
【专栏:前沿进展】2 月 17 日,澳大利亚阿德莱德大学副教授吴琦在青源 Talk 第 12期中带来了题为「视觉-语言导航新进展:Pre-training与Sim2Real」的报告。
吴琦首先简要介绍了「视觉-语言」导航任务的发展历史,进而介绍了考虑历史信息和顺序关系的VLN 预训练方法 HOP。
由于仿真环境和现实场景存在一定的差距,吴以如何将离散环境下训练的 VLN 模型应用于连续环境为例,提出了 Sim2Real 的研究课题。
本文整理自青源Talk第十二期,视频回看地址:https://event.baai.ac.cn/activities/247
Author: Wu Qi
Arrangement: Xiong Yuxuan
Editor: Li Mengjia
01
视觉语言行为
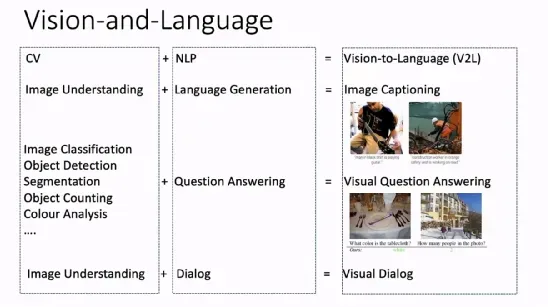
计算机视觉(CV)和自然语言处理(NLP)早先是两个较为独立的研究领域。CV 重点关注如何用计算机代替人眼对目标完成识别、跟踪、测量等任务,对图像进行处理;NLP 则研究计算机如何处理、运用自然语言,包括语言生成、问答、对话等任务。近年来,以深度神经网络为代表的机器学习和模式识别技术被广泛应用于 CV 和 NLP 领域,取得了目前最先进的效果。
人类可以同时使用视觉和语言这两方面的能力来完成一系列任务,CV 与 NLP 的结合(V2L)也成为了人工智能研究领域的重要课题,可以拓展这两个方向的重要应用。例如,将图像理解和语言生成任务结合起来构成了图像描述(image captioning)任务;将图像分类、目标检测、图像分割、目标技术、颜色分析等 CV 任务与问答任务结合起来就构成了视觉问答任务;将图像理解和对话任务结合起来就构成了视觉对话任务。
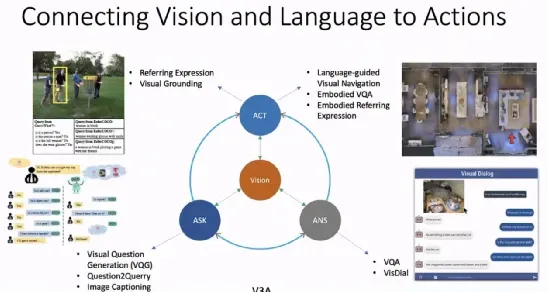
近年来,研究者们试图将动作控制也引入到「视觉-语言」任务的框架中。吴琦将此类任务命名为V3A(Vision, Ask, Answer, Act),在给定视觉输入后,我们希望机器能够提出问题、回答问题、并通过和人以及机器之间的语言交流执行某些动作。
例如,「Vision+Ask」的任务包含视觉问题生成、根据问题生成查询、图像描述等;「Vision+Answer」的任务包含视觉问答、视觉对话等;「Vision+Act」的任务包含指称表达、视觉对齐(visual grounding)、语言引导的视觉导航、具身视觉问答、具身指称表达等。

具身人工智能是目前的热门研究领域,它要求智能体能够感知周围环境,做出相应的决策,完成看、说、听、做、推理等任务。
