数据集格式介绍及转换
- 一、COCO数据集
- 1.1 相关介绍
- 1.1.1 数据集发展历程介绍
- 1.1.2 文件格式
- 1.1.3数据集下载地址
- 1.1.4数据集使用常见组合方式
- 1.2 目录层级
- 1.2.1 目录文件结构及其含义
- 1.2.2 每个类标签文件结构以及标签内容
- 1.2.3 标签xml文件结构
- 1.3 数据集自制
- 1.3.1 数据集目录层级制作
- 1.3.2 标注图片(如labelImg工具)
- 1.2.3 相关脚本代码
一、COCO数据集
COCO官方地址
1.1 相关介绍
1.1.1 数据集发展历程介绍
COCO_2014包含16.4万张图像,分为训练集(8.3万张)、验证集(4.1万张)和测试集(4.1万张);
COCO_2015年在 COCO_2014基础上扩充了额外的8.1万张图像测试集;
COCO_2017年将训练集/验证集分配从8.3万/4.1万更改为11.8万/0.5万张,新的拆分使用相同的图像和标注(annotation),测试集是 COCO_2015测试集的子集包含4.1万张。此外, COCO_2017版本包含一个新的未标注的12.3万张数据集。
总共有80个类别。
使用较多的是 COCO_2017。
class names: [‘person’, ‘bicycle’, ‘car’, ‘motorcycle’, ‘airplane’, ‘bus’, ‘train’, ‘truck’, ‘boat’, ‘traffic light’, ‘fire hydrant’, ‘stop sign’, ‘parking meter’, ‘bench’, ‘bird’, ‘cat’, ‘dog’, ‘horse’, ‘sheep’, ‘cow’, ‘elephant’, ‘bear’, ‘zebra’, ‘giraffe’, ‘backpack’, ‘umbrella’, ‘handbag’, ‘tie’, ‘suitcase’, ‘frisbee’, ‘skis’, ‘snowboard’, ‘sports ball’, ‘kite’, ‘baseball bat’, ‘baseball glove’, ‘skateboard’, ‘surfboard’, ‘tennis racket’, ‘bottle’, ‘wine glass’, ‘cup’, ‘fork’, ‘knife’, ‘spoon’, ‘bowl’, ‘banana’, ‘apple’, ‘sandwich’, ‘orange’, ‘broccoli’, ‘carrot’, ‘hot dog’, ‘pizza’, ‘donut’, ‘cake’, ‘chair’, ‘couch’, ‘potted plant’, ‘bed’, ‘dining table’, ‘toilet’, ‘tv’, ‘laptop’, ‘mouse’, ‘remote’, ‘keyboard’, ‘cell phone’, ‘microwave’, ‘oven’, ‘toaster’, ‘sink’, ‘refrigerator’, ‘book’, ‘clock’, ‘vase’, ‘scissors’, ‘teddy bear’, ‘hair drier’, ‘toothbrush’]
captions: 图像描述的标注文件,看图说话
instance:目标检测的标注文件
person_keypoint:人体关键点检测的标注文件
这3种类型共享这些基本类型:info、image、license。
1.1.2 文件格式
标签:json;图片:jpg
1.1.3数据集下载地址
COCO数据集下载
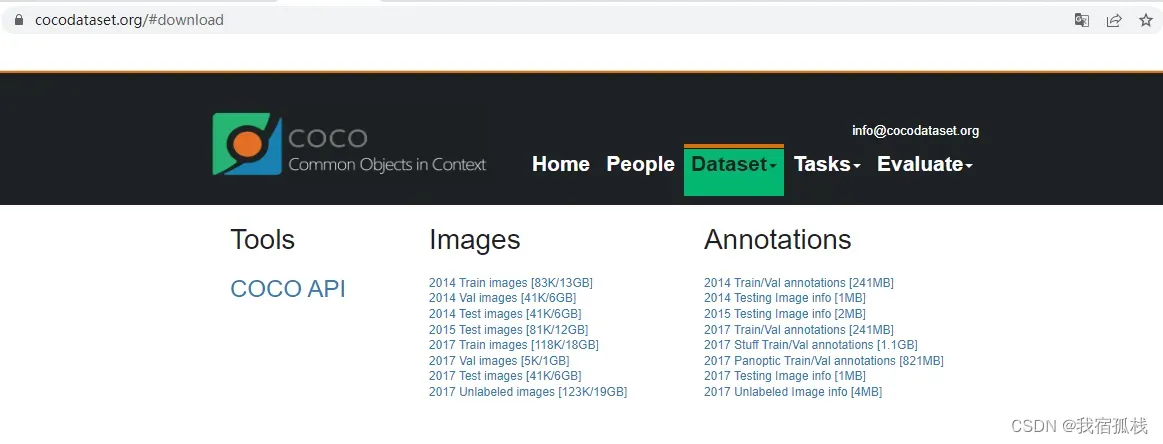
只需要下载2017 Train images\2017 Val images\和对应的所需的Task的annotation即可。
1.1.4数据集使用常见组合方式
1.2 目录层级
