玩了两个多月的AI语音,还是挺有意思的,收获颇多,不禁让人感叹AI已经进化到如此境界了,之前还有AI实时换脸的,两者配合起来使用简直让人不敢想象,这世上还有什么是真的。总之就是做一个学习记录,从下载到训练到推理到使用推理出来的音频做视频之内的,还有一些音频干声处理心得以及部分bug的解决方式。
目录
训练要求:N卡显存最好是6G往上(最新版的RVC似乎支持A卡,有需求的可以自己试试)
先从下载开始:
RVC整合包(0717版、0813版):RVC AI变声器813版本 含模型和虚拟声卡入梦整合包 (PC) – 入梦AI模型社区
SVC整合包:快速开始 · 语雀
下载整合包之后,解压到某个只有英文路径的盘下(中文其实也可以,不过这是个好习惯,因为国外的很多玩意都不支持中文),内存要大,几十G不嫌少,几百G不嫌多,不然训练的模型很快就会占满,像这样
准备训练集
干声集:即只有人的声音没有任何伴奏杂声的音频,比如说我要训练神里绫华(日配)的声音,我就去找声优的音频,她的一些配音角色,像约尔福杰、蝴蝶忍、蛇喰梦子、花鸟卷、神里绫华等等还有很多,可以自己去番剧中剪,也可以直接去游戏中找音频,也可以去一些视频网站上找这个角色的对应漫剪。
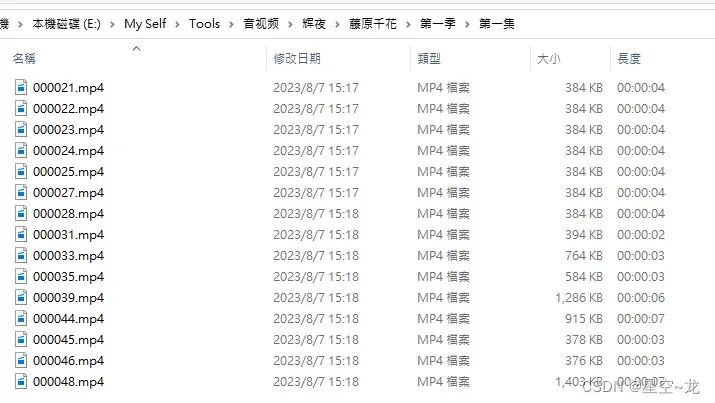
这里只展示手动去番剧中剪的方法(虽然有工具但还是比较耗时),也可直接去漫剪中找现成的,比如说我要提取辉夜大小姐中的藤原千花的全部语音片段,首先,我把下载全部三季动漫的MP4文件
然后准备好三季对应的字幕文件,这里有两种方法
第一种剪辑方法
自己去一些字幕网站上下载对应的字幕文件(ASS文件或SRT文件):
