什么是Stable Diffusion
Stable Diffusion是一种潜在扩散模型(Latent Diffusion Model),能够从文本描述中生成详细的图像。它还可以用于图像修复、图像绘制、文本到图像和图像到图像等任务。简单地说,我们只要给出想要的图片的文字描述在提Stable Diffusion就能生成符合你要求的逼真的图像!
Stable Diffusion将“图像生成”过程转换为逐渐去除噪声的“扩散”过程,整个过程从随机高斯噪声开始,经过训练逐步去除噪声,直到不再有噪声,最终输出更贴近文本描述的图像。这个过程的缺点是去噪过程的时间和内存消耗都非常大,尤其是在生成高分辨率图像时。Stable Diffusion引入潜在扩散来解决这个问题。潜在扩散通过在较低维度的潜在空间上应用扩散过程而不是使用实际像素空间来减少内存和计算成本。
什么是LoRA模型
LoRA的全称是LoRA: Low-Rank Adaptation of Large Language Models,可以理解为stable diffusion(SD)模型的一种插件,和hyper-network,controlNet一样,都是在不修改SD模型的前提下,利用少量数据训练出一种画风/IP/人物,实现定制化需求,所需的训练资源比训练SD模要小很多,非常适合社区使用者和个人开发者。LoRA最初应用于NLP领域,用于微调GPT-3等模型(也就是ChatGPT的前生)。由于GPT参数量超过千亿,训练成本太高,因此LoRA采用了一个办法,仅训练低秩矩阵(low rank matrics),使用时将LoRA模型的参数注入(inject)SD模型,从而改变SD模型的生成风格,或者为SD模型添加新的人物/IP。用数据公式表达如下,其中
是初始SD模型的参数(Weights), 为低秩矩阵也就是LoRA模型的参数,
代表被LORA模型影响后的最终SD模型参数。整个过程是一个简单的线性关系,可以认为是原SD模型叠加LORA模型后,得到一个全新效果的模型。
在著名的模型分享网站https://civitai.com/上,有大量的SD模型和LoRA模型,其中SD模型仅有2000个,剩下4万个基本都是LoRA等小模型。例如下图,水墨画和原神八重神子就是LoRA模型来实现特定的画风和人物IP。
快速体验Stable Diffusion
官方网络应用程序 https://beta.dreamstudio.ai/generate
整合包安装
知乎教程
整合包运行截图如下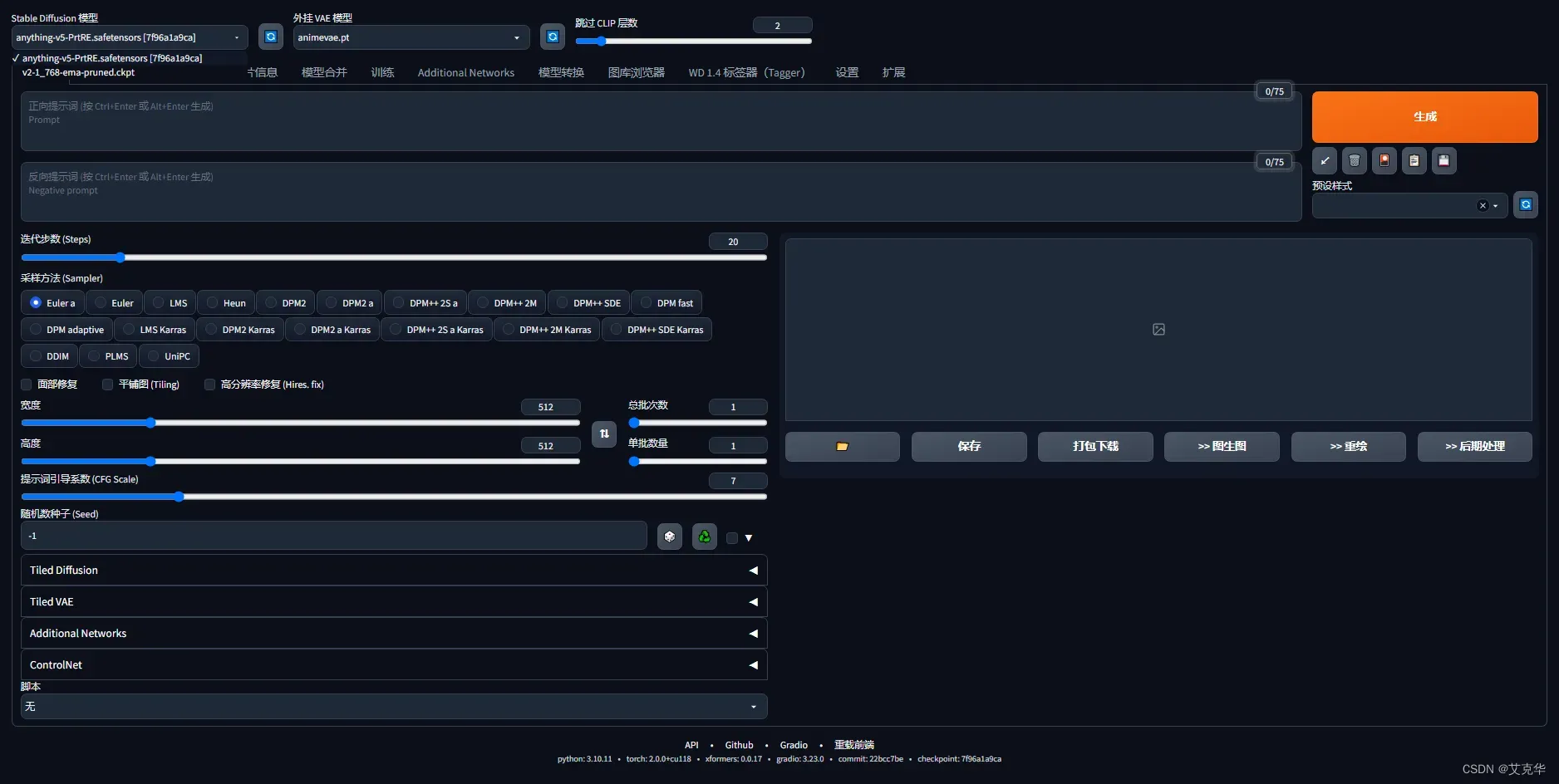
| 提示区 | 对于图像进行描述 |
|---|---|
| prompt | 告诉模型我想要什么样的风格或元素 |
| Negative prompt | 告诉模型我不想要什么样的风格或元素 |
| 参数调节区 | 用于控制和优化生成过程 |
|---|---|
| Sampling method | 扩散去噪算法的采样模式,不同采样模式会带来不一样的效果 |
| Sampling steps | 模型生成图片的迭代步数,每多一次迭代都会给 AI 更多的机会去对比 prompt 和 当前结果,从而进一步调整图片。更高的步数需要花费更多的计算时间,但却不一定意味着会有更好的结果。当然迭代步数不足肯定会降低输出的图像质量; |
| Width、Height | 输出图像宽高,图片尺寸越大越消耗资源,显存小的要特别注意。一般不建议设置的太大,因为生成后可以通过 Extras 进行放大; |
