1、数据提取
本次教程做适用于整体数据集上的处理工作,以不同的的处理代码展示整体的数据处理!
本次数据处理教程是没有做STFT变换,之间将提取的数据变换为适合2D-CNN输入的数据,以适应使用2D-CNN网络完成具体任务!
文件的目录如下:把所有患者数据文件夹放入一个文件夹中。
1.导入包
import numpy as np
import pandas as pd
import mne
import os
2.定义变量
包括数据目录、发病时间,选择的通道等。
path = "/data_edf/"
path_time_records = "/time_recods.csv"
t = pd.read_csv(path_time_records,index_col="chb")
channel = ['FP1-F7','F7-T7','T7-P7','P7-O1','FP1-F3','F3-C3','C3-P3','P3-O1','FZ-CZ','CZ-PZ','FP2-F4','F4-C4','C4-P4','P4-O2','FP2-F8','F8-T8','P8-O2','T8-P8-1']
dirs = sorted(os.listdir(path))
3.整体数据
for dir in dirs :
count = 0
os.mkdir("you want to save" + "/" + dir)
os.mkdir("you want to save" + "/" + dir)
path_old = "you want to save" + "/" + dir # 原始数据文件夹目录
path_d = "you want to save" + "/" + dir # 新数据文件夹目录
path_l = "you want to save" + "/" + dir # 新标签目录
files = sorted(os.listdir(path_old)) # 得到文件夹下的所有文件名称
# file_name = "X"+ "/" + dir + ".npy"
for file in files: #遍历文件夹
if os.path.splitext(file)[1] == '.seizures':
count+=1
f = os.path.splitext(file)[0]
# print('file name ', file + '\n'+ f)
file_name = os.path.splitext(os.path.splitext(file)[0])[0] + ".npy"
t_str = str(os.path.splitext(os.path.splitext(file)[0])[0])
raw = mne.io.read_raw_edf(path_old+"/" + f,preload=True)
edf = raw.copy().filter(0.2, 30.)
t_idx = edf.time_as_index([t.loc[t_str, 'start'], t.loc[t_str, 'end']])
edf.pick_channels(channel)
x,y = repat_file(edf, t_idx)
np.save(path_d+"/"+file_name, x)
np.save(path_l+"/"+file_name, y)
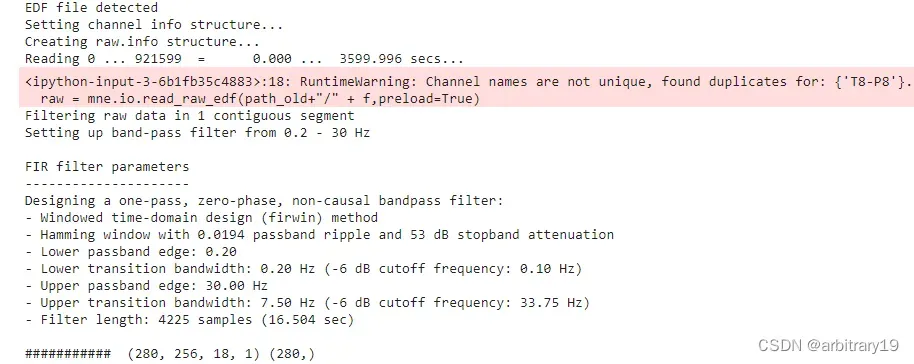
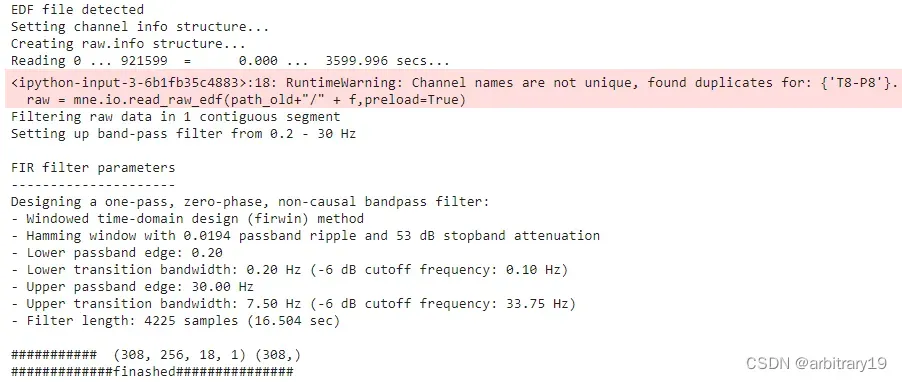
print("#############finashed###############")
2、提取过程
文章出处登录后可见!
已经登录?立即刷新