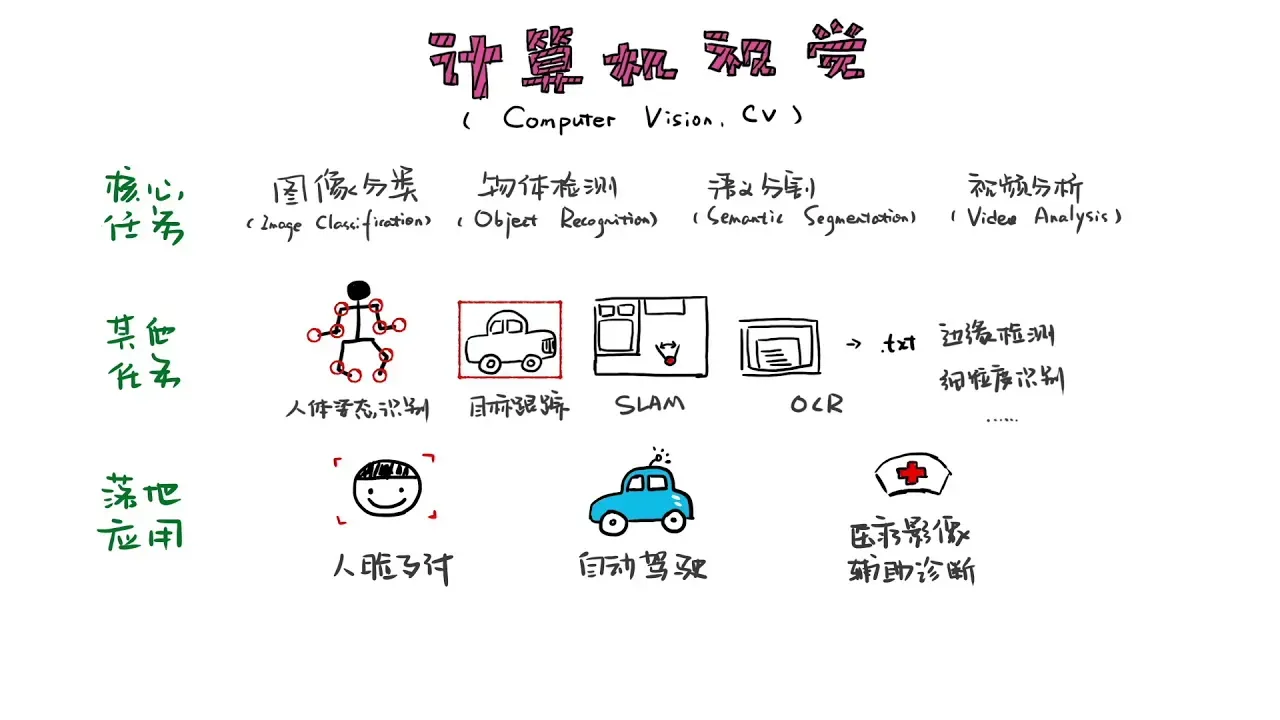
计算机视觉及其基本任务
什么是计算机视觉
计算机视觉(Computer Vision)
计算机视觉是一门研究如何使机器“看”的科学,更进一步的说,就是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理,使电脑处理成为更适合人眼观察或传送给仪器检测的图像或其他形式的信息。
计算机视觉与其相关领域
和计算机视觉相关的领域从顶向下包括但不限于机器视觉,图像处理,模式识别,信号处理,再往下就是例如代数与几何,高等数学,极限等基础的数学知识了。
机器视觉
机器视觉是计算机视觉用于执行某些(生产线)动作的特例。在化工行业中,机器视觉系统可以检查生产线上的容器(是否干净、空置、无损)或检查成品是否恰当封装,从而帮助产品制造,输入为图像,输出可以是位置坐标,厚度,坏点位置,质量不合格区块等多元化的输出形式,计算机视觉是工业4.0的重要组成部分,提升机器参与流水线,减少工人成本投入。

关系:计算机视觉更偏重于计算机理解图像的内容或生成新的图像,更偏重于“计算机科学”领域。而机器视觉更强调精准化和实际生产相结合,更偏向“计算机技术”领域。计算机视觉主要指面向神经网络,深度学习的应用。机器视觉则会结合部分神经网络,以及传统的图像处理算法更多。
图像处理
图像处理是一门独立的学科,图像处理研究图像去噪、图像增强等内容,输入为图像,输出也是图像。需要注意的是,数字图像处理常常从人类视觉成像的原理方面来作为出发点,利用人眼成像的一些特性,例如视觉暂留,例如对高频信息不敏感,例如人眼最多能分辨24位的颜色。
数字图像的经典应用领域(传统图像处理)包括:
- 几何变换(geometric transformations):包括放大、缩小、旋转等。