首页 – 射手网(伪) – assrt.net – 字幕下载,字幕组,中文字幕,美剧字幕,英剧字幕,双语字幕,新番字幕
下载好之后,用 ARCTIME 导入视频和字幕文件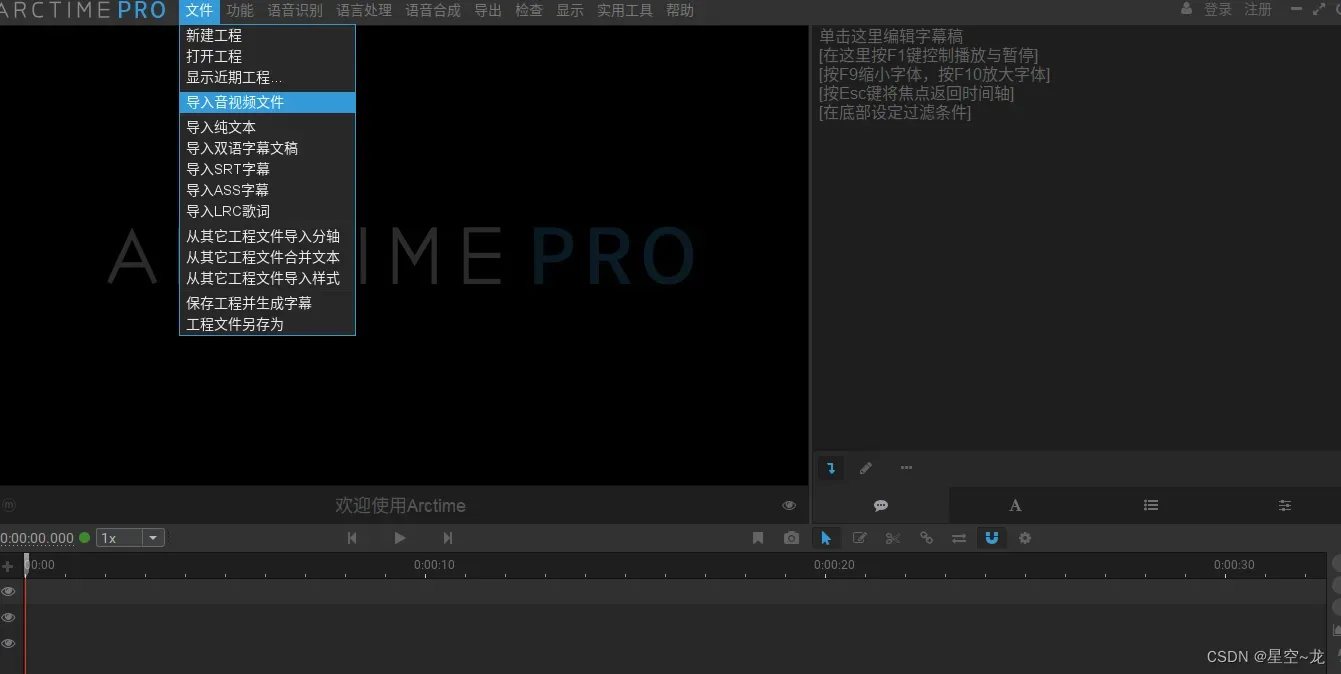
然后观察动漫镜头是否和字幕对应得上,如果对应不上,例如,实际视频字幕要比导入的字幕快12秒左右,可以用功能中的时间轴整体平移来调整观察。
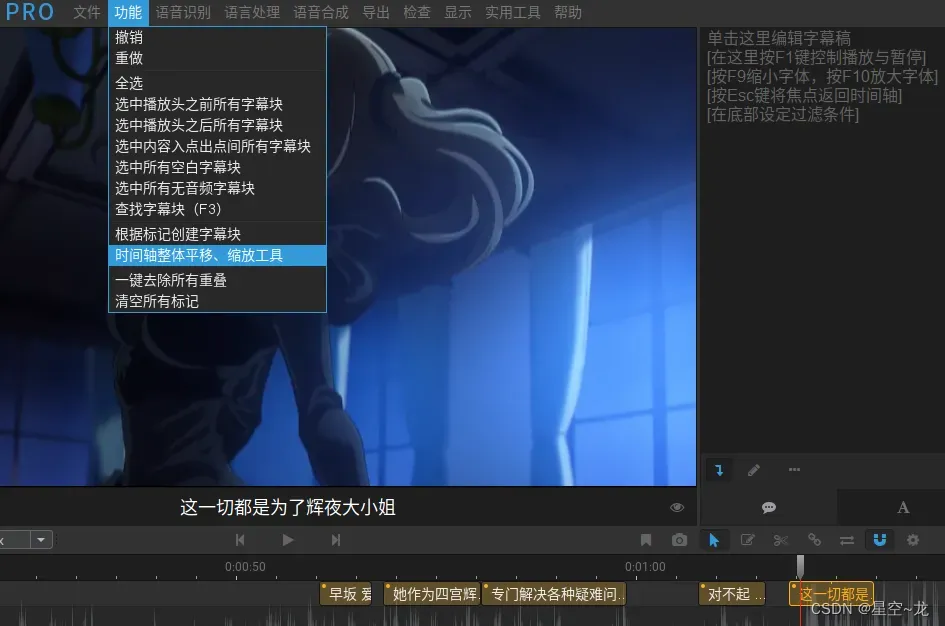
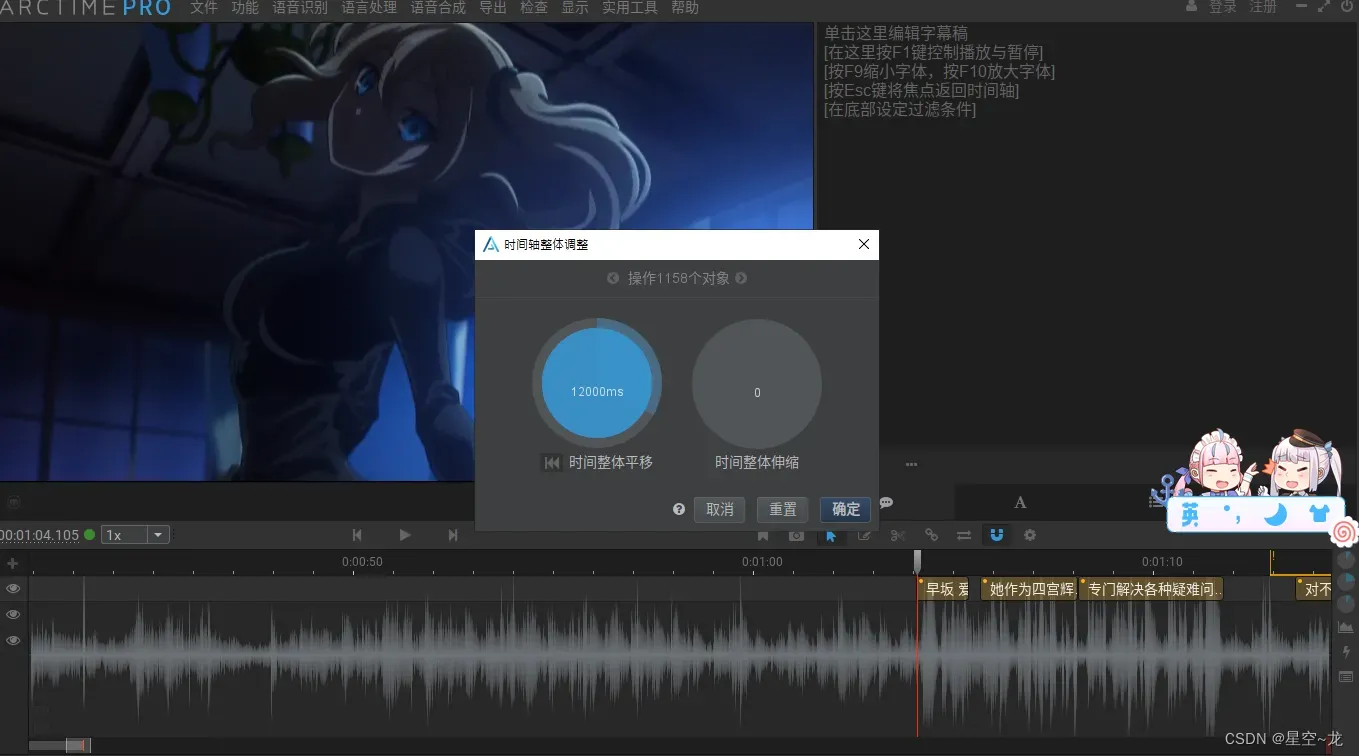
将字幕往后平移12000毫秒(12秒)之后才和视频对应的上,记住这个关键的秒数,12秒,然后, 打开 QuickCut(QC),选择视频和对应字幕后,将字幕时间偏移调整为12秒,取消勾选导出分段srt字幕,然后点击运行。

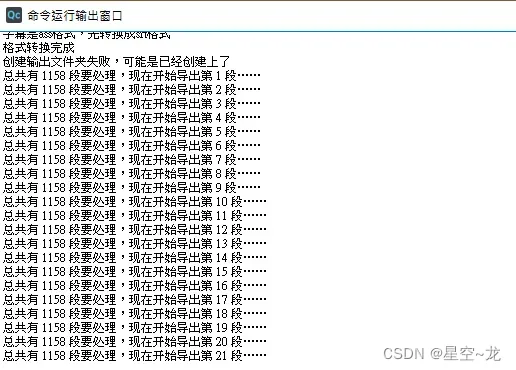
等待运行完成所有字幕对应的视频片段就分割好了(这样就相当于把所有角色说话的部分分割了下来),分割好的视频会在选择的视频的路径的文件夹中,我的建议是把1秒以下的片段全部去除,因为太短了,有些可能只是一些语气声音,根据视频长度排序然后删除1秒以下的片段之后,打开AudioDataset 开始手动的区分角色语音,先导入所有视频片段,选择视频片段所在目录即可,使用AudioDataset 筛选完执行的时候一定要注意,导出的文件夹不能是同一个,要分集导出,不然上一集筛选的内容会被覆盖(来自群友血的教训)。