| Batch count、 Batch size | 控制生成几张图,前者计算时间长,后者需要显存大 |
| CFG Scale | 分类器自由引导尺度,用于控制图像与提示的一致程度,值越低产生的内容越有创意; |
| Seed | 随机种子,只要种子一样,参数和模型不变,生成的图像主体就不会剧烈变化,适用于对生成图像进行微调; |
| Restore faces | 优化面部,当对生成的面部不满意时可以勾选该选项; |
| Tiling | 生成一张可以平铺的图像; |
| Highres. fix | 使用两个步骤的过程进行生成,以较小的分辨率创建图像,然后在不改变构图的情况下改进其中的细节,选中该选项会有一系列新的参数,其中重要的是: |
| Upscaler | 缩放算法; |
| Upscale by | 放大倍数; |
Stable Disffusion 采样器
| 提示区 | 对于图像进行描述 |
|---|---|
| Euler a | 属于超快采样模式,采样10次,即可完成基本画面。但是继续提高采样步数,就基本脱离了提示词。是个插画,tag利用率仅次与DPM2和DPM2 a,环境光效菜,构图有时很奇葩 |
| Euler | 同属于超快采样模式,采样10次,即可完成基本画面,继续提高采样步数,会略微调整一下衣物的细节。柔和,也适合插画,环境细节与渲染好,背景模糊较深。 |
| LMS | 可能不太适合拟真画面,采样30次,仍然不能完成基本画面。 |
| Heun | 采样20次后,可以完成基本画面,继续提高采样步数,会略微调整一下衣物与背景的细节。单次出图平均质量比Euler和Euler a高,但速度最慢,高step表现好。 |
| DPM2 | 采样20次后,可以完成基本画面,继续提高采样步数,会改变背景的细节。 |
| DPM2 a | 采样20次后,可以完成基本画面,继续提高采样步数,会脱离提示词。 |
| DPM++ 2S a | 也属于超快采样,采样10次即可完成基本画面,采样20次会形成新风格,继续提高采样步数,则会脱离提示词。 |
| DPM++ 2M | 采样20次后,可以完成基本画面,继续提高采样步数,会完善人物衣物的细节,整体变化不大。 |
| DPM++ SDE | 基本是脱离提示词的状态,但用于生成人物特写似乎特别高效,采样5次即可生成较好的人物画面。 |
| DPM fast | 不太适合拟真画面,采样30次也是脱离提示词的状态。 |
| DPM adaptive,和 DPM++ SDE | 差不多基本都是脱离提示词的状态,但用于生成人物特写似乎特别高效,采样5次即可生成较好的人物画面,与 DPM++ SDE 不同的是人物特征比较固化。 |
| LMS Karras | 采样色彩较好,采样10次后,可以完成基本画面,随着采样步数的增加,会进一步完善人物与背景的细节。会大改成油画的风格,写实不佳。 |
| DPM2 Karras | 采样10次后,可以完成基本画面,随着采样步数的增加,会进一步完善背景的细节,人物变化不大。 |
| DPM2 a Karras | 不太适合拟真画面,完全脱离提示词,随着采样步数的增加,人物与背景的变化都很大,但细节比较多,适合随机绘画。几乎与DPM2相同,对人物可能会有特写 |
| DPM++ 2S a Karras | 也属于超快采样,采样5次即可完成基本画面,采样10次就会有较好的表现,但采样步数增多,反而会脱离提示词。 |