- 颜色处理(color):颜色空间的转化、亮度以及对比度的调节、颜色修正等。
- 图像融合(image composite):多个图像的加、减、组合、拼接。
- 降噪(image denoising):研究各种针对二维图像的去噪滤波器或者信号处理技术。
- 边缘检测:进行边缘或者其他局部特征提取。
- 分割:依据不同标准,把二维图像分割成不同区域。
- 图像编辑:和计算机图形学有一定交叉。
- 图像配准:比较或集成不同条件下获取的图像。
- 图像增强(image enhancement):图像的恢复,动态范围扩展等
- 图像数字水印:研究图像域的数据隐藏、加密、或认证。
- 图像压缩:研究图像压缩。

关系:计算机视觉可以利用图像处理技术进行图像预处理,但图像处理本身构不成计算机视觉的核心内容。但现在也有很多用深度学习来解决传统图像问题的方法。
模式识别
模式识别技术根据从图像抽取的统计特性或结构信息,把图像分成特定的类别。例如,文字识别或指纹识别。
关系:在计算机视觉中模式识别技术经常用于对图像中的某些部分进行处理,例如分割区域的识别和分类。同时,模式识别可以看作是催生了人工神经网络的学科,是模式识别最早提出了神经元的概念,后续的人工神经网络只是用了更多的神经元组合为一层,而深度神经网络是用多层神经元组成的多层系统。另外,模式识别中的各种聚类算法,也是现在数据科学的起源,在大数据的多个领域(如广告,推荐,数据建模)等都有很广的应用。
信号处理
信号处理,就是要把记录在某种媒体上的信号进行处理,以便抽取出有用信息的过程,它是对信号进行提取、变换、分析、综合等处理过程的统称。图像也属于光学信号的一种,数字图像处理本身就是依托于信号处理作为技术理论基础。
