
01 运行方式
本文示例代码使用的Python版本为Python 3.6。运行Python代码有两种方式:
一种方式是启动Python,然后在命令窗口下直接输入相应的命令;
另一种方式就是将完整的代码写成.py脚本,如hello.py,然后在对应的路径下通过python hello.py执行。
hello.py脚本中的代码如下:
#hello.py
print(‘Hello World!’)
脚本的执行结果如图所示。
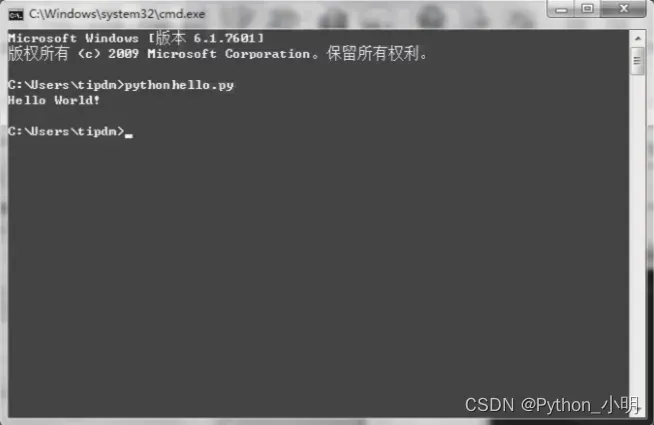
▲Hello.py脚本执行结果
在编写脚本的时候,可以添加适当的注释。在每一行中,可以用井号“#”来添加注释,添加单行注释的方法如下:
a = 2 + 3 # 这句命令的意思是将2+3的结果赋值给a
如果注释有多行,可以在两个“‘’’”(三个英文状态单引号)之间添加注释内容,添加多行注释的方法如下:
pythona = 2 + 3
#这里是Python的多行注释。
#这里是Python的多行注释。
如果脚本中带有中文(中文注释或者中文字符串,中文字符串要在前面加u),那么需要在文件头注明编码,并且还要将脚本保存为utf-8编码格式,注明编码的方法如下:
02 基本命令
1. 基本运算
初步认识Python时,可以把它当作一个方便的计算器来看待。读者可以打开Python,试着输入代码清单1所示的命令。
代码清单1:Python基本运算
a = 2
a \* 2
a \*\* 2
代码清单1所示的命令是Python几个基本运算,第一个命令是赋值运算,第二个命令是乘法运算,最后一个命令是幂运算(即a2),这些基本上是所有编程语言通用的。不过Python支持多重赋值,方法如下:
a, b, c = 2, 3, 4
这句多重赋值命令相当于如下命令:
a = 2
b = 3
c = 4
Python支持对字符串的灵活操作,如代码清单2所示。
代码清单2:Python字符串操作
s = ‘I like python’
s + ’ very much’ # 将s与’ very much’拼接,得到’I like python very much’
s.split(’ ') # 将s以空格分割,得到列表\[‘I’, ‘like’, ‘python’\]
2. 判断与循环
判断和循环是所有编程语言的基本命令,Python的判断语句格式如下:
if 条件1:
语句2
elif 条件3:
语句4
else:
语句5
需要特别指出的是,Python一般不用花括号{},也没有end语句,它用缩进对齐作为语句的层次标记。同一层次的缩进量要一一对应,否则会报错。下面是一个错误的缩进示例,如代码清单3所示。
代码清单3:错误的缩进
if a==1:
print(a)# 缩进两个空格
else:
print(‘a不等于1’)# 缩进三个空格
不管是哪种语言,正确的缩进都是一个优雅的编程习惯。
相应地,Python的循环有while循环和for循环,while循环如代码清单4所示。
代码清单4:while循环
s,k = 0,0
while k < 101:# 该循环过程就是求1+2+3+…+100
k = k + 1
s = s + k
print(s)
for循环如代码清单5所示。
代码清单5:for循环
s = 0
for k in range(101): # 该循环过程也是求1+2+3+…+100
s = s + k
print(s)
这里我们看到了in和range语法。in是一个非常方便而且非常直观的语法,用来判断一个元素是否在列表/元组中;range用来生成连续的序列,一般语法为range(a, b, c),表示以a为首项、c为公差且不超过b-1的等差数列,如代码清单6所示。
代码清单6:使用range生成等差数列
s = 0
if s in range(4):
print(‘s在0, 1, 2, 3中’)
if s not in range(1, 4, 1):
print(‘s不在1, 2, 3中’)
3. 函数
Python用def来自定义函数,如代码清单7所示。
代码清单7:自定义函数
def add2(x):
return x+2
print(add2(1)) # 输出结果为3
与一般编程语言不同的是,Python的函数返回值可以是各种形式,可以返回列表,甚至返回多个值,如代码清单8所示。
代码清单8:返回列表和返回多个值的自定义函数
def add2(x = 0, y = 0): # 定义函数,同时定义参数的默认值
return \[x+2, y+2\] # 返回值是一个列表
def add3(x, y):
