openPCdet 代码框架
openPCdet是由香港中文大学MMLab实验室开源的轻量话激光雷达点云目标检测框架,它定义了一种统一的3D坐标系以及采用了数据与模型分离的高层代码设计思想,使用起来非常方便,具体介绍可以看下面的链接:
点云3D检测开源库
项目github地址
实现自定义数据集导入的过程
- 基于模板类dataset实现自定义数据集类的编写(可以仿照kitti编写)
- 编写自定义数据集类的配置文件(yaml)编写
- 编写网络配置文件
实现了以上步骤之后,就可以开始训练了,下面附上我训练过程中的图片,这里采用的是pointpillar网络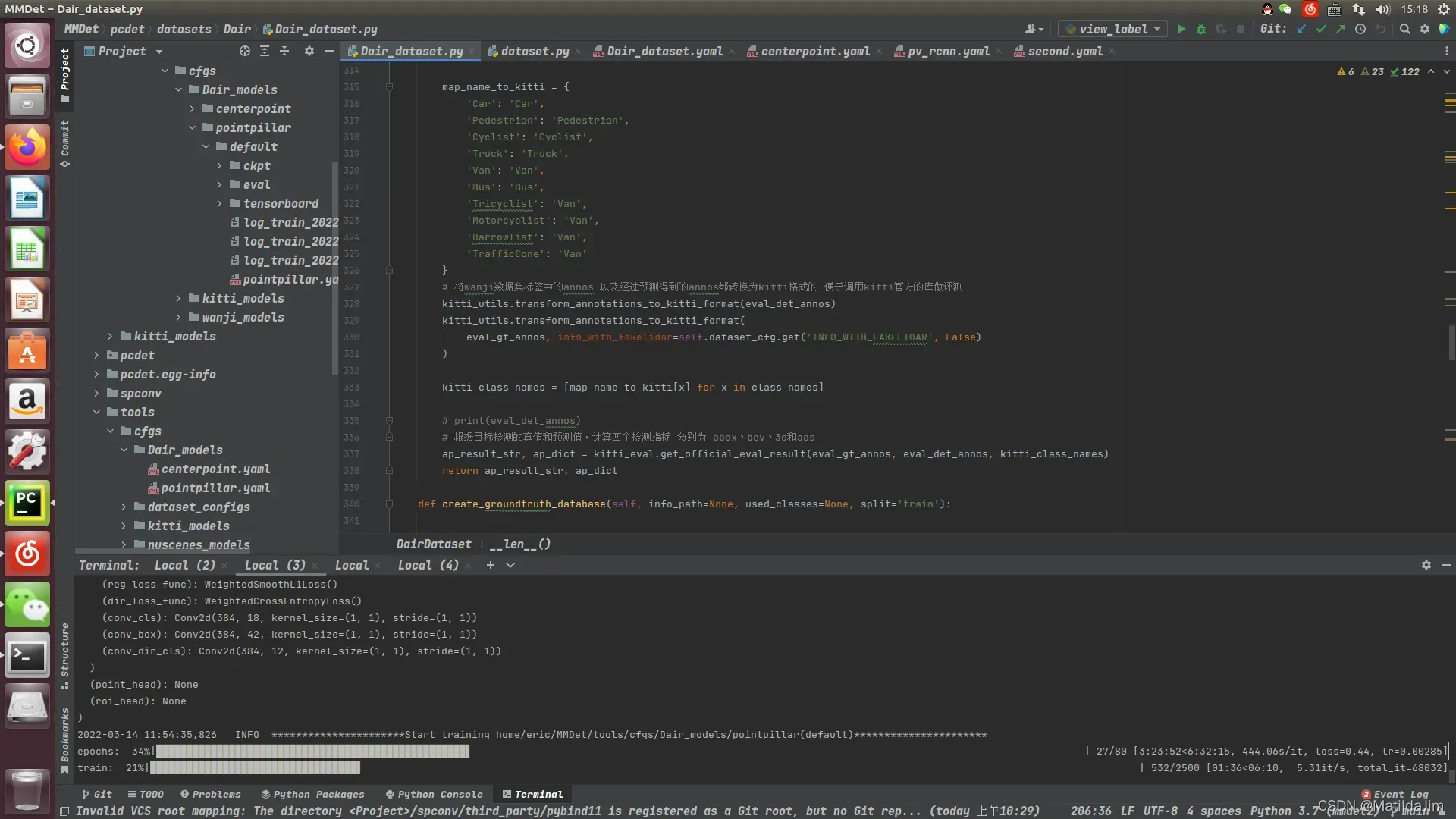
编写自定义数据集类
