自我介绍
我是秋说,研究 人工智能、大数据 等前沿技术,传递 Java、Python 等语言知识。

💬主页链接:秋说的博客
📆 学习专栏推荐:
人工智能探索之路💫
MySQL进阶之路🏆
C++编程集🚀
网安攻防实战🗡
从0精通C程序设计💯
欢迎点赞🌈 收藏⭐ 留言📝

✈️文章目录
- 1️⃣文章引言
- 2️⃣视觉感知优化汽车之眼
- 3️⃣神经网络赋能感知算法
- :star: 深度神经网络DNN
- :star: 卷积神经网络CNN
- :star: 循环神经网络RNN
- 4️⃣BEV+Transformer创新特征级融合
- 5️⃣语义分割深化场景理解
- 总结
1️⃣文章引言
当今,AI大模型是一个火热🔥的关键词。随着人工智能的迅猛发展,AI大模型在各个领域展现出了巨大的潜力和应用价值。在自动驾驶领域🚗,AI大模型的应用驱动自动驾驶算法具备更强的泛化能力🔌。
那么 AI大模型 为自动驾驶赋能了什么❔它的未来发展前景又是怎样❔
本文将以主流自动驾驶汽车特斯拉为例,揭开AI大模型在自动驾驶领域的神秘面纱
AI大模型在自动驾驶中的应用涵盖了深度神经网络、卷积神经网络、循环神经网络、BEV+Transformer特征级融合以及语义分割等方面。通过这些应用,AI大模型能够提供强大的感知和理解能力,为自动驾驶系统的性能和安全性提供关键支持。
2️⃣视觉感知优化汽车之眼
在自动驾驶中,视觉感知🔍是非常重要的一项技术,AI大模型在视觉感知上也有着广泛的应用。