关系:计算机视觉虽然不与信号处理直接相关,但是信号处理所涉及到的卷积,正负反馈,马尔可夫链,控制学理论和系统反馈等概念一直都是计算机视觉底层的逻辑来源。例如基于信号频域转化的傅里叶变换,对于图像这种二维信号,人们提出了图像的卷积操作来转换信息的维度。基于正负反馈系统的原理,提出了反向传播和残差的概念。基于马尔可夫链下一个阶段的状态只与前一个状态有关的理论,提出了循环神经网络(RNN)和长短期神经网络。另外信号处理涉及到的数学知识,例如代数与几何,极限,微积分,数字信号处理等知识,也是计算机视觉中重要的理论部分。
下面的这张图,来自于维基百科,生动形象的解释了几大领域之间的关系以及每个方向更强调的部分:
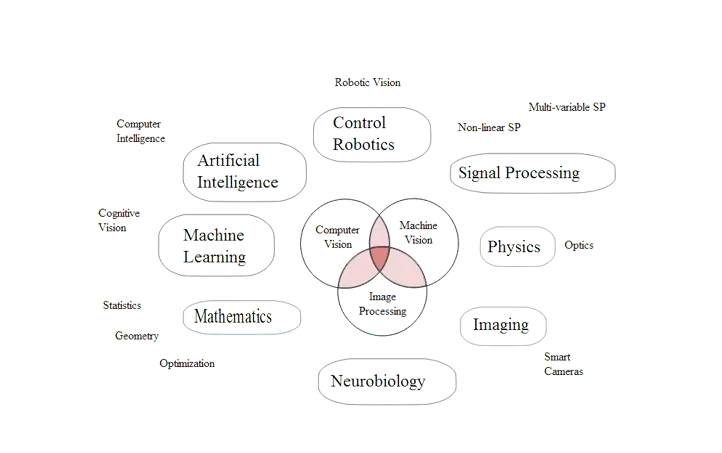
总结
- 计算机视觉更偏向利用深度学习和神经网络来解决图片的理解,处理,生成,语义转换等任务,随着算力与数据的增加,逐步辐射到下面的各个领域,具有不可解释性,即无法用公式描述出数据从输入到输出所经历的计算过程。
- 机器视觉会用到神经网络(但一般不是深度学习,因为实时性要求极高),模式识别,以及传统的图像处理算法来解决工业生产环境中的问题。
- 图像处理的输入和输出一般都是图片,致力于提升图片的可读性,美感,以方便人提取更多的信息,目前在计算机视觉中常用于计算机视觉任务数据集的前处理,清洗,标准化。
- 模式识别是信号处理向人工智能迈进的中间学科,提出的神经元是人工智能的基石。但模式识别的大部分方法还是有公式,输入到输出都有详细的公式,而计算机视觉涉及到深度学习,一般都不具有可解释性,即无法总结出数据在模型内部经过处理的公式。
- 信号处理涉及到的多种信号,声光电,而图片只是一种特殊的二维信号,信号与系统中的很多知识都成为了启发改进深度学习网络的原动力。
计算机视觉的任务:
处理对象