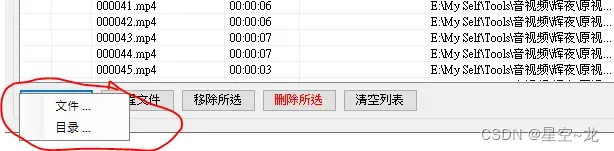
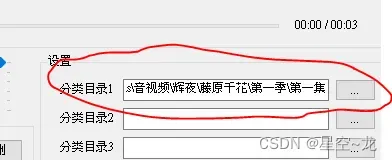
然后设置好对应角色的视频片段存储路径,有两个角色就设置两个
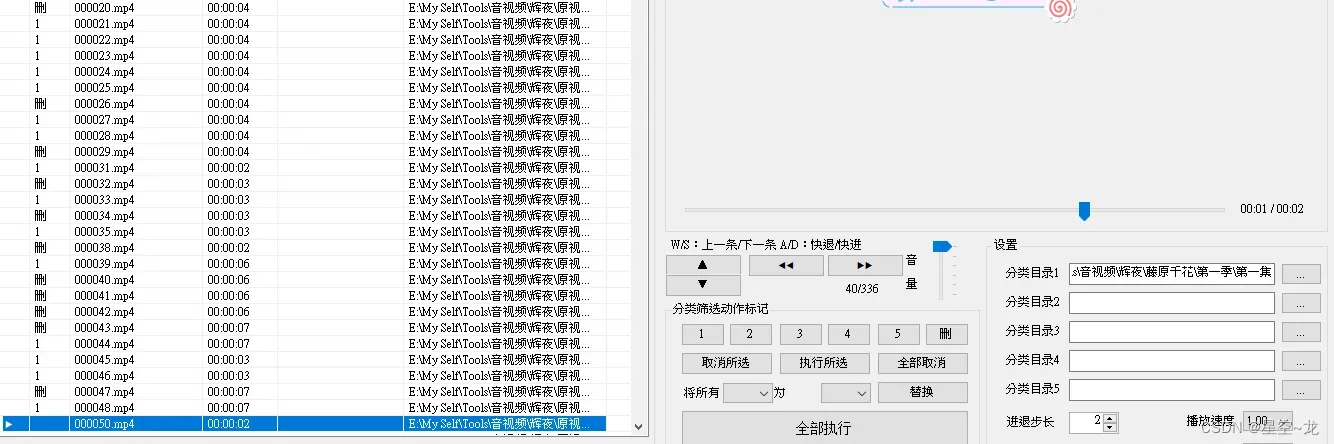
按空格开始播放,按键盘上的1,2,3,4,5可以标记要存储的位置,Delete可以标记要删除的视频(即不需要的),接下来就是一个一个视频的看(听),全部标记完之后点击全部执行即可完成操作,然后到存储的文件夹去查看对应的视频
再具体点的可以去B站看这个视频
[干货]教你快速提取番剧角色干声,告别手动剪辑!_哔哩哔哩_bilibili
然后每一集都要这样操作,将所有视频全部整好之后,可以用我写的一个小工具,将所有文件夹的视频整合到一个文件夹以及重命名,路径的话比如说,我剪了藤原千花所有的视频,路径为 藤原千花/季数/集数/所有视频,路径就选最外面的这个 “藤原千花”,下面的路径则选一个空文件夹。程序没有做什么验证,所以母文件夹以及子文件夹的所有文件都会被重命名(从1开始)放到新文件夹下。
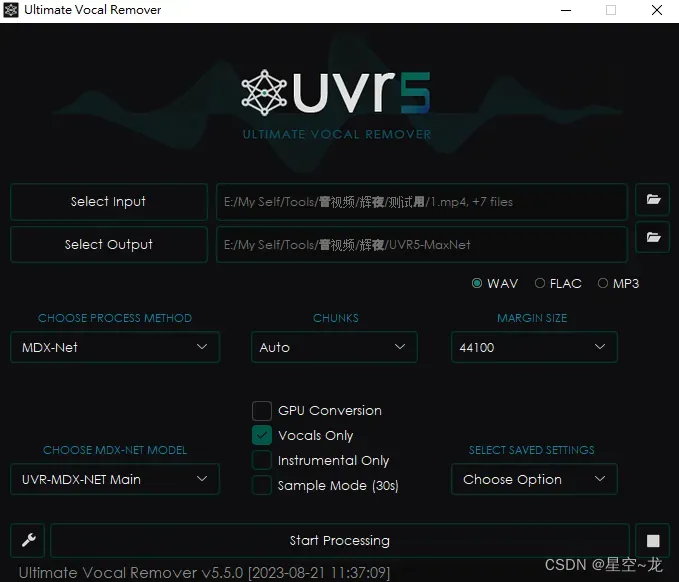
然后用 UVR5 进行人声伴奏分离,选择输入所有视频(我是一半一半分离的,显卡内存不够,选太多会爆显存) ,选择输出到某个空文件夹,格式选WAV就好了,声音分离方式选MDX-Net(也可以试试其他的,个人认为这个就足够用了),然后下面的模型选最后一个UVR-MDX-NET Main,勾上GPU Conversion(GPU加速)和Vocals Only(只保留人声),然后执行,完成之后到输出文件夹去查看,这样部分干声集就准备完成了。数据集理论上是越多越好,当然,质量为最优先考虑的。
