文献阅读(51)—— Transformer 用于中国空气质量检测
文章目录
AirFormer: Predicting Nationwide Air Quality in China with Transformers


这一篇还放在arxiv,但是看到下面的aaai让我很心动。一起康康吧~
先验知识/知识拓展
- 多头自注意力机制(MSA)
- 变分自编码器(VAE)
文章结构
- abstract
- introduction
- preliminary
- methodology★
- experiments
- related works
- conclusion and future
背景
- 国家为检测全国空气质量,在多地建立站点,这些站点会逐个小时反馈现在的空气质量(包括各种气体排放量)
- 在过去很多年,对空气质量预测进行长期建立的研究,从经典的色散模型到数据驱动的模型
- 但是因为计算量问题,大量研究都集中在一个站点或者是一个城市的部分站点
提出问题:
- 使用全国所有站点的空间污染指数预测中国大陆的空气质量。这样精细的涵盖很多范围的预测,不但为公众提供了更多有用的信息,而且包含了更多有利于模型训练的样本数据。但是如此之多数据传统Transformer的效率会对建模产生困难。
- 空气质量读数在本质上是不确定的,由于:不准确或确实的观察结果,以及一些不可预测的因素:汽车尾气、政策和工业排放。
因为空气污染会有域的影响,所以作者提出AirFormer,有利的结合区域信息建模取得更好的可解释性。 其中主要涉及两个阶段:
- stage1:deterministic stage
在此阶段,提出了两种新的MSA有效的捕获空间和时间的依赖性(解决Q1) - stage2:stochastic stage
在此阶段,使用VAE的思想探索在Transformer中的隐变量。这些隐变量是从上一阶段中学习到的概率分布中采样得到的,从而捕获输入数据的不确定性。(解决Q2)
核心目的:使用之前时间的所有站点数据预测未来某时间的空气质量指数
文章方法
AirFormer Framework
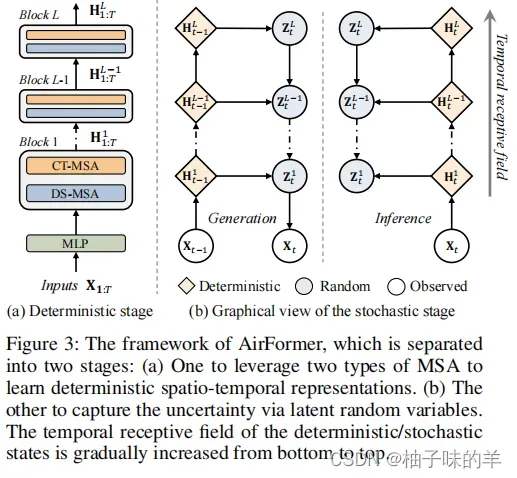
-
Bottom-up deterministic stage
- DS-MSA:学习具有线性复杂度的空间交互作用
- CT-MSA:捕获每个位置的时间依赖性
-
Top-down stochastic stage
- generation 是使用之前步骤的先验概率去预测下一个步
- inference 是用于估计后验概率
1. Dartboard Spatial MSA(DS-MSA)
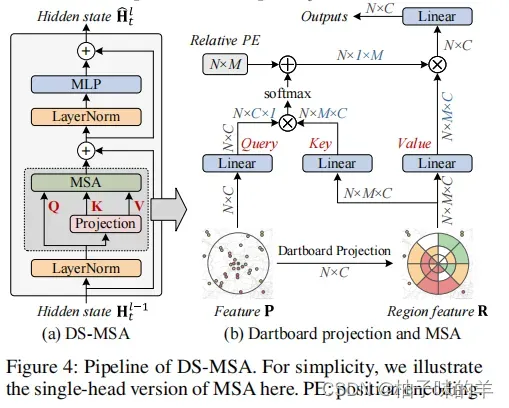
整体设计