02
视觉语言导航

如上图所示,在基于视觉与语言的导航(VLN)任务中,给定自然语言指令(走出浴室。左转,通过左侧的门离开房间。在那里等待。),希望智能体在虚拟环境中理解语言指令,并遵循该指令,按照给定的路线完成导航,到达规定的目的地。
第一篇 VLN 的工作发表于 2018 年的 CVPR,我们当时考虑如何把视觉-预言技术用于机器人,实现具身视觉。由于导航是机器人学中一个非常主流的研究方向,我们选定它作为首先尝试的任务。
对于人类而言,命令一个 5 岁左右的孩子为我们拿来勺子是一个很简单的任务。但是让机器人根据人类的语言指令完成该任务还是很困难的。因此,我们将该任务命名为「Bring Me a Spoon」。
自 2018 年起,「视觉-语言导航」就成为了继视觉问答、视觉对话之后一项重要的「视觉-语言」任务,许多机器人学方向的研究人员也加入到了这一研究队伍中。至今,已经出现了许多新的数据集(例如,REVERIE、RxR,以及一些户外的数据)和新的网络架构。
03
用于 VLN 的考虑历史和顺序的预训练(HOP)
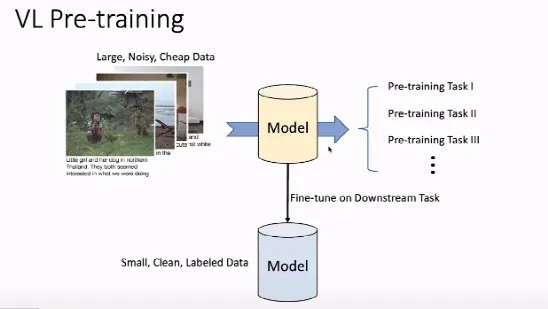
预训练技术在 CV 和 NLP 领域都扮演着重要的角色(例如,CV 领域的 ViT,NLP 领域的 Bert)。在图像描述、视觉问答等「视觉-语言」任务中,预训练技术也都在各大排行榜中占据了榜首位置。
如上图所示,主流的视觉语言预训练模型主要是在大规模、嘈杂、缺乏准确的人工标注数据上设计预训练任务,从而获得视觉和语言的丰富表征.在表示的过程中,我们需要匹配视觉-语言概念。
在获得良好表征的模型后,我们可以将其应用于下游任务,在小规模、噪音较小、人工标注的数据集上对其进行微调,以执行下游任务。

然而,直接将 VLBert 等预训练的视觉-语言模型直接用于视觉-语言导航任务的效果并不理想。这是由于 VLN 是较为特殊的视觉-语言任务。首先,它是一个部分可见的马尔科夫决策过程(POMDP),其决策非常依赖过去观测到的经验。同时,VLN 是一个时空任务,对于轨迹的序列顺序十分敏感。
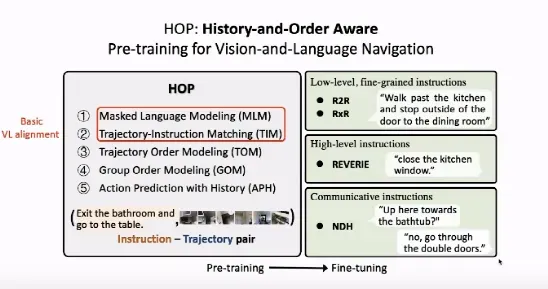
我们考虑针对 VLN 任务设计一系列新的预训练任务,使视觉语言预训练模型可以被用于 VLN 任务。预训练的输入是「指令-轨迹」。在这里,我们考虑三类 VLN 数据集:(1)底层细粒度指令:R2R、RxR 等数据集。给出详细的指令例如:走过厨房,在餐厅的门外停下(2)顶层指令:REVERIE 等数据集。并未给出详细指令,仅给出大致位置和最终目标,例如:关上厨房窗户(3)对话式指令:NDH 等数据集。人和机器、机器和机器之间存在对话,通过对话帮助机器人完成导航。针对以上四个数据集,我们试图统一预训练一个 VLN 模型,分别在每个数据集上进行微调。