第二种剪辑方法
和第一种方法差不多,我就不细说了,有缺点而且更加的繁琐,大概说一下,就是下载MKV格式的原视频,然后用工具去识别字幕,然后分离字幕文件,然后和上面一样,根据字幕分割视频,快的一部就是不需要使用 ARCTIME 去判断字幕偏移了多少,可是多出了识别字幕和分离字幕的操作,而且实测MKV文件在使用 QuickCut(QC)进行分割视频的时候要慢不少,具体操作同样是看这个up的,个人认为还是下载mp4视频文件和字幕文件然后判断偏移量再分割比较好。
[干货]教你快速提取番剧角色干声,告别手动剪辑!_哔哩哔哩_bilibili
开始训练(RVC)
RVC:双击打开项目中的go-web.bat
选择“训练”,设置好训练名称,(采样率选48k,版本选v2,听说这样效果更好),训练集路径(一定要是英文!一定要是英文!一定要是英文!),保存小模型的频率,训练轮数(数据集和训练轮数的比例大概是40分钟500轮的样子,我是凭感觉来的),显卡占用(batch_size,不能设置得太大,比如说我电脑N卡是8G显存,另一个集显也是8G,如果我设置显存超过了8G,则会降低N卡的频率和集显一样,也就是说内存是高了,但性能却低了,得不偿失,所以我设置6G或者7G,不超过8G就刚好可以把N卡的全部性能吃满又不会炸显存,SVC训练同理),然后点一键训练。
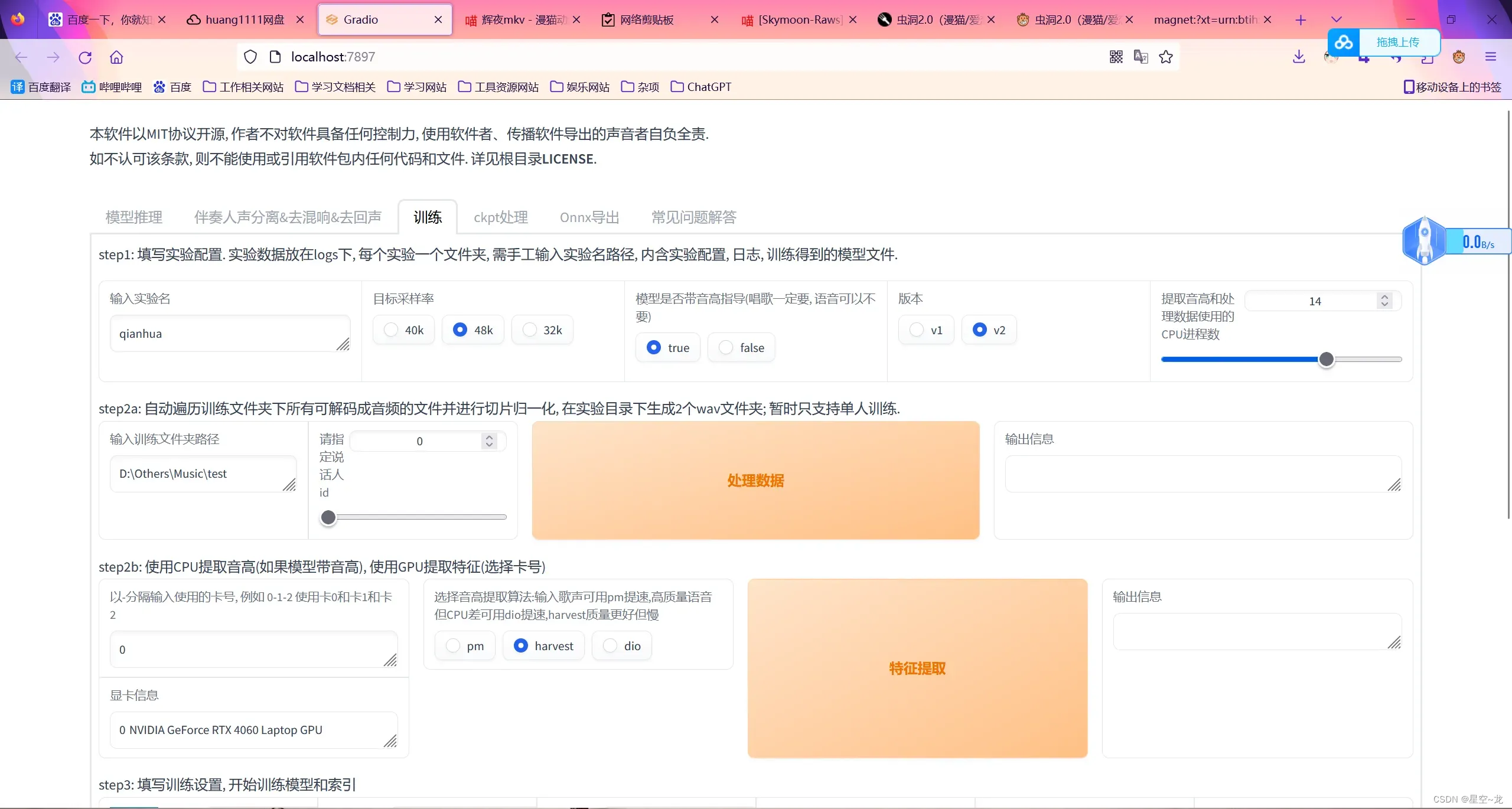