计算机视觉所面对的有两个对象:图像和视频(视频可以看作是一个连续的图像序列,不过针对视频连续序列的特征,相当于也有很多额外的信息引入)

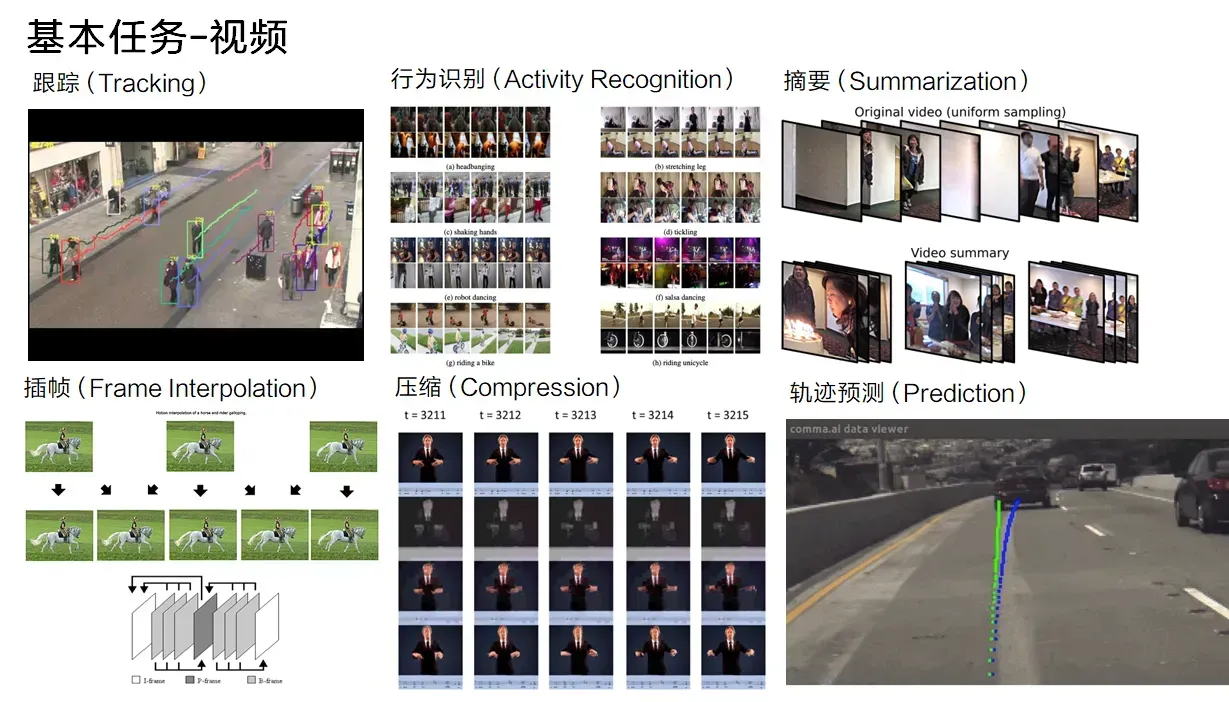
三大经典任务:分类、检测和分割
其中分类是为了告诉你“是什么”,检测任务的目标是为了告诉你“在哪里”,而分割任务将在像素级别上回答了在哪里这个问题。
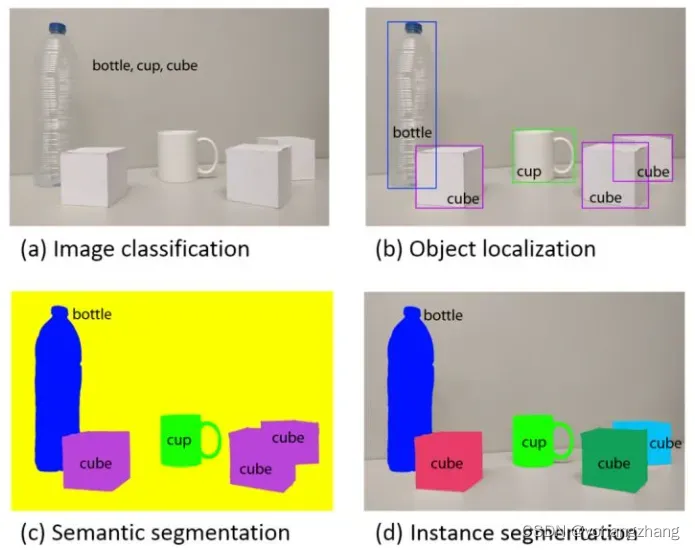
其他应用场景:
图像生成(Generation)
通过算法生成图片
子任务
随机生成
风格迁移

图片合成

图片翻译

典型应用:卡通化、换脸、换装
关键点定位(KeyPoint)
定位图像中的关键像素点
子任务
人脸关键点
人体关键点
 手势关键点
手势关键点
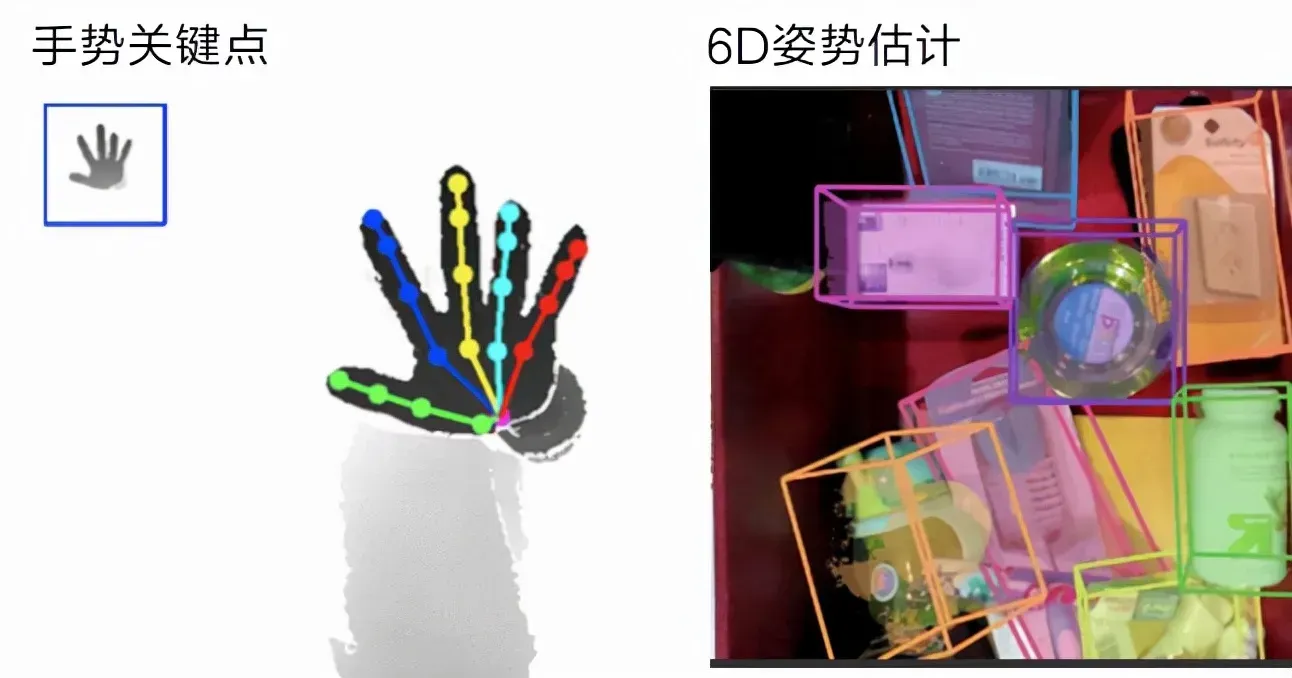
物体姿态估计
典型应用:人脸配准、手势识别
图像恢复(Restoration)
退化图像生成高质量图像
子任务
超分辨率
图像去噪

图像修补
去模糊

上色、去雾、去雨
典型应用:拍照画质增强、老照片修复
视频插帧(Video Interpolation)
合成任意时刻的视频帧,从而优化解决视频中卡顿、抖动等画
典型应用:慢动作视频制作
单帧HDR(动态范围展宽)
目前比较新的研究领域:
多模态
多模态研究: 目前的许多领域还是仅仅停留在单一的模态上,如单一分物体检测,物体识别等,而众所周知的是现实世界就是有多模态数据构成的,语音,图像,文字等等。 VQA 在近年来兴起的趋势可见,未来几年内,多模态的研究方向还是比较有前景的,如语音和图像结合,图像和文字结合,文字和语音结合等等。例如通过输入文字来生成图像或者视频,通过语音,字幕,图像来理解视频的内容等。
生成
