note
- instructGPT(基于提示学习的系列模型)——>GPT3.5(大规模预训练语言模型)——>ChatGPT模型(高质量数据标注+反馈学习)。chatGPT三大技术:情景学习、思维链、自然指令学习。
- GPT4飞跃式提升:多模态、输入字符数量、推理能力、文本创造,如poem、解释图片含义、图表计算等,2022年8月完成训练。
- 论文:https://cdn.openai.com/papers/gpt-4.pdf
- ChatGPT Plus:集成GPT-4的ChatGPT升级版,https://chat.openai.com/chat
- 可以利用chatGPT获取更高质量数据
- GPT的训练数据可能不够新,所以给出的答案时效性会不够。GPT的使用注意事项:
- 提示词要清晰、聚焦、内容相关,如问“如何进行时间管理”是合理的问题,“我今天好累,怎么办”就不太合理
- 持续调教
- 角色扮演:如问题一开头,说“你是一名教育工作者/心理咨询师等,请从。。角度回答”
- 创作:如短视频、写作等
- 合格的prompt:时间、地点、人物、背景、目标、任务
文章目录
- note
- 一、预训练模型LLM
- 二、GPT三大技术
- 2.1 情景学习
- 2.2 思维链
- 2.3 自然指令学习
- 三、ChatGLM-6B对话模型
- 四、`duckduckgo_search`+gpt解决实时性问题
- 五、ChatGPT的应用
- 5.1 使用上的注意事项
- 5.2 科研上的应用
- 5.3 其他应用
- 六、prompt的案例
- 七、其他LLM
- Reference
一、预训练模型LLM
先从熟悉的huggingface使用讲起:
import numpy as np
from datasets import load_dataset, load_metric
from transformers import BertTokenizerFast, BertForTokenClassification, TrainingArguments, Trainer, DataCollatorForTokenClassification
import torch
# 加载CoNLL-2003数据集、分词器
dataset = load_dataset('conll2003')
tokenizer = BertTokenizerFast.from_pretrained('bert-base-cased')
# 将训练集转换为可训练的特征形式
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)
labels = []
for i, label in enumerate(examples["ner_tags"]):
word_ids = tokenized_inputs.word_ids(batch_index=i)
previous_word_idx = None
label_ids = []
for word_idx in word_ids:
# 将特殊符号的标签设置为-100,以便在计算损失函数时自动忽略
if word_idx is None:
label_ids.append(-100)
# 把标签设置到每个词的第一个token上
elif word_idx != previous_word_idx:
label_ids.append(label[word_idx])
# 对于每个词的其他token也设置为当前标签
else:
label_ids.append(label[word_idx])
previous_word_idx = word_idx
labels.append(label_ids)
tokenized_inputs["labels"] = labels
# DatasetDict类型
return tokenized_inputs
tokenized_datasets = dataset.map(tokenize_and_align_labels, batched=True, load_from_cache_file=False)
