本篇文章,我们聊聊如何使用 Docker 快速运行中文 Stable Diffusion 模型:太乙。
写在前面
上个月的时候,有朋友和我推荐了一个 “Stable Diffusion” 模型,来自深圳大湾区数字经济研究院(IDEA)的封神榜大模型中的 “太乙” 。

最近想起来,想本地运行试试看,根据官方开源仓库的指引和 Issue 里的记录,发现如果用官方提供的容器镜像跑“太乙”,这个项目根本跑不起来。
于是,花了一些时间,封装了一个可以一键运行、开箱即用的模型镜像。完整代码开源在 github.com/soulteary/docker-stable-diffusion-taiyi,有需要的同学自取。
这篇文章,我将记录下来折腾过程,希望能帮助到有相同需求,想要快速运行这个模型,找乐子的同学。
当然,也希望这篇文章,能够帮到将模型开源开放出来的 IDEA 研究院的开发团队的同学,改进当前开源项目中的不足之处,让中文开源项目越来越好。
快速上手
如果你本地已经准备好了运行 Docker 的环境,并且有一张显存在 4G 到 8G 之间的显卡,可以尝试使用下面这个镜像,镜像尺寸为 8GB ( 如果你手头没有显卡,也不想使用云主机,那么可以等等后续不需要 GPU 的“模型把玩”文章,或者翻阅之前有关模型的文章 😄 )
docker pull soulteary/stable-diffusion:taiyi-0.1
想运行“太乙”,除了需要下载“模型游乐场”镜像之外,我们还需要获取“太乙模型”文件:
git clone https://huggingface.co/IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1
整个仓库尺寸比较大(大概有 18GB),需要花费一些时间:
Cloning into 'Taiyi-Stable-Diffusion-1B-Chinese-v0.1'...
remote: Enumerating objects: 157, done.
remote: Counting objects: 100% (157/157), done.
remote: Compressing objects: 100% (155/155), done.
remote: Total 157 (delta 77), reused 0 (delta 0), pack-reused 0
Receiving objects: 100% (157/157), 3.06 MiB | 22.25 MiB/s, done.
Resolving deltas: 100% (77/77), done.
Filtering content: 100% (5/5), 8.92 GiB | 11.48 MiB/s, done.
原始项目启用了 git lfs,所以添加不添加 --depth 参数没有差别,耐心等待模型下载完毕之后,我们编写一个容器编排文件,来启动模型应用:
version: "2"
services:
taiyi:
image: soulteary/stable-diffusion:taiyi-0.1
container_name: taiyi
restart: always
runtime: nvidia
ipc: host
ports:
- "7860:7860"
volumes:
- ./Taiyi-Stable-Diffusion-1B-Chinese-v0.1:/stable-diffusion-webui/models/Taiyi-Stable-Diffusion-1B-Chinese-v0.1
将上面的内容保存为 docker-compose.yml 之后,执行 docker compose up -d,稍等片刻,在浏览器访问启动服务的 IP 地址和对应端口,比如:http://localhost:7860,就能够正常使用啦。
模型运行起来,当然是要玩一把了,我使用博客首页的古诗“醉里不知天在水,满船清梦压星河”为主题,尝试生成了一张图,看起来效果还不错:
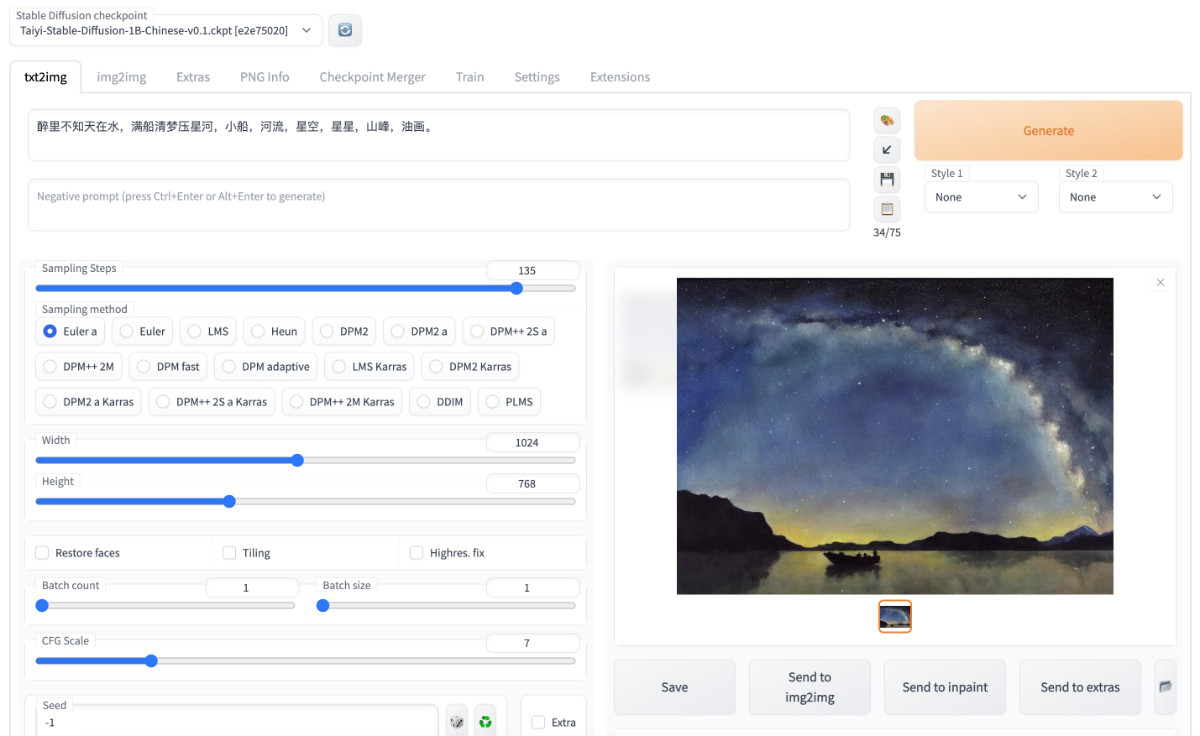
想要快速上手中文 Stable Diffusion 模型的同学,看到这里就可以啦。
如果你想了解如何从零开始配置 GPU 云服务器环境,或者想了解这个 Stable Diffusion 容器运行环境是如何构建的,可以继续阅读。
那么,聊聊如何将“太乙”正确的放进容器里。
如何将“太乙”正确的放进容器
既然提到了正确 ,我们首先要看看官方的镜像都包含哪些问题。
分析太乙官方镜像和应用项目存在的问题
官方团队并未在仓库中添加容器镜像的编排文件,起初我认为是上线匆忙忘记了,但是随着我翻开 DockerHub 的提交记录时,发现原来这个镜像的构建方式是基于传统的 docker commit 构建的,这样的镜像存在两个问题,首先是黑盒不透明,拿 Docker 当虚拟机用,不利于二次开发和维护;其次,这最后一次提交,单个提交的变动包含 5个GB ,里面是否无心夹带了不该存在的内容,对于想私有化部署的场景下,也着实是有些让人难以放心。