1.2.1 目录文件结构及其含义
此处以目标检测为例,组织数据集的文件结构。
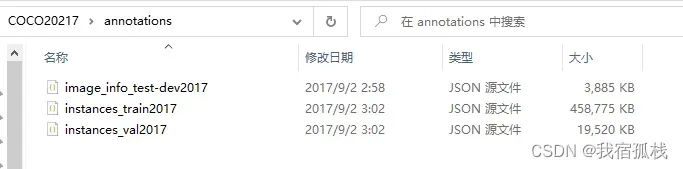
下载下图所示的五个文件。
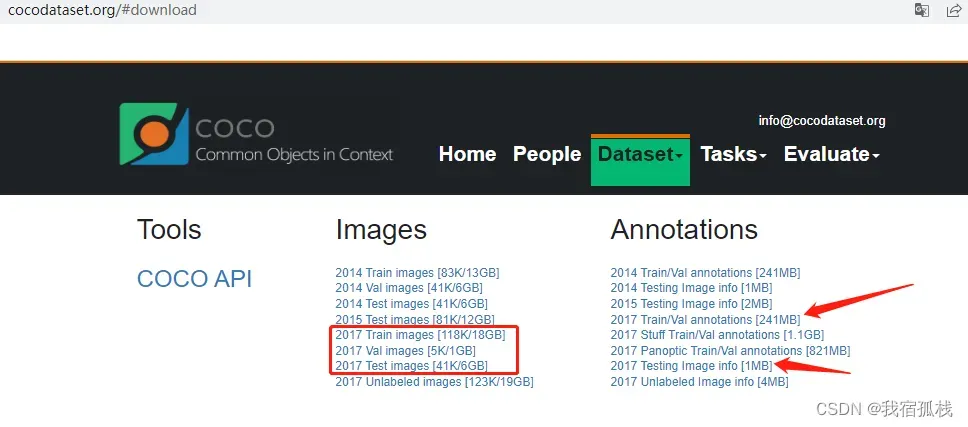

解压后将后三个文件分别放在同一目录下,并新建一个annotations文件。
train2017:所有训练集的图片集(118287)
val2017:所有验证集的图片集(5000)
test2017:所有测试集的图片集(404670)
annotations:标注文件夹
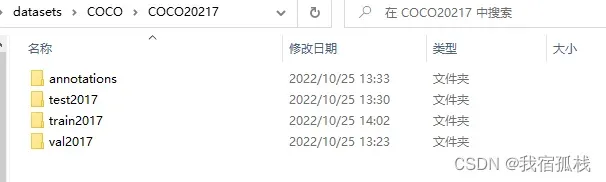
自己训练的时候,没有必要自己划分测试集。只有特别需求的时候,比如参加什么比赛有要求,防止人为修改参数在模型和数据、结果之间作弊。一般通过训练集得到模型,用验证集进行验证就可以满足基本要求了。
1.2.2 每个类标签文件结构以及标签内容
CoCo数据集没有VOC数据集那样一个文件一个xml标注,也没有每个类都有对应的train/val的.txt文件。相应的这部分CoCo存储在json文件中。类似的是它有三个标注类型的train/val对应的json文件。
1.2.3 标签xml文件结构
这3种类型共享这些基本类型:info、image、license。
{
"info": info, # dict
"licenses": [license], # list,内部是dict
"images": [image], # list,内部是dict
"annotations": [annotation],# list,内部是dict
"categories": [category] # list,内部是dict
}
info{ # 数据集信息描述
"year": int, # 数据集年份
"version": str, # 数据集版本
"description": str, # 数据集描述
"contributor": str, # 数据集提供者
"url": str, # 数据集下载链接
"date_created": datetime, # 数据集创建日期
}
license{
"id": int,
"name": str,
"url": str,
}
image{ # images是一个list,存放所有图片(dict)信息。image是一个dict,存放单张图片信息
"id": int, # 图片的ID编号(每张图片ID唯一)
"width": int, # 图片宽
"height": int, # 图片高
"file_name": str, # 图片名字
"license": int, # 协议
"flickr_url": str, # flickr链接地址
"coco_url": str, # 网络连接地址
"date_captured": datetime, # 数据集获取日期
}
info内的信息不需要怎么管,是数据来源和贡献者等信息。license也不需要管。annotation是指不同的TASK的annotation,(那六种task)。image内是图片的size,id,file_name等等。
以instances(目标检测实例)为例:
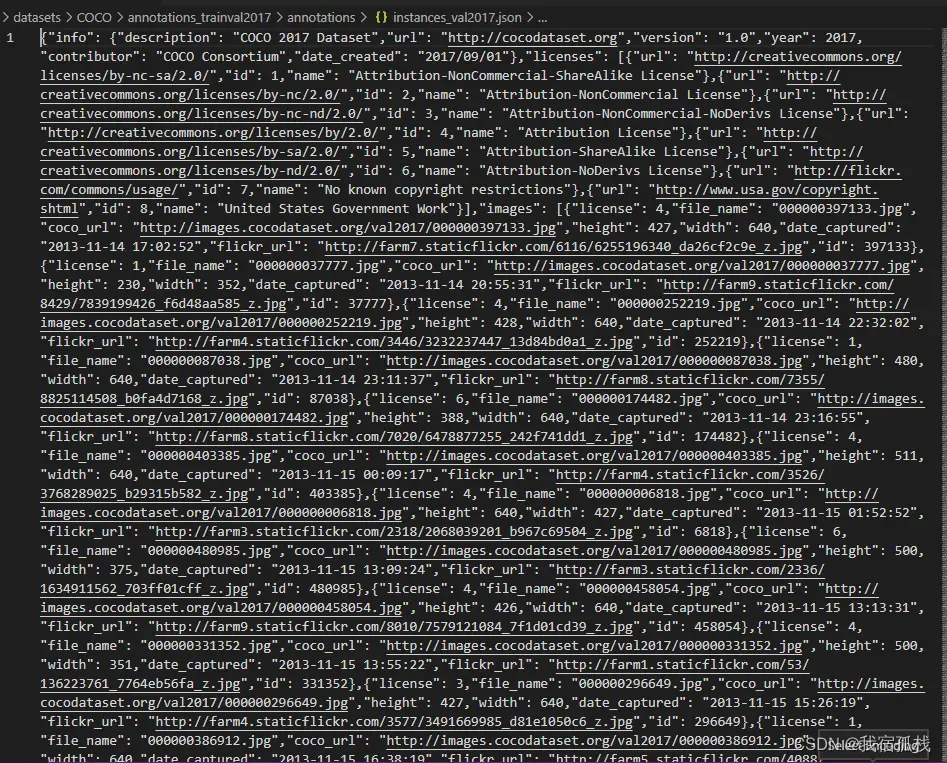
除了上文提到的共享信息外,其还包含annotation和categories:
annotation{ # annotations是一个list,存放所有标注(dict)信息。annotation是一个dict,存放单个目标标注信息。
"id": int, # 目标对象ID(每个对象ID唯一),每张图片可能有多个目标
"image_id": int, # 对应图片ID
"category_id": int, # 对应类别ID,与categories中的ID对应
