ChatPaper
- 1.简介及功能
- 2.前置准备
- 3.开始使用-命令行
- 4.开始使用-网页
1.简介及功能
ChatPaper是一种基于文本生成技术的研究论文,可以根据用户的输入进行智能回复和互动,具有类似于ChatGPT的功能。它可以根据关键字来获取相应的论文,并通过分析论文的标题、作者、单位、链接、研究背景、其它工作的问题、本文方法、本文方法具体步骤、总结本文的优缺点等内容,实现一分钟下载一篇最新arxiv论文,一个分钟速读主要信息。用户可以根据以上内容来判断是否需要更深入地了解该论文。
2.前置准备
**第一步:**下载项目代码:https://github.com/kaixindelele/ChatPaper
git clone https://github.com/kaixindelele/ChatPaper.git
第二步:配置环境
由于我已经安装了Anaconda和Pycharm,具体细节可以看这篇博客:点击
conda create -n chatgpt_pa python=3.9
# 进入到项目目录
python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
第三步:修改代码文件内容
你需要修改的地方如下
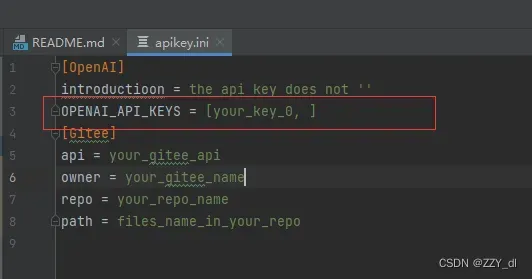
填入和这篇博客一样的Key即可(需要自己去官网获取):点击
3.开始使用-命令行
由于这里面太多功能,就不一一演示结果,可以根据自己的需求进行处理。
注意:key_word不重要,但是filter_keys非常重要! 一定要修改成你的关键词。
第一种:
python chat_paper.py --query "chatgpt robot" --filter_keys "chatgpt robot" --max_results 3
结果:
第二种:
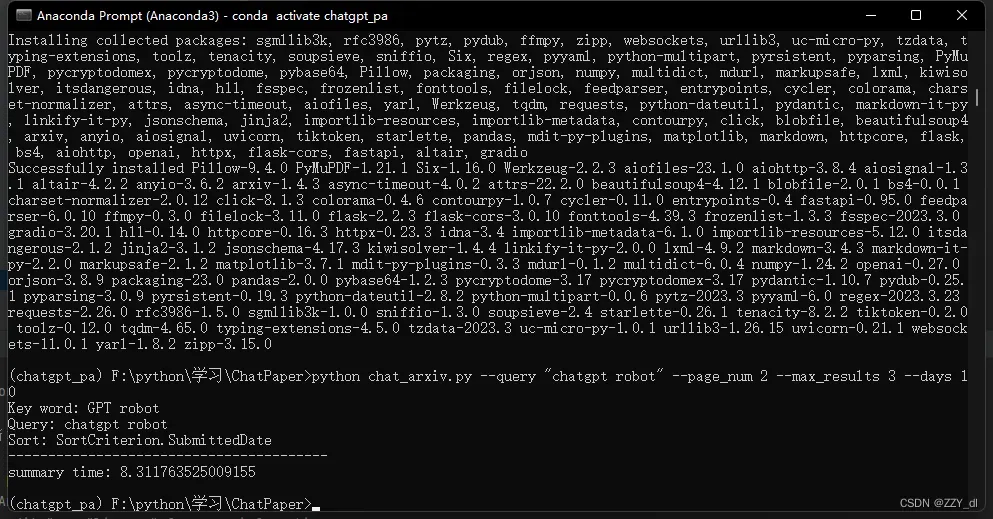
python chat_arxiv.py --query "chatgpt robot" --page_num 2 --max_results 3 --days 10
其中query是读者输入的搜索查询,filter_keys是用于在摘要中筛选的关键词,page_num是搜索的页面,每页和官网一样,最大是50篇,max_results是最终总结前N篇的文章,days是选最近几天的论文,严格筛选!