其次,用户如果想在干净完整复现,就只能参考镜像中的“历史操作记录”啦,然而,并不是所有的命令都是能被系统记录下来的,比如 vim 等交互式操作,或者非幂等的操作,用户实际上也无法再次复现。
我们使用 docker run --rm -it fengshenbang/pytorch:1.10-cuda11.1-cudann8-devel bash 启动一个太乙官方团队,三个月前制作的镜像的 Docker 容器。
输入 history,能够看到开发同学启动容器之后,又噼里啪啦的搞了“一堆事情”:
1 python
2 git clone https://github.com/IDEA-CCNL/Fengshenbang-LM.git
3 cd Fengshenbang-LM/
4 ls
5 vim fengshen/requirement.txt
6 pip install --editable fengshen
7 pip install --editable .
8 pip install --update pillow
9 pip install --upgrade pillow
10 nvcc --version
11 where nvcc
12 which nvcc
13 pip install torch==1.10.0+cu111 torchvision==0.11.0+cu111 torchaudio==0.10.0 -f https://download.pytorch.org/whl/torch_stable.html
14 pip install --upgrade packaging --use-feature=2020-resolver
15 pip install --upgrade PyYAML --use-feature=2020-resolver
16 pip install --upgrade PyYAML --use-feature=2020-resolver --ignore-installed
17 pip install --upgrade tqdm --use-feature=2020-resolver
18 pip uninstall pip install torchtext
19 pip uninstall torchtext
20 pip install torchtext
21 pip uninstall torchtext
22 pip install torchtext==0.10.0
23 python
24 pip install torchtext==0.11.0
25 cd fengshen
26 ls
27 cd examples/
28 cd pretrain_erlangshen_deberta_v2/
29 ls
30 vim pretrain_deberta_base.sh
31 sh pretrain_deberta_base.sh
32 git submodule init
33 git submodule update
34 cd ..
35 cd data/fs_datasets/
36 ls
37 ll
38 cd ..
39 git submodule init
40 git submodule update
41 cd data/fs_datasets/
42 cd ..
43 vim .gitmodules
44 git submodule update
45 git submodule init
46 git submodule update
47 vim .gitmodules
48 git submodule --help
49 git submodule
50 git submodule init
51 git submodule
52 git submodule update --init
53 vim .git/config
54 git submodule init
55 git submodule update
56 cd fengshen/examples/
57 ls
58 cd pretrain_erlangshen_deberta_v2/
59 sh pretrain_deberta_base.sh
60 vim pretrain_deberta_base.sh
61 sh pretrain_deberta_base.sh
62 cd ..
63 cd Fengshenbang-LM/
64 git status
65 rm -rf fengshen/workspace/torch_extendsions
66 rm fengshen/workspace/erlangshen-deberta-base/lightning_logs/
67 rm fengshen/workspace/erlangshen-deberta-base/lightning_logs -rf
68 rm fengshen/workspace/erlangshen-deberta-base/ckpt -rf
69 cd ..