"segmentation": RLE or [polygon], # 实例分割,对象的边界点坐标[x1,y1,x2,y2,....,xn,yn]
"area": float, # 对象区域面积
"bbox": [xmin,ymin,width,height], # 目标检测,对象定位边框[x,y,w,h]
"iscrowd": 0 or 1, # 表示是否是人群
}
categories{ # 类别描述
"id": int, # 类别对应的ID(0默认为背景)
"name": str, # 子类别名字
"supercategory": str, # 主类别名字
}
完整版:
{
"info": info, # dict
"licenses": [license], # list,内部是dict
"images": [image], # list,内部是dict
"annotations": [annotation],# list,内部是dict
"categories": [category] # list,内部是dict
}
info{ # 数据集信息描述
"year": int, # 数据集年份
"version": str, # 数据集版本
"description": str, # 数据集描述
"contributor": str, # 数据集提供者
"url": str, # 数据集下载链接
"date_created": datetime, # 数据集创建日期
}
license{
"id": int,
"name": str,
"url": str,
}
images{ # images是一个list,存放所有图片(dict)信息。image是一个dict,存放单张图片信息
"id": int, # 图片的ID编号(每张图片ID唯一)
"width": int, # 图片宽
"height": int, # 图片高
"file_name": str, # 图片名字
"license": int, # 协议
"flickr_url": str, # flickr链接地址
"coco_url": str, # 网络连接地址
"date_captured": datetime, # 数据集获取日期
}
annotation{ # annotations是一个list,存放所有标注(dict)信息。annotation是一个dict,存放单个目标标注信息。
"id": int, # 目标对象ID(每个对象ID唯一),每张图片可能有多个目标
"image_id": int, # 对应图片ID
"category_id": int, # 对应类别ID,与categories中的ID对应
"segmentation": RLE or [polygon], # 实例分割,对象的边界点坐标[x1,y1,x2,y2,....,xn,yn]
"area": float, # 对象区域面积
"bbox": [xmin,ymin,width,height], # 目标检测,对象定位边框[x,y,w,h]
"iscrowd": 0 or 1, # 表示是否是人群
}
categories{ # 类别描述
"id": int, # 类别对应的ID(0默认为背景)
"name": str, # 子类别名字
"supercategory": str, # 主类别名字
}
"bbox"::框坐标是从图像左上角测量的浮点数(并且是0索引的)。官方建议将坐标舍入到最接近十分之一像素的位置,以减少JSON文件的大小。
在目标检测时主要用到以下三个部分信息:images、annotations、categories这三部分的信息,分别对应图片信息、检测目标的位置信息、检测目标的分类信息,其中:
images:为序列表,序列表包含多个元素,每个元素对应数据集的一张图片。因此序列表的元素个数与数据集的图片个数一致。