| DPM++ 2M Karras | 采样色彩较佳,随着采样次数的增加,人物及背景的细节都会得到相应的增强。看来大部分人使用它,都是为了获得更好的色彩和采样宽容性。 |
| DPM++ SDE Karras | 完全脱离了提示词,随着采样次数的增加,人物变化不大,背景变化较大,适合人物随机特写。 |
| DDIM | 严格遵循提示词,采样10次可以完成基本画面,只是效果一般,采样20次会有较好的表现,采样30次达到稳定画面。适合宽画,速度偏低,高step表现好,负面tag不够时发挥随意,环境光线与水汽效果好,写实不佳。 |
| PLMS | 不太适合拟真画面,采样30次还不能完成基本画面,人物出现动漫画的特征。单次出图质量仅次于Heun。 |
| UniPC | 采样20次可以完成基本画面,线条感较强,采样30次之后,开始向拟真人物发展。 |
大部分AI绘画研究者都选择使用 DPM++ 2M Karras,确实是因为这种采样模式在适配提示词、画面色彩及采样宽容性上的表现最好。
模型种类
大模型
大模型特指标准的latent-diffusion模型。拥有完整的TextEncoder、U-Net、VAE。
由于想要训练一个大模型非常困难,需要极高的显卡算力,所以更多的人选择去训练小型模型。
CKPT
CKPT格式的全称为CheckPoint(检查点),完整模型的常见格式,模型体积较大,一般单个模型的大小在7GB左右。
文件位置:该模型一般放置在*\stable-diffusion-webui\models\Stable-diffusion目录内。
小模型
小模型一般都是截取大模型的某一特定部分,虽然不如大模型能力那样完整,但是小而精,因为训练的方向各为明确,所以在生成特定内容的情况下,效果更佳。
常见微调模型:Textual inversion (Embedding)、Hypernetwork、VAE、LoRA等,下面一一进行介绍。
VAE
全称:VAE全称Variational autoencoder。变分自编码器,负责将潜空间的数据转换为正常图像。
后缀格式:后缀一般为.pt格式。
功能描述:类似于滤镜一样的东西,他会影响出图的画面的色彩和某些极其微小的细节。大模型本身里面自带 VAE ,但是并不是所有大模型都适合使用VAE,VAE最好搭配指定的模型,避免出现反效果,降低生成质量。
使用方法:设置 -> Stable-Diffusion -> 模型的 VAE (SD VAE),在该选项框内选择VAE模型。
文件位置:该模型一般放置在*\stable-diffusion-webui\models\VAE目录内。
【入门篇】AI绘画软件Stable Diffusion模型指南/Lora/VAE文件存放位置AI绘画插图1
Embedding
常见格式为pt、png、webp格式,文件体积一般只有几KB。
风格模型,即只针对一个风格或一个主题,并将其作为一个模块在生成画作时使用对应TAG在Prompt进行调用。
使用方法:例如本站用数百张海绵宝宝训练了一个Embedding模型,然后将该模型命名为HMBaby,在使用AI绘图时加载名称为HMBaby的Embedding模型,在使用Promat时加入HMBaby的Tag关键字,SD将会自动调用该模型参与AI创作。
文件位置:该模型一般放置在*\stable-diffusion-webui\embeddings目录内。
Hypernetwork
一般为.pt后缀格式,大小一般在几十兆左右。这种模型的可自定义的参数非常之多。