AI大模型可以通过目标检测和跟踪技术,实现对道路上的车辆、行人等目标的准确识别和追踪。这种技术能够帮助自动驾驶系统建立对周围环境的感知,并为决策和规划提供必要的信息。
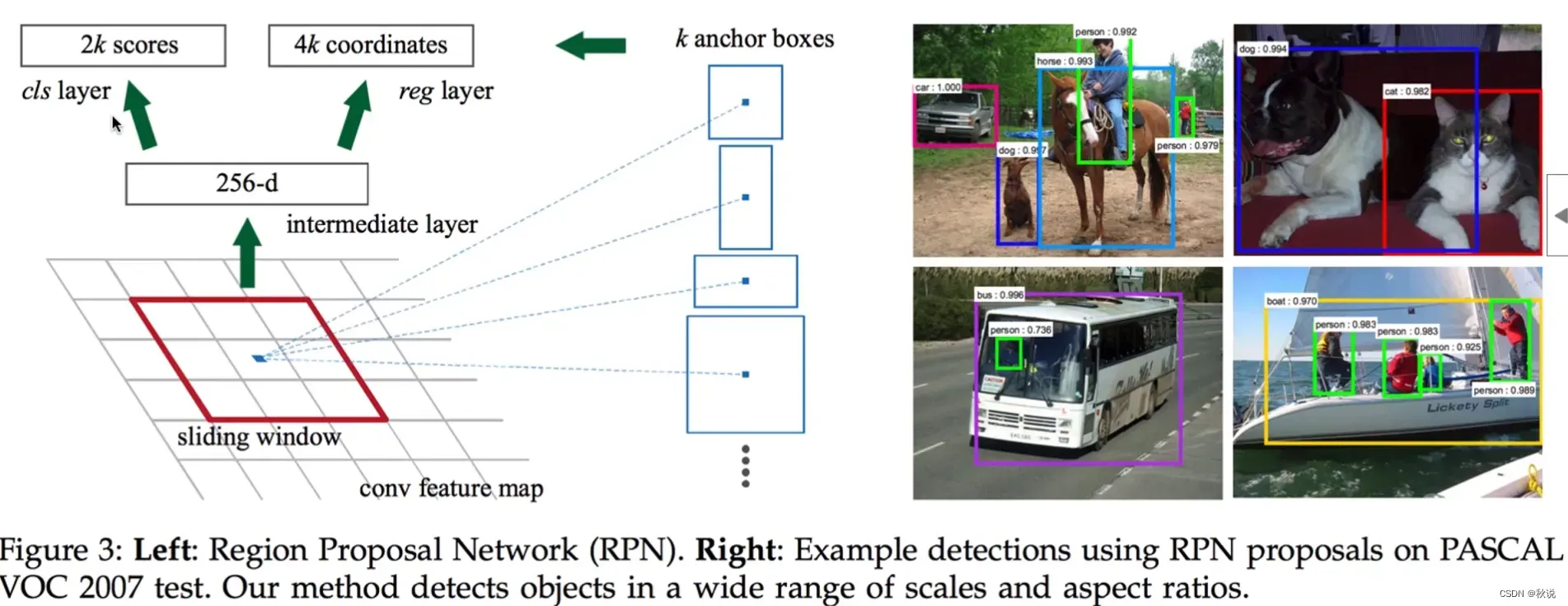
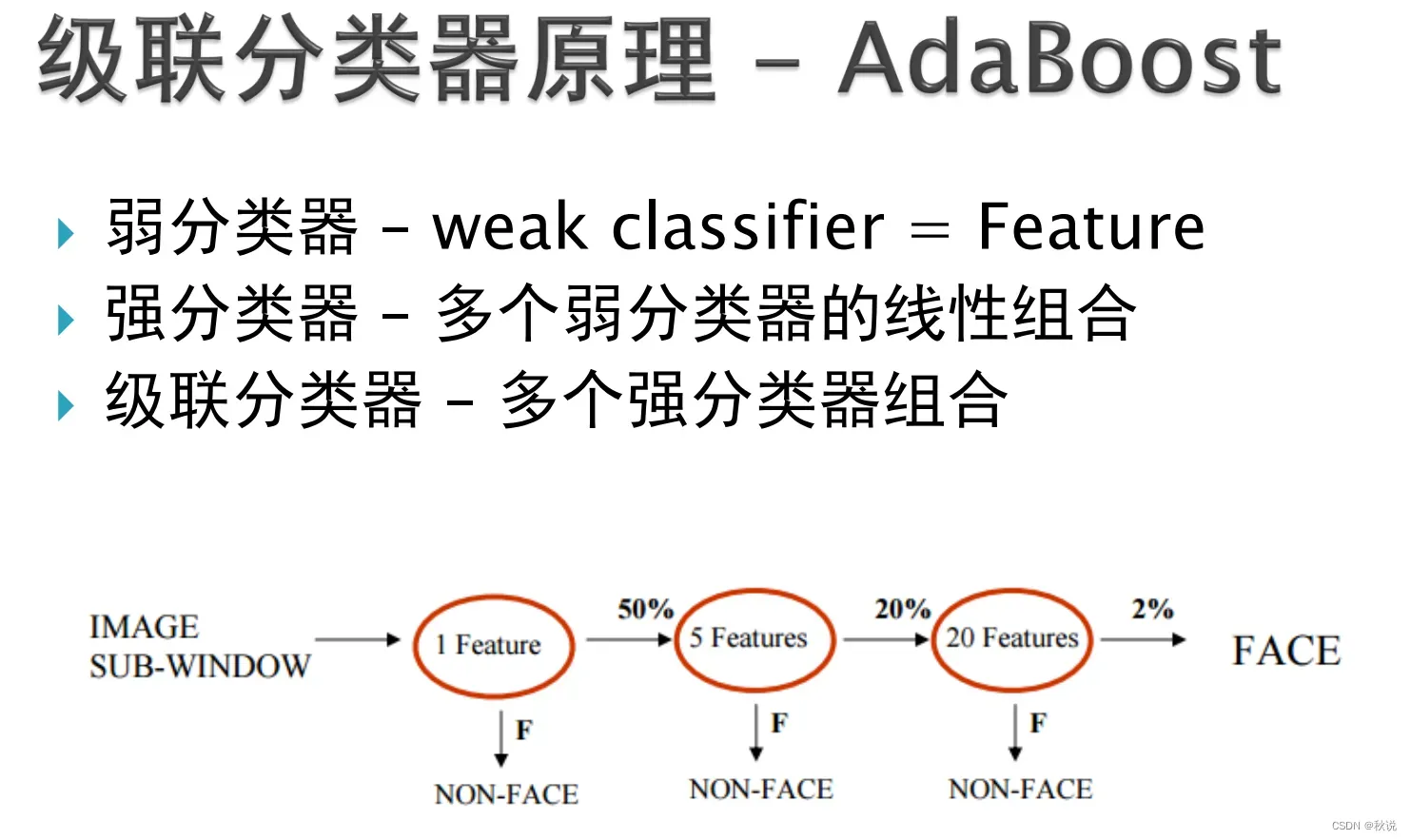
常见的目标检测算法⌨️包括基于传统方法的Haar特征级联分类器、HOG+SVM以及基于深度学习的Faster R-CNN和YOLO等。这些算法通常通过在图像上滑动窗口,并使用分类器来判断窗口内是否存在目标,进而完成目标的定位与识别。
📌光流估计是通过分析连续帧图像中像素的位移来推断运动信息的技术。
AI大模型可以利用光流估计来检测道路上的动态物体,并进行动态障碍物的预测和跟踪。这对于自动驾驶系统的安全性和稳定性至关重要。
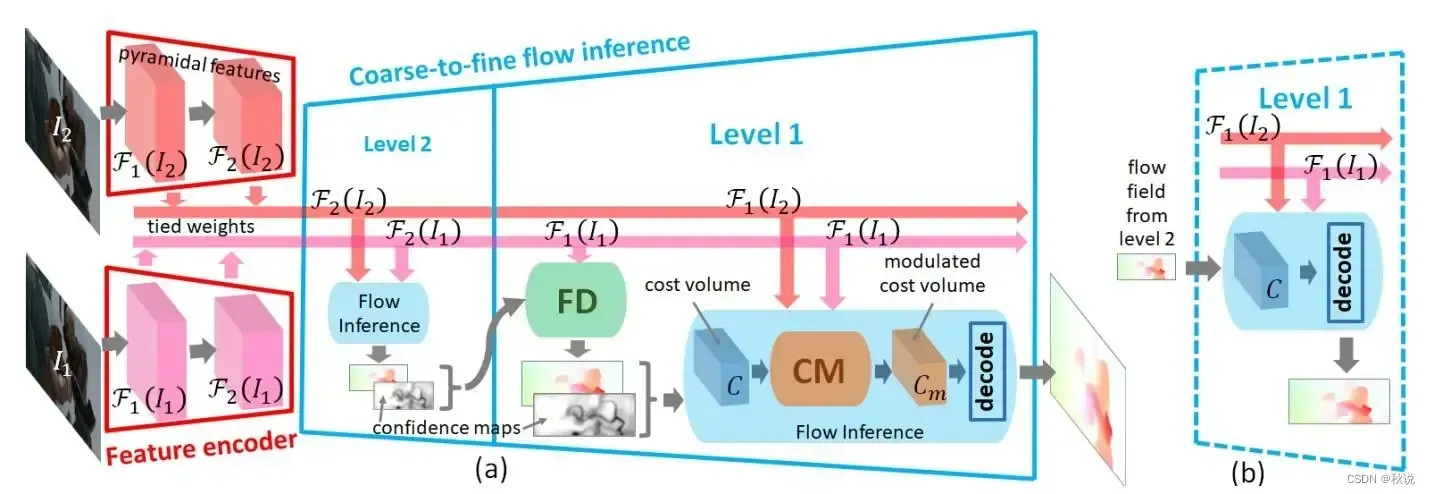
光流估计⚡基于亮度恒定和空间连续假设,将相邻图像中同一点的灰度变化关系转化为速度向量场,其中点的运动轨迹是连续、等间距的。通过对图像中的特征点进行跟踪,可以得到这些特征点的速度向量,从而推断出物体在图像中的运动情况。
以下是光流估计的简单代码:
import cv2
cap = cv2.VideoCapture(0)
# 设置参数
feature_params = dict(maxCorners=100, qualityLevel=0.3, minDistance=7, blockSize=7)
