
用于自动驾驶车辆安全验证的密集强化学习
论文标题:
Dense reinforcement learning for safety validation of autonomous vehicles
论文链接:
Dense reinforcement learning for safety validation of autonomous vehicles | Nature

2023年3月22日,清华大学自动化系智能交通团队助理教授封硕(独立一作)与美国密歇根大学Mcity主任Henry Liu教授(通讯作者)等人合作实现了基于强化学习的自动驾驶汽车安全性加速测试,相关研究成果以《Dense Reinforcement Learning for Safety Validation of Autonomous Vehicles》为题发表于《自然》(Nature)正刊,并被选为该期封面论文。
研究背景:在自动驾驶测试中验证安全性的经济和时间成本很高。
验证内容:基于AI的agent进行训练来验证在不会失去无偏性的情况下,自动驾驶汽车在加速模式中的安全表现。
方法论:根据真实驾驶数据, agent通过密集深度强化学习(dense deep-reinforcement-learning,D2RL)来学习执行什么样的对抗策略。通过删除非安全关键状态并重新连接关键状态来编辑马尔可夫决策过程,从而使训练数据中的信息更加密集。D2RL使神经网络能够从具有安全关键事件的密集信息中学习,并实现传统深度强化学习方法难以处理的任务。
实验:结合了仿真和实车实验,在增强现实环境的高速公路和城市测试轨道中对一个高度自动化车辆进行测试。
结论:D2RL训练的agent可以加速多个数量级的评估过程(到
倍)。D2RL还将加速其他安全关键型自主系统的测试和训练。
提高AV安全性能存在的一个关键瓶颈是安全验证的严重低效。主要验证方法通常是通过软件模拟、封闭试验跑道和道路试验相结合的方式,在NDE(自然驾驶环境)中对AV进行试验。为了在人类驾驶员的水平上验证自动驾驶汽车的安全性能,需要在NDE中测试数亿甚至数千亿英里。这种验证方式严重低效,导致开发人员必须付出大量的经济和时间成本来评估每个开发,阻碍了AV部署的进展。现有的基于场景的方法主要适用于具有限制背景的道路使用者的较短场景。