return x+3, y+3 # 双重返回
a, b = add3(1,2) # 此时a=4,b=5
有时候,像定义add2()这类简单的函数,用def来正式地写个命名、计算和返回显得稍有点麻烦,Python支持用lambda对简单的功能定义“行内函数”,这有点像MATLAB中的“匿名函数”,如代码清单9所示。
代码清单9:使用lambda定义函数
f = lambda x : x + 2 # 定义函数f(x)=x+2
g = lambda x, y: x + y # 定义函数g(x,y)=x+y
03 数据结构
Python有4个内建的数据结构—List(列表)、Tuple(元组)、Dictionary(字典)以及Set(集合),它们可以统称为容器(Container),因为它们实际上是一些“东西”组合而成的结构,而这些“东西”可以是数字、字符、列表或者是它们之间几种的组合。
通俗来说,容器里边是什么都行,而且容器里边的元素类型不要求相同。
1. 列表/元组
列表和元组都是序列结构,它们本身很相似,但又有一些不同的地方。
从外形上看,列表与元组存在一些区别是。列表是用方括号标记的,如a = [1, 2, 3],而元组是用圆括号标记的,如b = (4, 5, 6),访问列表和元组中的元素的方式都是一样的,如a[0]等于1,b[2]等于6,等等。刚刚已经谈到,容器里边是什么都行,因此,以下定义也是成立的:
c = \[1, ‘abc’, \[1, 2\]\]
‘’’
c是一个列表,列表的第一个元素是整型1,第二个是字符串’abc’,第三个是列表\[1, 2\]
‘’’
从功能上看,列表与元组的区别在于:列表可以被修改,而元组不可以。比如,对于a = [1, 2, 3],那么语句a[0] = 0,就会将列表a修改为[0, 2, 3],而对于元组b = (4, 5, 6),语句b[0] = 1就会报错。
要注意的是,如果已经有了一个列表a,同时想复制a,并命名为变量b,那么b = a是无效的,这时候b仅仅是a的别名(或者说引用),修改b也会修改a。正确的复制方法应该是b = a[:]。
跟列表有关的函数是list,跟元组有关的函数是tuple,它们的用法和功能几乎一样,都是将某个对象转换为列表/元组,如list(‘ab’)的结果是[‘a’, ‘b’],tuple([1, 2])的结果是(1, 2)。一些常见的与列表/元组相关的函数如下所示。
cmp(a, b):比较两个列表/元组的元素
len(a):列表/元组元素个数
max(a):返回列表/元组元素最大值
min(a):返回列表/元组元素最小值
sum(a):将列表/元组中的元素求和
sorted(a):对列表的元素进行升序排序
此外,作为对象来说,列表本身自带了很多实用的方法
(元组不允许修改,因此方法很少),如下所示。
a.append(1):将1添加到列表a末尾
a.count(1):统计列表a中元素1出现的次数
a.extend([1, 2]):将列表[1, 2]的内容追加到列表a的末尾
a.index(1):从列表a中找出第一个1的索引位置
a.insert(2, 1):将1插入列表a中索引为2的位置
a.pop(1):移除列表a中索引为1的元素
最后,不能不提的是“列表解析”这一功能,它能够简化我们对列表内元素逐一进行操作的代码。使用append函数对列表元素进行操作,如代码清单10所示。
代码清单10:使用append函数对列表元素进行操作
a = \[1, 2, 3\]
b = \[\]
for i in a:
b.append(i + 2)
使用列表解析进行简化,如代码清单11所示。
代码清单11:使用列表解析进行简化
a = \[1, 2, 3\]
b = \[i+2 for i in a\]
这样的语法不仅方便,而且直观。这充分体现了Python语法的人性化。在本书中,我们将会较多地用到这样简洁的代码。
2. 字典
Python引入了“自编”这一方便的概念。从数学上来讲,它实际上是一个映射。通俗来讲,它也相当于一个列表,然而它的“下标”不再是以0开头的数字,而是自己定义的“键”(Key)。
创建一个字典的基本方法如下:
d = {‘today’:20, ‘tomorrow’:30}
这里的today、tomorrow就是字典的“键”,它在整个字典中必须是唯一的,而20、30就是“键”对应的值。访问字典中元素的方法也很直观,如代码清单12所示。
代码清单12:访问字典中的元素
d\[‘today’\] # 该值为20
d\[‘tomorrow’\] # 该值为30
要创建一个字典,还有其他一些比较方便的方法来,如通过dict()函数转换,或者通过dict.fromkeys来创建,如代码清单13所示。
