一、前言
1、requests简介
requests是一个很实用的Python HTTP客户端库,爬虫和测试服务器响应数据时经常会用到,它是python语言的第三方的库,专门用于发送HTTP请求,使用起来比urllib更简洁也更强大。
2、requests库的安装
方法1:命令行安装
- windows操作系统:pip install requests
- Mac操作系统:pip3 install requests
- Linux操作系统:sodo pip install requests
方法2:源码安装
- 下载 requests源码 http://mirrors.aliyun.com/pypi/simple/requests/
- 下载文件到本地之后,解压到Python安装目录,之后打开解压文件
- 运行命令行输入python setup.py install 即可安装
二、常用方法
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | requests.request(url) | 构造一个请求,支持以下各种方法 |
| 2 | requests.get() | 发送一个Get请求 |
| 3 | requests.post() | 发送一个Post请求 |
| 4 | requests.head() | 获取HTML的头部信息 |
| 5 | requests.put() | 发送Put请求 |
| 6 | requests.patch() | 提交局部修改的请求 |
| 7 | requests.delete() | 提交删除请求 |
其中最常用的方法为get()和post(),分别用于发送Get请求和Post请求。
三、常用属性
| 序号 | 属性或方法 | 描述 |
|---|---|---|
| 1 | response.status_code | 响应状态码 |
| 2 | response.content | 把response对象转换为二进制数据 |
| 3 | response.text | 把response对象转换为字符串数据 |
| 4 | response.encoding | 定义response对象的编码 |
| 5 | response.cookie | 获取请求后的cookie |
| 6 | response.url | 获取请求网址 |
| 7 | response.json() | 内置的JSON解码器 |
| 8 | Response.headers | 以字典对象存储服务器响应头,字典键不区分大小写 |
四、发送请求
1、发送GET请求
1) 不带参数的请求
import requests
#定义百度URL,获取百度首页
url = "http://www.baidu.com"
#使用GET发起请求
res = requests.get(url)
#将返回对象的2进制数据进行解码并输出(根据响应解过中的HTML头判断编码类型)
print(res.content.decode("UTF-8"))
2) 带参数的请求
将参数放在URL中进行请求:
import requests
#将参数name和age拼接到URL中进行请求
res = requests.get(http://httpbin.org/get?name=gemey&age=22)
#输出返回对象的文本结果
print(res.text)
将参数写在字典中进行请求:
import requests
#将参数name和age定义到字典params中
params={
"name":"tony",
"age":20
}
url="http://httpbin.org/get"
#发送请求参数
res = requests.get(url=url,params=params)
#输出返回对象的文本结果
print(res.text)
自定义HTTP头信息进行请求:
import requests
# 将参数name和age定义到字典params中
params = {
"name": "tony",
"age": 20
}
url = 'http://httpbin.org/get'
# 定义HTTP头信息,cookie,UA和referer
headers = {
"User-agent": "Mozilla/5.0 (Linux; Android 8.1.0; SM-P585Y) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36",
"referer": "https://www.abidu.com",
"Cookies": "1234565678"
}
# 发送请求参数
res = requests.get(url = url,params = params,headers = headers)
# 输出返回对象的文本结果
print(res.text)
2、发送POST请求
POST请求一般用于提交参数,所以直接进行有参数的POST请求测试。
import requests
# 将参数name和age定义到字典params中
params = {
"name": "tony",
"age": 20
}
url = 'http://httpbin.org/post'
# 定义HTTP头信息
headers = {
"User-agent": "Mozilla/5.0 (Linux; Android 8.1.0; SM-P585Y) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36",
"referer": "https://www.abidu.com",
"Cookies": "username=user1&passwd=passwd"
}
# 发送请求参数
res = requests.post(url = url,params = params,headers = headers)
# 输出返回对象的文本结果
print(res.text)
五、读取内容
requests对象的get和post方法都会返回一个Response对象,这个对象里面存的是服务器返回的所有信息,包括响应头,响应码等。
上面提到了,对于request,常用的属性有content、text、json、cookie等。content和text两者区别在于,content中间存的是字节码,而text中存的是Beautifulsoup模块根据猜测的编码方式将content内容编码成字符串后的结果。
直接输出content,会发现前面存在b’这样的标志,这是字节字符串的标志,而text是没有前面的b,对于纯ascii码,这两个可以说一模一样,对于其他的文字,需要正确编码才能正常显示。
