这是我的第229篇原创文章。
一、问题
单站点多变量单步预测问题—-基于LSTM实现多变量时间序列预测股票价格。
二、实现过程
2.1 读取数据集
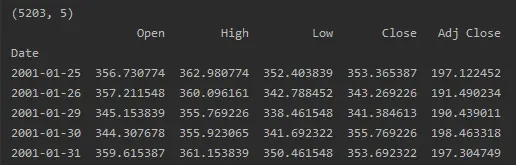
df=pd.read_csv("train.csv", parse_dates=["Date"], index_col=[0])
print(df.shape)
print(df.head())data:
2.2 划分数据集
# 拆分数据集为训练集和测试集
test_split=round(len(df)*0.20)
df_for_training=df[:-test_split]
df_for_testing=df[-test_split:]
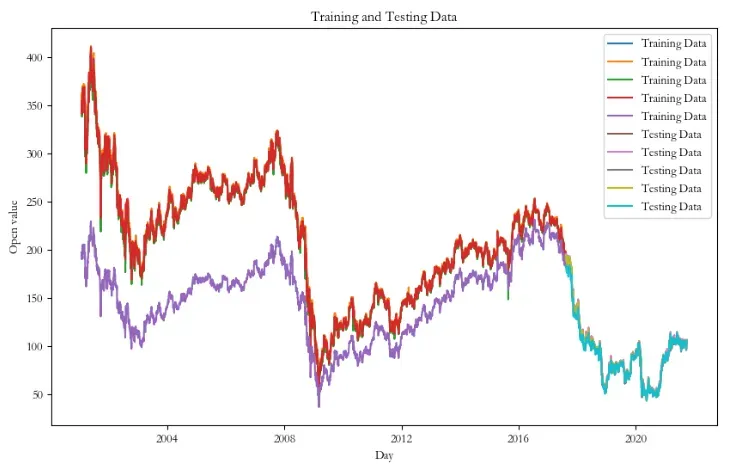
# 绘制训练集和测试集的折线图
plt.figure(figsize=(10, 6))
plt.plot(train_data, label='Training Data')
plt.plot(test_data, label='Testing Data')
plt.xlabel('Year')
plt.ylabel('Passenger Count')
plt.title('International Airline Passengers - Training and Testing Data')
plt.legend()
plt.show()共5203条数据,8:2划分:训练集4162,测试集1041。
训练集和测试集:
2.3 归一化
# 将数据归一化到 0~1 范围
scaler = MinMaxScaler(feature_range=(0,1))
df_for_training_scaled = scaler.fit_transform(df_for_training)
df_for_testing_scaled=scaler.transform(df_for_testing)2.4 构造LSTM数据集(时序–>监督学习)
def createXY(dataset,n_past):
pass
window_size = 30
trainX,trainY=createXY(df_for_training_scaled,window_size)
testX,testY=createXY(df_for_testing_scaled,window_size)
print(trainY[0])
print(trainY[0])
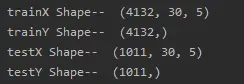
# 将数据集转换为 LSTM 模型所需的形状(样本数,时间步长,特征数)
trainX = np.reshape(trainX, (trainX.shape[0], window_size, 5))
testX = np.reshape(testX, (testX.shape[0], window_size, 5))
print("trainX Shape-- ",trainX.shape)
print("trainY Shape-- ",trainY.shape)
print("testX Shape-- ",testX.shape)
print("testY Shape-- ",testY.shape)滑动窗口30:
前30天的数据,即30行5列(特征列),预测第31天的第1列(目标列)
trainX[0]是前30天的数据,一个30行5列的数组
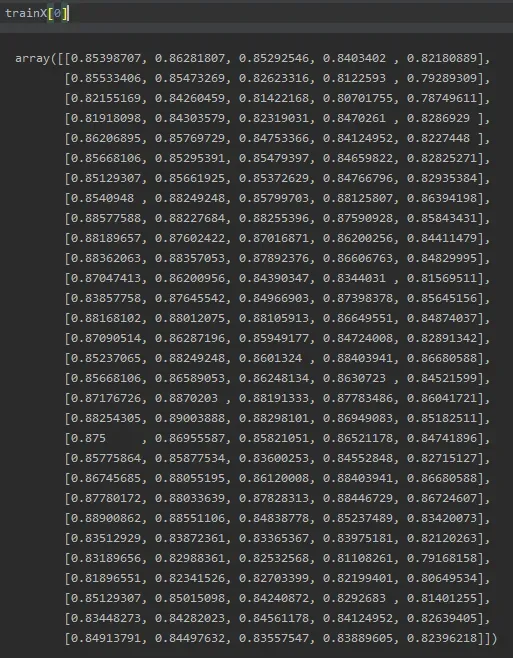
trainY[0]是第31天的第一列的值
![]()
训练集:经过滑动窗口构造的数据集,新的训练集数据数量(4132)比原始训练集(4162)少一个滑动窗口数量(30)。因此,实际训练值只有4132条,是训练的31-4162的部分。
【1-30】5列—–【31】第一列
【2-31】5列—–【32】第一列
…
【4131-4160】5列—–【4161】第一列
【4132-4161】5列—–【4162】第一列
X_train:(4132,30,5)
Y_train:(4132,1)
测试集:经过滑动窗口构造的数据集,新的测试集数据数量(1011)比原始训测试集(1041)少一个滑动窗口数量(30)。因此,实际预测值只有1011个,是预测的4193-5203的部分,如果想预测4163-4192的部分,可以取训练集的最后30个数进行预测。
【4163-4192】5列—–【4193】第一列
【4164-4163】5列—–【4194】第一列
…
【5172-5201】5列—–【5202】第一列
【5173-5202】5列—–【5203】第一列
X_test:(1011,30,5)
Y_test:(1011,1)
2.5 建立模拟合模型
from keras.wrappers.scikit_learn import KerasRegressor
from sklearn.model_selection import GridSearchCV
def build_model(optimizer):
grid_model = Sequential()
grid_model.add(LSTM(50,return_sequences=True,input_shape=(30,5)))
grid_model.add(LSTM(50))
grid_model.add(Dropout(0.2))
grid_model.add(Dense(1))
grid_model.compile(loss = 'mse',optimizer = optimizer)
return grid_model
grid_model = KerasRegressor(build_fn=build_model,verbose=1,validation_data=(testX,testY))