验证AV在NDE中的安全性能本质上是一个高维空间中的罕见事件估计问题。主要的挑战是由除了“维度灾难”之外的“稀有灾难”的复合效应引起的(如下图)。
“维数灾难”:驾驶环境可能是时空复杂的,并且定义这种环境所需的变量是高维的。随着变量空间的体积随维度呈指数增长,计算复杂度也呈指数增长。
“稀有灾难”:安全关键事件的发生概率是罕见的,变量空间的大多数点是非安全关键的,其不提供用于训练的信息或提供噪声信息。在这种情况下,即使给定大量数据,深度学习模型也难以学习,因为安全关键事件的有价值信息(例如策略梯度)可能被隐藏在大量非安全关键数据之下。
本文提出一种密集深度强化学习(D2RL)方法来应对这一挑战。基本思想是识别和删除非安全关键数据,并利用安全关键数据训练神经网络。
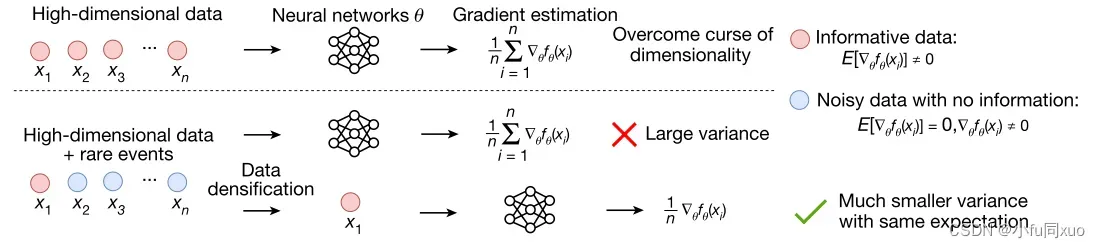
‘curse of rarity’阻碍了深度学习技术在安全关键系统中的适用性,因为神经网络的梯度估计会因为信息数据的稀有而遭受大方差。通过仅使用信息数据训练神经网络,我们的密集学习方法大大降低了梯度估计方差,从而实现了安全关键系统中的深度学习应用。f和E分别表示目标函数和数学期望。
由于只有非常小的一部分数据是安全关键的,因此剩余数据的信息将被大幅加密。D2RL方法通过删除非临界状态并重新连接临界状态来编辑马尔可夫决策过程,然后仅针对编辑后的马尔可夫过程来训练神经网络(如下图b)。

对于任何D2RL训练片段,来自结束状态的奖励沿着仅具有临界状态的编辑的马尔可夫链反向传播(如下图c)。
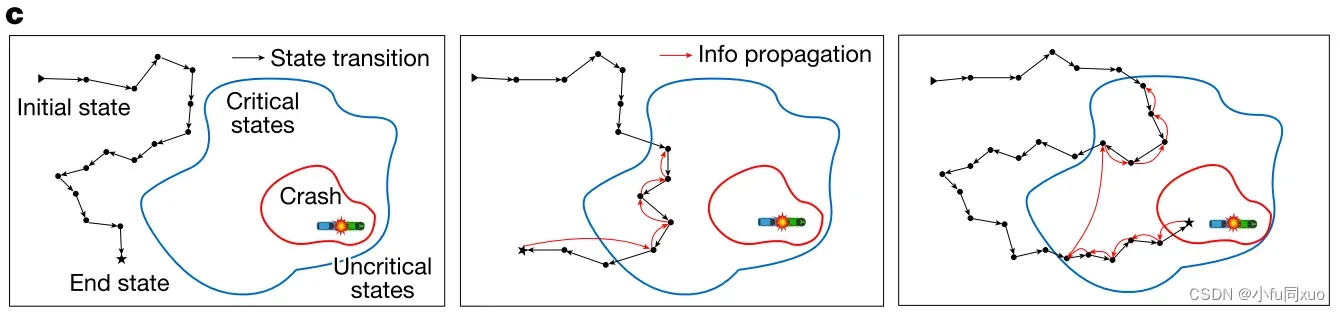
左图中,该事件不包含临界状态,所以将其完全从训练数据中移除。中间和右图能看到包含临界和非临界状态,跳过非临界,只选取从end state开始的反向传播临界状态,重新连接使训练数据密集化。中间的end state来自非碰撞事件,右图的end state来自碰撞事件。