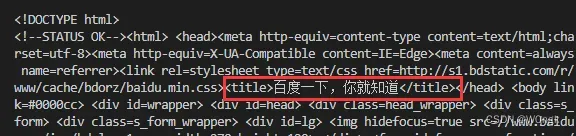
大部分情况下,我们可以直接使用text,但是当有中文的时候,直接使用text会显示乱码,所以需要使用content对象来手动进行解码后才能正常显示。
而json属性则是利用内置的json解析模块解析json数据。
cookie属性则是直接获取响应头中的cookie。
1、以content方式读取
import requests
url = "http://www.baidu.com"
res = requests.get(url)
#不进行解码,直接输出
print(res.content)
输出结果:
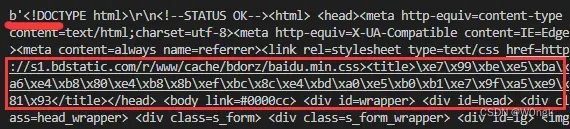
进行解码后输出:
2、以text方式读取
import requests
url = "http://www.baidu.com"
res = requests.get(url)
print(res.text)
输出结果: 中文存在乱码
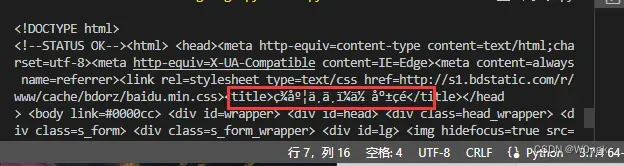
3、读取json数据
import requests
params = {
"name": "tony",
"age": 20
}
url = 'http://httpbin.org/get'
headers = {
"referer": "https://www.abidu.com",
"Cookies": "1234565678"
}
res = requests.get(url = url,params = params,headers = headers)
print(res.cookies)
输出结果:将json数据转换为字典进行输出
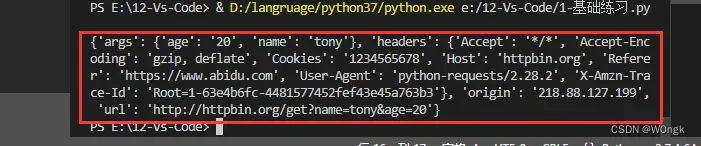
4、获取cookies
import requests
url = 'https://www.baidu.com'
res = requests.get(url = url)
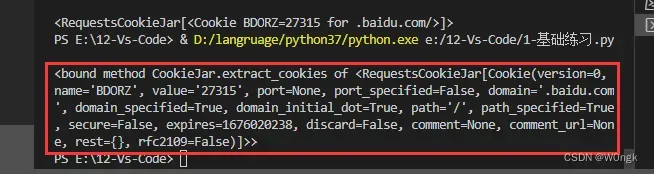
print(res.cookies.extract_cookies)
读取cookie时,直接使用reponse.cookie会返回一个RequestsCookieJar对象,不会直接显示cookie的信息,所以需要再使用extract_cookies属性对该对象进行解析,结果如下:
六、其他方法
1、设置超时退出
可以通过timeout属性设置超时时间,一旦超过这个时间还没获得响应内容,就会提示错误。
import requests
url = 'https://www.baidu.com'
#设置超时时间上限为1s
res = requests.get(url = url,timeout=1)
print(res.content.decode("UTF-8"))
2、异常处理
import requests
url = 'https://www.baidu.com'
#设置超时时间上限为1s,并使用try语句处理异常
try:
res = requests.get(url = url,timeout=1)
print(res.content.decode("UTF-8"))
except exceptions.Timeout as e:
print(e)
except exceptions.HTTPError as e:
print(e)
3、设置代理
代理格式: proxies = { ‘协议’:‘协议://IP:端口号’}
提示: 当我们抓取的地址为http时,使用http代理,反之使用https代理
示例:
import requests
url = 'https://www.baidu.com'
#使用字典定义代理
proxies={
'http':'http://123.45.67.76:8888'
'https':'http://123.45.67.76:4433'
}
#设置超时时间上限为1s,并使用try语句处理异常
try:
res = requests.get(url = url,timeout=1,proxies=proxies)
print(res.content.decode("UTF-8"))
except exceptions.Timeout as e:
print(e)
except exceptions.HTTPError as e:
print(e)
4、使用Session进行会话管理
直接 requests.get() 或者 requests.post() 发送GET请求或POST请求;当然也是可以带上 cookies 和 headers 的,但这都是一次性请求,你这次带着cookies信息,后面的请求还得带。如果使用sessionl来发起请求,session实例在请求了一个网站后,对方服务器设置在本地的cookie会保存在session中,下一次再使用session请求对方服务器的时候,会带上前一次的cookie,从而实现回话保持。
import requests
#使用session,需要先实例化一个session对象。
session = requests.session()
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36",
'Referer': "https://creator.douyin.com/"
}
url = "https://sso.******.com/get_qrcode/?next=https:%2F%2Fcreator.douyin.com%2Fcreator-micro%2Fhome&aid=2906&service=https:%2F%2Fcreator.douyin.com&is_vcd=1&fp=ktv0uumo_gD7FPCuy_MfX7_44zL_9T1C_6i8sUgr4bDT6"
data1 = {
"name" : "test",
"passwd" : "passwd"
}
data2 = {
"name" : "test",
"age" : 20
}
#使用session对象发起请求,进行登录。
try:
res = session.get(url = url,timeout=1,headers = headers,data=data1)
print(res.json())
#使用的登录后的session对需要登录的操作再次发起请求。
res2 = session.post(url,data=date2)
except exceptions.Timeout as e:
print(e)
except exceptions.HTTPError as e:
print(e)
文章出处登录后可见!