使用方法:使用方法:在SD的文生图或图生图界面内的生成按钮下,可以看到一个红色的图标,该图标名为Show extra networks(显示额外网络),点击该红色图标将会在本页弹出一个面板,在该面板中可以看到Hypernetwork选项卡。
文件位置:该模型一般放置在*\stable-diffusion-webui\models\hypernetworks目录内。
LoRA
LoRA的模型分两种,一种是基础模型,一种是变体。
目前最新版本的Stable-diffusion-WebUI原生支持Lora模型库,非常方便使用。
使用方法:在SD的文生图或图生图界面内的生成按钮下,可以看到一个红色的图标,该图标名为Show extra networks(显示额外网络),点击该红色图标将会在本页弹出一个面板,在该面板中可以看到Lora选项卡,在该选项卡中可以自由选择Lora模型,点击想要使用的模型将会自动在Prompt文本框中插入该Lora模型的Tag名称。
【入门篇】AI绘画软件Stable Diffusion模型指南/Lora/VAE文件存放位置AI绘画插图2
基础模型
名称一般为chilloutmix*,后缀可能为safetensors或CKPT。
基础模型存放位置:*\stable-diffusion-webui\models\Stable-diffusion目录内。
变体模型
变体模型存放位置:*\stable-diffusion-webui\models\Lora目录内。
是放在extensions下的,sd-webui-additional-networks文件夹下的models文件夹里的lora!!
不是主文件夹下的models,别放错了!!!
模型后缀解析
格式 描述
.ckpt Pytorch的标准模型保存格式,容易遭受Pickle反序列化攻击。
.pt Pytorch的标准模型保存格式,容易遭受Pickle反序列化攻击。
.pth Pytorch的标准模型保存格式,容易遭受Pickle反序列化攻击。
.safetensors safetensors格式可与Pytorch的模型相互格式转换,内容数据无区别。
其它 webui 特殊模型保存方法:PNG、WEBP图片格式。
Safetensors格式
Safetensors格式所生成的内容与ckpt等格式完全一致(包括NFSW)。
Safetensors格式拥有更高的安全性,
Safetensors比ckpt格式加载速度更快
该格式必须在2023年之后的Stable Diffusion内才可以使用,在此之间的SD版本内使用将无法识别。
Safetensors格式由Huggingface推出,将会逐渐取代ckpt、pt、pth等格式,使用方法上与其它格式完全一致。
Pickle反序列化攻击
可以将字节流转换为一个对象,但是当我们程序接受任意输入时,如果用户的输入包含一些恶意的序列化数据,然后这些数据在服务器上被反序列化,服务器是在将用户的输入转换为一个对象,之后服务器就会被任意代码执行。
模型训练
Embedding (Textual inversion)
可训练:画风√ 人物√ | 推荐训练:人物
配置要求:显存6GB以上。
训练速度:中等 | 训练难度:中等
综合评价:☆☆☆
Hypernetwork
可训练:画风√ 人物√ | 推荐训练:画风
配置要求:显存6GB以上。
训练速度:中等 | 训练难度:难
综合评价:☆☆
评价:非常强大的一种模型,但是想训练好很难,不推荐训练。
LoRA
可训练:画风? 人物√ 概念√ | 推荐训练:人物
