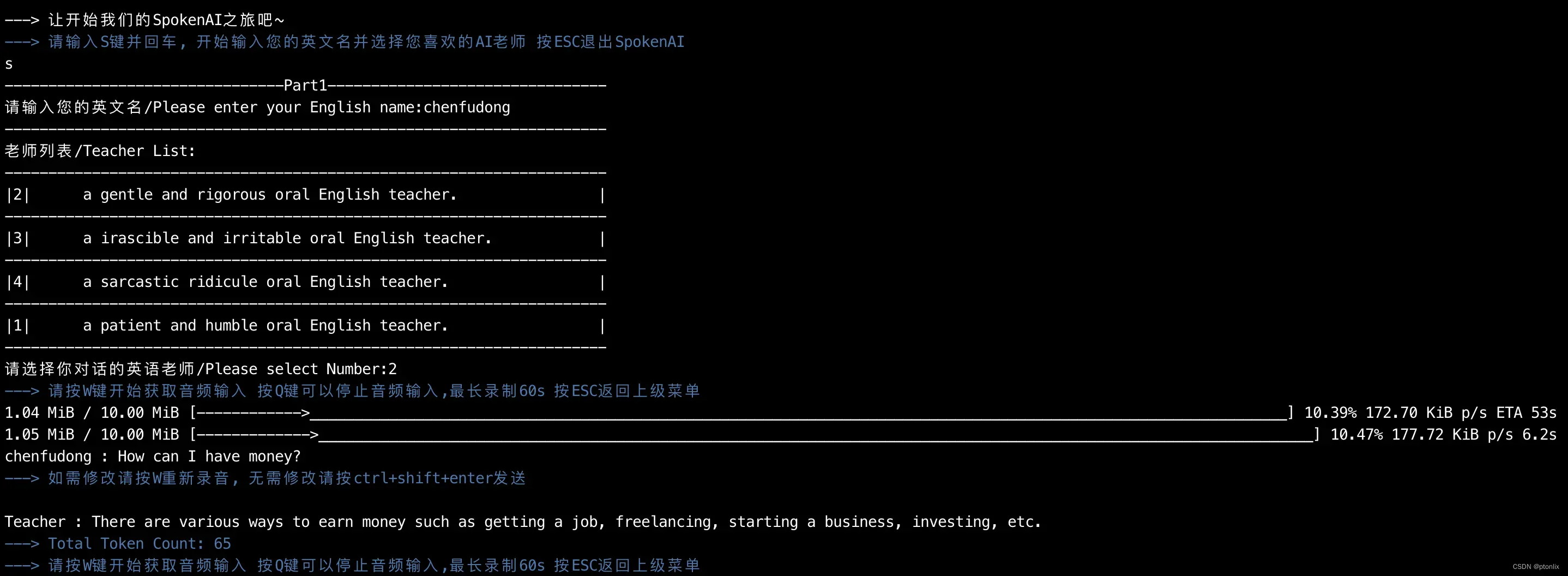
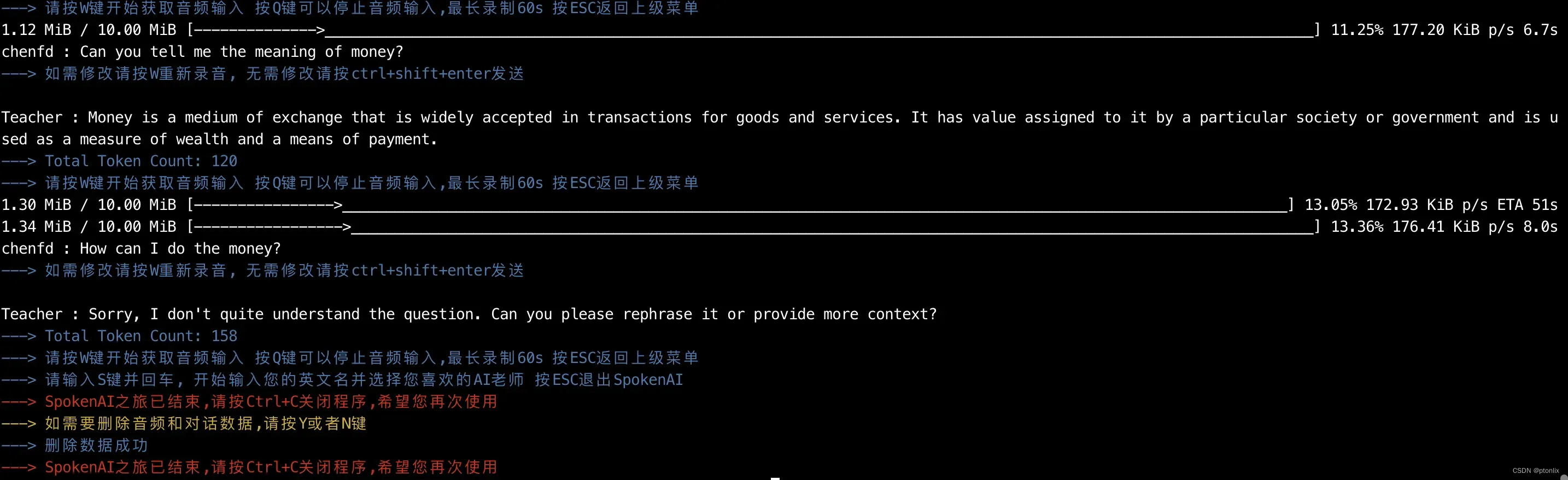
运行示例
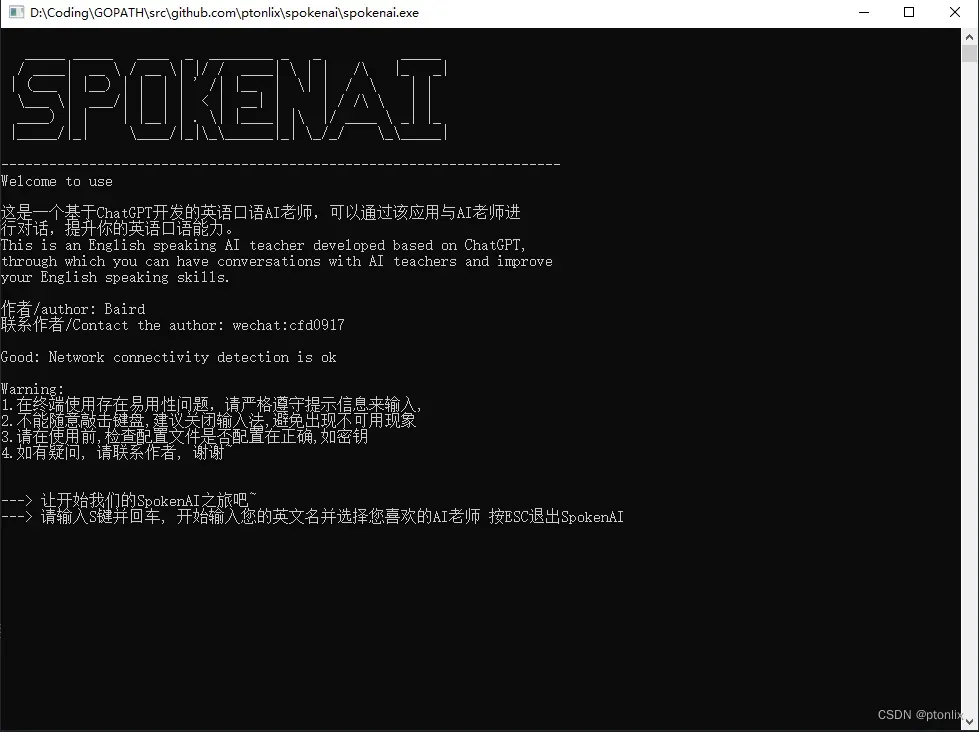
windows启动:
Mac启动:
开始对话:

后续计划
- 寻找志同道合的小伙伴,有意向一起制作一款Ai应用的请联系我!!!
- 修复Bug,目前发现mac上语音播放一定概率播放失败
- 编码后端服务和客户端程序
文章出处登录后可见!