数据生成: 现在机器学习领域的许多数据还是由现实世界拍摄的视频及图片经过人工标注后用作于训练或测试数据的,标注人员的职业素养和经验,以及多人标注下的规则统一难度在一定程度上也直接影响了模型的最终结果。而利用深度模型自动生成数据已经成为了一个新的研究热点方向,如何使用算法来自动生成数据相信在未来一段时间内都是不错的研究热点,或者用算法来创造内容都是可以增长的方向点。

视觉问答
做到让计算机能够理解图片中的元素,例如询问这是什么,它是什么颜色,有几个等问题,在这个意义上能够高度接近人类的功能。
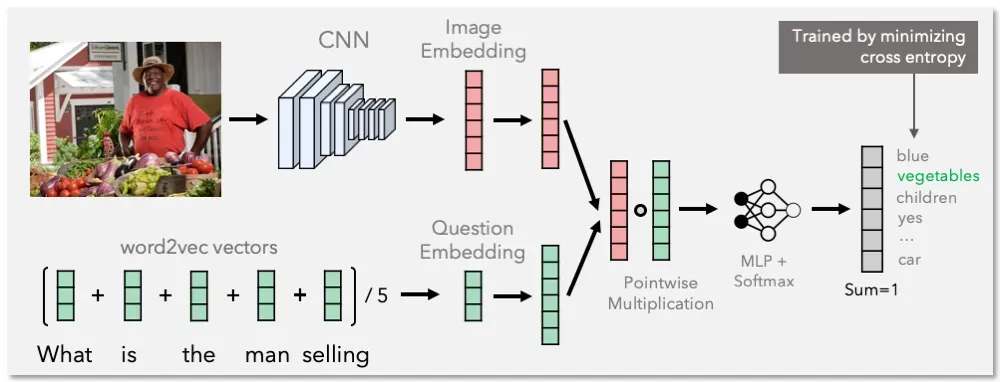
计算机视觉模型的工作流程:
计算机视觉的模型的训练及推理部署的简化全流程:
这里只写出了比较宽泛的概念,来源于英伟达对于CV流程的介绍,但是涵盖了训练,精炼,部署,执行的全套关系。
扩展阅读:
人体所获得的信息,80%来自视觉
百闻不如一见 包括人类在内的所有动物,都会感受外界所传来的各种信息,借以掌握外界的状况而加以行动。为了感受信息,人类拥有五种感觉:视觉、听觉、嗅觉、触觉、味觉,也就是所谓的“五感”。
虽然人类可以从眼睛、耳朵、鼻子、皮肤、舌头等处获得信息,但是可以取得最多信息的,就是视觉。在借助“五感”所获得的信息中,大约有80%是来自视觉。对人类而言,视觉信息最容易了解,也最能够信赖,因此有“百闻不如一见”这样的谚语。
虽然在这句谚语中,视觉与听觉之间有着100倍的差距,但还是有10%的外界信息是透过听觉取得的。在信息获得能力上,视觉遥遥领先第二名听觉。 不过视觉也有弱点。在没有光线的黑暗中,无法看见物体,因此就不能借助视觉来获取信息
肉眼可以识别的颜色约有1600万种,占24位色深