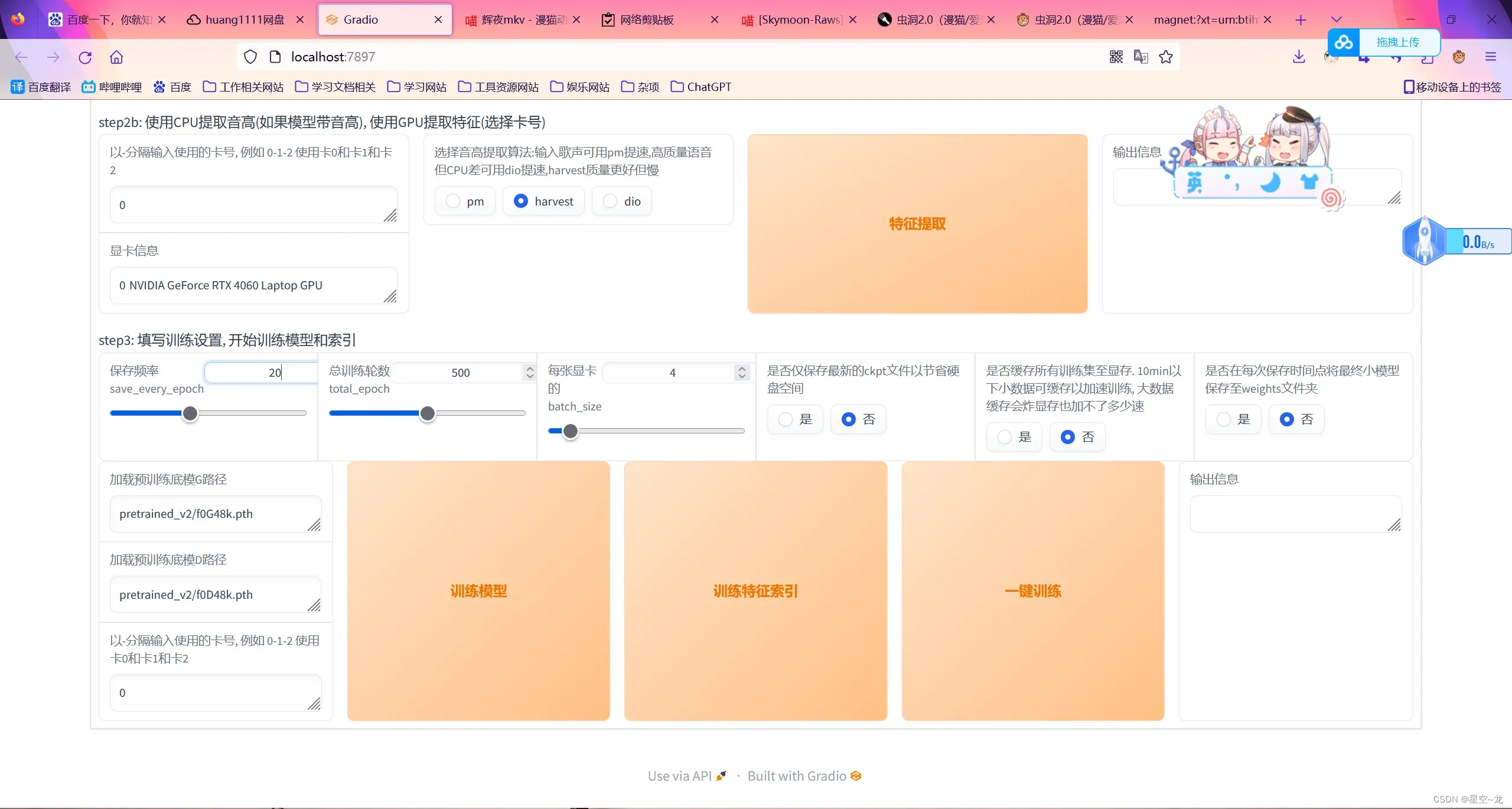
等训练结束后总模型会存在项目的“weights”文件夹中,保存的小模型则保存在“logs”文件夹中,logs文件夹中模型的作用,比如说我40分钟的数据训练了500轮,拿总模型推理出来效果不是很理想,然后我去logs文件夹里面对应模型的train.log(训练日志)查看,发现loss_gen在第400轮的时候变的很高(仅供参考,实际上我也不知道loss_gen可不可以作为实际参考价值,这个我也是在RVC群里面问了那些炼丹大佬他们教的),然后把小模型中的400轮之前的模型复制出来放到weights文件夹,然后推理去听听效果,一些心得:干声的质量是第一!长度才是第二!不要为了湊时长而把干声集都污染了,一粒老鼠屎打坏一锅汤!
开始训练(SVC)
SVC的训练和RVC的千篇一律,双击“启动webui.bat”
然后选择训练,将数据集放入项目中的“dataset_raw”文件夹中,文件夹目录 dataset_raw/qianhua/干声集
SVC对于干声的处理要更多一些,需要对干声集进行切片处理,RVC则不需要,我们分割出来的音频本来就才2秒——7秒左右,所以我们使用 QuickCut(QC)软件(以下称QC)融合所有音频之后在切片一次。使用QC软件的合并功能,点击+号,然后将所有音频全部添加进去(双击音频行可以移除所有音频),点击运行合并。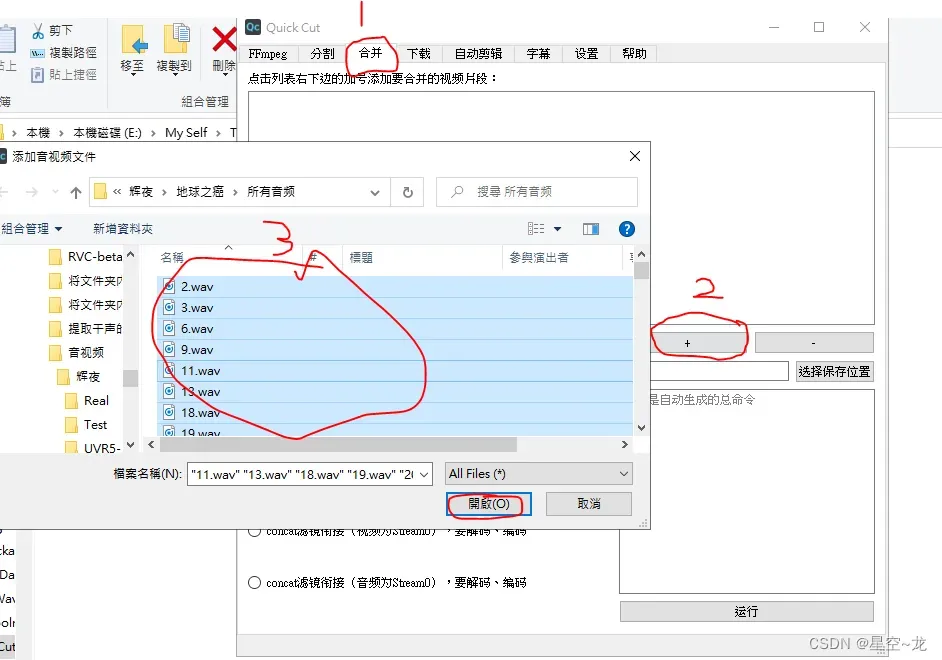
然后再使用QC的分割功能,使用第二种(根据片段时长进行分割),我们设置7秒左右
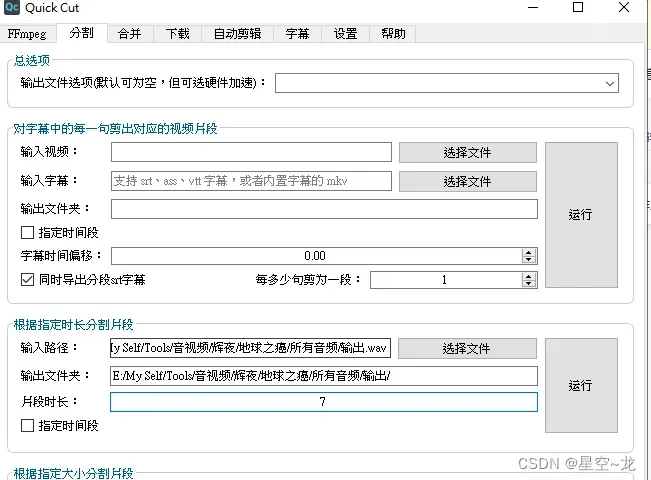