对于AV测试,利用D2RL方法并通过神经网络训练背景车辆(background vehicles,BVs),以学习何时执行何种对抗性机动,旨在提高测试效率并确保评估无偏性。这种测试方法的结果为:基于AI的对抗性测试环境,可以将AV所需的测试里程减少多个数量级,同时确保测试的无偏性。该方法可以应用于复杂的驾驶环境,包括多个高速公路,交叉口和环形交叉口,这是以前的基于场景的方法无法实现的。所提出的方法赋予环境中的智能测试agents创建一个智能测试环境,即使用AI来验证AI。
为了证明基于人工智能的测试方法的有效性,使用大规模自然驾驶数据集训练BV,并在物理测试轨道上进行了模拟实验和现场实验。使用Autoware在美国移动中心(ACM)的4公里长的高速公路测试赛道和Mcity的城市测试赛道上测试了4级自动驾驶汽车。为了在经过D2RL培训的测试环境中安全、准确地测试自动驾驶汽车,开发了一个增强现实测试平台,该平台结合了物理测试轨道和微观交通模拟器SUMO。
如下图d所示,通过同步真实的AV和虚拟BV的移动,物理测试轨道中的真实AV可以与虚拟BV交互,模拟现实交通环境。对于模拟和现场实验,我们不仅评估了碰撞率,而且还评估了碰撞类型和碰撞严重程度。仿真和现场测试结果表明,D2RL方法可以有效地学习智能测试环境,与直接在自然环境中测试AV的结果相比,可以将AV的无偏评价过程显著加快多个数量级(到
倍)。
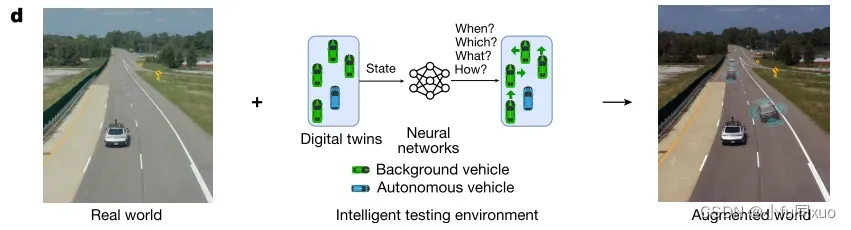
增强现实测试平台可以通过虚拟背景交通来增强现实世界,从而为AV提供更安全,更可控,更高效的测试环境。D2RL决定何时控制哪些背景车辆以何种概率执行何种对抗性机动。
Dense deep reinforcement learning
为了利用AI技术,该研究将AV测试问题表述为一个顺序的马尔可夫决策过程(MDP),其中BV的操作是由当前的状态信息决定的。该研究的目标是训练一个由神经网络建模的策略(DRL agent),他能控制BV和AV进行交互,最大限度地提高评价效率并保证无偏性。然而,受维数和计算复杂度的限制,如果直接应用 DRL 方法,很难甚至根本无法学习有效策略。