# 获取标签列表,并加载预训练模型
label_list = dataset["train"].features["ner_tags"].feature.names
model = BertForTokenClassification.from_pretrained('bert-base-cased', num_labels=len(label_list))
# 定义data_collator,并使用seqeval进行评价
data_collator = DataCollatorForTokenClassification(tokenizer)
metric = load_metric("seqeval")
# 定义评价指标
def compute_metrics(p):
predictions, labels = p
predictions = np.argmax(predictions, axis=2)
# 移除需要忽略的下标(之前记为-100)
true_predictions = [
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
true_labels = [
[label_list[l] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
results = metric.compute(predictions=true_predictions, references=true_labels)
return {
"precision": results["overall_precision"],
"recall": results["overall_recall"],
"f1": results["overall_f1"],
"accuracy": results["overall_accuracy"],
}
# 定义训练参数TrainingArguments和Trainer
args = TrainingArguments(
"ft-conll2003", # 输出路径,存放检查点和其他输出文件
evaluation_strategy="epoch", # 定义每轮结束后进行评价
learning_rate=2e-5, # 定义初始学习率
per_device_train_batch_size=16, # 定义训练批次大小
per_device_eval_batch_size=16, # 定义测试批次大小
num_train_epochs=3, # 定义训练轮数
)
trainer = Trainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
# 开始训练!(主流GPU上耗时约几分钟)
trainer.train()
model_path = "./ner_model.pkl"
# torch.save(model.state_dict(), model_path)
torch.save(model, model_path)
二、GPT三大技术
2.1 情景学习
情景学习(In-context learning)
改变了之前需要把大模型用到下游任务的范式。对于一些 LLM 没有见过的新任务,只需要设计一些任务的语言描述,并给出几个任务实例,作为模型的输入,即可让模型从给定的情景中学习新任务并给出满意的回答结果。这种训练方式能够有效提升模型小样本学习的能力。
2.2 思维链
思维链(Chain-of-Thought,CoT)
对于一些逻辑较为复杂的问题,直接向大规模语言模型提问可能会得到不准确的回答,但是如果以提示的方式在输入中给出有逻辑的解题步骤的示例后再提出问题,大模型就能给出正确题解。也就是说将复杂问题拆解为多个子问题解决再从中抽取答案,就可以得到正确的答案。
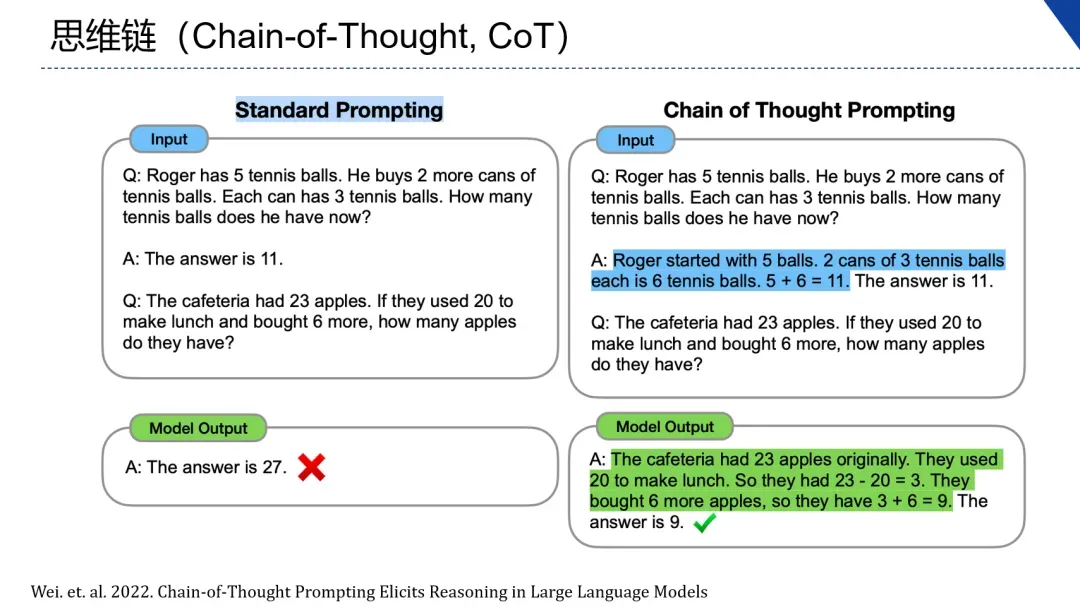
2.3 自然指令学习
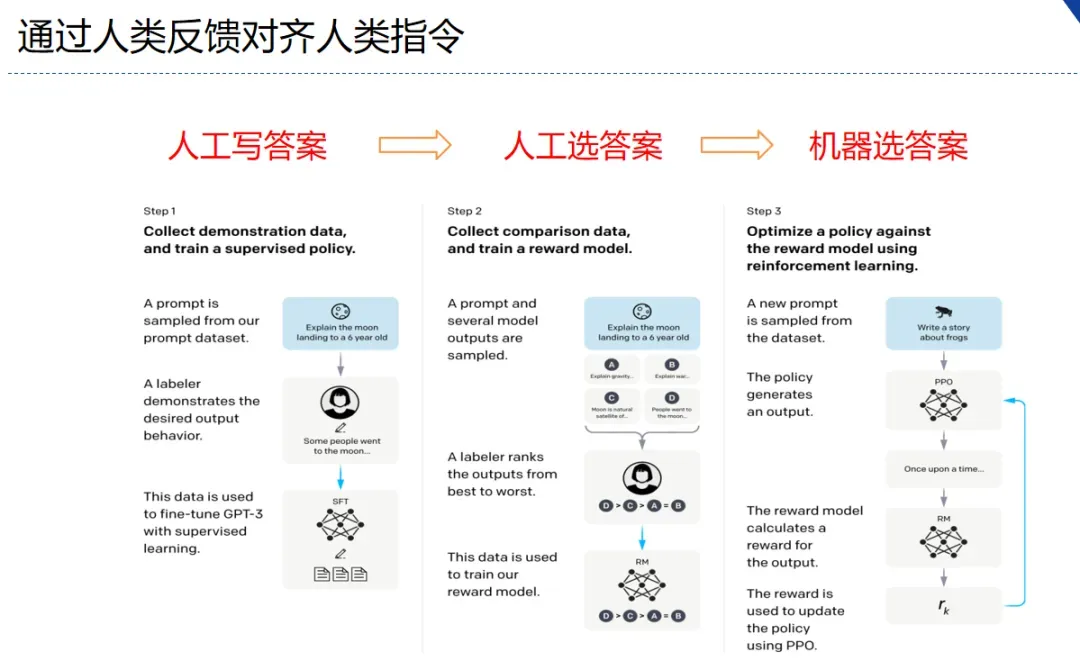
自然指令学习(Learning from Natural Instructions)