分割完成之后文件夹中就全是干声并且都是7秒的片段了。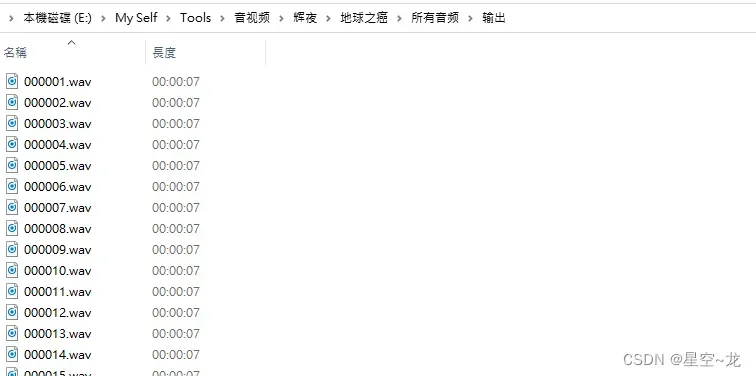
然后再放入项目中的“dataset_raw”文件夹中,运行“启动webui.bat”,识别数据集,数据预处理,设置batch(显存占用,和RVC的batch_size一样),然后写入配置文件,从头开始训练或者继续上一次训练(logs——>44k内的文件夹中是上一次训练进度),停止训练可以按Ctrl+C,然后可以推理试听效果,模型文件就在logs/44k文件夹中,要是这一炉觉得训练好了,准备开始下一炉训练了,什么都不用管,和第一次训练一样,直接点从头开始训练,会默认将上一炉结果保存至项目中的“models_backup”文件夹中,具体教程可以看b站up的视频
【AI翻唱/SoVITS 4.1】手把手教你老婆唱歌给你听~无需配置环境的本地训练/推理教程[懒人整合包]_哔哩哔哩_bilibili
SVC一些常见的问题:、
我所遇到的问题:
在数据预处理时报错了:’gbk’ codec can’t decode byte 0x8f in position 8: illegal multibyte sequence
win11系统遇到的,下载的是整合包,解决方案:在区域和语言里面勾上这个
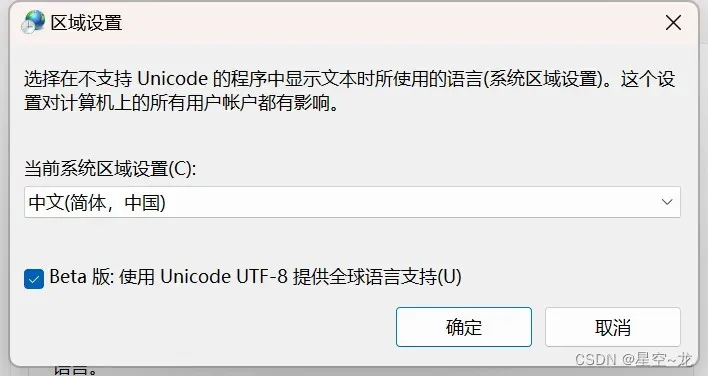
然后就可以训练了。
模型推理(RVC)
推理很简单,就是设置好使用的模型、需要推理的音频、特征文件和音高提取算法(建议使用rmvpe),然后点击转换就好了。