parameters = {'batch_size' : [16,20],
'epochs' : [8,10],
'optimizer' : ['adam','Adadelta'] }
grid_search = GridSearchCV(estimator = grid_model,
param_grid = parameters,
cv = 2)
grid_search = grid_search.fit(trainX,trainY)
print(grid_search.best_params_)
my_model=grid_search.best_estimator_.model2.6 进行预测
prediction=my_model.predict(testX)
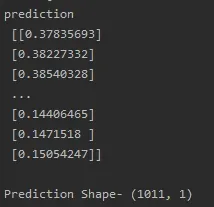
print("prediction\n", prediction)
print("\nPrediction Shape-",prediction.shape)prediction:
2.7 预测效果展示
prediction_copies_array = np.repeat(prediction,5, axis=-1)
print(prediction_copies_array.shape)
pred=scaler.inverse_transform(np.reshape(prediction_copies_array,(len(prediction),5)))[:,0]
original_copies_array = np.repeat(testY,5, axis=-1)
print(original_copies_array.shape)
original=scaler.inverse_transform(np.reshape(original_copies_array,(len(testY),5)))[:,0]
print("Pred Values-- ",pred)
print("\nOriginal Values-- ",original)
import matplotlib.pyplot as plt
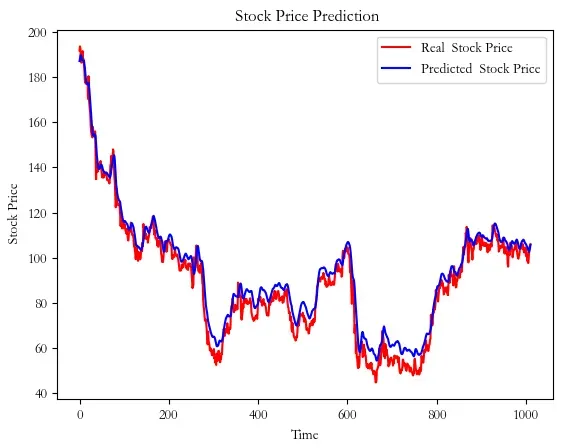
plt.plot(original, color = 'red', label = 'Real Stock Price')
plt.plot(pred, color = 'blue', label = 'Predicted Stock Price')
plt.title(' Stock Price Prediction')
plt.xlabel('Time')
plt.ylabel(' Stock Price')
plt.legend()
plt.show()测试集真实值与预测值:

三、新测试集上预测
代码:
df_30_days_past=df.iloc[-30:,:]
df_30_days_future=pd.read_csv("test.csv",parse_dates=["Date"],index_col=[0])
print(df_30_days_future.shape)
df_30_days_future["Open"]=0
df_30_days_future=df_30_days_future[["Open","High","Low","Close","Adj Close"]]
old_scaled_array=scaler.transform(df_30_days_past)
new_scaled_array=scaler.transform(df_30_days_future)
new_scaled_df=pd.DataFrame(new_scaled_array)
new_scaled_df.iloc[:,0]=np.nan
full_df=pd.concat([pd.DataFrame(old_scaled_array),new_scaled_df]).reset_index().drop(["index"],axis=1)
full_df_scaled_array=full_df.values
all_data=[]
time_step=30
for i in range(time_step,len(full_df_scaled_array)):
data_x=[]
data_x.append(full_df_scaled_array[i-time_step:i,0:full_df_scaled_array.shape[1]])
data_x=np.array(data_x)
prediction=my_model.predict(data_x)
all_data.append(prediction)
full_df.iloc[i,0]=prediction
new_array=np.array(all_data)
new_array=new_array.reshape(-1,1)
prediction_copies_array = np.repeat(new_array,5, axis=-1)
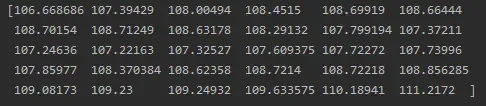
y_pred_future_30_days = scaler.inverse_transform(np.reshape(prediction_copies_array,(len(new_array),5)))[:,0]
print(y_pred_future_30_days)数据:30行4列
结果:
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。
版权声明:本文为博主作者:数据杂坛原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/sinat_41858359/article/details/136443741