70 exit
上面的命令中,主要做了几件事:
- 调整和配置 Python 应用所需要 Pytorch 基础运行环境,经历了多次失败和重试。
- 手动安装项目运行所需要的某几个软件包,也是经历了翻来覆去的重试。
- 或许,开发同学不太习惯使用
git submodule,为了让项目程序文件完整,也是折腾来折腾去。 - 在提供给用户的镜像里进行了
pretrain_erlangshen_deberta_v2的预训练,结束后或许是想保持干净的环境,删除掉了日志和模型文件。
然而,这些三个月前的操作,对于我们想正确运行太乙的模型和界面程序,非但没有正确指引,反而存在“误导”:
- PyTorch 版本低,运行程序会因为程序使用了新版本(1.13+)版本才存在的数据类型而无法运行。
- 历史操作中反复安装的
torchtext将阻止我们安装到正确的 PyTorch,进一步阻碍程序在容器内正确运行。 - 除此之外,官方项目使用的
submodule中的引用地址为:git@github.com:IDEA-CCNL/fs_datasets.git,在容器默认环境下是无法完成通过git进行下载的。 - 最后,官方在项目中推荐的方式是启动 Docker 容器作为虚拟机,然后
docker exec -it fengshen bash进去之后,使用git pull && git submodule ...来强制更新代码,这样容易出现代码和模型版本不匹配,代码和依赖组件不匹配,和基础环境软件不兼容的情况下,软件无法运行的情况。并且,这样做其实在一些情况下,是无法更新submodule中的程序文件的。
除了基础镜像的问题之外,官方 fork 改版的 stable-diffusion-webui Web UI 项目也隐藏了一些问题。虽然,其中不少问题都是从原版程序“继承”过来的。
首先,项目所需要的依赖,并不是完全都包含在项目的依赖声明文件中;并且,项目中存在俩 requirements.txt 文件,其中都包含了未指定明确版本的软件包。可能官方开发团队想缓解这个问题,于是编写了一个名为 launch.py 的启动文件,在执行程序之后,程序会自动调用 prepare_enviroment() 函数,包含了“近似”所有所需 Python 软件包依赖的安装,以及关联项目的下载。
在这个文件中,我们会发现目前版本的程序想正确运行起来,实际需要的基础运行环境是:torch==1.12.1+cu113 torchvision==0.13.1+cu113,好吧,如果你没有仔细阅读过这个 launch.py,那么官方镜像提供的默认环境将浪费不少想让程序运行起来,花费的调试时间。
我们也能够在这个文件中发现大量直接调用 subprocess.run 执行的安装命令。因为项目中没有明确的版本声明,所以当程序下载完 gfpgan、clip、xformers、deepdanbooru、pyngrok、Stable Diffusion、Taming Transformer、K-diffusion、CodeFormer、BLIP 后,一通安装后,再进行安装 web ui 本身的依赖,很容易造成程序因为版本兼容性存在问题,而无法运行,或者运行出错的问题,对其他人提供公开代码,或者下载的软件,使用显式声明是好习惯。
在上面的依赖安装中,还存在两个问题。第一个是来自 Facebook Research 的 xformers,如果想要在 GPU 环境正确安装,安装指令需要调整。推测这里测试的同学,偷懒没有验证 GPU 环境从零到一的安装验证。
其二,pyngrok 这个包,虽然目前还没有在项目中被公开使用,但是就伴随程序的“自动初始化”悄然无声的安装到用户电脑上,其实不见得是一件合适的事情。太乙团队的镜像里暂时并未发现 ngrok 的执行程序,但是如果其他人再分发的过程中,虽然不改动原始代码,但是在程序中夹带了 ngrok,配合不严格的安全策略,对于用户而言,潜在的数据安全风险还是蛮高的。
解决被官方忽视的 AI 容器应用问题
太乙官方团队之前选择的基础镜像是 pytorch:1.10-cuda11.1-cudann8-devel。结合上面的分析,我们不难知道两点:
- 第一,我们需要更新 cuda 版本到 11.3.1。
- 第二,我们有对 PyTorch “生态” 依赖进行安装更新的需要,使用预置 PyTorch 的镜像意义不大。
所以,这里我选择使用 nvidia/cuda:11.3.1-devel-ubuntu18.04 作为基础镜像,搭配 miniconda 完成经过验证的 PyTorch “生态”软件版本的安装,搞定程序的基础“运行时”。
如果你需要寻找其他版本的镜像,可以在 DockerHub 的这个页面搜索,另外,如果你需要判断 PyTorch 版本所需要的 CUDA 版本,可以在 PyTorch 官方发布页面中寻找线索:https://pytorch.org/get-started/previous-versions/。
FROM nvidia/cuda:11.3.1-devel-ubuntu18.04
ENV PATH="/root/miniconda3/bin:${PATH}"
RUN apt-get update
RUN apt-get install -y wget && rm -rf /var/lib/apt/lists/*
RUN wget \
https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh \
&& mkdir /root/.conda \
&& bash Miniconda3-latest-Linux-x86_64.sh -b \
&& rm -f Miniconda3-latest-Linux-x86_64.sh
RUN conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch -y
然后,我们开始翻译 launch.py 程序中关于软件的依赖下载和安装命令,先处理基础软件依赖(不进行 pyngrok 的安装):
# WebUI
RUN pip install transformers==4.19.2 diffusers==0.3.0 basicsr==1.4.2 gfpgan==1.3.8 gradio==3.8 numpy==1.23.3 Pillow==9.2.0 realesrgan==0.3.0 torch omegaconf==2.2.3 pytorch_lightning==1.7.6 scikit-image==0.19.2 fonts font-roboto timm==0.6.7 fairscale==0.4.9 piexif==1.1.3 einops==0.4.1 jsonmerge==1.8.0 clean-fid==0.1.29 resize-right==0.0.2 torchdiffeq==0.2.3 kornia==0.6.7 lark==1.1.2 inflection==0.5.1 GitPython==3.1.27