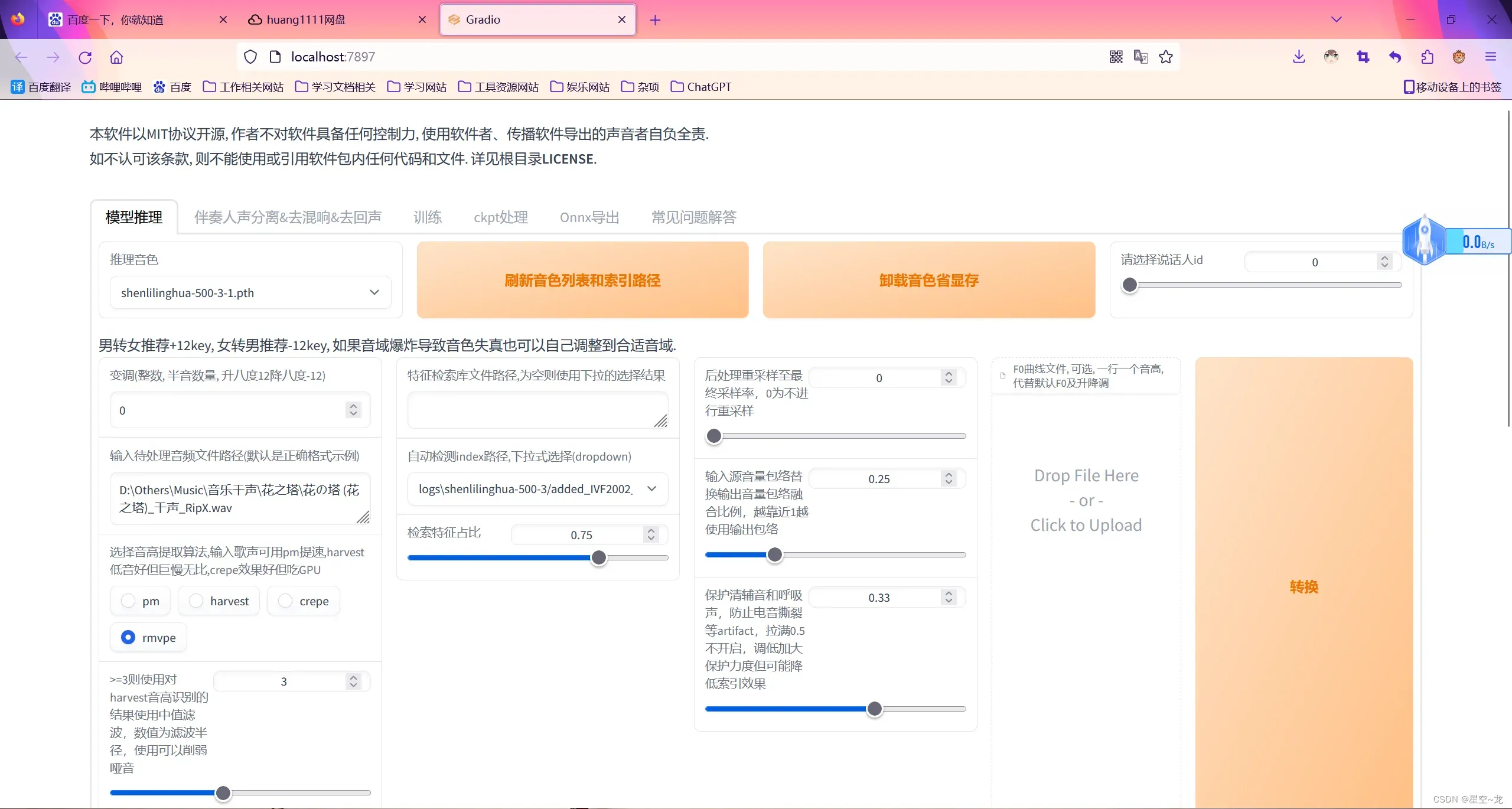
推理完成之后可以在下面进行播放试听,其中推理环节中,最难的是被推理音频干声的处理,因为模型只是模拟音色,如果被推理音频有很多杂音伴奏之内的,这些声音也会被推理就会失真电音之内的,所以我们要把音频的伴奏杂音去干净。
模型推理(SVC)
SVC的推理和RVC差不多,选择模型,加载模型,上传音频然后推理,下面的参数可以自行修改调试。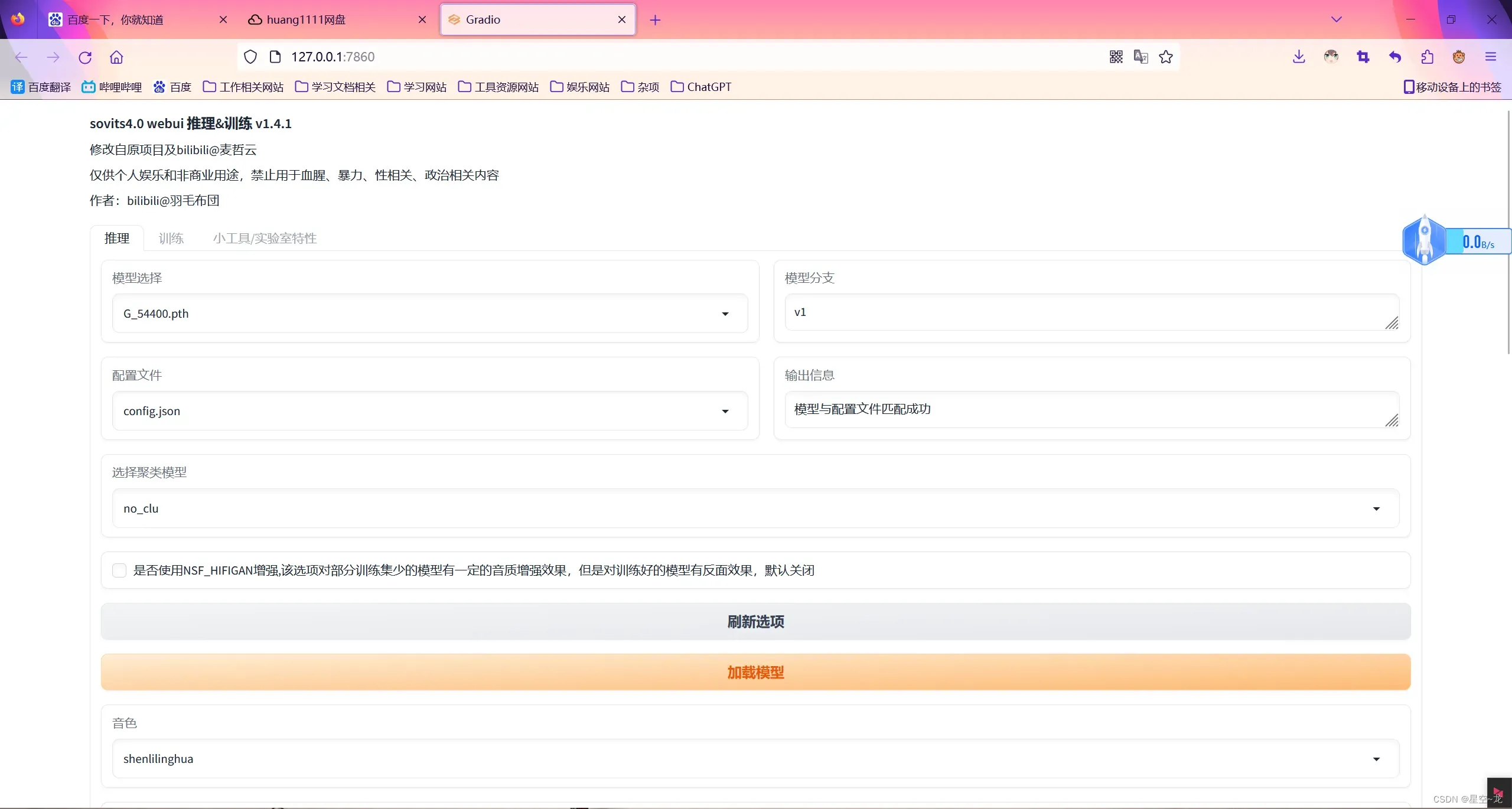
音频干声的处理
第一步:使用UVR5进行人声伴奏分离,UVR5算是市面上很强大的人声伴奏分离软件了,如果连这个都分不干净建议放弃这段音频,UVR5所使用的模型可以看这个up的视频:
【教程】如何优雅的分离 修复人声_哔哩哔哩_bilibili
未鸟大佬的视频,讲了很多段,最主要的就是RVR5所使用的模型,可以按照大佬的模型来,在UVR5上下载,然后设置模型。
分离之后,可以很清晰的听到只有人声了,不过有的歌我分离出来的伴奏中也会轻微的漏人声,就感觉有点违和,比如说《花の塔》,个人觉得可以使用UVR5的VR Architecture中的1_HP-UVR.pth模型去提取一下伴奏,实际使用时1_HP-UVR.pth提取伴奏要比2_HP-UVR.pth提取的伴奏更干净些。很多歌都有和声部分(和声:多个人的声调),其实UVR5中也有可以去除和声的模型(5_HP-Karaoke-UVR),但是去除得太暴力了,有时候连主人声都被去除了,这个时候就需要用到RipX这个软件了
第二步:使用 RipX 手动移除和声
