1. BoTNet(Bottleneck Transformer Network)
UC伯克利,谷歌研究院(Ashish Vaswani, 大名鼎鼎的Transformer一作)
论文:https://arxiv.org/abs/2101.11605
Github:https://github.com/leaderj1001/BottleneckTransformers
BoTNet(Bottleneck Transformer Network):一种基于Transformer的新骨干架构。BoTNet同时使用卷积和自注意力机制,即在ResNet的最后3个bottleneck blocks中使用全局多头自注意力(Multi-Head Self-Attention, MHSA)替换3 × 3空间卷积。
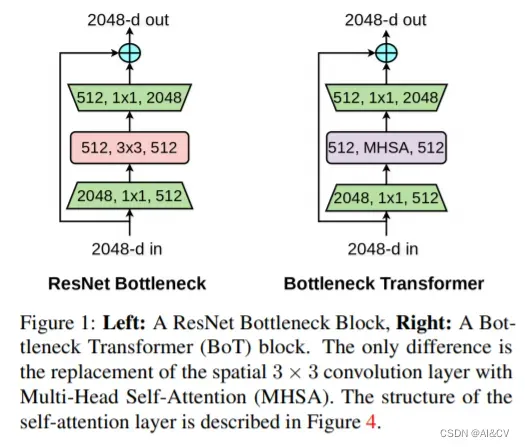
2.Yolov5/Yolov7加入BoTNet、MHSA
2.1 BoTNet、MHSA加入common.py中
class MHSA(nn.Module):
def __init__(self, n_dims, width=14, height=14, heads=4, pos_emb=False):
super(MHSA, self).__init__()
self.heads = heads
self.query = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.key = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.value = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.pos = pos_emb
if self.pos:
self.rel_h_weight = nn.Parameter(torch.randn([1, heads, (n_dims) // heads, 1, int(height)]),
requires_grad=True)
self.rel_w_weight = nn.Parameter(torch.randn([1, heads, (n_dims) // heads, int(width), 1]),
requires_grad=True)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
n_batch, C, width, height = x.size()
q = self.query(x).view(n_batch, self.heads, C // self.heads, -1)
k = self.key(x).view(n_batch, self.heads, C // self.heads, -1)
v = self.value(x).view(n_batch, self.heads, C // self.heads, -1)
# print('q shape:{},k shape:{},v shape:{}'.format(q.shape,k.shape,v.shape)) #1,4,64,256
content_content = torch.matmul(q.permute(0, 1, 3, 2), k) # 1,C,h*w,h*w
# print("qkT=",content_content.shape)
c1, c2, c3, c4 = content_content.size()
if self.pos:
# print("old content_content shape",content_content.shape) #1,4,256,256
content_position = (self.rel_h_weight + self.rel_w_weight).view(1, self.heads, C // self.heads, -1).permute(
0, 1, 3, 2) # 1,4,1024,64
content_position = torch.matmul(content_position, q) # ([1, 4, 1024, 256])
content_position = content_position if (
content_content.shape == content_position.shape) else content_position[:, :, :c3, ]
assert (content_content.shape == content_position.shape)
# print('new pos222-> shape:',content_position.shape)
# print('new content222-> shape:',content_content.shape)
energy = content_content + content_position
else:
energy = content_content
attention = self.softmax(energy)
out = torch.matmul(v, attention.permute(0, 1, 3, 2)) # 1,4,256,64
out = out.view(n_batch, C, width, height)
return out
class BottleneckTransformer(nn.Module):
# Transformer bottleneck
# expansion = 1
def __init__(self, c1, c2, stride=1, heads=4, mhsa=True, resolution=None, expansion=1):
super(BottleneckTransformer, self).__init__()
c_ = int(c2 * expansion)
self.cv1 = Conv(c1, c_, 1, 1)
# self.bn1 = nn.BatchNorm2d(c2)
if not mhsa:
self.cv2 = Conv(c_, c2, 3, 1)
else:
self.cv2 = nn.ModuleList()
self.cv2.append(MHSA(c2, width=int(resolution[0]), height=int(resolution[1]), heads=heads))
if stride == 2:
self.cv2.append(nn.AvgPool2d(2, 2))
self.cv2 = nn.Sequential(*self.cv2)
self.shortcut = c1 == c2
if stride != 1 or c1 != expansion * c2:
self.shortcut = nn.Sequential(
nn.Conv2d(c1, expansion * c2, kernel_size=1, stride=stride),
nn.BatchNorm2d(expansion * c2)
)
self.fc1 = nn.Linear(c2, c2)
def forward(self, x):
out = x + self.cv2(self.cv1(x)) if self.shortcut else self.cv2(self.cv1(x))
return out
class BoT3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, e=0.5, e2=1, w=20, h=20): # ch_in, ch_out, number, , expansion,w,h
super(BoT3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(
*[BottleneckTransformer(c_, c_, stride=1, heads=4, mhsa=True, resolution=(w, h), expansion=e2) for _ in
range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1)) 2.3 BoTNet、MHSA加入yolo.py中
if m in {
Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, C2f,
EVCBlock, ODConv_3rd, ConvNextBlock, SEAM, RFEM, C3RFEM, ConvMixer, MultiSEAM,MLPBlock,Partial_conv3,CBAM,GAM_Attention,MHSA,BoT3}:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x, C2f,EVCBlock,C3RFEM,BoT3}:
args.insert(2, n) # number of repeats
n = 12.4修改 yolov5s_botnet.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, BoT3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
2.5 修改 yolov5s_mhsa.yaml
# parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
#- [5,6, 7,9, 12,10] # P2/4
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args] # [c=channels,module,kernlsize,strides]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [c=3,64*0.5=32,3]
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, MHSA, [1024,1024]], #9
[-1, 1, SPPF, [1024,5]], #10
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 14
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 18 (P3/8-small)
[-1, 1, MHSA, [256,256]], #19
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 22 (P4/16-medium) [256, 256, 1, False]
[-1, 1, MHSA, [512,512]],
[-1, 1, Conv, [512, 3, 2]], #[256, 256, 3, 2]
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 25 (P5/32-large) [512, 512, 1, False]
[-1, 1, MHSA, [1024,1024]], #
[[19, 23, 27], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
文章出处登录后可见!
已经登录?立即刷新