由于大多数状态都是非关键的,无法为安全关键事件提供信息,因此 D2RL 的重点是去除这些非关键状态的数据。对于 AV 测试问题,可以利用许多安全指标来识别具有不同效率和有效性的关键状态。该研究利用的关键性度量指标是当前状态特定时间范围内(例如1秒)AV 碰撞率的外部近似值。然后该研究编辑了马尔可夫过程,丢弃非关键状态的数据,并将剩余数据用于 DRL 训练的策略梯度估计和 Bootstrap。
为了证明D2RL的有效性,本文将D2RL与DRL方法进行了比较,以解决异常问题(corner-case-generation problem),它可以被表述为一个定义明确的强化学习问题。训练一个神经网络,通过控制最近的八个BV的动作来最大化AV的碰撞率。
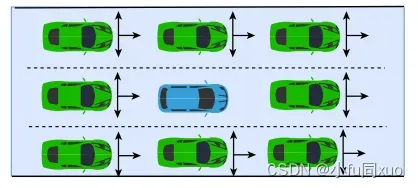
神经网络控制120 m内最近8辆车的操纵,其中每个BV每0.1s有33个离散动作:左变道、31个离散纵向加速度([-4,2],离散分辨率为0.2 m /s2)和右变道。
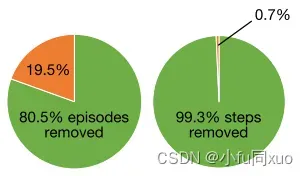
我们使用邻近策略优化(proximal policy optimization,PPO)来更新策略网络的参数,给定每个测试片段的奖励, AV碰撞为+20,其他为0。DRL和D2RL之间的唯一区别是DRL用所有数据来训练神经网络,而D2RL仅利用临界状态的数据。如下图,与DRL相比,D2RL从非临界状态中去除了80.5%的完整发作和99.3%的步骤的数据。
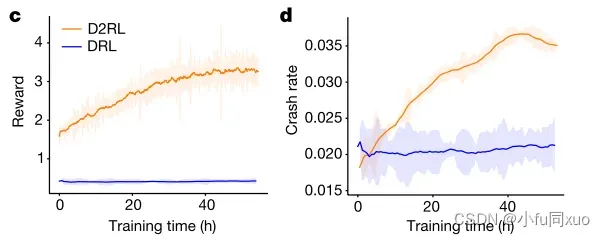
D2RL可以在训练过程期间最大化奖励,而DRL从训练过程开始就被卡住。D2RL学习的策略可以有效地增加AV的碰撞率,而DRL未能做到这一点。
e-g是三组corner case。其中,e是AV为躲避一辆切入的车辆而进行了躲避性变道,但与相邻车辆相撞;f是右前车做了切入,左后车做了右变道,右后车则加速。这三种车辆合作包围了AV,引发事故;g是右前车辆切入以强制AV进行制动,这为右后车辆在2.8秒(即28个非关键步骤)后变道创造了机会,导致撞车。

Learning the intelligent testing environment