openAI使用了instruct GPT的逻辑,强化学习的人类反馈。
三、ChatGLM-6B对话模型
- ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
- ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
- 为了方便下游开发者针对自己的应用场景定制模型,可以基于 P-Tuning v2 的高效参数微调方法 (使用指南) ,INT4 量化级别下最低只需 7GB 显存即可启动微调。
- 由于 ChatGLM-6B 的规模较小,目前已知其具有相当多的局限性,如事实性/数学逻辑错误,可能生成有害/有偏见内容,较弱的上下文能力,自我认知混乱,以及对英文指示生成与中文指示完全矛盾的内容。请大家在使用前了解这些问题,以免产生误解。更大的基于 1300 亿参数 GLM-130B 的 ChatGLM 正在内测开发中。
- 官方博客:https://chatglm.cn/blog; 官方:https://github.com/THUDM/ChatGLM-6B
- 注意:下载预训练模型可以即时下载(如下),或者直接在huggingface上下载到当前文件夹里面,创建一个
model文件夹,里面放着这坨内容即可,可以直接命令git clone https://huggingface.co/THUDM/chatglm-6b然后修改这个文件名为model。如果是前者,默认是保存到.cache文件夹里面,另外可以参考如何优雅的下载huggingface-transformers模型。
```python
from huggingface_hub import snapshot_download
snapshot_download(repo_id="THUDM/chatglm-6b")
上面提到的git方法时可以使用LFS,即Large File Storage。在使用git lfs track命令后,git push的时候,git lfs会截取要管理的大文件,并将其传至git lfs的服务器中,从而减小仓库的体积
yum install git-lfs
# Make sure you have git-lfs installed
# (https://git-lfs.github.com/)
git lfs install
或者直接像以前一样的方法:
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModelForMaskedLM.from_pretrained("bert-base-uncased")
四、duckduckgo_search+gpt解决实时性问题
DuckDuckGo是一个互联网搜寻引擎,DuckDuckGo强调在传统搜寻引擎的基础上引入各大Web 2.0站点 的内容。其办站哲学主张维护使用者的隐私权,并承诺不监控、不记录使用者的搜寻内容,其提供ddg_suggestions直接获取词语联想、ddg_translate直接中英翻译、duckduckgo_search直接搜索网页、ddg_news直接搜索新闻等多个功能。
地址:https://github.com/deedy5/duckduckgo_search
from duckduckgo_search import ddg_suggestions
from duckduckgo_search import ddg_translate, ddg, ddg_news
ddg_suggestions("马克龙")
# 1. 直接获取词条
print("suggetstion test:\n", ddg_suggestions("马克龙"), "\n")
'''
suggetstion test:
[{'phrase': '马克龙竞选拍照钱想报销被拒'}, {'phrase': '马克龙希望德尚继续执教国家队'}, {'phrase': '马克龙被兴奋庆祝的球员晾在一边'}, {'phrase': '马克龙将在g20峰会后致电普京'}, {'phrase': '马克龙晒姆巴佩吉鲁比赛照'}, {'phrase': '马克龙访华'}, {'phrase': '马克龙支持将堕胎权写入法国宪法'}, {'phrase': '马克龙妻子'}]