lk_params = dict(winSize=(15, 15), maxLevel=2, criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03))
# 初始化点的位置
old_points = None
while True:
ret, frame = cap.read()
# 灰度处理
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 检测特征点
if old_points is None:
old_points = cv2.goodFeaturesToTrack(gray, mask=None, **feature_params)
else:
# 计算光流
new_points, status, error = cv2.calcOpticalFlowPyrLK(old_gray, gray, old_points, None, **lk_params)
# 选取好的新特征点
good_new = new_points[status == 1]
# 选取对应的旧特征点
good_old = old_points[status == 1]
# 绘制跟踪结果
for i, (new, old) in enumerate(zip(good_new, good_old)):
a, b = new.ravel()
c, d = old.ravel()
mask = cv2.line(mask, (a, b), (c, d), color[i].tolist(), 2)
frame = cv2.circle(frame, (a, b), 5, color[i].tolist(), -1)
img = cv2.add(frame, mask)
old_gray = gray.copy() # 更新旧特征点
old_points = good_new.reshape(-1, 1, 2) # 更新旧特征点
cv2.imshow('frame', img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
💡AI大模型在目标检测与跟踪、路面分割与地面估计、光流估计与动态物体检测等方面的应用,能够提供强大的视觉感知能力,为自动驾驶系统的安全性和性能提供重要支持。
3️⃣神经网络赋能感知算法
神经网络是自动驾驶中的重要组成部分⚙️,用于感知、决策和控制,提供智能化的数据处理和驾驶决策能力。
在自动驾驶中,我们主要运用到了深度神经网络DNN、卷积神经网络CNN、循环神经网络RNN三种神经网络🌐。
⭐️ 深度神经网络DNN
⛵深度神经网络是一种由多个神经网络层级组成的模型,每一层都会对输入数据进行一系列的非线性转换和特征提取。通过增加网络的深度,深度神经网络可以学习到更复杂、抽象的特征表示,从而提高模型的表达能力和性能。

在自动驾驶中,深度神经网络常用于图像识别、目标检测、语义分割等感知任务,以及决策和规划等高级驾驶任务。
