噪声是影响机器学习算法有效性的重要因素之一,由于实际数据集存在采集误差、主观标注以及被恶意投毒等许多因素,使得所构造的数据集中难免存在噪声
一、噪声的分类、产生原因与影响
在机器学习训练集中,存在两种噪声
属性噪声 样本中某个属性的值存在噪声
标签噪声 样本归属类别
关于噪声分布的假设:均匀分布、高斯分布、泊松分布等
一般认为,数据质量决定了分类效果的上限,而分类器算法只能决定多大程度上逼近这个上限
标签噪声的产生原因
(1)特定类别的影响,在给定的标注任务中,各个类别样本之间的区分度不同,有的类别与其他类别都比较相似,就会导致这类样本标注错误率高
(2)标注人为的因素
(3)少数类的标注更容易错误
(4)训练数据受到了恶意投毒,当在对抗环境下应用机器学习模型时,攻击者往往会通过一些途径向数据中注入恶意样本,扰乱分类器的性能
标签噪声比属性噪声更重要
数据利用率
分类性能下降: KNN、决策树和支持向量机、 Boosting 等
模型复杂度 决策树节点增多 为了降低噪声影响,需要增加正确样本数量 可能导致非平衡数据
正面影响:Bagging训练数据中的噪声有利于提升基分类器的多样性
与噪声类似的概念和研究
异常 离群点:outlier 少数类 小样本 对抗样本 恶意样本 脏数据
二、噪声处理的理论与方法
概率近似正确定理(probably approximately correct,PAC )
对于任意的学习算法而言,训练数据噪声率β,必须满足β≤ ε /(1+ ε) ,其中ε表示分类器的错误率
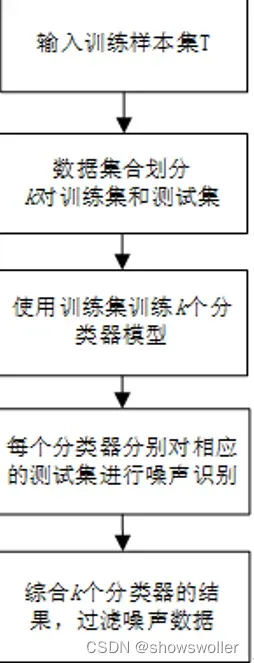
三、基于数据清洗的噪声过滤
在这类方法中,一般假设噪声标签样本是分类错误的样本,因此就把噪声样本的过滤问题转换为普通的分类问题,这种方法的基本思路是消除或者纠正数据中的错误标签,这个步骤可以在训练之前完成,也可以与模型训练同步进行,噪声去除方法具体包括直接删除法,基于最近邻的去噪方法和集成去噪法等
数据层 去除噪声样本 修正噪声样本 方法:采用噪声敏感方法检测噪声 KNN,K小 密度方法 决策树 集成学习:静态集成、动态集成;投票 主动学习:人工+分类器迭代
1:直接删除法
直接删除法是基于两种情况,把异常值影响较大或看起来比较可疑的实例删除,或者直接删除分类器中分类错误的训练实例
在具体实现方法上,如何判断异常值、可疑等特征,可以使用边界点发现之类的方法
2:基于最近邻的去噪方法
从KNN本身原理来看,当k比较小的时候,分类结果与近邻的样本标签关系很大。因此,它是一种典型的噪声敏感模型,在噪声过滤中有一定优势
压缩最近邻CNN、缩减最近邻RNN、基于实例选择的Edited Nearest Neighbor等,也都可以用于噪声过滤
3:集成去噪