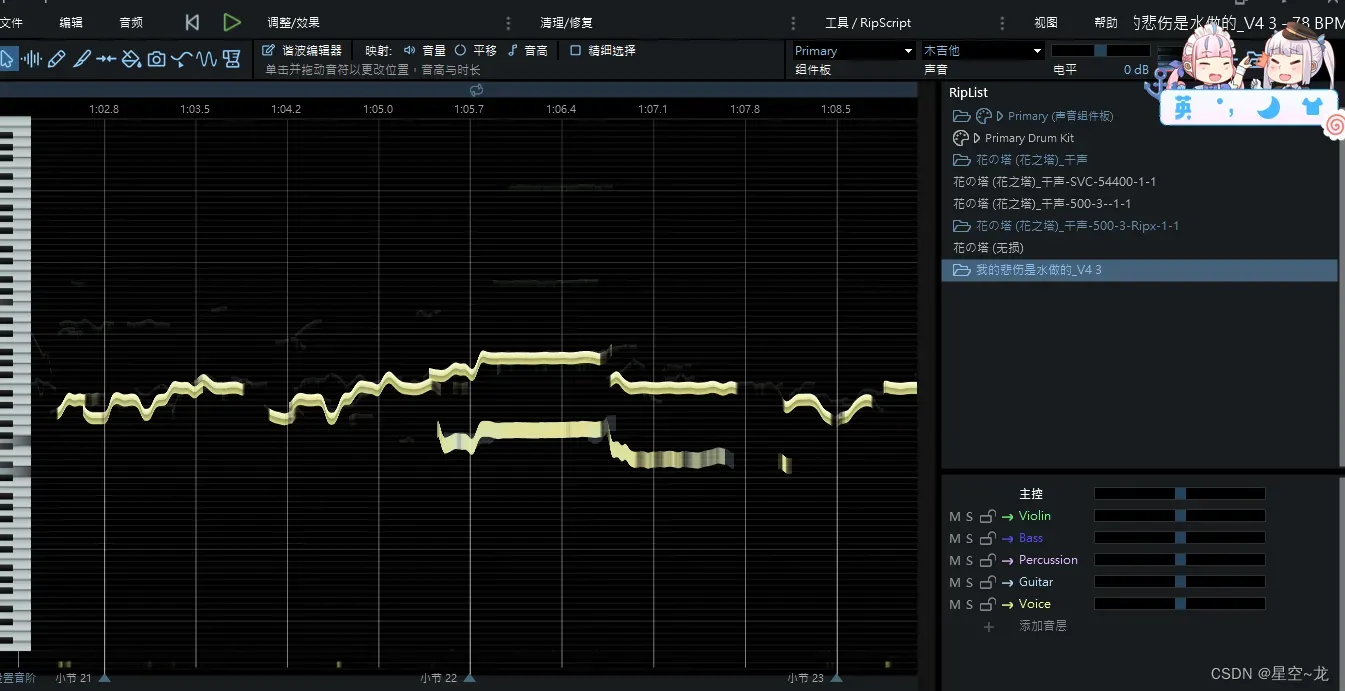
直接选中和声部分,按Delete删除,有的歌和声音调和主声音调一样就去除不了,不过音调一样推理出来也不会有大的违和感。
处理完和声,再去推理,效果就很好了。
最终合成
我是把RVC的推理结果和SVC的推理结果都放到RipX里去,选取两个音频中比较好的部分组合到一起,然后再导出成最终音频,然后再把导出来的音频,和UVR5分离出来的伴奏,进行融合。
我所使用的融合方法:使用 GoldWave 软件进行音频合成,先打开干声和伴奏,然后选择其中一个,点击上方的复制,再选择另一个,再点击混合。
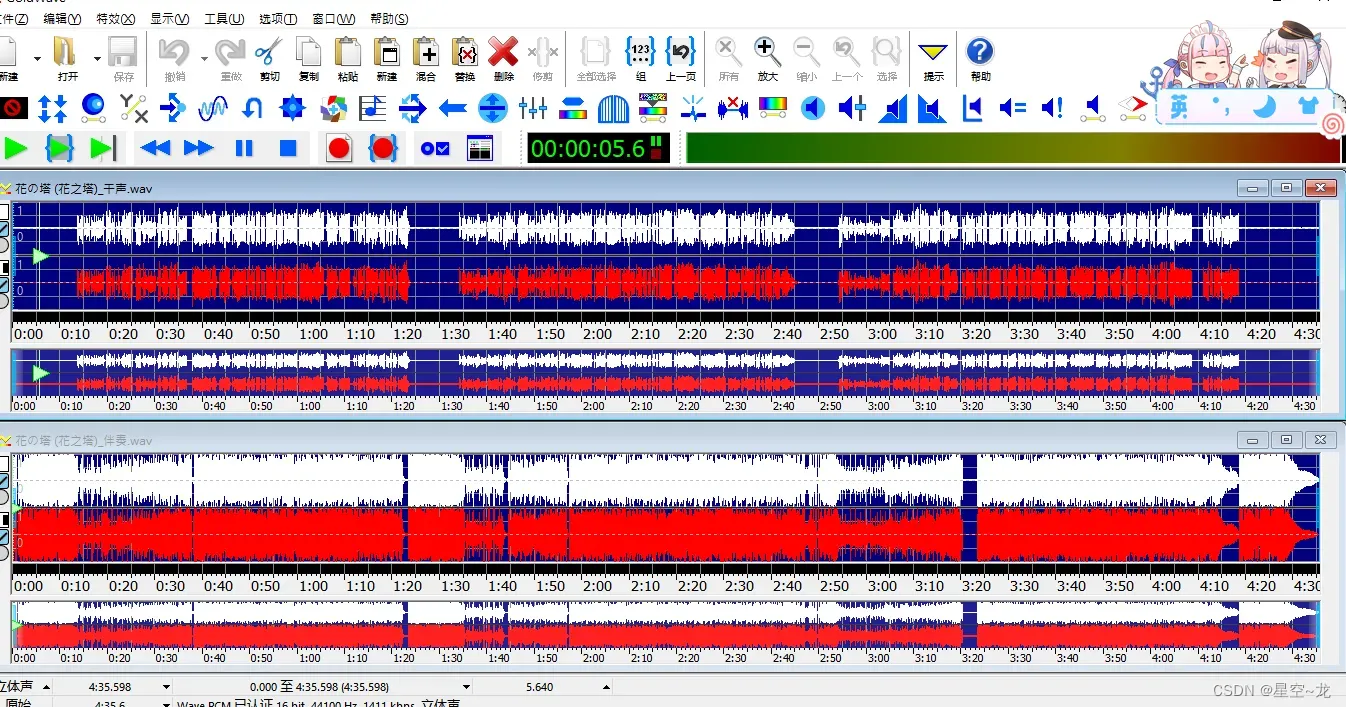
混合之后点击上面的“文件”——>“另存为”,不要保存,不然就覆盖掉了,另存为然后叉掉就不会覆盖掉。
当然,如果要用音频来做视频那更简单,直接把伴奏和干声都拖进去,起始点设置一样就好了。
一步一步走过来,磕磕绊绊的,遇到了问题也不知道问谁,加了很多群和大佬去学习经验,学了很多乱七八糟的东西,像ARCTIME我是用来判断视频和字幕的偏移量的,GoldWave用来剪取和融合音频的,Mkvtoolnix用来提取字幕,QuickCut用来根据字幕分割视频以及融合(分割)音频的,UVR5(人声伴奏分离),RX10(音频修复),RipX(去除和声),还有PS,AE等等
这是我训练然后推理的其中一个,还是挺不错的。
【AI 神里绫华】忘れてやらない(绝不会忘记)_哔哩哔哩_bilibili
在此做个记录以免忘记,如果想起来还有未记录的会回来补齐。
文章出处登录后可见!