本节开始笔者针对自己的研究领域进行RL方面的介绍和笔记总结,欢迎同行学者一起学习和讨论。本文笔者来介绍RL中比较出名的算法PPO算法,读者需要预先了解Reinforcement-Learning中几个基础定义才可以阅读,否则不容易理解其中的内容。不过笔者尽可能把它写的详细让读者弄懂。本文干货内容较多,注重算法理解和数学基础而不仅仅是算法实现。
本文一定程度上参考了李宏毅”Reinforcement-Learning”
本文内容不难,适合想要学习RL的初学者进行预备,PPO是OpenAI的默认RL框架,足以见得它的强大。
1、预备知识
1.1、策略梯度
首先笔者来介绍策略梯度算法,为后续的内容做铺垫,首先给予读者一些RL中基本定义:
1.State:状态,也即智能体(Agent)当前所处的环境是什么?
2.Action:动作,也即Agent在当前可以采取的行动是什么?(该行为我们可以通过网络可控)
3.Reward:奖励,也即Agent在当前状态下采取动作Action后得到了多大的奖励?
首先,设置Agent采取的总步长为,这也即我们获得了一条轨迹(trajectory):
:
事实上,上述的1,2,3中我们只有2是可控的,其他的1,3为从环境中获取的,是无法人为干预的。假设我们拥有一个具有网络参数为的策略
,那么显然我们的目标是想要使得总Reward越大越好,但由于该奖励为一个随机变量,因此我们只能求得它的期望。即target任务为最大化以下函数:
为了让上述期望最大化,我们需要策略梯度,即:
以下简称策略梯度,由上述推导我们可知:
由于,故代入有:
因此,在实际应用的时候,用sampling的办法,应该做一些的更新方式(为学习率):
但是,该存在以下的缺陷。
1.1.1、策略梯度缺陷(1)
首先针对而言,直观的理解为,若某一条轨迹
得到的奖励总和
为正(positive)的,那么该策略梯度会升高产生这条轨迹的每一步骤产生的概率大小,若
得到的奖励总和
为负(negative)的,那么该策略梯度会降低产生该条轨迹的概率大小,但若奖励总和
总为positive的,那该策略梯度会受到一定的影响。虽然Reward的大小可以反应策略梯度上升的快慢大小,但是由于动作是通过Sample来获取的,因此会产生某些”好的动作”没办法被偶然采样到,那么该好的动作就容易被忽略掉。因此一般会采用以下更新策略梯度方式来更新,保证
有正有负。
其中为待定参数,可以为人工设定或者其他办法获得。
1.1.2、策略梯度缺陷(2)
策略梯度的缺陷之二是:针对,更新时刻每一步,他们共用一个
,这会带来很大的问题,因为显然地,一个轨迹的总Reward高不见得每一步的Reward都要求的是好(高)的并且完美的,而是一个整体的现象。如果单纯用一整条轨迹更新轨迹中每个操作显得很不满足条件。
因此,常见的处理办法之一为:采用未来折扣回报来代替:
其中第步时的未来折扣回报的定义为:
,代表了从第
步到结束的带有折扣因子
的未来总奖励大小。
因此策略梯度被写成了如下情况:
往往,某些时刻,我们可以将未来折扣回报视为在当前
下,采取了动作
,未来给了我多少奖励,也即当前状态
下,采取了动作
的好坏程度,这通常称之为状态价值函数,一般用
来表示,通常情况下,未来折扣回报是通过
来进行估计的,若将其也视为一个网络,参数为
,这即:
则想要更新参数时,可以首先采样出一系列轨迹,并进行策略梯度的更新:
当然,这是针对某一个整条轨迹做更新的,那么如果想要按照时间步长逐步更新(第
步):
这也即采样了一个Batch的第
步的
信息后,进行的梯度更新:
策略梯度有个明显的缺点,就是更新过后,网络
就发生了改变,而策略梯度是要基于
进行采样的,因此,之前的采样样本就失效了,也即参数只能被更新一次,之后需要根据更新后的重新采集样本。这显然用起来非常不方便,理想情况下如果能够进行off-policy更新,即某个样本可以被反复更新而不需重采样,这就需要1.2的重要性采样过程。
1.2、Important-Sampling
设需要估计,但是无法从
中进行sampling,只能从一个以知的分布
进行采样,那如何计算所要求的期望?
事实上:
即
这是理论相等,但是存在如下问题:
很明显若,此时
即,若通过采样的办法,两个分布的差异不能太大,若进行的话,采样是不准确的,甚至是失真的。
为了可以用到RL中进行off-policy的更新,我们需要定义两个策略网络,一个是专门负责进行采样操作,一个是
,为待学习的网络参数,相应的,还存在两个价值网络,一个参数为
负责给予探索的动作打分,一个参数为
为待学习的参数,则此时
根据Important-Sampling原理可进行如下替换,并且可以更新多步而不局限于更新一次:
进行整理后得到:
若目标函数称为为,令
则
那么,每一次主需要计算,在第
步进行更新即可:
2、置信策略优化(TRPO)与近端策略优化(PPO)
2.1、TRPO与PPO的区别
根据1节所讨论的部分,下面介绍这两种算法的本质区别,在1.2节已经提到了,要想使用Important-Samlping办法,那么两个策略网络的差异不能够太大,否则将会出现估计失真的情况。根据此,TRPO的策略优化函数需要满足以下两个条件为:
其中为超参数,这很麻烦,因为不仅需要进行策略梯度更新,还需要进行条件约束,相比之下,PPO采用了罚函数办法:
当发现,此时说明两个分布差异过大,需要增大惩罚系数,此时
当发现,此时说明两个分布差异很小,需要调小惩罚系数,此时
2.2、Clip-PPO
OpenAI给出了另外一种裁剪PPO,下面笔者来介绍它的具体思想。
上面已经介绍过了,PPO的目的是为了缓解Important-Sampling差异较大带来的影响,若不加以任何限制,原始的目标优化函数为:
现分成两种情况来介绍:
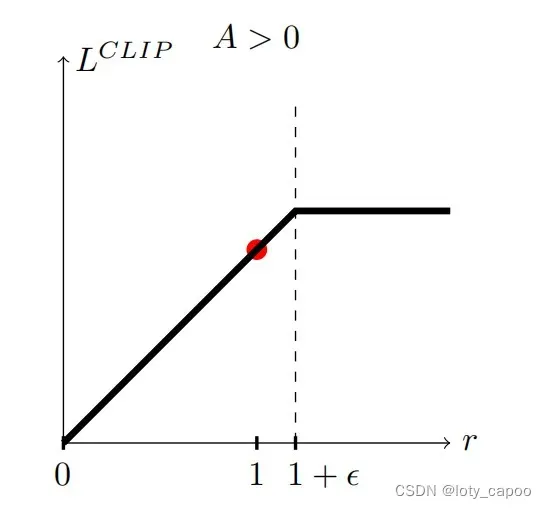
(1)
此时说明,这个动作很好,应该加大该的概率,那么这个时候显然的,会增大对应的
的概率,为了避免出现该值过分的增大,OpenAI提出了Clip方法,即设定一个上限
不允许超过。
即:
对应的图示情况为:(A即为这里的Q)
3、总结
PPO思想还是很简单的,主要是针对Important-Sampling产生的不稳定性进行了CLIP操作和罚函数法,相比TRPO方法更简单容易实现,有了策略梯度的定义,可以结合其他Actor-Critic进行联合使用更新,并且PPO将策略梯度缺陷的on-policy变为了off-policy,更大可能的利用了采样样本,效率和速度都有了一定的提升。
文章出处登录后可见!