annotations:也为序列表,序列表包含多个元素,每个元素对应数据集的一个检测目标,该检测目标根据image_id对应到images部分的id,使检测目标与图片关联起来,同时根据category_id对应到categories部分的id,使检测目标与类别信息关联起来。因此序列表的元素个数与数据集图片中包含的所有检测目标个数一致。
categories:同样为序列表,序列表包含多个元素,每个元素则对一个类别。因此序列表的元素个数与所有检测目标的类别数(80个类别)一致。
1.3 数据集自制
1.3.1 数据集目录层级制作
如下制作一个COCO2017的数据集:
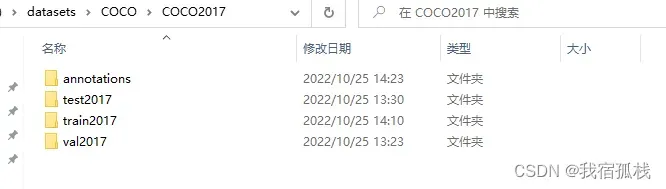
annotations对应文件夹,其包含train、val和test的json标注文件:
注意:上述例子test相关非必须。
1.3.2 标注图片(如labelImg工具)
此处同理VOC数据集。此处以标注工具labelImg为例,具体标注方法网上有很多教程,大家自行选择。
标注完成后将标注文件json保存到Annotations文件夹中。
1.2.3 相关脚本代码
COCO数据集官方提供了COCO API用于更加方便地解析标注文件,在使用之前通过pip install pycocotools安装依赖或通过pip install git+https://github.com/cocodataset/cocoapi.git进行安装。可直接查看该COCOAPI的官方文档。在使用各API前,我们需要实例化COCO类,它接受的参数为标注文件的路径,返回类的对象。COCO中的核心单元是anno。
使用COCO时,首先需要初始化COCO类,
.__init__(self, annotation_file=None):读取val2017.json文件并解析到类中的dataset对象中去,然后.createIndex()。这里的.createIndex()步骤非常关键;
.createIndex():会在初始化的时候,为COCO类创建了5个对象非常重要的对象:
上面的初始化之后,就可以调用以下api:
.info(self):打印数据集的一些基础信息;
decodeMask:通过运行长度解码二进制掩码M进行解码;
encodeMask:使用运行长度编码对二进制掩码M进行编码;
.getAnnIds(self, imgIds=[], catIds=[], areaRng=[], iscrow=None):根据一条标注信息对应的image_id、cat_id、area_range、iscrowd来获得对应的id,这里iscrowd对应segmentation的格式
.getCatIds():获得满足给定过滤条件的category的id;
.getImgIds():得到满足给定过滤条件的imgage的id;
.loadAnns(self, ids=[]):使用指定的id加载annotation;
.loadCats(self, ids=[]):使用指定的id加载category;
.loadImgs(self, ids=[]):使用指定的id加载imgage;
annToMask:将注释中的segmentation转换为二进制mask;
loadRes(self, resFile):是我们最常用的也是最重要的方法。它做了以下工作:
1)初始化另一个COCO类DT(以下用DT指代检测类),用于存储检测数据;
2)将GT的所有image赋给DT,也就是DT所有的image和GT是完全一样的;
3)读取由我们自己生成的结果.json文件,并且判断结果.json文件必须是完全被GT的image包含的;
4)依次为DT类生成caption、bbox、segmention、keypoints,并且,重写DT类里所有anno的id,也就是不管我们有没有在我们的结果文件里生成id,它都会在这里重写这些id以保证id的唯一性;
5)返回需要的DT;
download:从mscoco.org服务器下载COCO图像。
具体使用可参见COCOapi使用示例
文章出处登录后可见!