引言
本文是【理论篇】是时候彻底弄懂BERT模型了的姊妹篇。在本文中,我们通过🤗的transformers库来实战使用预训练的BERT模型。
我们主要会实战文本分类中的情绪识别任务和自然语言推理中的问答任务。
注意,文中提到的
嵌入表示、嵌入、嵌入向量、向量表示、表示说的都是同一个东西。
探索预训练的BERT模型
在理论篇中,我们知道了如何使用屏蔽语言建模和下一句预测任务来预训练BERT模型。
但是从开开始预训练BERT模型是很耗资源的,所以我们可以下载预训练好的BERT模型。Google开源了预训练的BERT模型,我们可以从https://github.com/google-research/bert中下载。他们开源了多种配置,如下图所示。代表编码器层数,
代表隐藏单元大小:
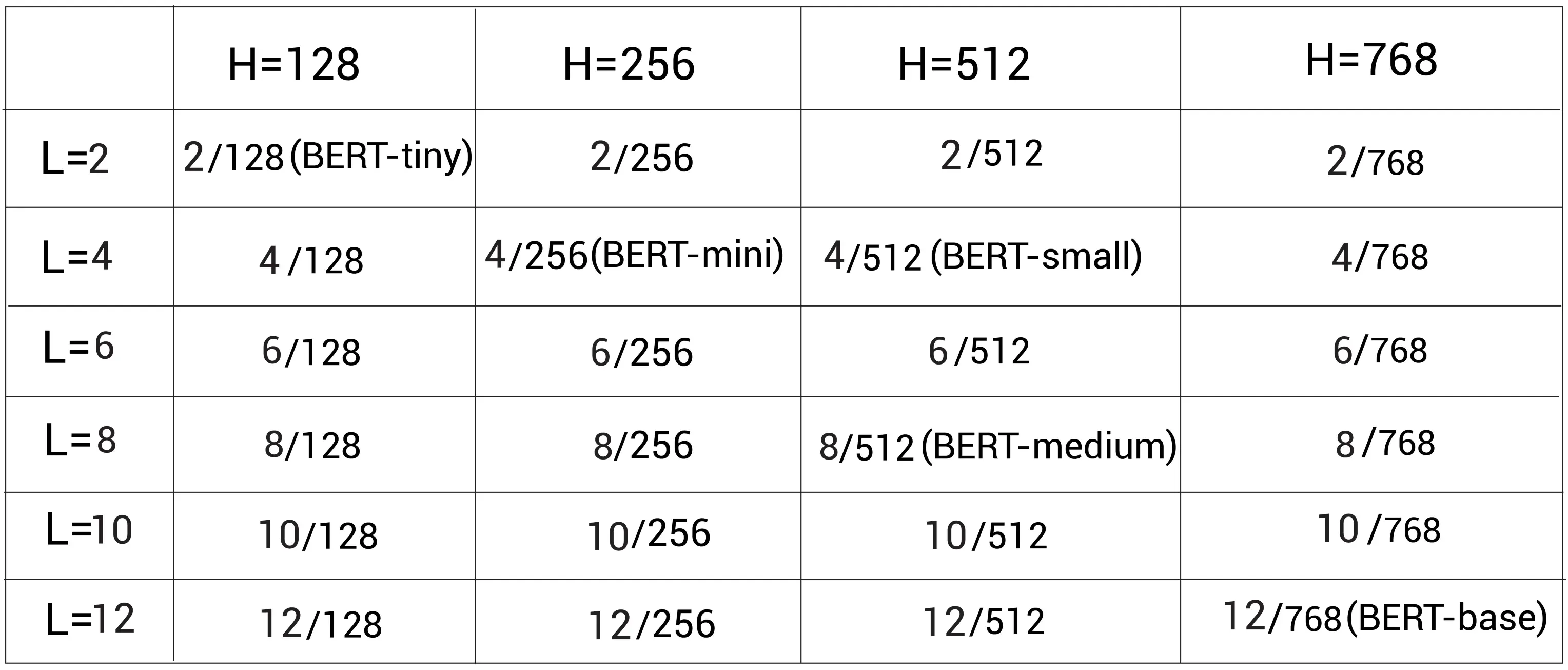
预训练模型也可用于 BERT-uncased 和 BERT-cased 格式。在BERT-uncased中,所有的标记都是小写的,但是在BERT-cased中的标记没有转换为小写,而是直接用来训练。
其中BERT-uncased模型是最常用的,但是如果我们在像命名实体识别任务时,此时我们应该保留大小写,所以我们应该使用BERT-cased模型。除此之外,Google还释放了使用整词屏蔽(whole word masking,WWM)方法预训练的模型。
我们可以以下面两个方式使用预训练模型:
- 作为抽取嵌入表示的特征抽取器
- 通过在下游任务像文本分类、问答等任务的微调预训练的BERT模型