结果:
第三种:
Arxiv在线批量搜索+下载+总结+高级搜索: 运行chat_paper.py, 比如:
python chat_paper.py --query "all: reinforcement learning robot 2023" --filter_keys "reinforcement robot" --max_results 3
第四种:
Arxiv在线批量搜索+下载+总结+高级搜索+指定作者: 运行chat_paper.py, 比如:
python chat_paper.py --query "ti: Sergey Levine" --filter_keys "reinforcement robot" --max_results 3
第五种:
本地pdf总结: 运行chat_paper.py, 比如:
python chat_paper.py --pdf_path "demo.pdf"
第六种:
本地文件夹批量总结: 运行chat_paper.py, 比如:
python chat_paper.py --pdf_path "your_absolute_path"
第七种:
谷歌学术论文整理: 运行google_scholar_spider.py, 比如:
python google_scholar_spider.py --kw "deep learning" --nresults 30 --csvpath "./data" --sortby "cit/year" --plotresults 1
此命令在Google Scholar上搜索与“deep learning”相关的文章,检索30个结果,将结果保存到“./data”文件夹中的CSV文件中,按每年引用次数排序数据,并绘制结果。
最后会在export下生成对应的报告,默认为md文档。
4.开始使用-网页
感觉没有命令行好用
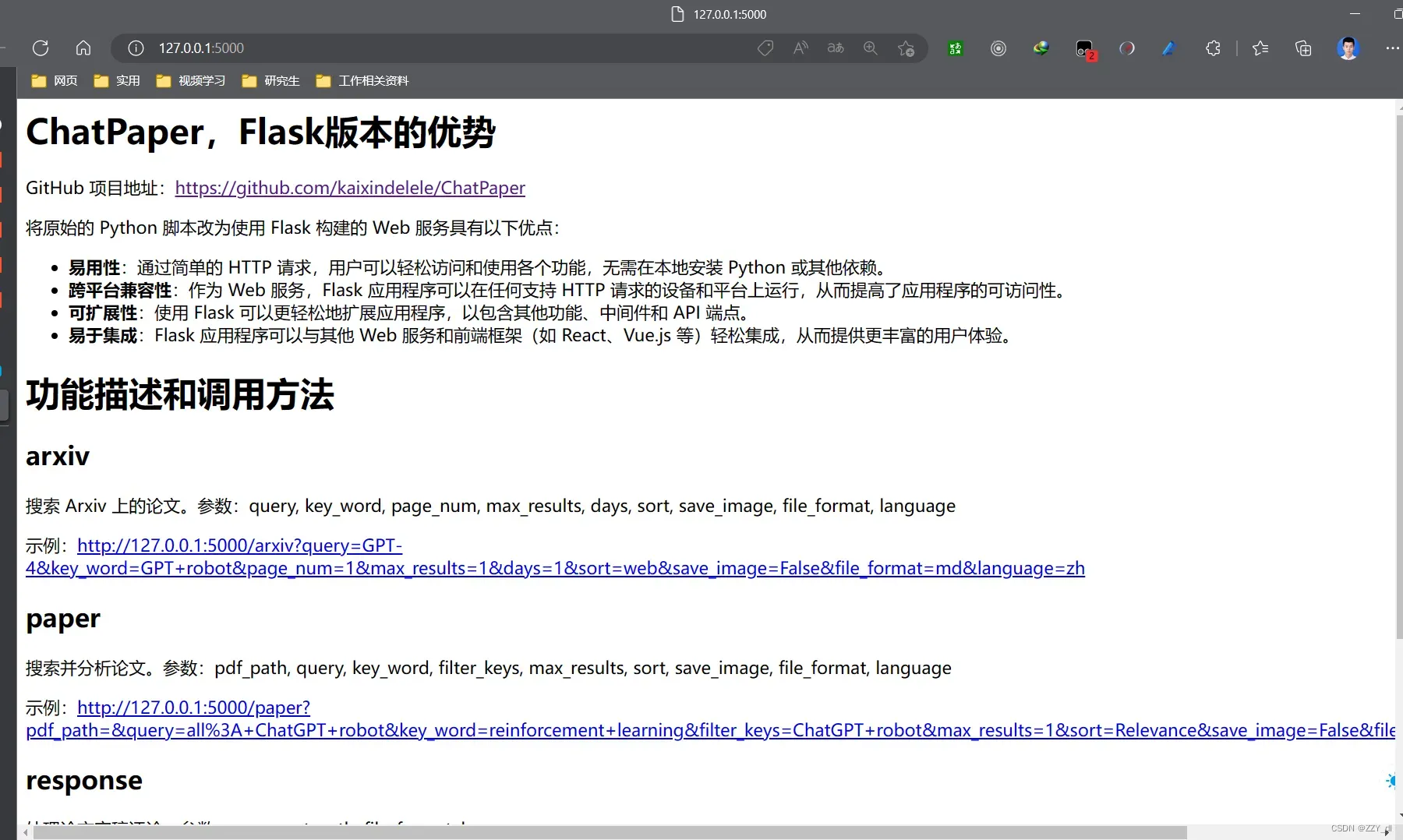
除了用命令行的方式,还可以用网页的形式来操作。启动服务
python3 app.py
启动 Flask 服务。运行此命令后,Flask 服务将在本地的 5000 端口上启动并等待用户请求。在浏览器中访问以下地址之一以访问 Flask 服务的主页:
http://127.0.0.1:5000/
或
http://127.0.0.1:5000/index
访问 http://127.0.0.1:5000/ 后,您将看到主页。在主页上,您可以点击不同的链接来调用各种服务。您可以通过修改链接中的参数值来实现不同的效果。有关参数详细信息,请参阅上一步骤中的详细介绍主界面:
特别的,这四个接口实际是封装了根目录下四个脚本的 web 界面。参数可以通过链接来修改。例如要运行“arxiv?query=GPT-4&key_word=GPT+robot&page_num=1&max_results=1&days=1&sort=web&save_image=False&file_format=md&language=zh”的话,相当于在根目录下调用 chat_arxiv.py 并返回结果。这个显示的结果和在命令行中调用的结果是一样的(即:python chat_arxiv.py –query “GPT-4” –key_word “GPT robot” –page_num 1 –max_results 1 –days 1 –sort “web” –save_image False –file_format “md” –language “zh”)。您可以通过修改参数来获得其他搜索结果。
如果以这种方式部署的话,结果会保存在同级目录下新生成的export、pdf_files 和response_file三个文件夹里
文章出处登录后可见!