集成分类方法对若干个弱分类器进行组合,根据结果的一致性来判断是否为噪声,是目前一种较好的标签去噪方法。两种情况
使用具有相同分布的其他数据集,当然该数据集必须是一个干净、没有噪声的数据
不使用外部数据集,而是直接使用给定的标签数据集进行K折交叉分析
四、主动式过滤
基于数据清洗的噪声过滤方法的隐含假设是噪声是错分样本,把噪声和错分样本等同起来
位于分类边界的噪声最难于处理,需要人工确认
主动学习框架和理论为人类专家与机器学习的写作提供了一种有效的途径,它通过迭代抽样的方式将某种特定的样本挑选出来,交由专家对标签进行人工判断和标注,从而构造有效训练集的一种方法
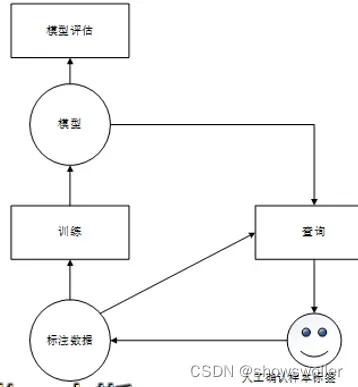
查询策略如何选择可能是噪声的样本,就成为主动学习的核心问题
查询策略主要可以分为以下两类:基于池的样例选择算法和基于流的样例选择算法
基于池的样本选择算法代表性的有:基于不确定性采样的查询方法、基于委员会的查询方法、基于密度权重的方法等
不确定采样
不确定性采样的查询
将模型难于区分的样本提取出来,具体在衡量不确定性时可以采用的方法有最小置信度、边缘采样和熵
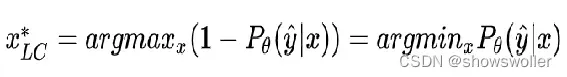
边缘采样是选择哪些类别概率相差不大的样本
其中,y1,y2是样本x的top 2归属概率的类别。 对于两个样本a,b的分类概率分别为(0.71,0.19,0.10)、(0.17,0.53,0.30) ,应当选择b,因为0.53-0.17<0.71-0.19。对于二分类问题,边缘采样和最小置信度是等价的
基于熵采样
通过熵来度量,它衡量了在每个类别归属概率上的不确定。选择熵最大的样本作为需要人工判定的样本
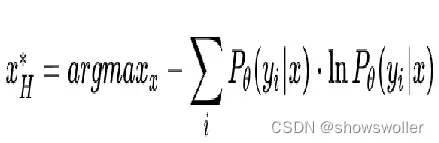
基于委员会的采样
当主动学习中采用集成学习模型时,这种选择策略考虑到每个基分类器的投票情况。相应地,通过基于投票熵和平均KL散度来选择样本
样本x的投票熵计算时,把x的每个类别的投票数当作随机变量,衡量该随机变量的不确定性
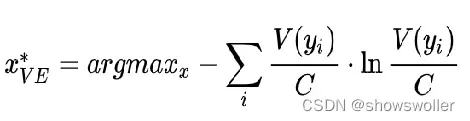
其中V(y)表示投票给y的分类器的个数,C表示分类器总数。投票熵越大,就越有可能被选择出来
当每个基分类器为每个样本输出分类概率时,可以使用平均KL散度来计算各个分类器的分类概率分布与平均分布的平均偏差。偏差越大的样本,其分类概率分布的一致性越差,应当越有可能被选择出来
五、噪声鲁棒模型
在分类模型中嵌入噪声处理的学习机制,使得学习到的模型能抵抗一定的噪声样本
在机制设计上,可以从样本权重调整、损失函数设计、Bagging集成学习、深度学习等角度提升模型的噪声容忍度
AdaBoost串接的基分类器中,越往后面,错误标签的样本越会得到基分类器的关注