⭐️ 卷积神经网络CNN
💬卷积神经网络通过卷积层和池化层的组合,可以从图像中提取特征,并自动学习这些特征的表示。卷积操作可以在输入图像上滑动一个小的窗口,将窗口内的局部信息与卷积核进行卷积运算,以提取不同位置的特征。📺而池化层则可以对特征图进行下采样,保留最重要的特征信息。通过堆叠多个卷积层和池化层,CNN可以逐渐提取出更高级别的特征,从而实现对图像的分类、检测和分割等任务。
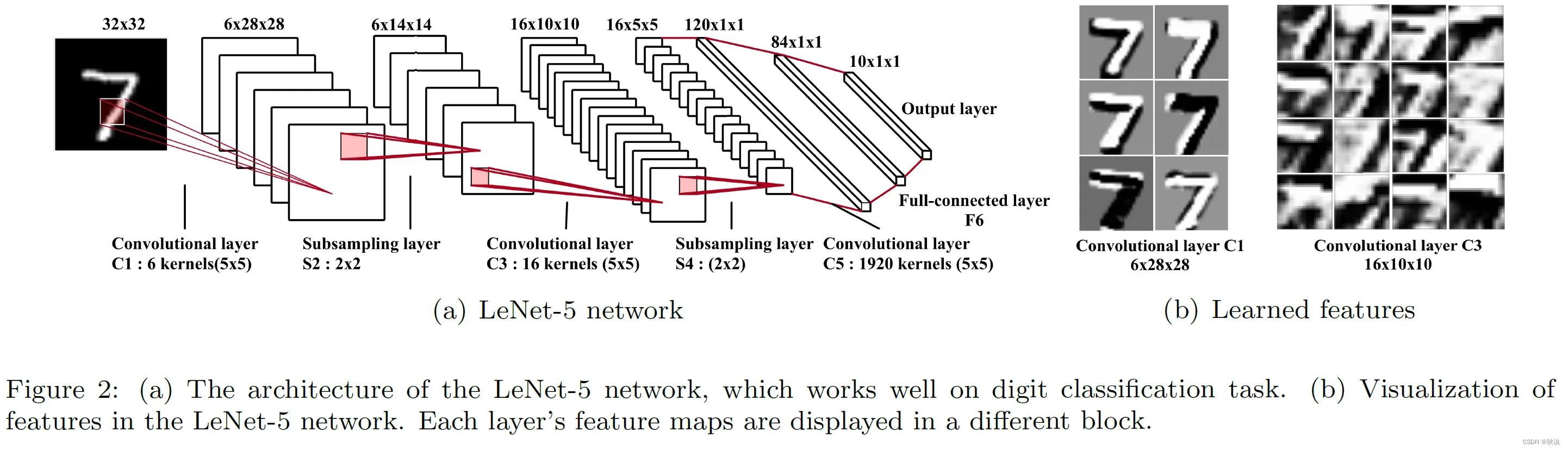
在自动驾驶中,CNN被广泛应用于实现车辆的视觉感知,如道路边界识别、障碍物检测和交通标志识别等。
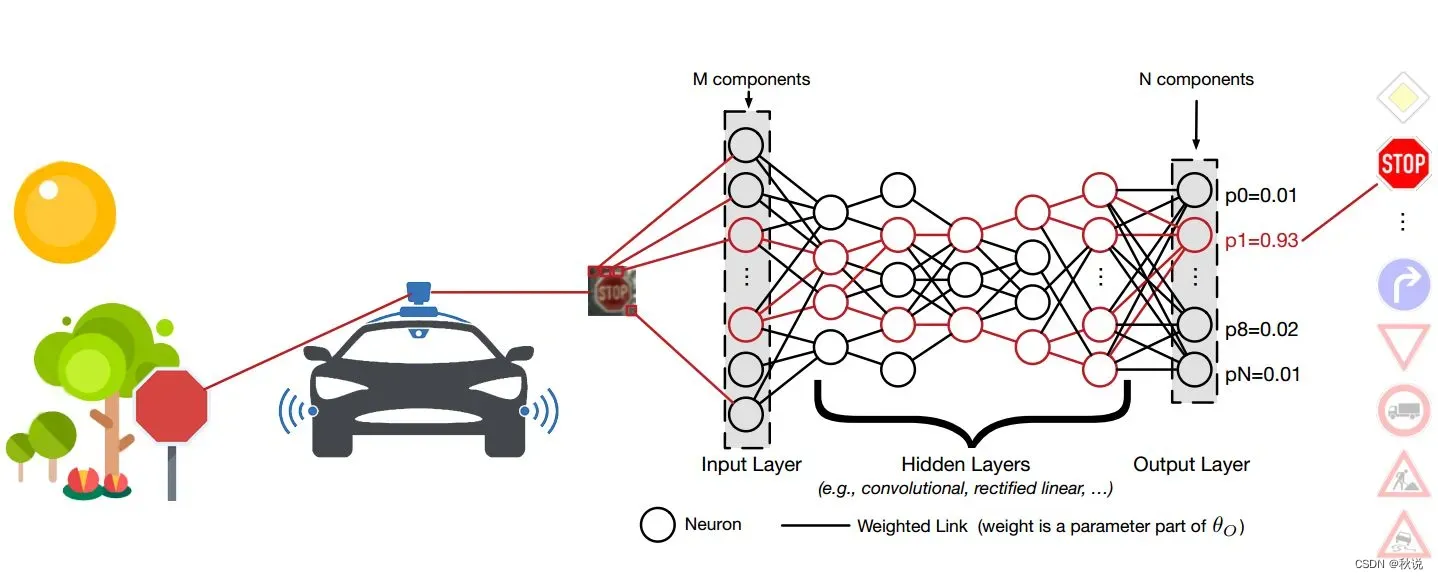
⭐️ 循环神经网络RNN
循环神经网络是一种用于处理序列数据的神经网络。与传统的前馈神经网络不同,RNN具有循环连接,使得它可以保持记忆⌛并处理变长的序列输入。
❄️举个例子:
✏️假设我们有一段文本:“The cat sat on the mat”,现在需要将其进行自动翻译为中文。我们可以使用循环神经网络来完成这个任务。
🛰️首先,我们定义一个包含若干隐藏层的循环神经网络,并将整个英文传入网络中。在每个时间步长上,网络会从前一个时间步长中的隐藏状态和当前时间步长的输入中计算出当前时间步长对应的隐藏状态,并将其传递到下一个时间步长。在整个文本输入完成后,我们从最后一个隐藏状态中提取出该文本的语义表示。