学习智能测试环境以进行无偏见和有效的AV评估比生成corner case要复杂得多。根据importance sampling theory,目标是学习新的抽样分布,即操纵BV以取代它们自然分布的一个重要函数,其目的是最小化AV测试的估计方差。对BV进行训练,以学习何时执行什么对抗性操纵,因为所有BV都遵循自然行为,只有选定的车辆在选定的时刻根据学习的概率执行专门设计的对抗性移动。
从估计方差导出奖励函数为:
表示每个测试事件的变量,
是AV碰撞事件(A)的指示函数,
和
是由重要性抽样产生的权重(或可能性)。
表示自然分布,
表示具有目标策略
的函数,
表示具有行为策略
的函数。较高的奖励值代表更有效的测试环境。这种奖励设计也适用于其他高维变量的稀有事件估计问题。
定理2证明在训练过程中收集数据的最优行为策略与目标策略几乎成反比。研究表明,如果使用on-policy ,行为策略将远离最优,这可能会误导训练过程,最终导致低估问题。所以使用off-policy,设计了一个通用的行为策略
,在训练过程中保持不变。
AV testing in simulation
通过系统的仿真分析,评估了基于D2RL的智能测试环境在准确性、效率、可扩展性和通用性等方面的有效性。NDE中不同碰撞类型和严重程度的碰撞率被作为基准。由于NDE完全基于自然驾驶数据生成,因此NDE中的测试结果可以代表真实的世界中的AV的安全性能。对于每一个测试集,模拟AV驾驶在交通中一个固定的距离,然后记录和分析测试结果。为了研究该方法的可扩展性和通用性,我们对不同的道路几何形状、不同的行驶距离和两种不同类型的自动驾驶模型(AV-I和AV-II)。以下是AV-I模型在400米行驶距离的双车道公路环境下的结果。
如图a所示,在训练过程中,AI环境的估计方差随着奖励函数的增大而减小,证明了等式(1)中的奖励函数的有效性。
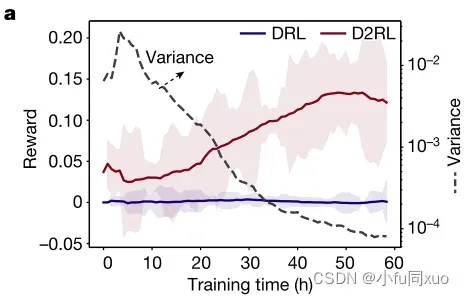
DRL和D2RL方法reward的比较。 D2RL方法的估计方差(虚线)表示测试效率;实线表示移动平均值;阴影区域表示标准偏差。
如图b所示,在训练过程期间,on-policy实验的碰撞概率持续增加,但off-policy的碰撞概率基本不变,因为行为策略不变。然而,由于on-policy打破了奖励函数和估计方差之间的一致性,所以碰撞率的增加是误导的。