一个地方的空气质量,除了当地的排放外,还会收到相邻地方的影响。提出了DS-MSA去捕获同一时间某地方与其他区域的联系。DS-MSA有更大的感受野但是却只有线性的计算复杂度。DS-MSA以上一个block得到的隐变量H作为输入,首先对其进行LayerNorm将其经过Linear层生成该站点的query矩阵,并将周围环境投影到Dartboard中得到key和value,以该方法减少计算复杂度。最后执行MSA学习空间依赖性,利用MLP输出结果H1。
详细设计
- 对于每个站点,都会有一个相应的映射矩阵A(M*N),其中M表示区域数量,N表示站点总个数。A矩阵中的值a[i,j]表示第j个站点属于i区域的可能性,A矩阵中一行值的和0(类似AVG)
- 对于每个站点区域的划分,是以当前站点为中心的同心圆,如下面例子中一共有3*8+1=25个区域(25<<1000+,极大地降低计算复杂度)
- 假设进入dartboard映射的输入是P矩阵(NC),通过A矩阵,可以得到每个站点的区域表示R[i] = A[i]P(MC),最终的区域表示是R = [R1,R2,R3…Rn](NM*C),N个站点的区域表示concat得到。
- 之后使用得到的query和根据R经过linear得到的key和value进入MSA捕获空间关联。
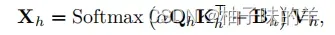
- B是一个可学习的相对位置编码用于增加位置信息。我们可以引入风俗风向等外部信息作为辅助。
DS-MSA模块考虑了空气污染分散的领域知识,由于将区域的个数从N个站点降低到M个region,计算复杂度降低,使用dartboard映射不会再MSA中引入额外的可学习变量,固模型是轻量级的。
2. CT-MSA
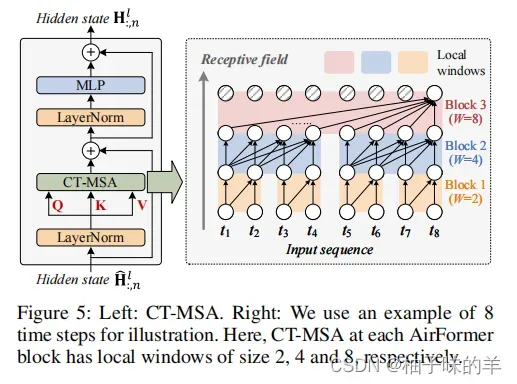
整体设计
一个地方的空气变化不但会受到周围地区的影响,还会受到之前空气排量的影响。如果直接使用MSA学习时间依赖会产生平方级的成本,因此使用CT-MSA代替标准MSA
详细设计
- 鉴于时间越接近当前时间相关性越强,因此作者使用非重叠的窗口,在窗口内执行MSA捕获时间步长之间的局部交互作用。为了尽量不丧失MSA的感受野,作者从上到下逐渐增加了窗口的大小。
- 时间因果关系:由于当前时间的空气质量不以其未来为条件,所以遵循WaveNet在MSA中引入因果关系,确保模型不会违反输入数据的时间顺序。这种顺序关系可以在mask attention map中的区域实现。
- 为了在MSA中实现位置敏感性,在CT-MSA的输入中增加了绝对位置编码。
3. 自上而下的随机阶段
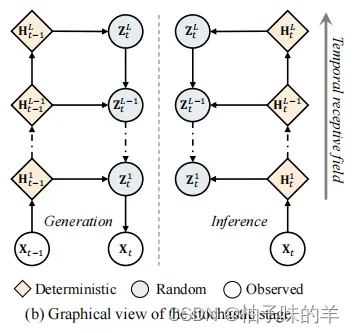
整体设计
在使用自下而上的两个MSA获得确定性以后,作者使用自上而下阶段对潜在随机变量学习空气质量数据中的不确定性
详细设计
- 生成阶段(generation):在过去所有的步骤中预测下一步