'''
# 2. translate
print("translate test: \n", ddg_translate("中国有多少人口", to = "en"))
'''
translate test:
[{'detected_language': 'zh-Hans', 'translated': 'How much population is China', 'original': '中国有多少人口'}]
'''
# 3. search page
r = ddg("马克龙、冯德莱恩访华", max_results=5)
for page in r:
print("page test:\n", page, "\n")
# 4. search news
print("news test:\n", ddg_news("张继科事件", safesearch='Off', time='d', max_results=5))
'''
news test:
[{'date': '2023-04-15T05:17:00', 'title': '张继科床照事件引发严重质疑,体育明星该如何保持高尚品德和行为', 'body': '近日,一则关于中国乒乓球运动员张继科的床照事件在互联网上引起了轩然大波。这些照片中,张继科被拍到在床上与一名女子拥抱,并且照片中的氛围颇显暧昧,引发了一场轩然大波。 这一事件让人对张继科的品德产生了严重的质疑,让我们不得不重新审视这位曾经被誉为乒乓球界的偶像的行为。 作为一名公众人物,张继科在社会舞台上担负着很大的社会责任。作为中国乒乓球队的一员,他不仅代表了国家和民族的形象,更是年轻一代的榜样。', 'url': 'https://www.163.com/dy/article/I2C9TJ3B05562MYS.html', 'image': None, 'source': '网易'}, {'date': '2023-04-15T02:11:00', 'title': '张继科事件再传!小时候在网上睡觉可不是那么容易被曝光的', 'body': 'Jike被曝欠债,散播前女友景甜的私密视频,惹来不小的风波。而他本人,也从光鲜亮丽的奥运冠军,摇身一变成为红极一时的"绝情男"。 后来,张继科和皮友良之前就谈过恋爱,这个消息更是让大家震惊。两个人在日常生活中可以说是完全格格不入,甚至都没有过交集。张继科和皮友良也是个人。它是如何走到一起的?不少网友对此提出质疑,认为这只是一种宣传手段,或者说反派是想通过这种方式来拉高自己的知名度。毕竟反派是网红,', 'url': 'https://www.163.com/dy/article/I2BVA6FT05561UMW.html', 'image': None, 'source': '网易'}, {'date': '2023-04-14T17:43:00', 'title': '狗仔曝张继科事件内幕又添新料', 'body': '张继科居住在上海,拥有豪车和高端房产,生活非常奢华。他还玩高尔夫等高端运动,与一些有不良嗜好的朋友交往。在不久前的一些八卦事件中,张继科被指控赌博借钱不还、传播女明星的私密照片等问题。 狗仔还提到张继科和现女友张蕊已经生子,但没有领证,女方很有家底,是个富家千金。狗仔最后还说张继科还曾发过别的女性的私密照。大家认为这个消息是真的吗? 一个人的品德和行为应该是我们选择朋友或伴侣时所关注的首要因素。我', 'url': 'https://new.qq.com/rain/a/20230413A07U8900', 'image': 'https://inews.gtimg.com/om_bt/O7URdZTcE5XJkEV8u4TwAYUcN9khc9uj3FHwyHYpyKETYAA/1000', 'source': '腾讯网'}, {'date': '2023-04-14T11:54:00', 'title': '张继科事件持续发酵!欠债多达1700万,现女友被扒:离过婚生了娃', 'body': '最近一段时间,体坛热度最高的事情,毫无疑问是关于张继科的。