以三种视锥细胞识别颜色 蓝、绿、红三种颜色称为三原色。将三原色适当地切割混合之后,可以产生出任何一种颜色,彩色电视也是由三原色构成的。人类通过视网膜里三种视锥细胞的作用,而能够感知到各种颜色。
视锥细胞分为可以有效捕捉蓝光、绿光、红光特性的三种细胞。各种视锥细胞可以捕捉光的波长,将信息传入脑中以辨别颜色。 光的波长差异可以被感知为颜色的差异。人类可以感受的光线波长为380~780纳米的范围,此范围的光被称为可见光。其中,400纳米左右为紫色;500纳米附近为绿色;700纳米前后为红色。
人类只能感知到固定范围波长内的光线,因此能够识别的颜色也有限。 人类可以识别的可见光颜色为红、橙、黄、绿、蓝、靛、紫等七种基本色,以及这些颜色的中间色,大约有160种颜色。
色深和位深:
色深就是屏幕单个像素能显示的最大颜色数二进制位数,比如24位,30位;
位深就是单个颜色的表示二进制位数,比如8位,10位等。
色深意思就是用来描述单个像素的色彩比特数,通俗的话就是说用来描述色彩的丰富程度。
色深一般采用 RGB 三通道的数值总和来表达。常见的24bit、30bit、36bit彩色扫描仪, 它们每通道的量化数值分别为8位,10位,12位,表示其每通道内有256、1024、4096阶层次的信息。
位深的概念则要宽泛一些,它可以用来描述一切将模拟信号量化或将数字信号模拟化的设备的精度,是一种采样概念,其常用于表示精度,我们平时常说的摄影机8bit,10bit也是指位深,指摄影机量化采样等精度。
量化,在数字信号处理领域,是指将信号的连续取值(或者大量可能的离散取值)近似为有限多个(或较少的)离散值的过程。量化的过程是先将整个幅度划分成有限个小幅度(量化阶距)的集合,把落入某个阶距内的样值归为一类,并赋予相同的量化值。