配置要求:显存8GB以上。
训练速度:快 | 训练难度:简单
综合评价:☆☆☆☆
评价:非常好训练 好出效果的人物训练,配置要求低,图要求少。
备注:LoRA 本身也应该归类到 Dreambooth,但是这里还是分开讲。
Dreambooth / Native Train
可训练:画风√ 人物√ 概念√ | 推荐训练:Dreambooth 推荐人物,Native Train 推荐画风
配置要求:显存12GB以上。
训练速度:慢 | 训练难度:可以简单可以很难
综合评价:☆☆☆☆☆
评价:微调大模型,非常强大的训练方式,但是使用上会不那么灵活,推荐训练画风用,人物使用 LoRA 训练。
DreamArtist
显存要求6GB(4GB应该也可以),只需要(也只能)使用一张图完成训练,一般用于训练人物(画风没法抓住主次),优点是训练要求极低,成功率高,缺点是容易过拟合,并且不像Embedding可以跨模型应用,这个训练时使用什么模型应用时就要用什么,哪怕调一下CLIP参数生成结果都会完全跑飞。推荐每250步保存模型,后期用X/Y图脚本进行挑选。
模型后缀
仓库内一般存在多个模型文件,文件名后缀各不相同,这里简单介绍下文件名常见后缀及其含义:
ControlNet
ControlNet比之前的img2img要更加的精准和有效,可以直接提取画面的构图,人物的姿势和画
面的深度信息等等。有了它的帮助,就不用频繁的用提示词来碰运气,抽卡式的创作了。
instruct-pix2pix
在 stable-diffusion-webui 中的img2img专用模型 自然语言指导图像编辑 生成速度极快 ,仅需要几秒的时间。
FP16、FP32
代表着精度不同,精度越高所需显存越大,效果也会有所提升。
512|768
代表着默认训练分辨率时512X512还是768X768,理论上默认分辨率高生成效果也会相应更好。
inpaint
代表着是专门为imgtoimg中的inpaint功能训练的模型,在做inpaint时效果会相对来说较好。
depth
代表此模型是能包含处理图片深度信息并进行inpainting和img2img的
EMA
模型文件名中带EMA一般意味着这是个用来继续训练的模型,文件大小相对较大
与之相比,正常的、大小相当较小的那个模型文件是为了做推理生成的
对于那些有兴趣真正理解发生了什么的人来说,应该使用EMA模型来进行推理
小模型实际上有EMA权重。而大模型是一个 “完整版”,既有EMA权重,也有标准权重。因此,如果你想训练这个模型,你应该加载完整的模型,并使用use_ema=False。
EMA权重
就像你作为一个学生在接受训练时,也许你会在最后一次考试表现较差,或者决定作弊并记住答案。所以一般来说,通过使用考试分数的平均值,你可以更好地了解到学生的表现,
由于你不关心幼儿园时的分数,如果你只考虑去年的分数(即只用一组最近的实际数据值来预测),你会得到MA(moving average 移动平均数). 而如果你保留整个历史,但给最近的分数以更大的权重,则会得到EMA(exponential moving average 指数移动平均数)。
这对具有不稳定训练动态的GANs来说是一个非常重要的技巧,但对扩散模型来说,它其实并不是那么重要。
VAE
VAE模型文件并不能和正常模型文件一样独立完成图片生成。
Stable Diffusion资源列表
好的生成质量离不开好的模型, 除了标准模型外,Stable Diffusion还有其他几种类型的模型,models目录下每一个子目录就是一种类型的模型,其中用的最多的是LoRA模型。