首先需要继承模板类dataset,下面是其中的基本方法 类结构: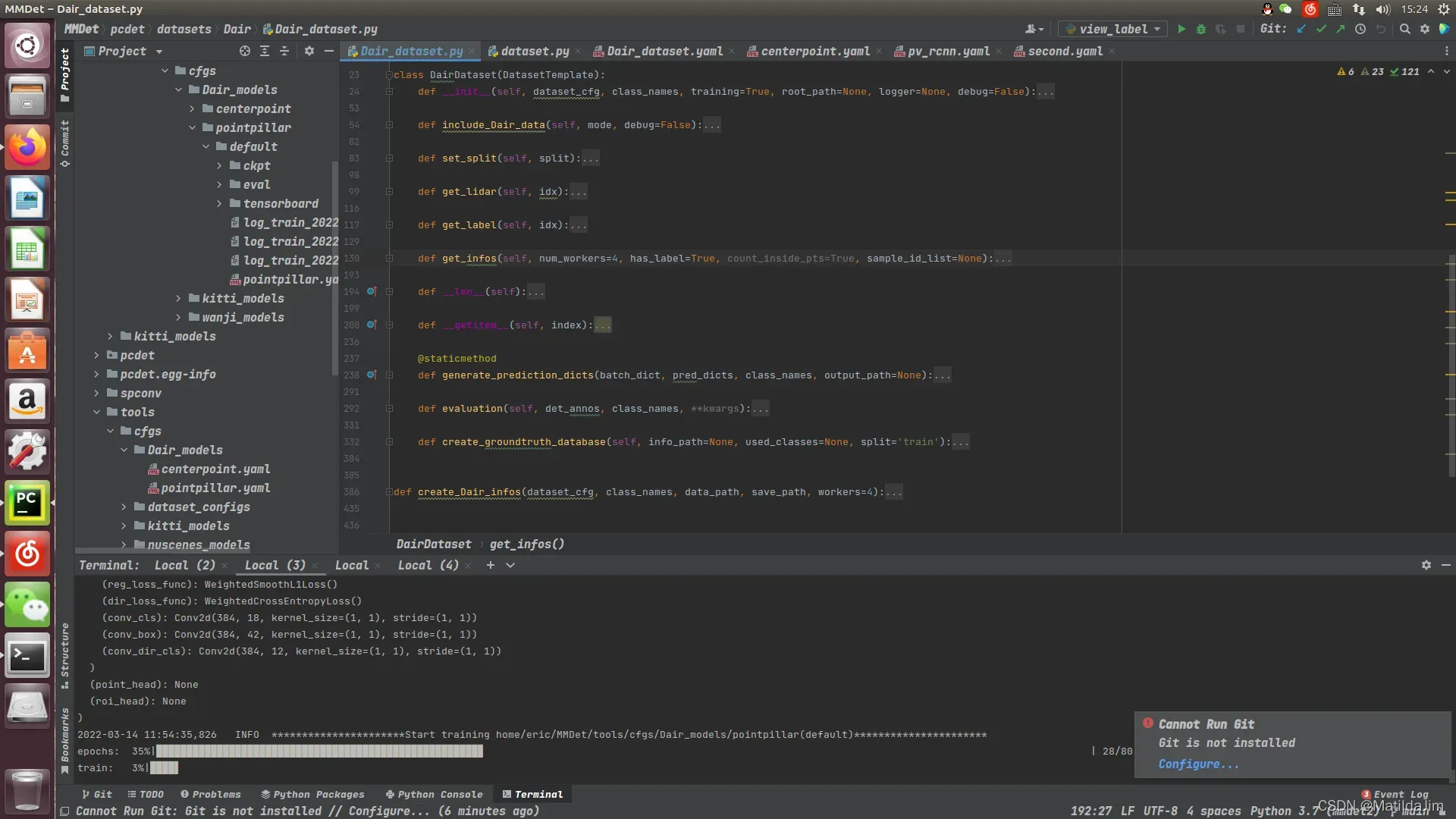
其中比较重要的就是getlidar(),getlabel()方法的实现,这两个方法实现了获取点云数据以及获取点云标签。然后需要注意在get_info()中需根据不同的数据集标注文件中3D坐标系的定义构建不同的坐标转换方式转换到统一的3D坐标系中。
我这里用的是万机发布的路边激光雷达数据集。代码如下:
def get_lidar(self, idx):
"""Loads point cloud for a sample
Args:
index (int): Index of the point cloud file to get.
Returns:
np.array(N, 4): point cloud.