# Etc...
RUN apt-get update && apt-get install -y git
RUN pip install "git+https://github.com/TencentARC/GFPGAN.git@8d2447a2d918f8eba5a4a01463fd48e45126a379"
RUN pip install "git+https://github.com/openai/CLIP.git@d50d76daa670286dd6cacf3bcd80b5e4823fc8e1"
RUN pip install "git+https://github.com/KichangKim/DeepDanbooru.git@d91a2963bf87c6a770d74894667e9ffa9f6de7ff#egg=deepdanbooru" && \
pip install tensorflow==2.10.0 tensorflow-io==0.27.0
RUN pip install ninja && \
pip install -v -U "git+https://github.com/facebookresearch/xformers.git@main#egg=xformers"
接着,我们来处理程序运行所需要的三方开源仓库这类组件依赖,按照官方 Web UI 所需要的 git hash 版本将它们下载下来:
RUN git clone "https://github.com/CompVis/stable-diffusion.git" "stable-diffusion" && \
cd "stable-diffusion" && \
git checkout "69ae4b35e0a0f6ee1af8bb9a5d0016ccb27e36dc"
RUN git clone "https://github.com/CompVis/taming-transformers.git" "taming-transformers" && \
cd "taming-transformers" && \
git checkout "24268930bf1dce879235a7fddd0b2355b84d7ea6"
RUN git clone "https://github.com/crowsonkb/k-diffusion.git" "k-diffusion" && \
cd "k-diffusion" && \
git checkout "60e5042ca0da89c14d1dd59d73883280f8fce991"
RUN git clone "https://github.com/sczhou/CodeFormer.git" "CodeFormer" && \
cd "CodeFormer" && \
git checkout "c5b4593074ba6214284d6acd5f1719b6c5d739af"
RUN git clone "https://github.com/salesforce/BLIP.git" "BLIP" && \
cd "BLIP" && \
git checkout "48211a1594f1321b00f14c9f7a5b4813144b2fb9"
RUN cd "CodeFormer" && \
pip install -r requirements.txt
然后,我们来处理太乙专属的 Web UI 这部分的程序,为了让镜像能够稳定构建、稳定运行,我们对 IDEA-CCNL/stable-diffusion-webui 也进行“版本的显式定义”:
RUN git clone https://github.com/IDEA-CCNL/stable-diffusion-webui.git && \
cd "stable-diffusion-webui" && \
git checkout "b31fc195a6d56a36b4abe1f6e36890211a78e844"
RUN mv "stable-diffusion" stable-diffusion-webui/repositories/ && \
mv "taming-transformers" stable-diffusion-webui/repositories/ && \
mv "k-diffusion" stable-diffusion-webui/repositories/ && \
mv "CodeFormer" stable-diffusion-webui/repositories/ && \
mv "BLIP" stable-diffusion-webui/repositories/
接下来,对官方团队准备好的配置文件进行调整,为了方便容器使用,我们将把太乙的模型文件放在 Web UI 的 stable-diffusion-webui/models/Taiyi-Stable-Diffusion-1B-Chinese-v0.1/ 目录中:
RUN cd stable-diffusion-webui/repositories/ && \
cp "stable-diffusion-taiyi/configs/stable-diffusion/v1-inference.yaml" "stable-diffusion/configs/stable-diffusion/v1-inference.yaml" && \
cp "stable-diffusion-taiyi/ldm/modules/encoders/modules.py" "stable-diffusion/ldm/modules/encoders/modules.py" && \