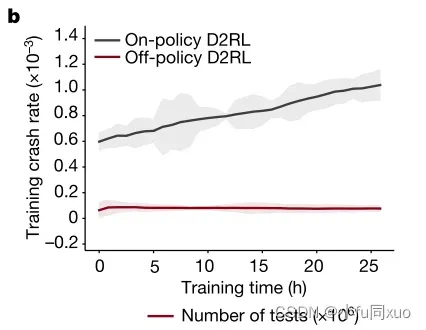
如图c-e所示,基于on-policy的测试环境低估了碰撞率。off-policy可以获得与NDE方法相同的碰撞率,但比NDE方法更有效。阴影区域表示90%置信水平(confidence level),实线表示平均值。
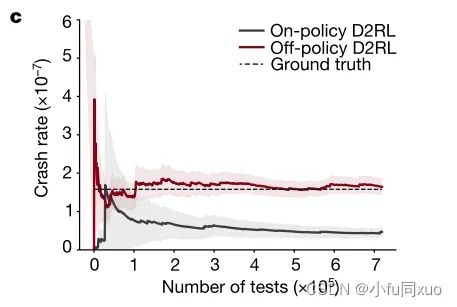
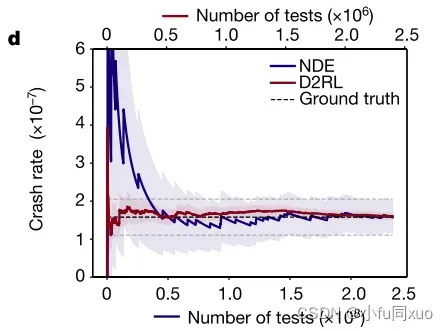
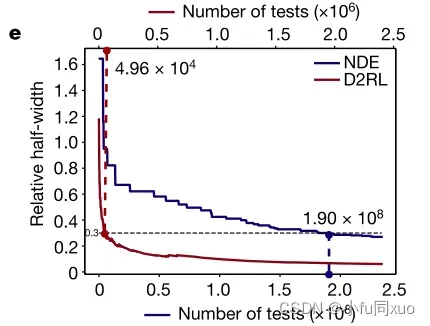
为了测量效率,计算了达到预定精度阈值的最小测试次数(相对半宽度为0.3)。通过NDE和基于D2RL的AI环境对AV-I模型的碰撞率估计(d)和相对半宽度(e)。底部x轴表示NDE的测试数量,顶部x轴表示AI环境的测试数量。阴影区域表示90%置信水平,实线表示平均值(d)。虚线表示0.3相对半宽,数字表示达到0.3相对半宽(e)所需的试验次数。
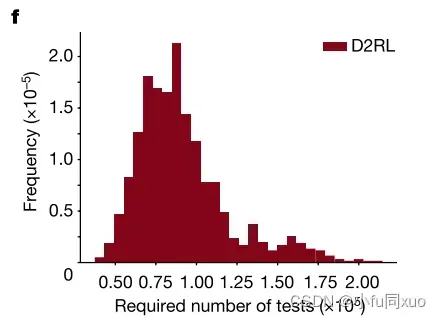
为了减少结果的随机性,通过自助采样(bootstrap sampling)重复测试,并获得了所需测试次数的频率和平均值(图f,重复测试实验所需测试次数的频率)。
与需要1.9 × 108次测试的NDE方法相比,本文提出的方法需要平均9.1 × 104次测试,快了2.1 × 103倍。为了研究可推广性,使用相同的智能测试环境进一步测试了AV-II模型,这也可以以大约103倍的速度获得准确的估计。
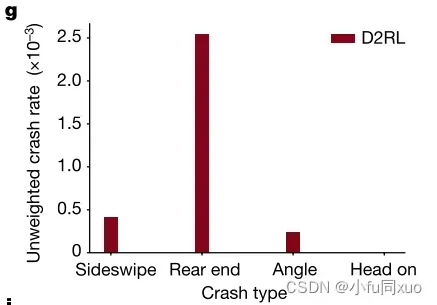
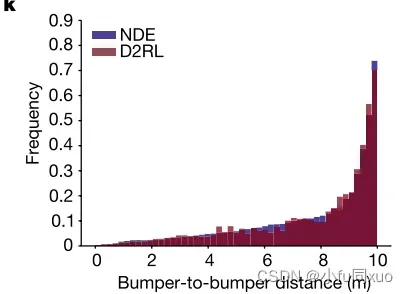
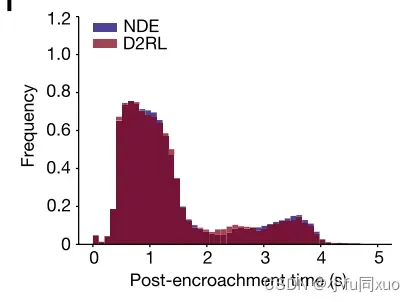
为了验证碰撞类型、碰撞严重程度和未遂事件的无偏性,本文分析了不同碰撞类型的碰撞率、碰撞时刻的速度差分布、碰撞时间的分布、保险杠到保险杠的距离和未遂事件的后侵入时间(PET)。全文所述的无偏性是指,本文方法测试的估计值与NDE测试的估计值有相同的数学期望。本实验采集了大约2.34 × 次NDE测试和3.15 ×