1、Hugging Face Stable Diffusion、ControlNet的官方仓库 是一个专注于构建、训练和部署先进开源机器学习模型的网站,目前平台上有270多个与Stable Diffusion相关的模型,用”Stable Diffusion”作为关键字就能搜到。
2、C 站: https://civitai.com/
下载一个模型放在这个文件夹下:
[stable-diffusion-webui安装目录]\models\Stable-diffusion
##模型介绍
1、Dreamlike Photoreal 2.0这个模型,这是一个由Dreamlike.art制作的基于Stable Diffusion v1.5的真实感模型,生成效果非常接近真实照片。
2、LoRA(Low-Rank Adaptation)里面多是Lora或其它NSFW等模型的仓库 模型是小型稳定扩散模型,可对标准模型进行微调。它通常比标准模型小10-100倍,这使得LoRA模型在文件大小和训练效果之间取得了很好平衡。LoRA无法单独使用,需要跟标准模型配合使用,这种组合使用方式也为Stable Diffusion带来了强大的灵活性。
LoRA模型下载后需要放到Lora目录中,使用时在提示中加入LoRA语法,语法格式如下:
<lora:filename:multiplier>
filename是LoRA模型的文件名(不带文件后缀)
multiplier 是LoRA 模型的权重,默认值为1,将其设置为 0 将禁用该模型。
3、Discord:公共聊天软件,如果有需要可行前往搜索相应频道。
4、四比三备份站:国内备份模型和参考图的网站,可以直接下载。
5、Reddit:公共交流社区,如果有需要可行前往搜索相应频道。
DollLikeness 模型
中日韩超火AI绘画模型KoreanDollLikeness+JapaneseDollLikeness+Taiwan更新
koreanDollLikeness_v15.safetensors – Google 云端硬盘
taiwanDollLikeness_v10.safetensors – Google 云端硬盘
japaneseDollLikeness_v10.safetensors – Google 云端硬盘
把下载的 ChilloutMix-NI模型放到 novelai-webui-aki-v2\models\Stable-diffusion内。下载的Doll Likeness模型放到 novelai-webui-aki-v2\models\Lora内 模型就准备完成
3、GFPGAN
这是腾讯旗下的一个开源项目,可以用于修复和绘制人脸,减少stable diffusion人脸的绘制扭曲变形问题
地址:https://github.com/TencentARC/GFPGAN
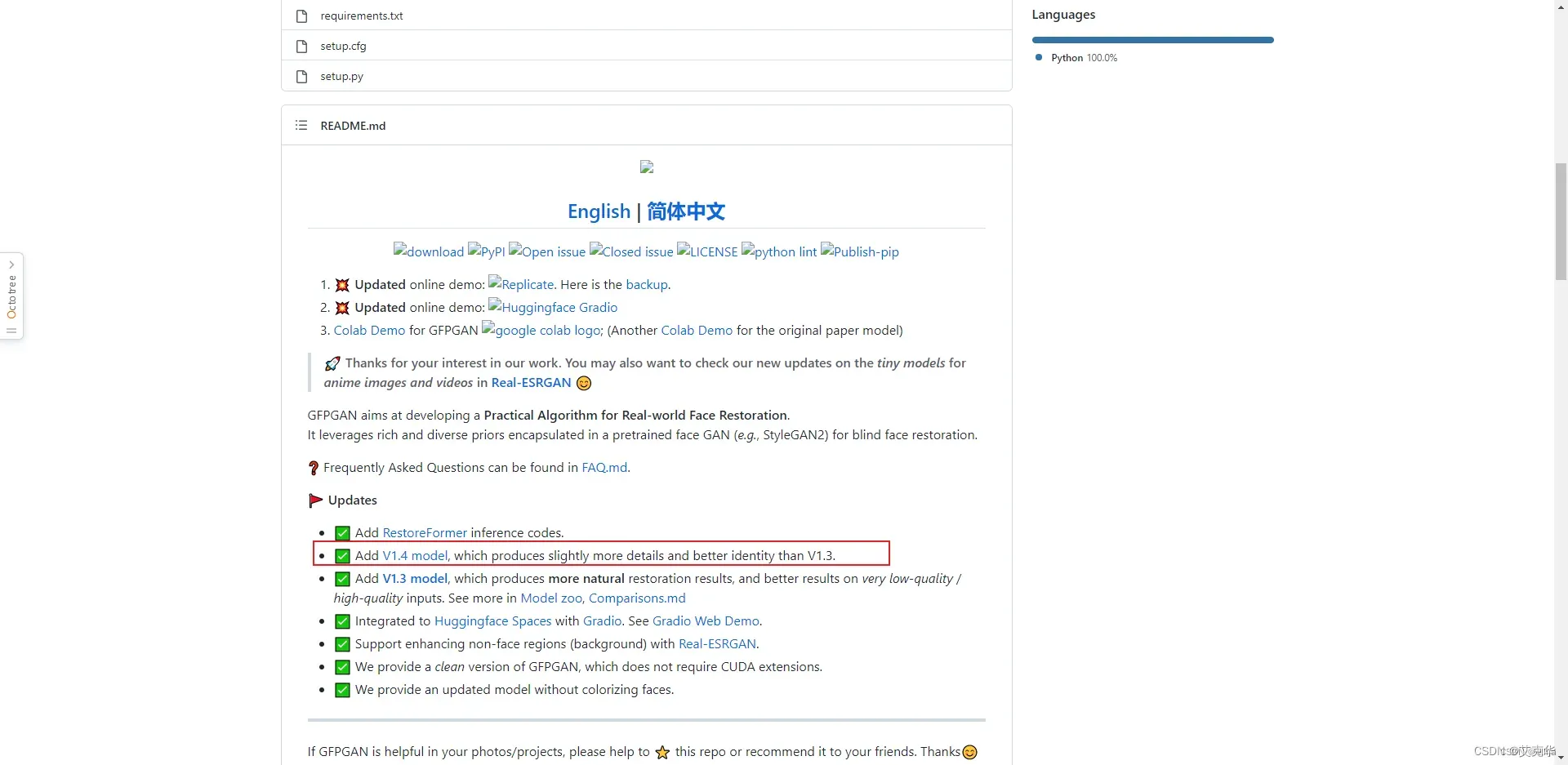
点击蓝色的1.4就可以下载。
下载好之后,放在sd-webui项目的根目录下面即可,比如我的根目录是D:\stable-diffusion-webui
5款好用的动漫风格模型
本次文章模型测试展示图片都将使用相同的关键词、设置相同的参数,采样方法(Sampler)选择了 DPM++ 2M Karras, 采样迭代步数(Steps):25,CFG scale: 7,不额外使用LoRA模型和其他辅助的插件,大家可以通过参考样张选择适合的模型进行使用。
