foreword
图像卷积神经网络(Convolution Neural Network ,CNN)是通过Kernel对图像Tensor进行卷积(废话 )从而提取出高维向量,对图像进行分类,目标识别,语义分割。写网络的过程中,不由得好奇每个层中图像被提取出了什么特征,所以简单编写了一个以Yolov3为例的特征层可视化函数。
一、Yolov3
Yolov3是一个目标识别卷积神经网络,该网络均由Convolutional layer组成,一个Convolutional layer包括一个Conv2d层,一个BN层和一个LeakyReLU层组成。
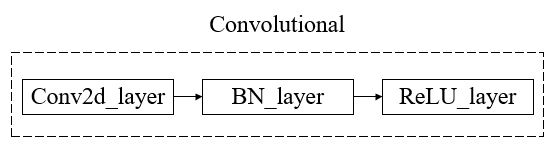
1.Darknet53
Yolov3的主干网络被称为Darknet53,是在Darknet基础上的魔改网络,其结构为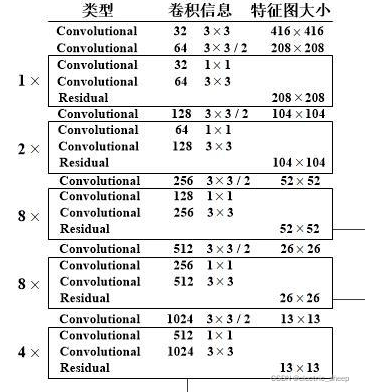
其中两个Convolutional又组成了一个Residual块,一共有23个残差块。
这里根据输出Tensor的shape不同将网络特征层分为5个部分进行依次输出,对backbone的每层残差块进行特征层可视化。
2. 特征图像可视化
1.可视化函数
特征层的可视化实际上是卷积层输出的分层输出
只需要将每一个块的输出压缩batch维度后进行逐层转换为array并保存即可。
import os
import cv2
import numpy as np
import torch
import torch.nn as nn
def to_image(input_tensor, channel, layer_name):
print("input_tensor_size===>",input_tensor.shape)
img_out = input_tensor[:1,channel,:,:]
img_out = img_out.squeeze()
img_out = img_out.unsqueeze(dim = 0)
print(img_out.shape)
with torch.no_grad():
img_out = np.array(img_out.permute(1,2,0) * 255)
save_path = f"featuremap/{layer_name}/"
if os.path.exists(save_path):
pass
else:
os.makedirs(save_path)
cv2.imwrite(save_path + f"out{channel}.jpg", img_out)
该函数的输入有三个,分别是input_tensor, channel, layer_name,对应输入tensor(即每个块的输出),分离通道维度(即将第几个维度输出为图像,一般循环使用)和该块的名称。
最终会将结果保存到当前路径下的featurmap文件夹下。
为了尽可能小的对网络结构进行修改,我们直接将函数引入到网络的forward()函数中,在每次调用网络时就可以进行自动保存了。
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu1(out)
''' 保存特征层图像'''
out = self.block1(out)
for i in range(out.shape[1]):
to_image(out,i,"backbone_block1")
out = self.block2(out)
for i in range(out.shape[1]):
to_image(out,i,"backbone_block2")
out1 = self.block3(out)
for i in range(out1.shape[1]):
to_image(out1,i,"backbone_block3")
out2 = self.block4(out1)
for i in range(out2.shape[1]):
to_image(out2,i,"backbone_block4")
out3 = self.block5(out2)
for i in range(out3.shape[1]):
to_image(out3,i,"backbone_block5")
以上代码实现了五层残差块的卷积结果的输出
2.特征可视化
设置好网络后,还需要准备输入图像和权重。
以最近数学建模中的特征增强图像为例。
该图像shaoe为640*480*3,在输入进网络前可以进行cv2.resize(img, (416, 416))也可以不进行。
初始化网络并加载权重:
if __name__ == "__main__":
from nets import yolo3
from nets.yolo3 import YoloBody
from utils.config import Config
net = yolo3.YoloBody(Config)
model_weights = torch.load("logs/Epoch100-Total_Loss20.2089-Val_Loss26.2946.pkl", map_location=torch.device("cuda"))
net.load_state_dict(model_weights)
img = np.array(cv2.resize(cv2.imread("img_load_demo/class1/0_liner_avg_1_144.16.jpg"),(416,416)), dtype = np.float32)
img = torch.from_numpy(img)
img = img.unsqueeze(dim = 0).permute(0,3,1,2)
out0,out1,out2 = net(img)
print("out.grad===>",out0.requires_grad)
print("out.size===>",out0.size())
print("out.size===>",out1.size())
print("out.size===>",out2.size())
以上代码权重变量为model_weights,图像变量为img,修改这两个可以改变网络权重与卷积图像。在输出每个残差块的特征图像同时也会输出最后三个残差块的输出尺寸。因为之前训练的类为500,输入图像为416*416*3所以最终输出的三个输出如下。
out.size===> torch.Size([1, 1515, 13, 13])
out.size===> torch.Size([1, 1515, 26, 26])
out.size===> torch.Size([1, 1515, 52, 52])
输出文件夹featuremap会有五个block的文件夹,图像数量分别对应每层残差块的层数(即第二维度数量),分别为(64,128,256,512,1024)个文件。
block1的特征图像
block4的特征图像

可以发现随着层数加深,图像尺寸也越来越小,这与网络输出的Tensor3,4维度的尺寸相同。
Summarize
以上仅是对Yolov3的主干网络残差块进行特征可视化,YoloBody与内部各个卷积层的可视化道理相同。但是需要对forward()和nn.Module进行一点修改,读者可以自行尝试。
文章出处登录后可见!