- 推理阶段(inference):推断模型被应用于近似给定当前和先前步骤的 Z 的后验分布。也就是说,推断模型的作用是根据当前和之前的数据,来预测未知变量 Z 的概率分布。这种方法可以帮助我们更准确地推断出 Z 的值,从而得到更可靠的结果。

这个部分我没读懂,因为我对VAE的原理真的只懂浅显,数学渣渣搞不定这么多公式,我哭。所以我找来了我的好朋友ChatGPT帮我理解,它是这样解释的:
- 在AirFormer模型中,Top-Down Stochastic Stage是用于预测未来空气质量指数的一个重要步骤。这个步骤主要利用随机性来增强模型的表现力和稳健性。
- 具体地说,Top-Down Stochastic Stage包括两个子步骤:Top-Down Sampling和Stochastic Prediction
- 在Top-Down Sampling阶段,模型会以历史观测数据和先前生成的空气质量指数值作为输入,并使用Decoder来生成一组可能的未来时刻的候选空气质量序列。每个候选序列都是从“起始”标记开始生成的,直到达到预定的预测时间窗口为止。
- 在Stochastic Prediction阶段,模型会对所有候选空气质量指数序列进行评估,并选择其中最能符合真实未来空气质量指数的序列作为最终的预测结果。这个评估过程基于一个分数函数,它将历史时刻的观测数据、先前生成的空气质量指数值以及每个候选序列的概率分布情况结合起来计算得出。
- 需要注意的是,在Top-Down Stochastic Stage中,每个候选空气质量指数序列都是通过随机采样生成的。这种随机性的引入可以使模型更好地处理未知和噪声数据,从而提高模型的泛化能力和鲁棒性。同时,使用多个候选序列并对它们进行评估,也可以增强模型的表现力和预测准确性。
文章结果
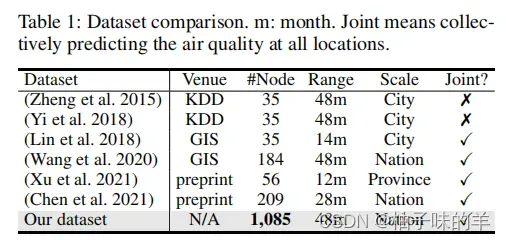
1. 数据集
2. baseline的比较
评估指标选择:MAE和RMSE
- 传统方法
- STGNN变体
- 基于注意力机制的模型
- 空气质量预测模型
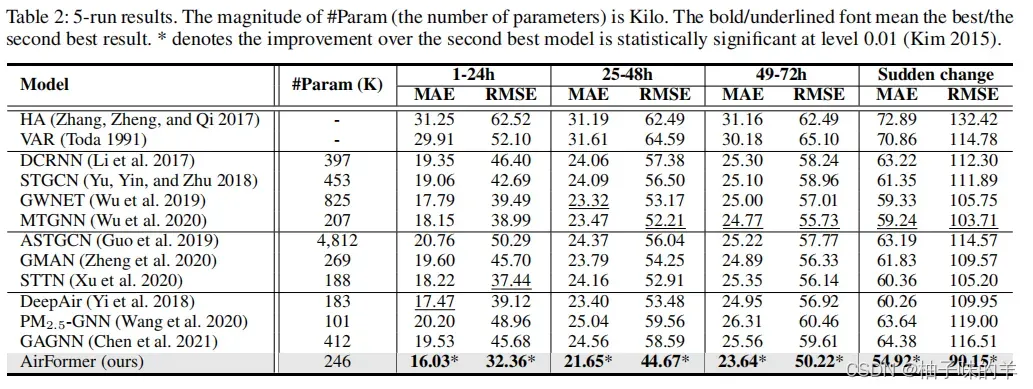
这验证了空气污染的领域知识不仅有助于我们设计更多解释的模型,而且提高了预测的精度。
3. 消融实验
(1)DS-MSA的性能
对比了没有DS-MSA,标准的MSA,MSA(50km),DS-MSA(50-200),DS-MSA(50),DS-MSA(50-200-500)。灰色行表示最终的模型,加粗为最好,横线表示性能第二好的。
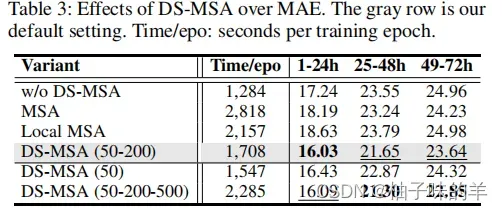
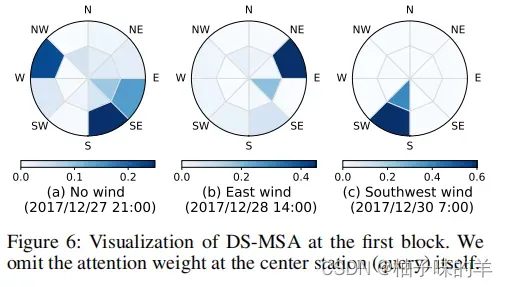
此外为了验证DS-MSA的性能,对以西直门为中心的50-200的dartboard进行研究,当没有风的时候,权重被分散,如果有来自东风或者西南风,注意力的权重会集中在相应的方向上,这说明DS-MSA不但有效,而且对于模型的可解释性也更强。(咱就是说真牛!)