如上图所示,我们设计了 5 类预训练任务。其中,掩码语言建模(MLM)、轨迹-指令匹配(TIM)等任务属于常见的 VL 对齐任务,旨在将视觉-语言的语义概念对齐起来。在 MLM 任务中,我们将指令中的若干词语「遮盖」掉,希望通过上下文中的信息预测出被「遮盖」的词语。
在 TIM 任务中,给定环境中的轨迹以及一段对轨迹的描述,模型需要判断二者是否匹配。针对 VLN 任务中的行走顺序,我们设计了轨迹顺序建模(TOM)、分组顺序建模(GOM)任务。为了利用部分可见马尔科夫决策过程中的历史信息,我们设计了考虑历史信息的动作预测任务(APH)。
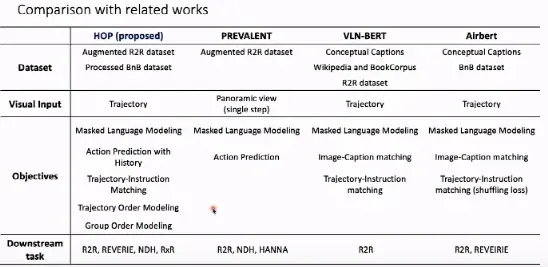
在上图中,我们从数据、视觉输入、训练目标、下游任务四个方面将 HOP 与目前最先进的工作(PREVALENT、VLN-BERT、Airbert)进行了对比。对比方法之间的差异主要体现在训练目标上,所有方法都使用了 MLM 预训练任务,但是只有 HOP 针对 VLN 任务的特性设计了新的预训练任务。此外,除了室外导航任务,HOP 在大多数主流的室内导航任务数据集上都进行了微调,测试了模型的性能。
04
模型框架
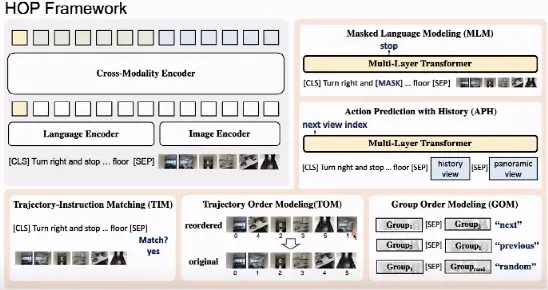
HOP 由一个单流 Transformer 跨模态编码器和5 个下游任务的预测头(MLM、TIM、TOM、GOM、APH)组成。模型的输入为轨迹指令的序列和轨迹图片序列,通过[SEP] 将这两个部分分隔开来。
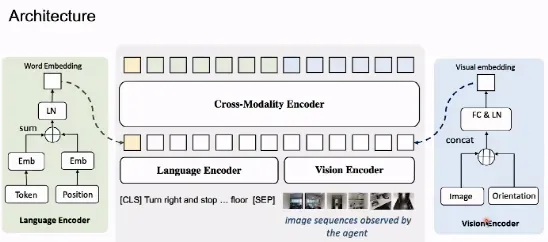
在 Transformer 跨模态编码器中,对于语言指令,我们首先将 Token 嵌入与位置编码嵌入相加,再将求和结果输入给层归一化模块,从而得到对词语的嵌入。对于轨迹中的图像,我们为每个图像设置一个方向角度,将其作为位置编码与图像的嵌入连接起来,形成新的特征。再通过全连接层和层归一化模块处理得到的连接特征,从而得到视觉嵌入。
一、预训练任务——MLM
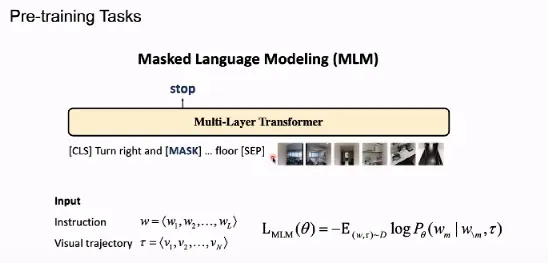
在 MLM 任务中,我们首先遮蔽掉若干单词,根据输入上下文预测遮蔽掉的单词,这是一个分类任务。