"""
# 获取雷达数据 root_split_path=/data/wanji/ training或者testing
lidar_file = self.root_split_path / 'velodyne' / ('%s.bin' % idx)
# 如果该文件不存在直接报错
# print(lidar_file)
assert lidar_file.exists()
return np.fromfile(str(lidar_file), dtype=np.float32).reshape(-1, 4)
def get_label(self, idx):
# 获取标签数据
label_file = self.root_split_path / 'label' / ('%s.txt' % idx)
# 调用get_objects_from_label函数,首先读取该文件的所有行赋值为 lines
# 在对lines中的每一个line(一个object的参数)作为object3d类的参数 进行遍历,
# 最后返回:objects[]列表 ,里面是当前文件里所有物体的属性值,如:type、x,y,等
assert label_file.exists()
# print(label_file)
objects = []
with open(label_file, 'r') as f:
for i in f.readlines():
object1 = i.strip('\n').split(',')
# print(object1)
objects.append(object1)
return objects
根据万集数据集标注文件,重写get_info()函数如下:
def get_infos(self, num_workers=4, has_label=True, count_inside_pts=True, sample_id_list=None):
import concurrent.futures as futures
# 线程函数
def process_single_scene(sample_idx):
# print('%s sample_idx: %s' % (self.split, sample_idx))
# 定义info空字典
info = {}
# 点云信息:点云特征维度和索引
pc_info = {'num_features': 4, 'lidar_idx': sample_idx}
# 添加到点云信息
info['point_cloud'] = pc_info
if has_label:
# 根据索引读取label,构造object列表
obj_list = self.get_label(sample_idx)
# print(obj_list)
# 创建标签信息空列表
annotations = {}
# 根据属性将所有obj_list的属性添加进annotations
annotations['type'] = np.array([int(obj[1]) for obj in obj_list])
# 总物体的个数 10个
num_gt = len(annotations['type'])
names = np.empty(num_gt, dtype="U30")
j = 0
for i in annotations['type']:
name = self.id_to_type(i)
# print(name)
names[j] = name
# print(names.dtype)
j = j + 1
annotations['name'] = names.reshape(num_gt)
# print(annotations['name'])
annotations['x'] = np.array([float(obj[2]) for obj in obj_list]).reshape(num_gt, 1)
annotations['y'] = np.array([float(obj[3]) for obj in obj_list]).reshape(num_gt, 1)
annotations['z'] = np.array([float(obj[4]) for obj in obj_list]).reshape(num_gt, 1)
annotations['l'] = np.array([float(obj[7]) for obj in obj_list]).reshape(num_gt, 1)
annotations['w'] = np.array([float(obj[8]) for obj in obj_list]).reshape(num_gt, 1)
annotations['h'] = np.array([float(obj[9]) for obj in obj_list]).reshape(num_gt, 1)
annotations['rotation_y'] = np.array([float(obj[6]) for obj in obj_list]).reshape(num_gt, 1)
# annotations['score'] = np.array([float(obj[12]) for obj in obj_list]).reshape(num_gt, 1)
# print(annotations['x'].shape)
x = annotations['x'] / 100
y = annotations['y'] / 100
z = annotations['z'] / 100
l = annotations['l'] / 100
w = annotations['w'] / 100
h = annotations['h'] / 100
# wanji数据集中3Dbbox角度是相对于y轴正方向 且正方向为顺时针角度 需要进行坐标角度转换
# 在统一坐标系下 heading是相对于x轴的夹角 并且逆时针方向为正
rots = annotations['rotation_y'] * (np.pi / 180)
# print(rots)
# (N, 7) [x, y, z, dx, dy, dz, heading]
gt_boxes_lidar = np.concatenate([x, y, z, l, w, h, rots], axis=1)
# print(gt_boxes_lidar.shape)
annotations['gt_boxes_lidar'] = gt_boxes_lidar
# print(annotations)
# 添加注释信息
info['annos'] = annotations
# print(info)
# 最后得到的info信息:
# info['point_cloud'] = pc_info
# info['annos'] = annotations
return info
sample_id_list = sample_id_list if sample_id_list is not None else self.sample_id_list
# 创建线程池,多线程异步处理,增加处理速度
with futures.ThreadPoolExecutor(num_workers) as executor:
# map返回一个迭代器,其中的回调函数的参数 最好是可以迭代的数据类型,如list;如果有 多个参数 则多个参数的数据长度相同;
# 如: pool.map(work,[[1,2],[3,4]],[0,1]]) 中 [1,2]对应0 ;[3,4]对应1 ;其实内部执行的函数为 work([1,2],0) ; work([3,4],1)
# map返回的结果 是 有序结果;是根据迭代函数执行顺序返回的结果
# 使用map的优点是 每次调用回调函数的结果不用手动的放入结果list中
infos = executor.map(process_single_scene, sample_id_list)
# infos是一个列表,每一个元素代表了一帧的信息(字典)
return list(infos)
大概比较重要的就是上面的三个方法的实现,由于我是仿照kitti实现的,所以也学习了kitti制作了pkl格式文件实现了数据的预加载,即在训练之前需要create_info,调用如下语句即可:
python -m pcdet.datasets.Dair.Dair_dataset create_Dair_infos tools/cfgs/dataset_configs/Dair_dataset.yaml
数据准备好后,就可以开始训练了
文章出处登录后可见!
已经登录?立即刷新