sed -ie s#your_path/Taiyi-Stable-Diffusion-1B-Chinese-v0.1#/stable-diffusion-webui/models/Taiyi-Stable-Diffusion-1B-Chinese-v0.1/# "stable-diffusion/configs/stable-diffusion/v1-inference.yaml"
设置程序运行工作目录,以及启动参数:
WORKDIR stable-diffusion-webui
CMD ["python", "webui.py", "--ckpt", "/stable-diffusion-webui/models/Taiyi-Stable-Diffusion-1B-Chinese-v0.1/Taiyi-Stable-Diffusion-1B-Chinese-v0.1.ckpt", "--listen"]
最后,将上面的内容保存为 Dockerfile,执行 docker build -t soulteary/stable-diffusion:taiyi-0.1 . ,耐心等待镜像构建完毕就好啦。
我们使用 docker images 查看镜像尺寸:
REPOSITORY TAG IMAGE ID CREATED SIZE
soulteary/stable-diffusion taiyi-0.1 359b67ba7c2f 5 hours ago 17.4GB
发现虽然比官方镜像解压缩后的 22.5GB 小,但是还是有些大,那么,接下来,我们来进行简单优化。
如果你想了解极限的“硬核优化”,可以参考《使用 Docker 和 HuggingFace 实现 NLP 文本情感分析应用》或者往期大文章,在此就不赘述啦 😄
进一步优化 AI 应用的镜像尺寸
因为时间关系,我就先不折腾多阶段构建,以及定向的压缩实现啦,我们针对上面的镜像编排指令进行合并,再每个阶段去掉不必要的文件,很容易得到类似下面的,紧凑一些的 Dockerfile:
FROM nvidia/cuda:11.3.1-devel-ubuntu18.04
LABEL org.opencontainers.image.authors="soulteary@gmail.com"
ENV PATH="/root/miniconda3/bin:${PATH}"
RUN apt-get update && \
apt-get install -y wget git ffmpeg libsm6 libxext6 && \
rm -rf /var/lib/apt/lists/* && \
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh && \
mkdir /root/.conda && \
bash Miniconda3-latest-Linux-x86_64.sh -b && \
rm -f Miniconda3-latest-Linux-x86_64.sh
# Basic environment (PyApp & WebUI)
RUN conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch -y && \
pip install transformers==4.19.2 diffusers==0.3.0 basicsr==1.4.2 gfpgan==1.3.8 gradio==3.8 numpy==1.23.3 Pillow==9.2.0 realesrgan==0.3.0 torch omegaconf==2.2.3 pytorch_lightning==1.7.6 scikit-image==0.19.2 fonts font-roboto timm==0.6.7 fairscale==0.4.9 piexif==1.1.3 einops==0.4.1 jsonmerge==1.8.0 clean-fid==0.1.29 resize-right==0.0.2 torchdiffeq==0.2.3 kornia==0.6.7 lark==1.1.2 inflection==0.5.1 GitPython==3.1.27 && \
pip install "git+https://github.com/TencentARC/GFPGAN.git@8d2447a2d918f8eba5a4a01463fd48e45126a379" && \
pip install "git+https://github.com/openai/CLIP.git@d50d76daa670286dd6cacf3bcd80b5e4823fc8e1" && \
pip install "git+https://github.com/KichangKim/DeepDanbooru.git@d91a2963bf87c6a770d74894667e9ffa9f6de7ff#egg=deepdanbooru" && \
pip install tensorflow==2.10.0 tensorflow-io==0.27.0 && \
pip install ninja && \
pip install -v -U "git+https://github.com/facebookresearch/xformers.git@main#egg=xformers" && \
pip cache purge
# Components
RUN git clone "https://github.com/CompVis/stable-diffusion.git" "stable-diffusion" && \
cd "stable-diffusion" && \
git checkout "69ae4b35e0a0f6ee1af8bb9a5d0016ccb27e36dc" && rm -rf .git