二、预训练任务——TIM

在 TIM 任务中,我们随机选取一段完整的预言指令和一组轨迹图像,模型需要判断指令与图像序列是否匹配,这是一个二分类问题。
三、预训练任务——TOM
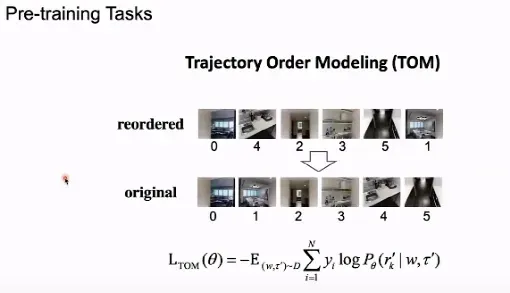
在 TOM 任务中,我们输入一段乱序的轨迹图像序列,要求模型能够恢复出正确的图像顺序,从而将人类行走的常识赋予模型。
四、预训练任务——GOM
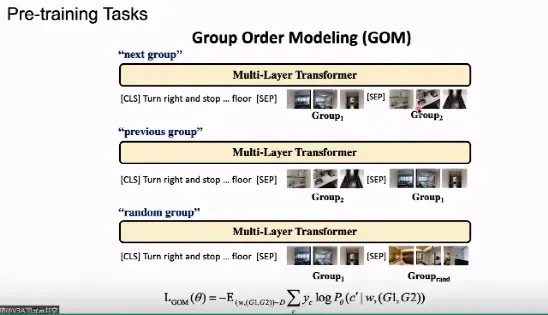
在 GOM 任务中,我们将输入给 Transformer 的轨迹图像分为两组,并将这两组图像的顺序打乱,模型需要识别轨迹图像的顺序以及是否与语言指令相匹配。
五、预训练任务——APH
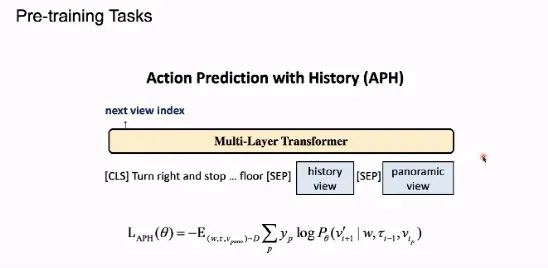
在 HOP 任务中,我们要求模型利用历史数据对下一步动作进行预测。我们将模型根据指令执行的历史数据(图像序列)输入 Transformer,并且将最后位置的 360 度全景图像输入给模型。我们希望模型根据语言指令和历史数据决定在 360 度的图像中应该往哪个方向继续行走。
05
下游任务微调效果

针对不同的下游任务,我们考虑使用不同的评价指标。R2R 数据集主要考虑导航的准确率,其评价指标包含成功率(SR)、导航误差(NE)、根据路径长度加权的成功率(SPL);REVERIE 主要考虑 RGS 指标;RxR 主要考虑语言指令和实际所走的路径是否匹配,采用 DTW 作为评价指标。
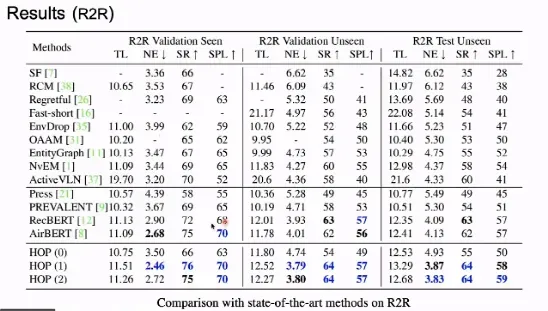
在我们的实验中,我们考虑了三种设置:
(1)不使用预训练的 Transformer 架构
(2)仅仅使用 PREVALENT 中的数据进行预训练
(3)使用 PREVALENT 以及处理过后的 AirBnB 自动生成的导航数据进行预训练。
如上图所示,使用预训练技术之后的模型性能整体优于不使用预训练时的效果。相较于 PREVALENT,HOP 在加入了新的预训练任务后得到了显著的性能提升,在加入了 AirBnB 的数据后,模型的性能得到了微弱提升,这可能是由于 AirBnB 中的数据噪声较多。此外,在 REVERIE 、NDH、RxR 等数据集上,HOP 都取得了最优的性能。
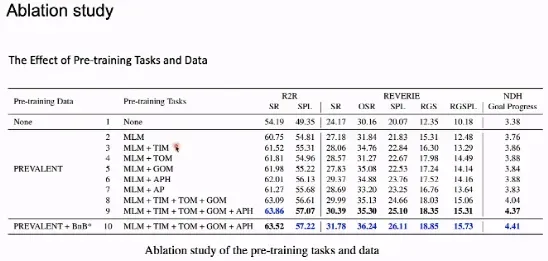
在 ablation study 中,我们发现所有引入的预训练任务对于最终性能的提升都是有效的。在动作预测任务中,使用历史数据相较于不使用历史数据有较大的性能提升。同时使用所有预训练任务得到的模型性能最优。