这位国乒大满贯得主,目前已经成为众矢之的,而且丑闻仍在持续发酵。最关键的是,现在连娱乐圈也开始扒张继科的猛料了,接下来估计有更多的内幕会被曝光。 众所周知,娱乐圈中有一位"百科全书"式的人物,他有非常多的人脉和资源,因此每次有大事发生之时,吃瓜群众都在等着他发声。没错,这个人就是狗仔卓伟。 近日,卓伟曝光了关于张继科事件的一些后续。他表示,', 'url': 'https://new.qq.com/rain/a/20230414A086WS00', 'image': 'https://inews.gtimg.com/news_bt/ODLPndHCDP435bA9AD5gf85NWhttes0rhCXFFUIl376W8AA/1000', 'source': '腾讯网'}, {'date': '2023-04-14T10:43:00', 'title': '张继科"债主"名单曝光!欠债1.9亿,孙颖莎、陈梦都借给过他钱', 'body': '4月14日,时隔数日,前中国乒乓球运动员、奥运冠军张继科再次登上热搜,成为国内媒体、球迷关注的焦点!日前,娱乐圈第一狗仔卓伟重出江湖,曝出更多关于张继科的猛料、细节,情节远比大家想象中的要恶劣。据卓伟爆料称,张继科将某女明星的隐私视频、照片给债主抵债确有其事。此外,卓伟还在爆料中提到,曾在2020年1月,他接到过一个来自境外的电话,电话那头的人想请他帮忙向景甜要钱。 据电话那头的人透露,张继科因*', 'url': 'https://www.sohu.com/a/666759410_120875314', 'image': 'https://p3.itc.cn/images01/20230414/4d10b6a3d4194ba4bd2c61323b3a9dfe.jpeg', 'source': '搜狐'}]
'''
一个思路:将duckduckgo_search实时结果接入GLM6B进行内容生成。其中GLM6B服务使用flask搭建。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import os
import json
from flask import Flask, request
from transformers import AutoModel, AutoTokenizer
os.environ["CUDA_VISIBLE_DEVICES"] = "3"
tokenizer = AutoTokenizer.from_pretrained(r"chatglm-6b", trust_remote_code=True,
revision="main")
model = AutoModel.from_pretrained(r"chatglm-6b", trust_remote_code=True,
revision="main").half().quantize(4).cuda()
model = model.cuda()
model = model.eval()
app = Flask(import_name=__name__)
def predict(input_string, history):
if history is None:
history = []
try:
response, history = model.chat(tokenizer, input_string, history)
return {"msg": "success", "code": 200, "response": response}
except Exception as error:
return {"msg": "error", "code": 500, "response": error}
@app.route("/chat_with_history", methods=["POST", "GET"])
def chat_with_history():
data = json.loads(request.data)
input_text = data['input_text']
history = data.get("history", None)