RUN git clone "https://github.com/CompVis/taming-transformers.git" "taming-transformers" && \
cd "taming-transformers" && \
git checkout "24268930bf1dce879235a7fddd0b2355b84d7ea6" && rm -rf .git
RUN git clone "https://github.com/crowsonkb/k-diffusion.git" "k-diffusion" && \
cd "k-diffusion" && \
git checkout "60e5042ca0da89c14d1dd59d73883280f8fce991" && rm -rf .git
RUN git clone "https://github.com/sczhou/CodeFormer.git" "CodeFormer" && \
cd "CodeFormer" && \
git checkout "c5b4593074ba6214284d6acd5f1719b6c5d739af" && rm -rf .git && \
pip install -r requirements.txt && pip cache purge
RUN git clone "https://github.com/salesforce/BLIP.git" "BLIP" && \
cd "BLIP" && \
git checkout "48211a1594f1321b00f14c9f7a5b4813144b2fb9" && rm -rf .git
RUN git clone "https://github.com/IDEA-CCNL/stable-diffusion-webui.git" "stable-diffusion-webui" && \
cd "stable-diffusion-webui" && \
git checkout "b31fc195a6d56a36b4abe1f6e36890211a78e844" && rm -rf .git && \
cd ../ && \
mv "stable-diffusion" "stable-diffusion-webui/repositories/" && \
mv "taming-transformers" "stable-diffusion-webui/repositories/" && \
mv "k-diffusion" "stable-diffusion-webui/repositories/" && \
mv "CodeFormer" "stable-diffusion-webui/repositories/" && \
mv "BLIP" "stable-diffusion-webui/repositories/" && \
cd "stable-diffusion-webui/repositories/" && \
cp "stable-diffusion-taiyi/configs/stable-diffusion/v1-inference.yaml" "stable-diffusion/configs/stable-diffusion/v1-inference.yaml" && \
cp "stable-diffusion-taiyi/ldm/modules/encoders/modules.py" "stable-diffusion/ldm/modules/encoders/modules.py" && \
sed -ie s#your_path/Taiyi-Stable-Diffusion-1B-Chinese-v0.1#/stable-diffusion-webui/models/Taiyi-Stable-Diffusion-1B-Chinese-v0.1/# "stable-diffusion/configs/stable-diffusion/v1-inference.yaml"
WORKDIR stable-diffusion-webui
CMD ["python", "webui.py", "--ckpt", "/stable-diffusion-webui/models/Taiyi-Stable-Diffusion-1B-Chinese-v0.1/Taiyi-Stable-Diffusion-1B-Chinese-v0.1.ckpt", "--listen"]
再次执行 docker build -t soulteary/stable-diffusion:taiyi-0.1 . 进行镜像的构建,构建完毕后,再一次使用 docker images 查看镜像尺寸,发现尺寸立减 2GB,相比官方镜像小了 6GB+:
REPOSITORY TAG IMAGE ID CREATED SIZE
soulteary/stable-diffusion taiyi-0.1 0e1c48709672 2 hours ago 15.4GB
将镜像推送到 DockerHub 上,经过平台的压缩,镜像传输尺比官方压缩后的镜像“轻” 2GB:
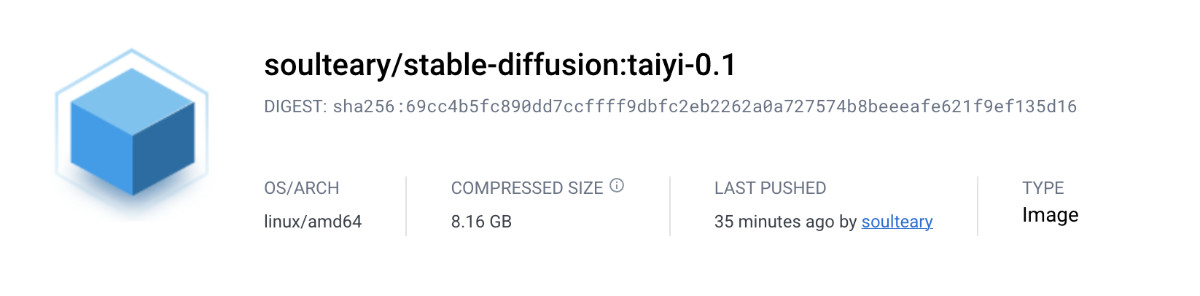
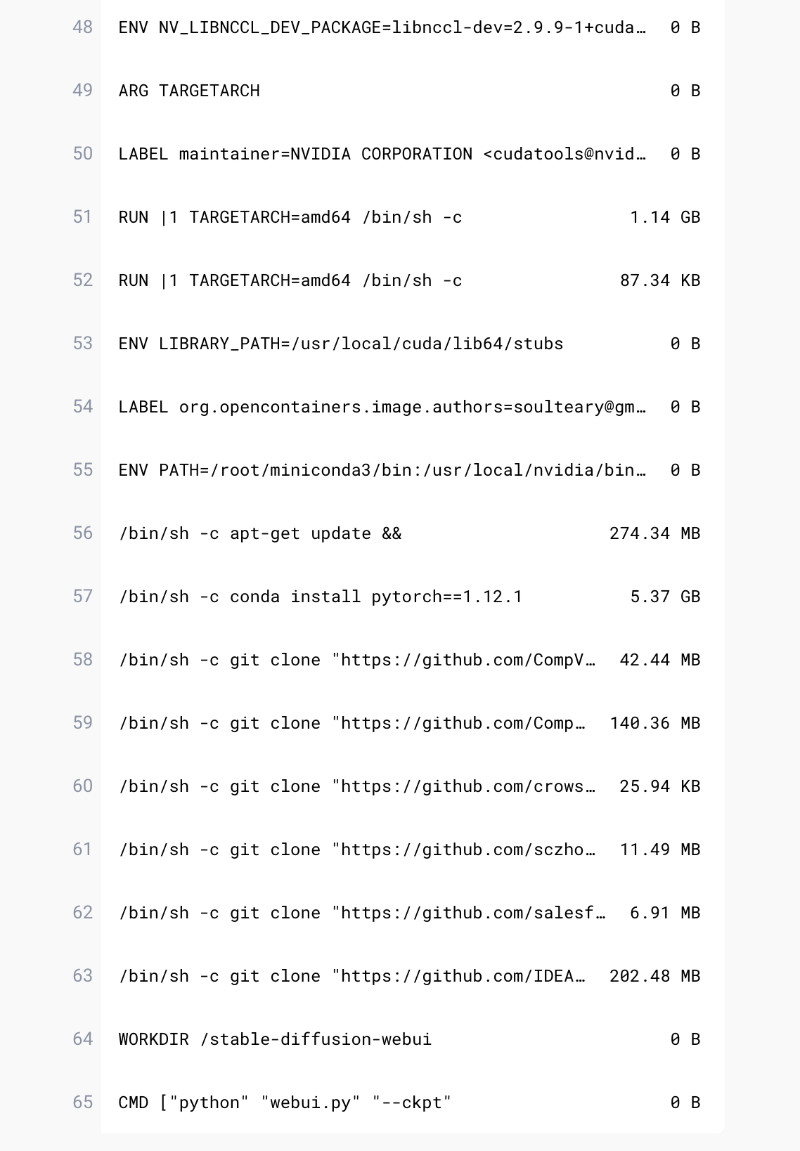
并且,镜像构建细节中,每一步做了什么,构建的层多大,都清清楚楚的展示在了 DockerHub 的镜像详情页中,“干净又卫生”。
GPU 云主机环境的配置
想要简单、丝滑的在云服务器上运行 Python AI 应用,有一些前置工作要做。
Docker 基础环境的安装