代码清单13:通过dict或者dict.fromkeys创建字典
dict(\[\[‘today’, 20\], \[‘tomorrow’, 30\]\]) # 也相当于{‘today’:20, ‘tomorrow’:30}
dict.fromkeys(\[‘today’, ‘tomorrow’\], 20) # 相当于{‘today’:20, ‘tomorrow’:20}
很多字典相关的函数和方法与列表相同,在这里就不再赘述了。
3. 集合
Python内置了集合这一数据结构,这一概念跟数学上的集合的概念基本上是一致的,它跟列表的区别在于:①它的元素是不重复的,而且是无序的;②它不支持索引。一般我们通过花括号{}或者set()函数来创建一个集合,如代码清单14所示。
代码清单14:创建集合
s = {1, 2, 2, 3} # 注意2会自动去重,得到{1, 2, 3}
s = set(\[1, 2, 2, 3\]) # 同样地,它将列表转换为集合,得到{1, 2, 3}
集合具有一定的特殊性(特别是无序性),因此集合有一些特别的运算,如代码清单15所示。
代码清单15:集合运算
a = t | s # t和s的并集
b = t & s # t和s的交集
c = t – s # 求差集(项在t中,但不在s中)
d = t ^ s # 对称差集(项在t或s中,但不会同时出现在二者中)
4. 函数式编程
函数式编程(Functional programming)或者函数程序设计又称泛函编程,是一种编程范型,它将计算机运算视为数学上的函数计算,并且避免使用程序状态以及易变对象。
简单来讲,函数式编程是一种“广播式”编程,通常是结合前面提到的lambda定义函数用于科学计算中,会显得简洁方便。
在Python中,函数式编程主要由几个函数的使用构成:lambda、map、reduce、filter,其中lambda前面已经介绍过,主要用来自定义“行内函数”,所以现在我们逐一介绍后面3个。
(1)map函数
假设有一个列表a = [1, 2, 3],要给列表中的每个元素都加2得到一个新列表,利用前面已经谈及的列表解析,我们可以这样写,如代码清单16所示。
代码清单16:使用列表解析操作列表元素
b = \[i+2 for i in a\]
而利用map函数我们可以这样写,如代码清单17所示。
代码清单17:使用map函数操作列表元素
b = map(lambda x: x+2, a)
b = list(b) # 结果是\[3, 4, 5\]
也就是说,我们首先要定义一个函数,然后再用map命令将函数逐一应用到(map)列表中的每个元素,最后返回一个数组。map命令也接受多参数的函数,如map(lambda x,y: x*y, a, b)表示将a、b两个列表的元素对应相乘,把结果返回新列表。
也许有的读者会有疑问:有了列表解析,为什么还要有map命令呢?其实列表解析虽然代码简短,但是本质上还是for命令,而Python的for命令效率并不高,而map函数实现了相同的功能,并且效率更高,原则上来说,它的循环命令是C语言速度的。
(2)reduce函数
reduce有点像map,但map用于逐一遍历,而reduce用于递归计算。在Python 3.x中,reduce函数已经被移出了全局命名空间,被置于fuctools库中,使用时需要通过from fuctools import reduce引入reduce。先给出一个例子,这个例子可以算出n的阶乘,如代码清单18所示。
代码清单18:使用reduce计算n的阶乘
from fuctools import reduce# 导入reduce函数
reduce(lambda x,y: x_y, range(1, n+1))
其中range(1, n+1)相当于给出了一个列表,元素是1~n这n个整数。lambda x,y: x_y构造了一个二元函数,返回两个参数的乘积。
reduce命令首先将列表的头两个元素作为函数的参数进行运算,然后将运算结果与第三个数字作为函数的参数,然后再将运算结果与第四个数字作为函数的参数……依此递推,直到列表结束,返回最终结果。如果用循环命令,那就要写成代码清单19所示的形式。
代码清单19:使用循环命令计算n的阶乘
s = 1
for i in range(1, n+1):
s = s \* i
(3)filter
顾名思义,它是一个过滤器,用来筛选列表中符合条件的元素,如代码清单20所示。
代码清单20:使用filter筛选列表元素
b = filter(lambda x: x > 5 and x < 8, range(10))