if history is not None:
history = json.loads(history)
return predict(input_text, history)
if __name__ == '__main__':
app.run(port=12345, debug=True, host='0.0.0.0') # 如果是0.0.0.0,则可以被外网访问
五、ChatGPT的应用
5.1 使用上的注意事项
- 提示词要清晰、聚焦、内容相关,如问“如何进行时间管理”是合理的问题,“我今天好累,怎么办”就不太合理
- 持续调教
- 角色扮演:如问题一开头,说“你是一名教育工作者/心理咨询师等,请从。。角度回答”
- 创作:如短视频、写作等



- 素材查找:帮我找一个案例,最好是2020年后的XX相关案例
- 语言润色
- 文案or脚本:提示词:你是一个文案大师,你现在需要撰写xxx的宣传文案,面向用户的特点是:xxx,文案的要求是:xxx。请写出10个xxx的宣传文案。
- 文本生成AI提示词高阶玩法
- Instruction(必须): 指令,即你希望模型执行的具体任务。
- Context(选填): 背景信息,或者说是上下文信息,这可以引导模型做出更好的反应。
- Input Data(选填): 输入数据,告知模型需要处理的数据。
- Output Indicator(选填): 输出指示器,告知模型我们要输出的类型或格式。

5.2 科研上的应用
- 数据分析,如画图、解释复杂的数据关系
- 实验
- latex源码:如公式、表格等
- 数据收集
- 嵌套模型创新

5.3 其他应用
- ChatGPT + PDF(ChatDOC):https://chatdoc.com/chatdoc/ ;导入pdf文档后可以对其进行提问
- ChatGPT + Excel:可以让ChatGPT写VBA,然后嵌入到Excel中运行
- ChatGPT 生成思维导图:让ChatGPT 生成某本书/某篇文档的思维导图,
- 1)给chatgpt下指令说用markdown格式输出某一主题的内容
- 2)内容到你满意后,复制到txt里,再把txt的扩展名该成md
- 3)打开xmind,随便新建一个导图,点击文件—导入markdown格式,选择刚才保存的txt即可
- 导出ChatGPT对话记录的插件:ChatGPT to Markdown / ChatGPT Save Data
- google chrome上一些能提高生产效率的插件:
- SciSpace Copilot
- Compose AI
- Wiseone
- UseChatGPT AI
- Merlin
六、prompt的案例
- 合格的prompt:时间、地点、人物、背景、目标、任务
- 案例一:导游

- 案例二:辅助工作

- 案例三:辅助编程任务


- 案例四:辅助学习英语
Q: 请对以下这段英语的语法结构分析,并以表格形式给出,并给出重点标注:...
A: 如下表格:
以下是对该段英语的语法结构的分析,并以表格形式给出,每个表格为一个句子:
| 句子 | 主语 | 谓语 | 宾语 | 宾语补语 | 介词短语 |
|---|---|---|---|---|---|
| Who would have thought that, globally, the IT industry produces about the same volume of greenhouse gases as the world’s airlines do – roughly 2 percent of all CO2 emissions? | IT industry | produces | about the same volume of greenhouse gases as the world’s airlines do – roughly 2 percent of all CO2 emissions | – | who, globally |
| Many everyday tasks take a surprising toll on the environment. | Many everyday tasks | take | a surprising toll on the environment | – | – |