在后文中我们会学习这两种方式是如何使用的。
从预训练的BERT中抽取嵌入表示
我们通过一个实例来理解。考虑一个句子 I love Paris,假设我们要抽取该句子中的每个标记的上下文嵌入。首先,我们对句子分词然后喂给预训练的BERT模型,它会返回每个标记的嵌入表示。除了可以获取标记级(单词级)的嵌入表示,我们还可以获取句子级的表示。
在本节中,我们来学习具体如何从预训练的BERT模型中抽取单词级和句子级的嵌入表示。
假设我们想要完成一个情感分析任务,然后我们有下面的数据集:
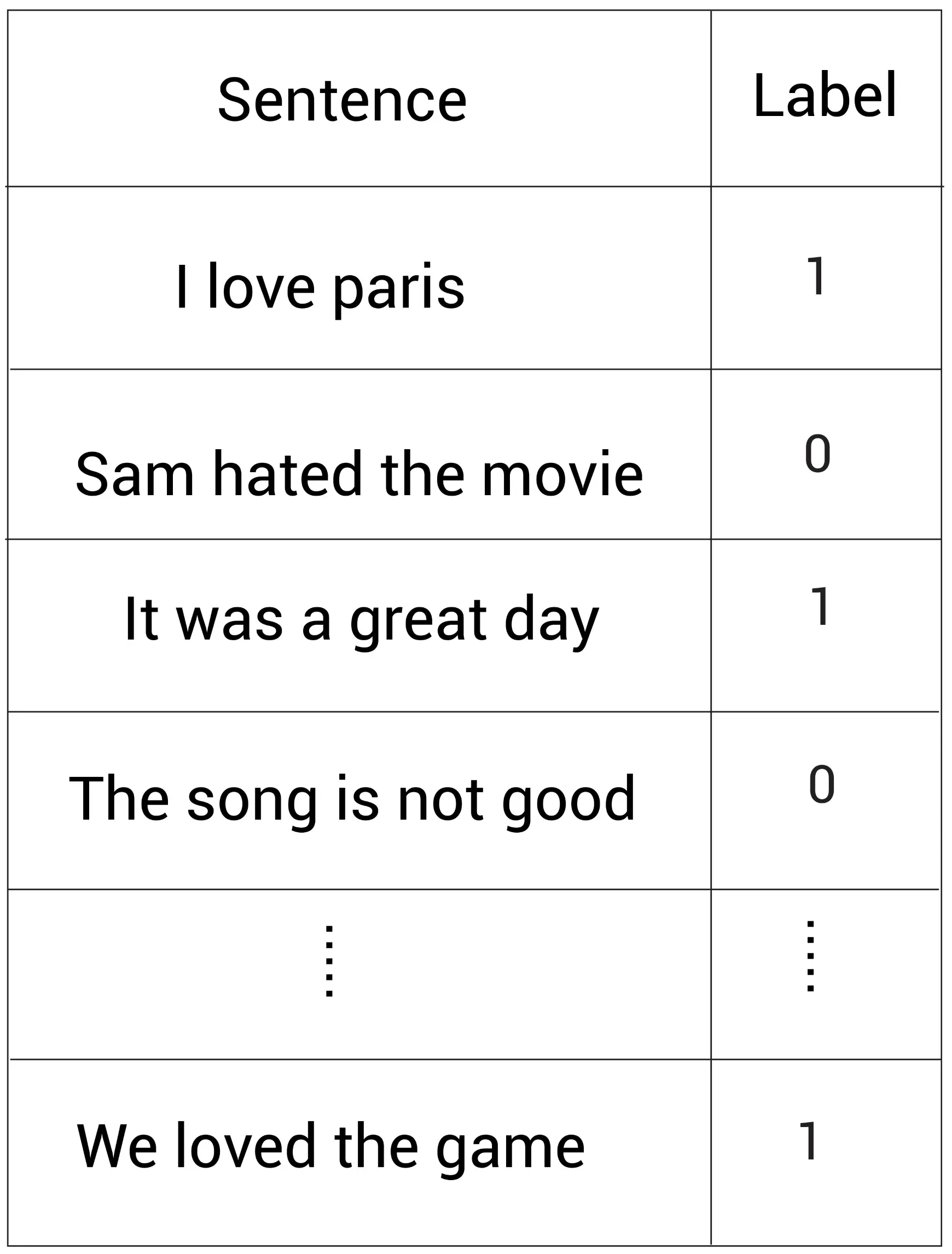
我们有句子以及对应的标签,其中代表正向情感而
代表负向情感。我们可以使用给定的数据集训练一个分类器来分类句子的情感。
首先,我们需要对数据集中的文本进行向量化。我们可以使用诸如TF-IDF、word2vec等方法进行向量化。但既然我们已经知道BERT可以学到单词的上下文嵌入表示,我们何不直接使用预训练的BERT模型去向量化数据集中的句子呢?
考虑我们数据集中第一个句子:I love Paris。首先,我们通过WordPiece分词器进行分词并得到分词后的单词(标记):
tokens = [I, love, Paris]
然后增加[CLS]和SEP标记:
tokens = [ [CLS], I, love, Paris, [SEP] ]
类似的,我们就可以对训练集中的所有句子进行同样的操作。但是每个句子的长度是不固定的。所以我们需要保证所有的单词列表长度是一致的。假设我们保持数据集中的句子长度为。如果我们查看上面的单词列表,它的长度为