在本文中,我们发现在 VLN 任务的预训练中引入历史信息十分重要,顺序信息在 VLN 预训练中也发挥了重要作用。
06
Sim2Real

在 Sim2Real 中,我们试图缩小离散环境和连续环境的差异。如上图左侧所示,在离散环境中,智能体只能在给定的导航路线图中在不同点之间跳跃移动,此时智能体可以感知到周围若干个备选点的情况,并选择跳跃至哪一个备选点。此时,智能体具有一个离散的移动空间,VLN 任务退化为了一个分类任务,无需预测旋转的角度或者前进的距离,我们重点考虑视觉和语言的匹配。

然而,机器人学研究社区的研究者认为离散环境与实际情况相差甚远,于是提出了连续环境下的 VLN 任务。Facebook 在 R2R 的基础上去掉了导航图,构建了一个连续的空间,在每一步预测行进的角度和距离。这种执行底层动作的过程更加贴近实际情况。
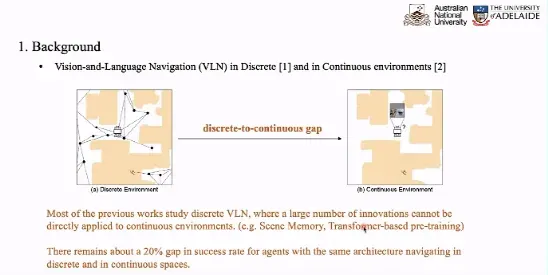
目前,大多数计算机视觉研究者更习惯于使用离散的环境,重点关注视觉-语言的匹配,大多数 VLN 的工作都是在离散环境下开展的。然而,如果直接将离散环境下设计的模型运用于连续环境中,将会产生 20% 的性能下降。因此,我们试图寻找降低这种性能下降程度的方式。
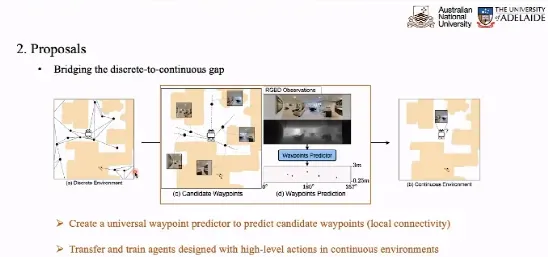
为此,我们尝试在连续空间中预测一个离散的导航地图,并为当前点预测几个参考路径点,即预测最有可能满足步行要求的点。代理在两点之间移动,而不在预测的导航图中做出决定。

在具体的实现过程中,我们考虑了两类动作:
(1)底层动作:例如,前进 0.25 米,左转 15°,右转 15°,停下。
(2)高层动作:选择周围若干候选点中的一个,直接跳跃过去。
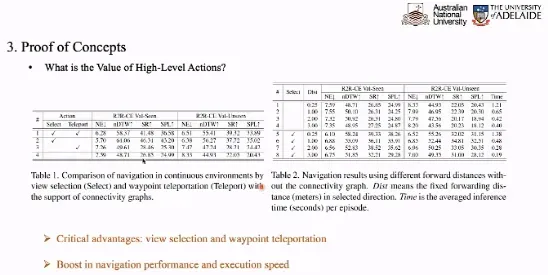
为了验证高层动作的作用,我们测试了它在选择行进角度和远距离传输能力方面的作用。实验结果表明,在没有高级动作的情况下,代理在连续环境中的性能会大幅下降。
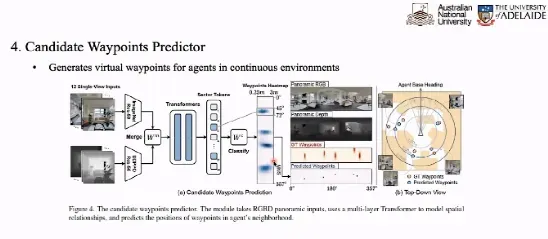
路径点预测器旨在根据当前点看到的信息决策出下一步可能走向的落脚点。如上图所示,在每个点我们可能选取 12 个视图的图像,将其与深度信息融合后输入给 Transformer 得到 12 个 Token。
我们训练一个分类器根据 12 个 Token 得到路径点预测的热力图,预测出若干个候选点的行进方向和距离,从而得到了候选点的概率图。我们可以根据 Ground Truth 的路径点作为监督信号,帮助我们训练路径点预测器。