| A Google search can leak between 0.2 and 7.0 grams of CO2, depending on how many attempts are needed to get the “right” answer. | A Google search | can leak | between 0.2 and 7.0 grams of CO2 | depending on how many attempts are needed to get the “right” answer | – |
| To deliver results to its users quickly, then, Google has to maintain vast data centres around the world, packed with powerful computers. | has to maintain | vast data centres around the world, packed with powerful computers | to deliver results to its users quickly | – | |
| While producing large quantities of CO2, these computers emit a great deal of heat, so the centres need to be well air-conditioned, which uses even more energy. | these computers | emit | a great deal of heat | – | while producing large quantities of CO2; so the centres need to be well air-conditioned, which uses even more energy |
| However, Google and other big tech providers monitor their efficiency closely and make improvements. | Google and other big tech providers | monitor | their efficiency closely and make improvements | – | however |
| Monitoring is the first step on the road to reduction, but there is much more to be done, and not just by big companies. | Monitoring | is | the first step on the road to reduction | – | but there is much more to be done, and not just by big companies |
重点标注:
- 第一句话中,疑问词“who”引导的从句为插入语,用逗号与主句隔开。
- 第三句话中,“depending on how many attempts are needed to get the ‘right’ answer”为非限定性定语从句,用逗号与主句隔开。
- 第四句话中,“to deliver results to its users quickly”为不定式短语,作目的状语。
- 第五句话中,“while producing large quantities of CO2”和“which uses even more energy”为两个非限定性定语从句,用分号隔开。
- 第六句话中,“however”为转折连词,表示与前面的内容相反。