我们在云环境默认创建的 GPU 服务器,可能环境有这样或者那样的小问题,为了避免时间浪费在琐碎问题上,我们可以考虑用 Docker 所提供的“固定 & 明确的运行环境”来节约时间。
想要运行 Docker 首先要完成 Docker 的安装,在《在笔记本上搭建高性价比的 Linux 学习环境:基础篇》一文的“更简单的 Docker 安装”小节中,我提到过如何快速、正确的在 Ubuntu 环境完成 Docker 的安装,这里就不做展开了,有需要的同学可以自行翻阅。
如果,我们想在 Docker 中调用 Nvidia 显卡,光是完成 Docker 安装,还是不够的,还有一些事情要做。
完善 Nvidia 显卡驱动安装
我们需要先信任 Nvidia 的 GPG Key,然后才能安装来自 Nvidia 的开源软件。
curl -fsSL https://nvidia.github.io/nvidia-container-runtime/gpgkey | sudo gpg --dearmor -o /etc/apt/keyrings/nvidia-container-runtime.gpg
接着,需要更新系统中的软件源列表,添加 NVIDIA/nvidia-container-runtime 开源项目的软件源到 apt 配置中。
cat > /etc/apt/sources.list.d/nvidia-container-runtime.list << EOF
deb https://nvidia.github.io/libnvidia-container/stable/ubuntu22.04/amd64 /
deb https://nvidia.github.io/nvidia-container-runtime/stable/ubuntu22.04/amd64 /
EOF
如果你的系统架构和系统版本不是 amd64 和 ubuntu22.04,请结合实际情况进行调整。
在添加了软件源之后,我们执行下面的命令,完成 nvidia-container-cli 工具的安装:
apt-get update
apt install -y nvidia-container-runtime
完成工具安装之后,就可以使用下面的命令,来检查 Docker 需要的 Nvidia 显卡驱动是否完成完整安装了:
nvidia-container-cli -k -d /dev/tty info
执行完毕,我们将看到类似下面的日志:
-- WARNING, the following logs are for debugging purposes only --
I1209 15:46:16.088339 22574 nvc.c:376] initializing library context (version=1.11.0, build=c8f267be0bac1c654d59ad4ea5df907141149977)
I1209 15:46:16.088444 22574 nvc.c:350] using root /
I1209 15:46:16.088458 22574 nvc.c:351] using ldcache /etc/ld.so.cache
I1209 15:46:16.088469 22574 nvc.c:352] using unprivileged user 65534:65534
I1209 15:46:16.088499 22574 nvc.c:393] attempting to load dxcore to see if we are running under Windows Subsystem for Linux (WSL)
I1209 15:46:16.088915 22574 nvc.c:395] dxcore initialization failed, continuing assuming a non-WSL environment
I1209 15:46:16.090266 22575 nvc.c:278] loading kernel module nvidia
E1209 15:46:16.094200 22575 nvc.c:280] could not load kernel module nvidia
I1209 15:46:16.094227 22575 nvc.c:296] loading kernel module nvidia_uvm
E1209 15:46:16.097819 22575 nvc.c:298] could not load kernel module nvidia_uvm
I1209 15:46:16.097845 22575 nvc.c:305] loading kernel module nvidia_modeset
E1209 15:46:16.101219 22575 nvc.c:307] could not load kernel module nvidia_modeset
I1209 15:46:16.101496 22579 rpc.c:71] starting driver rpc service
I1209 15:46:16.101960 22574 rpc.c:135] driver rpc service terminated with signal 15
nvidia-container-cli: initialization error: load library failed: libnvidia-ml.so.1: cannot open shared object file: no such file or directory
I1209 15:46:16.102035 22574 nvc.c:434] shutting down library context
...