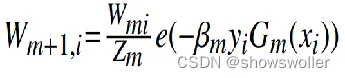
当样本x分类错误时,其权值以exp(beta_m)变化;而对于正确分类的样本以exp(-beta_m)。 从上述算法流程可以看出,0<=e_m<=0.5,相应地,beta_m>=0。因此,对于,错误的样本的权重>exp(0)=1,而分类正确的样本的权值<=exp(0)=1
经过t轮后得到的权重为exp(beta_m1) exp(beta_m2)…exp(beta_mt)。可见噪声样本的权重得到了快速增加而变得很大
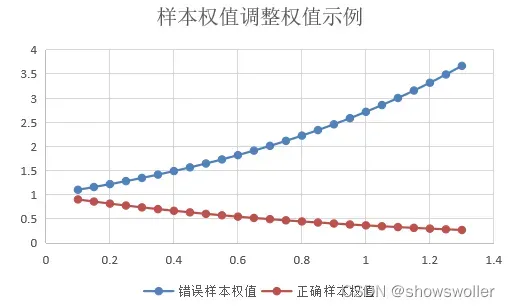
AdaBoost 算法的噪声敏感性归因于其对数损失函数,当一个样本未被正确分类的时候,该样本的 权值会指数型增加
随着迭代次数的增加,由于算法会更多地关注于错分类的样本, 必然会使得噪声样本的权值越来越大,进而增加了模型复杂度,降低了算法性能
删除权重过高的样本或调整异常样本的权重来降低标签噪声的影响
MadaBoost:针对噪声样本在后期的训练权重过大的问题,算法重新调整了AdaBoost中的权值更新公式,设置了一个权重的最大上限1,限制标签噪声造成的样本权值的过度增加
AdaBoost的损失函数改进
各分类器稳健性差异的本质原因在于损失函数
不同损失函数对噪声的稳健性差异
0-1损失或最小二乘损失对均匀分布噪声稳健
指数、对数型损失函数对各类噪声大都不稳健
AdaBoost的损失函数
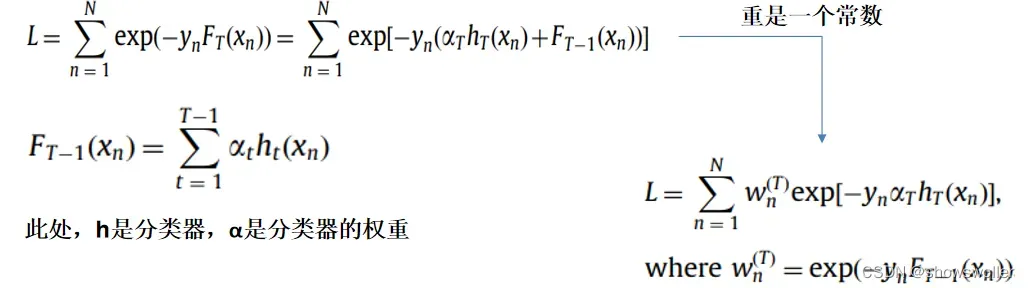
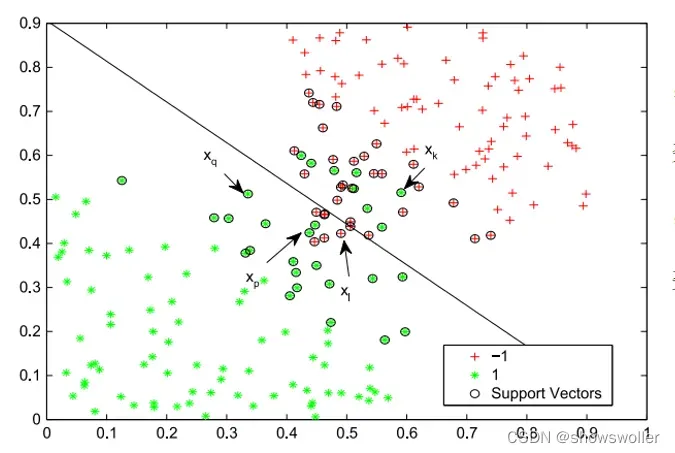
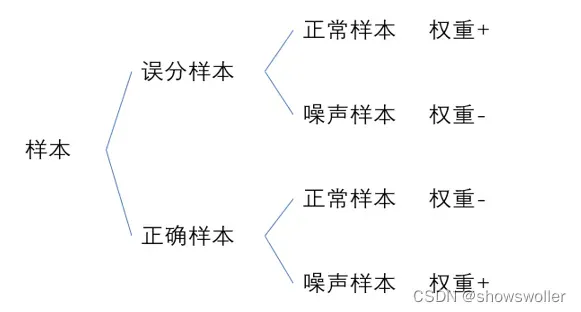
(1)噪声样本被正确分类,表示为xp
(2)非噪声样本被正确分类,表示为xq
(3)噪声样本被错误分类,表示为xk
(4)非噪声样本被错误分类,表示为xl
预期目标
ndAdaBoost的损失函数
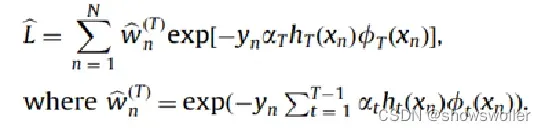

在这样的损失函数下
(1)如果样本xn被错误分类 在误分的样本中,噪声数据比非噪声数据所占的比例更大。不正确分类的样本噪声越大,其损失函数值越小
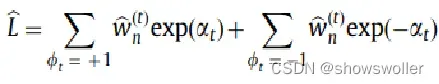
(2)如果样本xn被正确分类
在正确分类的样本中,非噪声数据倾向于最小化损失函数,也就是说非噪声数据尽可能多地成为正确分类
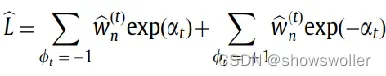
常见损失函数如下
0-1损失函数
平均绝对误差MAE
均方误差MSE
均方根误差RMSE
交叉熵损失
指数损失
对数损失
Hinge损失函数
文章出处登录后可见!