次(大约少了两个数量级)AI环境测试。由于AI环境比NDE更具对抗性,因此本文方法中的总碰撞率为3.21 ×
(图3g),远高于NDE中的总碰撞率1.58 ×
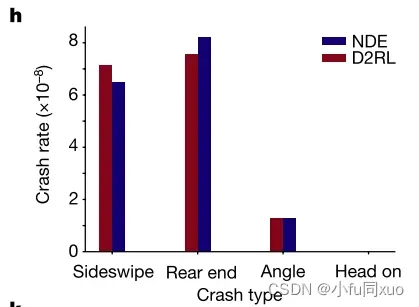
。根据重要性采样定理的要求,每个碰撞事件都要用似然比进行加权,以保持无偏性。因此,将所有碰撞类型的加权碰撞率与NDE结果进行比较。图g未加权碰撞率,图h加权碰撞率对比。
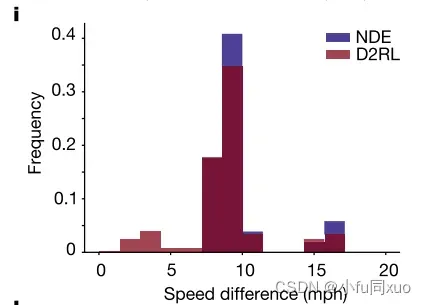
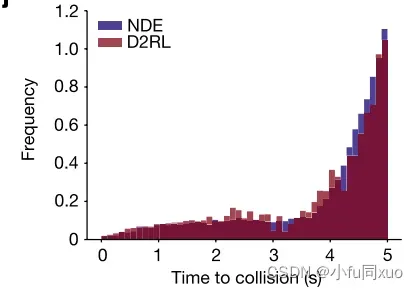
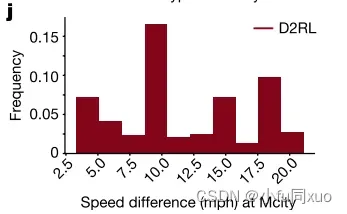
下图分别是碰撞时刻(i)、碰撞时间(j)、保险杠间距离(k)和未遂事件后侵入时间(l)的速度差的加权分布。它们表明,本文方法还可以在评价精度范围内无偏评估AV关于碰撞严重性和未遂事件的安全性能。由于未遂事件对于AV的发展至关重要,因此在不损失无偏性的情况下生成的未遂事件为加速AV训练打开了大门,成为了接下来的研究方向。
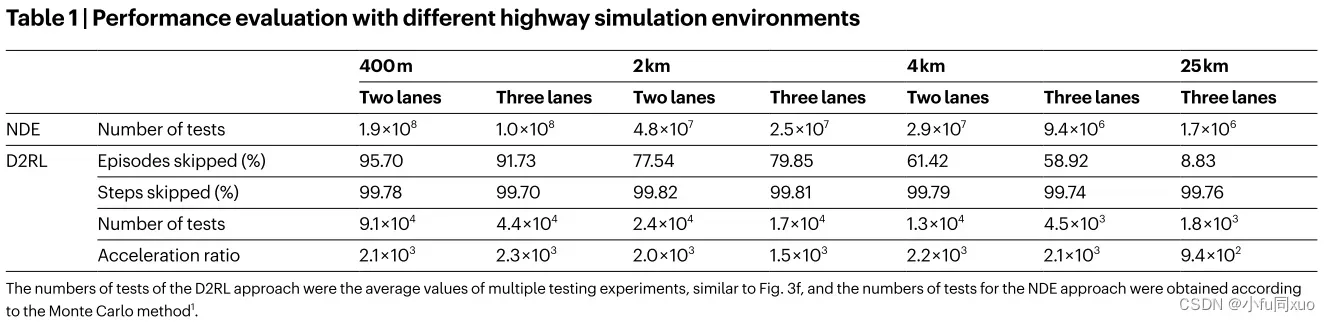
为了进一步研究的可扩展性和普遍性,本文进行了不同数量的车道(两个和三个车道)和驾驶距离(400米,2公里,4公里和25公里)的AV-I模型的实验。在美国,通勤者平均单程旅行约25公里,所以本文用25公里的实验来证明本文方法在长行程的有效性。如表1所示,由于跳过的片段和步骤大大减少了训练方差,本文方法可以有效地学习所有实验的AI环境。
在真实场景中德国的四臂环形交叉路口进行实验,该场景交通量大,相互作用复杂。与需要约8.91 × 次测试才能达到30%相对半宽的NDE方法相比,本文方法只需要3.76 ×
次测试,快了2.37 ×
倍。
AV testing in test tracks
自动驾驶系统:Autoware
AV:林肯MKZ混合动力车(图a)
测试环境:ACM长度4公里的多车道高速公路测试场地(图b)和Mcity的城市物理试验场(图c)