在上面的日志中,我们能看到 could not load kernel module nvidia,说明系统中没有完整安装 Nvidia 的内核驱动。
解决这个问题很简单,在 Ubuntu 系统环境中,内置了经过官方验证的驱动检查命令:
ubuntu-drivers devices
执行命令,能够得到支持安装的显卡驱动列表:
== /sys/devices/pci0000:00/0000:00:07.0 ==
modalias : pci:v000010DEd00001DB1sv000010DEsd00001212bc03sc02i00
vendor : NVIDIA Corporation
model : GV100GL [Tesla V100 SXM2 16GB]
driver : nvidia-driver-418-server - distro non-free
driver : nvidia-driver-450-server - distro non-free
driver : nvidia-driver-510 - distro non-free
driver : nvidia-driver-515-server - distro non-free
driver : nvidia-driver-525 - distro non-free recommended
driver : nvidia-driver-515 - distro non-free
driver : nvidia-driver-390 - distro non-free
driver : nvidia-driver-470 - distro non-free
driver : nvidia-driver-470-server - distro non-free
driver : xserver-xorg-video-nouveau - distro free builtin
如果你不确定安装哪一个好,可以跟着“推荐”(recommended)来:
apt install nvidia-driver-525 -y
完成驱动安装,在 Ubuntu 22.04 中,将会自动加载内核驱动,如果你的操作系统没有自动完成驱动加载,那么可能需要执行重启。
再次执行检测命令,得到类似下面的日志:
nvidia-container-cli -k -d /dev/tty info
NVRM version: 525.60.11
CUDA version: 12.0
Device Index: 0
Device Minor: 0
Model: Tesla V100-SXM2-16GB
Brand: Tesla
GPU UUID: GPU-775f6201-9640-a18e-5d09-3b26e9b11a52
Bus Location: 00000000:00:07.0
Architecture: 7.0
I1209 15:52:25.463383 42317 nvc.c:434] shutting down library context
I1209 15:52:25.463438 42351 rpc.c:95] terminating nvcgo rpc service
I1209 15:52:25.463812 42317 rpc.c:135] nvcgo rpc service terminated successfully
I1209 15:52:25.466657 42346 rpc.c:95] terminating driver rpc service
I1209 15:52:25.466810 42317 rpc.c:135] driver rpc service terminated successfully
不难发现,显卡类型已经能够被正常展示出来了。
为 Docker 添加 Nvidia 运行时支持
完成 Docker 和 Nvidia 显卡的安装之后,此时 Docker 还不能调用显卡硬件,还需要做一些配置上的调整。
执行下面的命令,将 nvidia-container-runtime 添加到 Docker 的启动参数中:
sudo mkdir -p /etc/systemd/system/docker.service.d
sudo tee /etc/systemd/system/docker.service.d/override.conf <<EOF
[Service]
ExecStart=
ExecStart=/usr/bin/dockerd --host=fd:// --add-runtime=nvidia=/usr/bin/nvidia-container-runtime
EOF
搞定之后,执行下面的命令重载 daemon-reload 和重启 docker,让配置生效。
sudo systemctl daemon-reload
sudo systemctl restart docker
接着,为了万无一失,我们在 /etc/docker/daemon.json 中添加配置字段,如果需要的话,还可以在 runtimeArgs 中添加需要的参数:
sudo tee /etc/docker/daemon.json <<EOF
{
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
EOF
执行完毕,除了执行上面的命令之外,也可以用怀旧命令来重启服务 service docker restart。
现在,我们就可以在使用 Docker 的时候,调用 Nvidia 显卡啦:
docker run --runtime=nvidia --ipc=host ...
其他:太乙模型的资源要求
太乙模型实际资源要求,感觉还不错,默认配置情况下一般也就占 4G 不到的显存,偶尔输出“sampling steps”比较大的图,会膨胀到 8GB 左右。
所以,如果控制生成配置的“计算量”,“小卡”运行应该也问题不大。
nvidia-smi
Fri Dec 9 22:20:23 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.60.11 Driver Version: 525.60.11 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... Off | 00000000:00:07.0 Off | 0 |
| N/A 38C P0 55W / 300W | 3202MiB / 16384MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 181118 C python 3200MiB |
+-----------------------------------------------------------------------------+
最后
好啦,到这里本篇文章就写完啦。
接下来,我会考虑聊聊 AIGC 话题里,绕不开的一些“关键词”,比如:大模型、Mac 、ARMv64 、低成本的 FineTune 等等。
–EOF
我们有一个小小的折腾群,里面聚集了一些喜欢折腾的小伙伴。
在不发广告的情况下,我们在里面会一起聊聊软硬件、HomeLab、编程上的一些问题,也会在群里不定期的分享一些技术沙龙的资料。
喜欢折腾的小伙伴,欢迎阅读下面的内容,扫码添加好友。
- 关于“交友”的一些建议和看法
- 添加好友,请备注实名和公司或学校、注明来源和目的,否则不会通过审核。
- 关于折腾群入群的那些事
本文使用「署名 4.0 国际 (CC BY 4.0)」许可协议,欢迎转载、或重新修改使用,但需要注明来源。 署名 4.0 国际 (CC BY 4.0)
本文作者: 苏洋
创建时间: 2022年11月29日
统计字数: 12906字
阅读时间: 26分钟阅读
本文链接: https://soulteary.com/2022/11/29/private-cloud-environment-installed-in-a-notebook-k8s-cluster-preparation.html
文章出处登录后可见!