本次图片分为2次图片展示,分别为复杂关键词和简单关键词对比。
复杂关键词为:<(masterpiece:1.3), (best quality:1.2)>, (collared shirt:1.6), <high resolution illustration, coloful, chromatic aberration, intricate details, (cinematic light, rim lighting), (beautiful and clear background), depth of field, (finely detailed face), (prettyface)>, scenery, white shirt, (white kneesocks:1.3), beautiful garden, detailed garden, window, garden, flowers, dynamic_pose, light_particles, 1girl, cowboy shot, solo, (white_hair, short_hair, green eyes):1.2, looking at viewer, (black pleated skirt, black suspenders:1.4), (beautiful small city, detailed small city, steampunk, many object),
简单关键词为:1girl, (hanfu), sidelighting, wallpaper
OK,那让我们展示一下,不同模型最终的表现效果吧!若有喜欢的模型可自行复制大模型名称,前往C站搜索即可下载了。
MeinaPastel(美娜粉彩)

MeinaPastel目前已经更新到了V4版本,V1-V3版本模型在C站也可以进行下载,根据作者的介绍MeinaPastel旨在通过良好的光线,阴影和细节制作具有2d感觉的插图,制作柔和 或彩色图像!
TMND-Mix(TMND-混合)
TMND-Mix目前有6个版本的模型,最新版本为TMND-Mix_III,最新版本的模型有更好的 2D 性能/更好的 2D 表现,作者推荐Upscaler/放大算法:R-ESRGAN 4x+、去噪强度/重绘广度:0.25-0.35、可添加VAE:ClearVAE一起使用。

Cetus-Mix(鲸鱼座混合)
Cetus-Mix目前有9个版本的模型,作者比较推荐的版本选择建议:推荐使用V2f、V3、Coda和V3.5 ,尤其是CODA ,适合初次使用的用户。Highres.fix:SwinIR_4x

MeinaMix(美娜美娜)
MeinaMix目前在C站有14个版本的大模型,最新的版本为Meina V9,模型作者提示:MeinaMix 的目标是能够 在很少提示的情况下完成出色的艺术创作。作者推荐的采样器为:Euler a: 40~60 steps和DPM++ SDE Karras: 30~60 steps,所以这次测试可能有所偏差。

Counterfeit-V3.0(仿冒-V3.0)
Counterfeit目前有3个版本模型,最新模版版本为v3.0,介绍为:高质量的动漫风格模型。

通过复杂关键词和简单关键词的图片对比,通过关键词这些模型都可以较好的复原我们的设置的关键词,在简单关键词时,生成的图片效果也比较理想并且在风格上也各有差异,大家可以根据自己的喜好进行选择模型。
文章出处登录后可见!