下文推导的前提:
n:输入序列长度
d:embedding的大小
1.self-attention 时间复杂度

上图为 n×n的矩阵A和 n×n的矩阵B相乘的时间复杂度
同理
n×d的矩阵Q和 d×n的矩阵KT相乘的时间复杂度 为 O(n^2 d)
n×n的矩阵softamx(Q*KT)和 n×d的矩阵V相乘的时间复杂度 为 O(n^2 d)
而softmax(n×n)的时间复杂度为 O(n^2)
所以self-attention最终的时间复杂度为 O(n^2 d)(选最大的)
2.CNN 时间复杂度
有一定的前提条件:要求输入和输出的大小相同 为 n×d
卷积核 kernel 大小为 k×d
则有——需要对输入 n×d 进行padding ,加(k-1)行
同时需要 d 个核

然后一个核的复杂度为 O(kd),n行为 O(nkd),d列为 O(nk d^2)
3.RNN 时间复杂度
其实这个我也不是很清楚,找了一个RNN的计算图
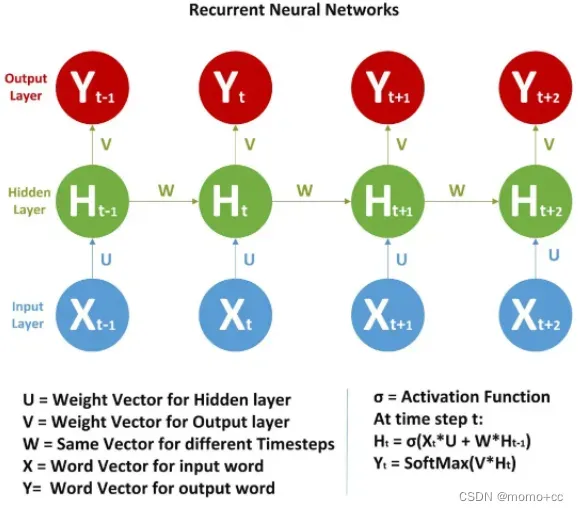
RNN计算公式为
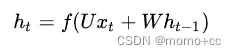
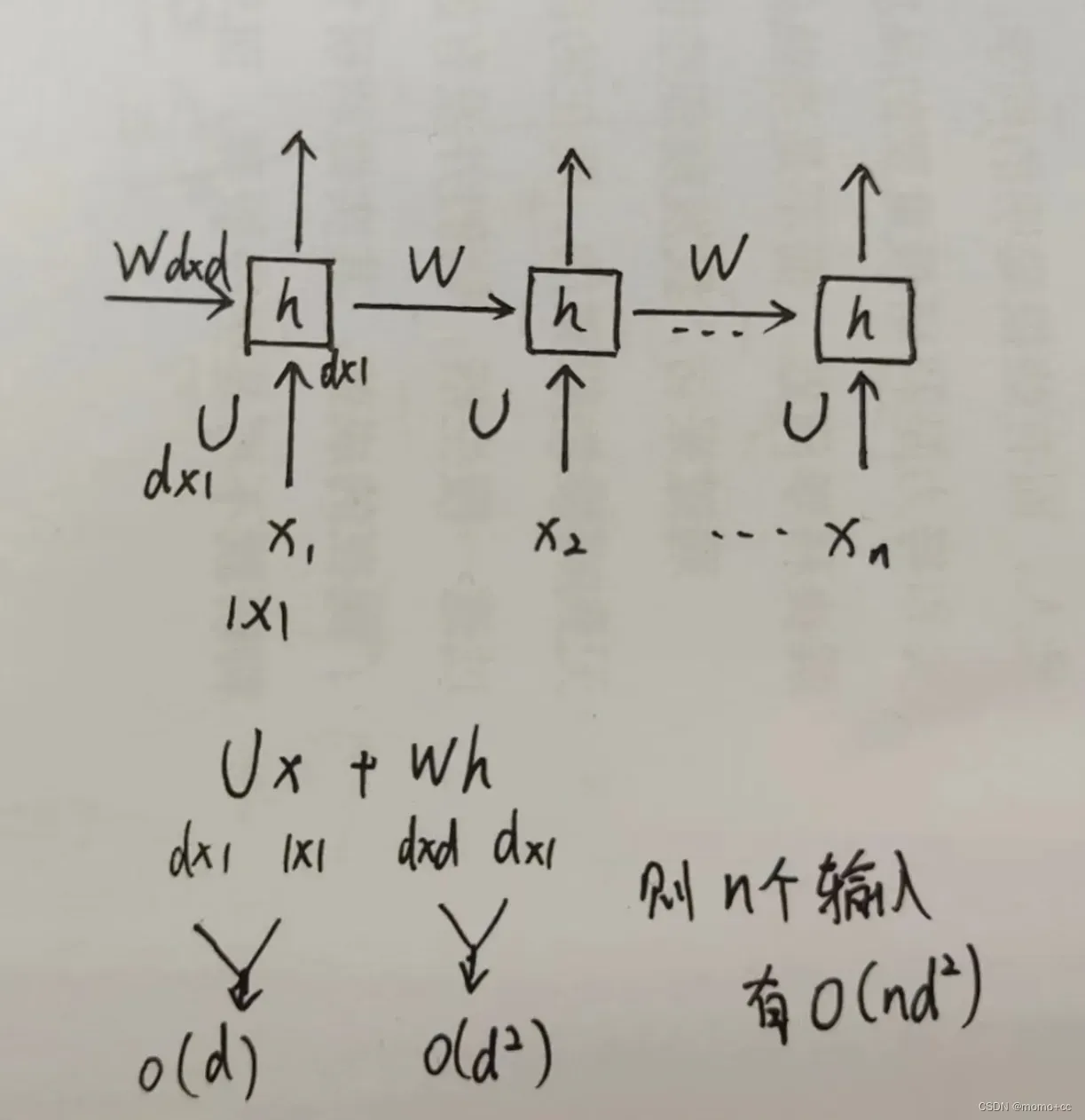
self-attention中计算复杂度大致就是这样了,时间复杂度有时候看不出来的话,还是要写一写,自己感觉还是写成代码比较直观。
文章出处登录后可见!
已经登录?立即刷新