b = list(b) # 结果是\[6, 7\]
使用filter首先需要一个返回值为bool型的函数,如上述“lambda x: x > 5 and x < 8”定义了一个函数,判断x是否大于5且小于8,然后将这个函数作用到range(10)的每个元素中,如果为True,则“挑出”那个元素,最后将满足条件的所有元素组成一个列表返回。
当然,上述filter语句,也可以使用列表解析,如代码清单21所示。
代码清单21:使用列表解析筛选
b = \[i for i in range(10) if i > 5 and i < 8\]
它并不比filter语句复杂。但是要注意,我们使用map、reduce或filter,最终目的是兼顾简洁和效率,因为map、reduce或filter的循环速度比Python内置的for循环或while循环要快得多。
04 库的导入与添加
前面我们已经讲述了Python基本平台的搭建和使用,然而仅在默认情况下它并不会将所有的功能加载进来。我们需要把更多的库(或者叫作模块、包等)加载进来,甚至需要安装第三方扩展库,以丰富Python的功能,实现我们的目的。
1. 库的导入
Python本身内置了很多强大的库,如数学相关的math库,可以为我们提供更加丰富且复杂的数学运算,如代码清单22所示。
代码清单22:使用math库进行数学运算
import math
math.sin(1) # 计算正弦
math.exp(1) # 计算指数
math.pi # 内置的圆周率常数
导入库的方法,除了直接“import库名”之外,还可以为库起一个别名,如代码清单23所示。
代码清单23:使用别名导入库
import math as m
m.sin(1) # 计算正弦
此外,如果并不需要导入库中的所有函数,可以特别指定导入函数的名称,如代码清单24所示。
代码清单24:通过名称导入指定函数
from math import exp as e # 只导入math库中的exp函数,并起别名e
e(1) # 计算指数
sin(1) # 此时sin(1)和math.sin(1)都会出错,因为没被导入
若直接导入库中的所有函数,如代码清单25所示。
代码清单25:导入库中所有函数
#直接导入math库,也就是去掉math.,但如果大量地这样引入第三库,就容易引起命名冲突
from math import \*
exp(1)
sin(1)
我们可以通过help(‘modules’)命令来获得已经安装的所有模块名。
2. 导入future特征(For 2.x)
Python 2.x与Python 3.x之间的差别不仅是在内核上,也部分地表现在代码的实现中。比如,在Python 2.x中,print是作为一个语句出现的,用法为print a;但是在Python 3.x中,它是作为函数出现的,用法为print(a)。
为了保证兼容性,本文的基本代码是基于Python 3.x的语法编写的,而使用Python 2.x的读者,可以通过引入future特征的方式兼容代码,如代码清单26所示。
代码清单26:导入future特征
#将print变成函数形式,即用print(a)格式输出
from **future** import print\_function
#3.x的3/2=1.5,3//2才等于1;2.x中3/2=1
from future import division
3. 添加第三方库
Python自带了很多库,但不一定可以满足我们的需求。就数据分析和数据挖掘而言,还需要添加一些第三方库来拓展它的功能。这里简单介绍一下第三方库的安装。
安装第三方库有多种方法,如下所示。
下载源代码自行安装:安装灵活,但需要自行解决上级依赖问题
用pip命令安装:比较方便,自动解决上级依赖问题
用easy_install命令安装:比较方便,自动解决上级依赖问题,比pip稍弱
下载编译好的文件包:一般是Windows系统才提供现成的可执行文件包
系统自带的安装方式:Linux系统或Mac系统的软件管理器自带了某些库的安装方式
一、Python所有方向的学习路线(思维导图)
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具以及学习资料
只有Python的理论基础学好了,才能在Python编程上走得更远!!!
三、100个实战项目
基础理论知识牢固了,还要学会跟着一起敲敲实战项目,要动手实操,才能将自己的所学运用到实际当中去。
这份完整版的Python全套学习资料已经打包好啦!
宝子们如果需要可以留言,掉落呀!
文章出处登录后可见!