💻接着,我们可以将这个语义表示作为输入,连同一个全连接层一起,构成一个解码器。在解码器中,我们在每个时间步长上都输出一个汉字。为了让模型学习到如何正确翻译句子,我们将整个中文文本作为目标输出,并以其与解码器的输出之间的差异作为损失函数,使用反向传播算法对整个模型进行训练。经过数代迭代,循环神经网络将逐渐学会将英文文本翻译成中文。
图示如下:
输入层 隐藏层 输出层
-------- ----------- --------
| w | ------->| neuron |------->| x |
| o | | (h) | | n |
| r | <-------| |<-------| .
| d | ------->| |------->| .
-------- ------------ --------
✒️循环神经网络在自然语言处理、语音识别、时间序列预测等任务中广泛应用。RNN能够捕捉到序列中的动态模式,并对未来的内容进行预测或生成。
4️⃣BEV+Transformer创新特征级融合
特征级融合指的是将不同来源或不同类型的特征进行整合,以提升模型性能和表征能力。
📷BEV是一种俯视图,可以提供关于场景的全局信息和准确的空间定位。BEV以图像的形式展示了车辆周围的环境,每个像素代表一种属性(例如障碍物、道路线等)。
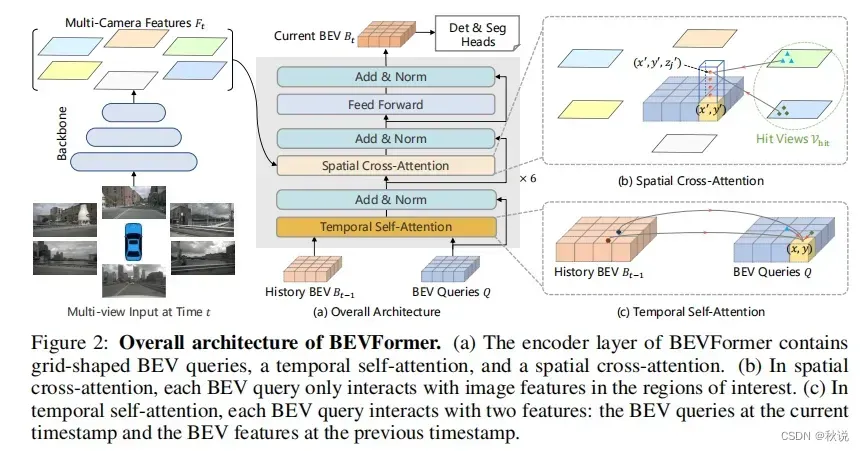
