在各处看到关于yolo的魔改都是基于yolov5版本的,于是借鉴学习一下用在yolov7-tiny版本上,做一下学习记录。
1、配置yaml文件
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# yolov7-tiny backbone
backbone:
# [from, number, module, args] c2, k=1, s=1, p=None, g=1, act=True
[ [ -1, 1, conv_bn_hswish, [ 16, 2 ] ], # 0-p1/2
[ -1, 1, MobileNet_Block, [ 16, 16, 3, 2, 1, 0 ] ], # 1-p2/4
[ -1, 1, MobileNet_Block, [ 24, 72, 3, 2, 0, 0 ] ], # 2-p3/8
[ -1, 1, MobileNet_Block, [ 24, 88, 3, 1, 0, 0 ] ], # 3-p3/8
[ -1, 1, MobileNet_Block, [ 40, 96, 5, 2, 1, 1 ] ], # 4-p4/16
[ -1, 1, MobileNet_Block, [ 40, 240, 5, 1, 1, 1 ] ], # 5-p4/16
[ -1, 1, MobileNet_Block, [ 40, 240, 5, 1, 1, 1 ] ], # 6-p4/16
[ -1, 1, MobileNet_Block, [ 48, 120, 5, 1, 1, 1 ] ], # 7-p4/16
[ -1, 1, MobileNet_Block, [ 48, 144, 5, 1, 1, 1 ] ], # 8-p4/16
[ -1, 1, MobileNet_Block, [ 96, 288, 5, 2, 1, 1 ] ], # 9-p5/32
[ -1, 1, MobileNet_Block, [ 96, 576, 5, 1, 1, 1 ] ], # 10-p5/32
[ -1, 1, MobileNet_Block, [ 96, 576, 5, 1, 1, 1 ] ], # 11-p5/32
]
# yolov7-tiny head
head:
[[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, SP, [5]],
[-2, 1, SP, [9]],
[-3, 1, SP, [13]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -7], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 20
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[8, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 30
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[3, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # route backbone P3
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 40
[-1, 1, Conv, [128, 3, 2, None, 1, nn.LeakyReLU(0.1)]],
[[-1, 30], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 48
[-1, 1, Conv, [256, 3, 2, None, 1, nn.LeakyReLU(0.1)]],
[[-1, 20], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 56
[40, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[48, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[56, 1, Conv, [512, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[57,58,59], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]2、配置common.py
把以下代码添加至/models/common.py中即可
#——————MobileNetV3-small——————
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class SELayer(nn.Module):
def __init__(self, channel, reduction=4):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel),
h_sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x)
y = y.view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
class conv_bn_hswish(nn.Module):
def __init__(self, c1, c2, stride):
super(conv_bn_hswish, self).__init__()
self.conv = nn.Conv2d(c1, c2, 3, stride, 1, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = h_swish()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class MobileNet_Block(nn.Module):
def __init__(self, inp, oup, hidden_dim, kernel_size, stride, use_se, use_hs):
super(MobileNet_Block, self).__init__()
assert stride in [1, 2]
self.identity = stride == 1 and inp == oup
if inp == hidden_dim:
self.conv = nn.Sequential(
# dw
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, (kernel_size - 1) // 2, groups=hidden_dim,
bias=False),
nn.BatchNorm2d(hidden_dim),
h_swish() if use_hs else nn.ReLU(inplace=True),
# Squeeze-and-Excite
SELayer(hidden_dim) if use_se else nn.Sequential(),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
else:
self.conv = nn.Sequential(
# pw
nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
h_swish() if use_hs else nn.ReLU(inplace=True),
# dw
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, (kernel_size - 1) // 2, groups=hidden_dim,
bias=False),
nn.BatchNorm2d(hidden_dim),
# Squeeze-and-Excite
SELayer(hidden_dim) if use_se else nn.Sequential(),
h_swish() if use_hs else nn.ReLU(inplace=True),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
y = self.conv(x)
if self.identity:
return x + y
else:
return y
3、去yolo.py中加载添加的类
找到parse_model中最长那一段,加入所添加的h_sigmoid, h_swish,SELayer,conv_bn_hswish, MobileNet_Block模块即可,如图所示
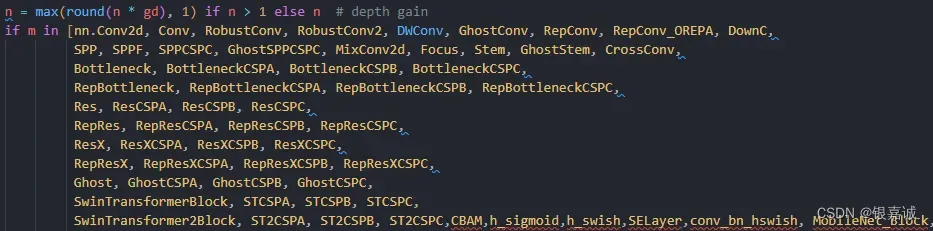
4、训练即可,注意train.py时将cfg文件改成自己的yaml, 如下所示
python train.py --workers 16 --device 0,1,2,3 --batch-size 32 --data data/data.yaml --cfg cfg/training/yolov7-tiny-mb3s.yaml --weights '' --name yolov7-tiny-mb3s --hyp data/hyp.scratch.p5.yaml
参考blog:
(111条消息) 目标检测算法——YOLOv5/YOLOv7改进之结合轻量化网络MobileNetV3(降参提速)_加勒比海带66的博客-CSDN博客_conv_bn_hswish
文章出处登录后可见!
已经登录?立即刷新