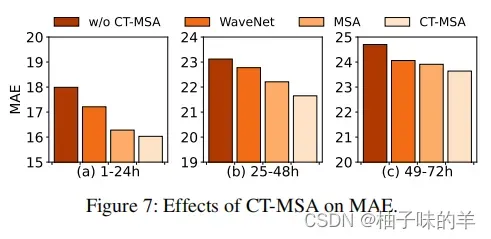
(2)CT-MSA的性能
对比了没有CT-MSA,WaveNet取代CT-MSA,标准的MSA。首先可以看到所有具有时间模块变体的模型性能都比没有CT-MSA的性能好,这一现象说明根据时间建模的必要性,此外,两个使用锁头注意力机制的模型性能比WaveNet的性能好,说明了MSA在空气质量预测的优越性。此外,将英国关系和局部窗口集成到MSA可以持续提高性能!(看到这里我表示respect!)
(3)隐变量的性能
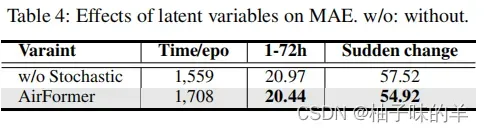
因为气体扩散的随机性,捕获空气质量数据中的不确定性可以有效的提高性能,增强模型的鲁棒性。
(4)位置编码的性能
由于MSA是排列不变的,作者将位置编码集成到DS-MSA和CT-MSA中,用来考虑顺序信息。
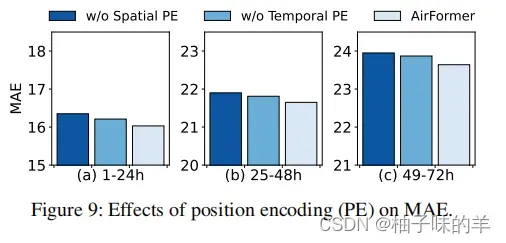
Contributions
- 考虑到附近区域的空间对该区域的相关性要大于遥远区域的相关性,设计了DS-MSA有效捕获位置空间关系
- 设计了因果时间模块CT-MSA学习时间依赖性,确保每一个步骤的输出只来自前面的步骤。引入局部性来提高效率
- 使用VAE模型的思想,增强了具有隐变量的transformer,以此捕获空气质量数据的不确定性
- 是第一次共同预测数千个地点的空间质量的工作,比现有的SOTA误差低4-8个百分点。
总结
无论是实验内容还是写作方面,这篇文章都是值得精读的,反复看了三遍,但是我觉得还需要再看。真的别人发顶会,投好期刊不是没有道理的。虽然说预测的性能不想一般分类和分割模型那般优秀,但是这种不确定性因素很强的bg,能做到这么详尽真的不多见了,很久没有读到过这么有营养的文章了,respect!
可借鉴点/学习点?
都给我去看!
文章出处登录后可见!