- 第七句话中,“but there is much more to be done, and not just by big companies”为并列句,用逗号隔开。
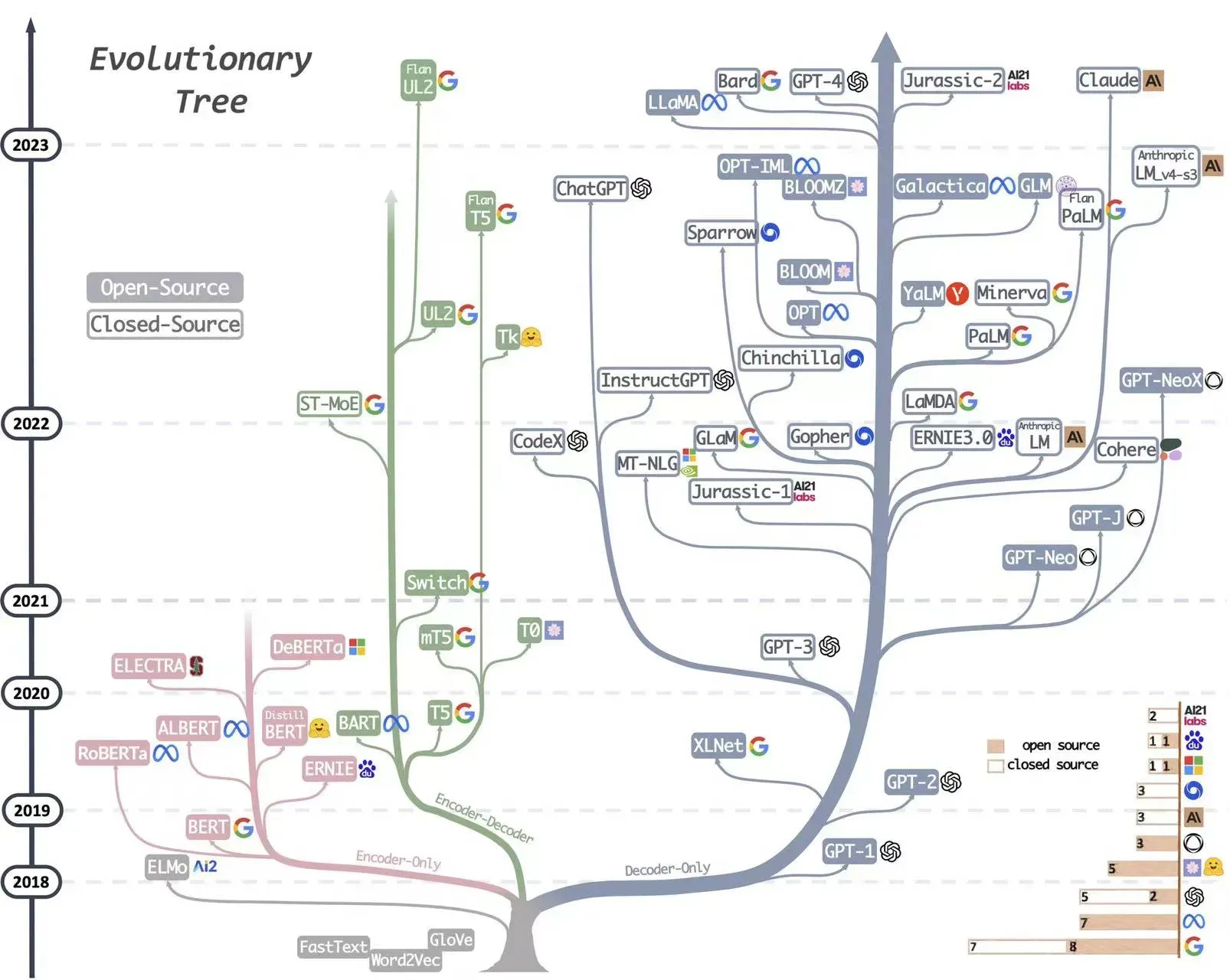
七、其他LLM
Reference
[1] ChatPaper:一款论文总结工具,根据用户输入的关键词,自动在arxiv上下载最新的论文,再利用ChatGPT3.5的API接口的总结能力:ChatPaper – Use ChatGPT to summary the Arxiv papers.’ kaixindelele GitHub: github.com/kaixindelele/ChatPaper
[2] ClassGPT:上传教材/讲义/参考资料基于 OpenAI ChatGPT API 交互式生成报告用 PPT:github.com/benthecoder/ClassGPT
[3] 哈工大: ChatGPT调研报告
[4] A Comprehensive Survey of AI-Generated Content (AIGC):
A History of Generative AI from GAN to ChatGPT
[5] 人工智能觉醒序章:Prompt工程
[6] GPT-4 Technical Report. OpenAI
[7] 为什么现在的大语言模型(LLM)都是Decoder-only的架构. 苏神
[8] 复旦邱锡鹏:深度剖析 ChatGPT 类大语言模型的关键技术
[9] Awesome Pretrained Chinese NLP Models
[10] 张俊林:由ChatGPT反思大语言模型(LLM)的技术精要
[11] 学术论文使用GPT:https://github.com/kaixindelele/chatpaper
[12] https://huggingface.co/Helsinki-NLP/opus-mt-en-ro
[13] https://github.com/adapter-hub/adapter-transformers/tree/master/examples/pytorch
[14] 机器翻译:https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation.ipynb
[15] HuggingFace学习3:加载预训练模型完成机器翻译(中译英)任务
[16] https://chat.plexpt.com/
[17] 清华大学开源中文版ChatGPT模型-ChatGLM-6B发布
[18] 李沐动手学dl:自然语言推断:微调BERT
[19] 微软推出HuggingGPT:所有HuggingFace的模型都可以被ChatGPT随意调用
[20] ChatGLM:小白也可搭建属于自己的chatgpt(全程教学)paddle
[21] 类ChatGPT开源项目的部署与微调:从LLaMA到ChatGLM-6B
[22] https://huggingface.co/THUDM/chatglm-6b/tree/main
[23] 如何解决类ChatGPT生成的时效性问题:基于duckduckgo_search+GLM-6B路线的一个简单实验分析
[24] chatglm官方博客 https://chatglm.cn/blog
[25] 清华 ChatGLM-6B 中文对话模型部署简易教程
[26] 清华ChatGLM-6B单机部署教程
[27] https://github.com/deedy5/duckduckgo_search
[28] GPT 4.0 你知道的和你不知道的.中科院 彭伟
[29] modelscope社区
[30] https://poe.com/
[31] https://web.skype.com/
[32] 如何用ChatGPT画流程图
[33] openai-cookbook:https://github.com/openai/openai-cookbook/tree/main/examples
[34] https://github.com/Significant-Gravitas/Auto-GPT
文章出处登录后可见!