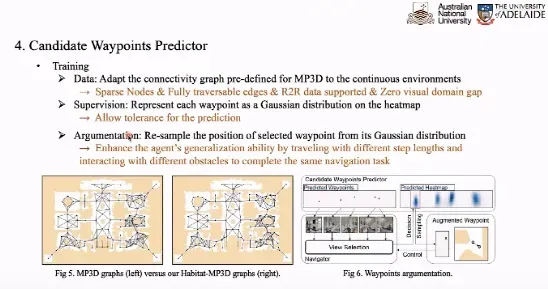
在训练候选路径点预测器时,我们使用离散的导航图作为训练数据,并且将每个路径点表示为热力图上的高斯分布作为监督信号,从而避免监督信号过于稀疏。就训练目标而言,我们希望缩小 GroundTruth 分布和预测分布之间的差异。此外,我们还对处理为高斯分布的 GT 进行采样,得到新的路径点作为额外的训练数据,从而实现数据增广。
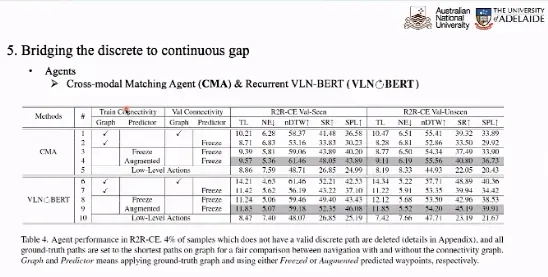
在预测出路径点之后,我们还需要进一步考虑如何将离散环境下训练的 VLN 模型应用于连续环境。在实验中,我们选取 CMA 和 VLN-BERT 作为对比基准,在离散环境中训练模型,在连续环境中测试模型性能。相较于仅仅使用底层动作训练,预测路径点的数据增广可以将预测的性能提升一倍。
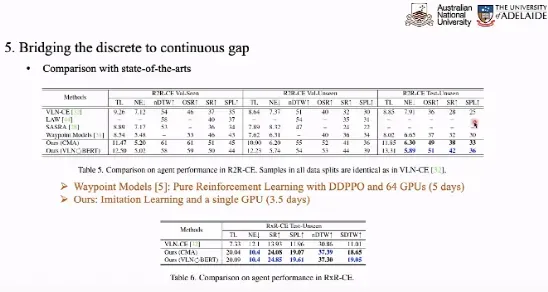
与在连续环境中训练的最先进模型相比,本文提出的方法以更少的计算开销实现了更好的性能。
07
总结

本文证明了高层动作在 VLN 任务中的价值,它可以使训练成本大大下降。我们可以设计预测候选路径点的方式,将在离散环境下训练的 VLN 模型应用于连续环境。我们希望该工作能够启发更多 VLN 研究者参与到 Sim2Real 的研究中,考虑实际环境下存在的诸多问题。
目前吴琦组的两篇文章均被CVPR2022接受:
第一篇:HOP: History-and-Order Aware Pre-training for Vision-and-Language Navigation, Yanyuan Qiao, Yuankai Qi, Yicong Hong, Zheng Yu, Peng Wang, Qi Wu, CVPR 2022.
第二篇:Bridging the Gap Between Learning in Discrete and Continuous Environments for Vision-and-Language Navigation, Yiconghong, Zun Wang, Qi Wu, Stephen Gould, CVPR 2022.
版权声明:本文为博主智源社区原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/BAAIBeijing/article/details/123244171