测试平台:自行开发的现实增强测试平台,结合了真实测试环境和模拟环境SUMO。
使用与仿真研究类似的训练设置,在ACM公路路段和Mcity城市路段的数字孪生中训练智能测试环境。图c中爆炸图标表示测试期间发生的碰撞事件的位置。
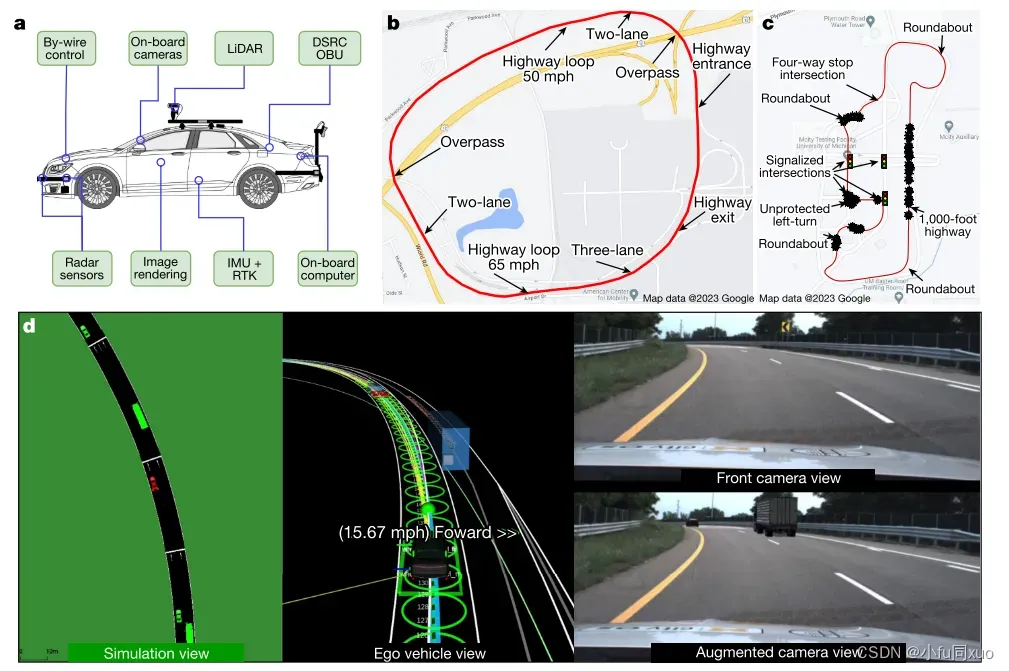
图d为测试过程的实时可视化图示。左:模拟视图,其中虚拟BV(绿色车辆)由AI测试环境生成和控制,以与AV(红色车辆)进行交互。中间:由Autoware可视化的真实世界AV视图,其中黑色车辆是测试中的AV,蓝色车辆是增强的BV。右:来自AV前置摄像头的原始图像视图(上)和增强图像视图(下)。
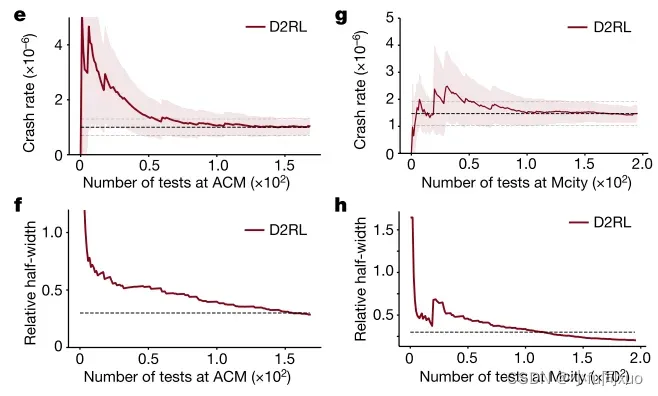
碰撞率估计收敛并达到0.3的相对半宽度,ACM需要156次(图4e、f),Mcity需要117次(图4g、h),比NDE测试快倍(ACM2.5 ×
次,Mcity2.1 ×
次。黑色虚线(e,g)表示碰撞率的最终估计,灰色虚线(e,g)表示碰撞率的30%相对误差,灰色虚线(f,h)表示0.3相对半宽阈值,阴影区域(e,g)表示90%置信水平。
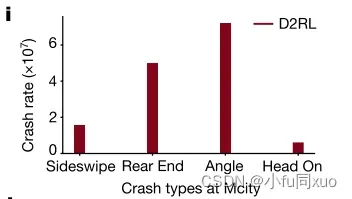
同时还评估了AV在不同碰撞类型和严重程度下的安全性能。图i,在Mcity中AV的不同碰撞类型的碰撞率。图j,在Mcity中AV碰撞严重度分析的碰撞瞬间速度差分布。
本文提出了使用D2RL验证AV在行为能力方面的安全性能的方法。将D2RL用于加速测试过程,同时还可用于模拟测试和测试跟踪方法。D2RL可以大大增强现有的测试方法(falsification methods, scenario-based methods and NDE methods),以克服其在现实世界中应用的局限性。
本篇文章是第一篇被刊出在nature并且作为封面自动驾驶相关论文,可以说是自动驾驶测试的一个里程碑!文中提出的D2RL方法给出了详细的推理和证明过程,并且提供了极为丰富的真实测试数据,值得反复精读学习!!!该项目也已经在github上开源,可以尝试进行复现。
项目链接:
文章出处登录后可见!