⚽而Transformer是一种基于自注意力机制的序列建模方法,它通过多头自注意力机制和前馈神经网络构建,可以同时考虑序列中的长距离依赖关系,并且在处理任意长度的序列时具有可扩展性。
🔭使用Transformer网络来处理BEV图像中的特征,并将其编码为高维特征表示。然后,这些特征可以与其他传感器(如相机图像)提取的特征进行融合,形成一个更加综合且全面的特征表示。
简单来说, 使用融合后的特征表示作为输入,目标检测算法会根据综合特征来预测物体的位置、类别和其他属性。
🧭这样的融合可以帮助模型更好地理解和处理复杂的场景,并提升任务的性能,例如目标检测、目标跟踪和行为预测等。
5️⃣语义分割深化场景理解
🤖语义分割是计算机视觉领域的一个任务,旨在将图像中的每个像素标记为对应的语义类别,从而实现对图像的像素级别理解。
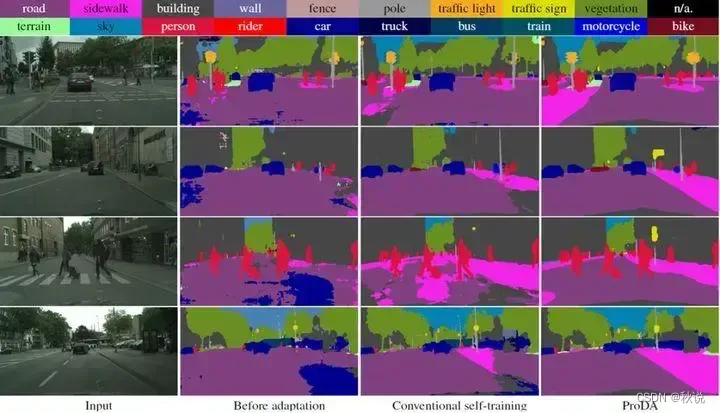
语义分割能够将图像中的每个像素进行分类💾,包括物体、背景和其他区域。
同时,语义分割也可以区分出图像中不同的物体实例➿,并给它们分配独立的类别标签,例如目标的姿态、形状和尺寸等特征。
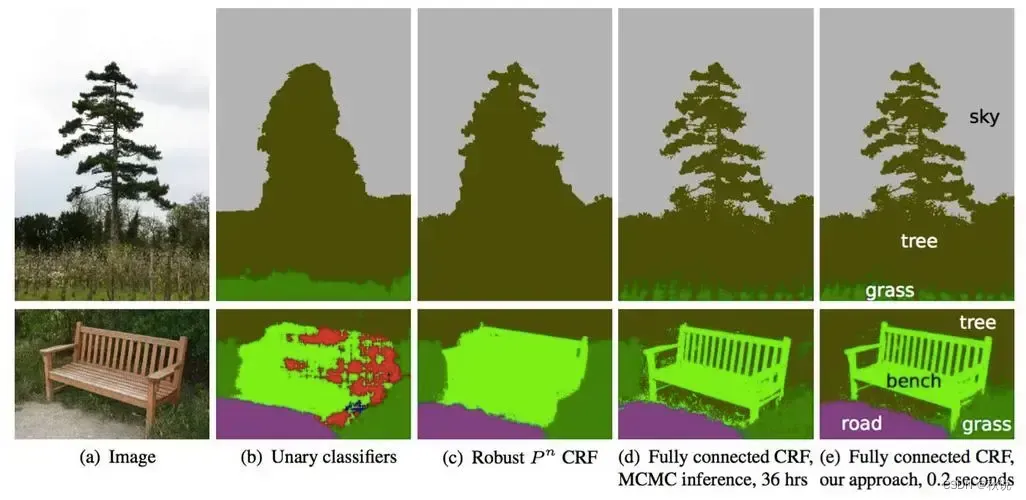
🚀这提供了更详细和准确的场景信息,也为各种计算机视觉任务和应用提供了更强大的支持和基础。
总结
✈️AI大模型的发展和成熟为自动驾驶技术带来了巨大的推动力。
未来🌎,自动驾驶将成为安全、高效和舒适出行😊的代名词,同时对交通方式和城市规划产生深远的影响,为我们创造更美好的出行体验。

文章出处登录后可见!