量化位数越大,可以表现的值越精细,例如,8bit的量化位数可以表示256个数值,连续的数值会被离散化为0-255中的数,如果信号的值域在0到1之间,如果我有一个0.83的数,按照8bit量化,等式可以列为0.83/x=1/255,得到x=211.65,取整为211(第一幅图),但是如果我们采用10bit量化,可以表示1024个数值,那么等式可以列为0.83/x=1/1024, x=849.92, 取849,量化台阶变得更细了(第二幅图)。
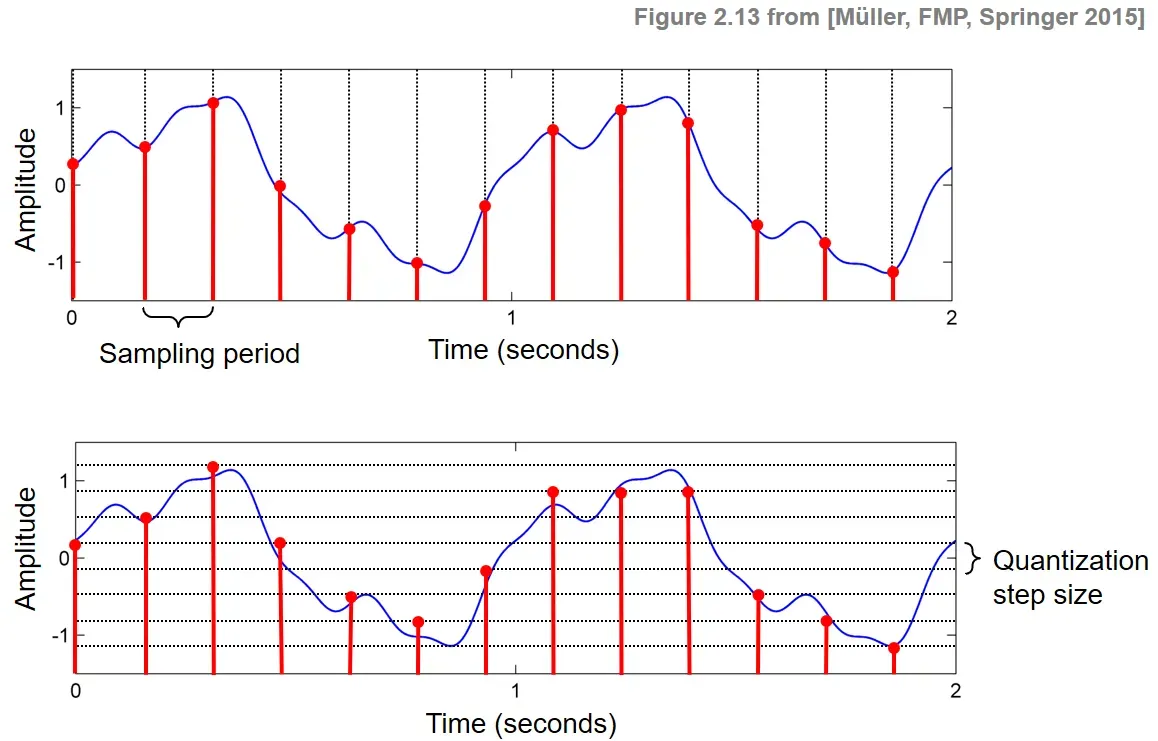
量化在有损数据压缩中起着相当重要的作用。很多情况下,量化可以被当作将有损数据压缩同无损数据压缩相区别的标志之一。量化的目的通常是为了减少数据量。一些压缩算法,例如MP3和Vorbis,以有选择地丢弃部分数据作为压缩的一种方法,这种手段可以被认为是量化的过程也可以被看作是一种有损压缩的形式。
JPEG也是一种利用了量化的图像有损压缩。JPEG的编码过程对原始的图像数据作离散余弦变换,然后对变换结果进行量化并作熵编码。通过量化可以降低变换值的精度,从而减少图像的数据量。当然,精度的损失意味着图像质量的下降。然而图像的质量可以通过量化位数的选择加以控制。例如,JPEG在每像素3比特的精度下得到的图像质量还让人可以接受的,相对于PCM抽样得到的每个像素24比特的原始图像来说,数据量大大下降了。
最后是色深和位深换算举例:
10bit位深可以显示1073741824种色深即为30bit色深,10.7亿色(1024×1024×1024=1073741824);
8bit位深可以显示16777216种色深即为24bit色深,1677万色(256×256×256=16777216)
总而言之,
色深面向的对象是RGB/RGBA合起来的显像单元,针对成像单元
位深是单一的硬件上R/G/B/A单个二极管的亮度,针对单一通道
文章出处登录后可见!