。为了满足长度为
的要求,我们需要增加一个新的填充标记叫
[PAD],这样我们得到的单词列表如下:
tokens = [ [CLS], I, love, Paris, [SEP], [PAD], [PAD] ]
这样我们的单词列表长度就变成了。下一步就是让我们的模型理解
[PAD]标记是用于填充而不是实际的标记。因此我们引入一个注意力屏蔽(mask)。我们将注意力mask中所有实际标记位置都设为,而
[PAD]标记位置都设为,我们就有了下面的注意力mask:
attention_mask = [ 1,1,1,1,1,0,0]
接下来我们映射所有标记到一个独立的标记ID。假设用映射后的标记ID如下:
token_ids = [101, 1045, 2293, 3000, 102, 0, 0]
它的意思是标记[CLS]的ID是;标记
I的DI是等等。
现在,我们将token_ids以及attention_mask作为BERT模型的输入,然后获取每个标记的相应嵌入表示。
下图显示我们如何使用预训练的BERT模型来获得嵌入表示的。为了清晰起见,我们画出了标记本身而不是它的ID。一旦我们将标记作为输入喂给BERT,编码器1(Encoder 1)计算所有标记的嵌入表示然后传给下一个编码器——编码器2。编码器2将编码器1计算的嵌入表示作为输入,然后输出一个新的嵌入表示,接着继续传递给下一个编码器。这样每个编码器都把自己输出的嵌入表示传递到它上面的下一个编码器。而最后的编码器,返回的是我们句子中所有标记的最终嵌入表示。
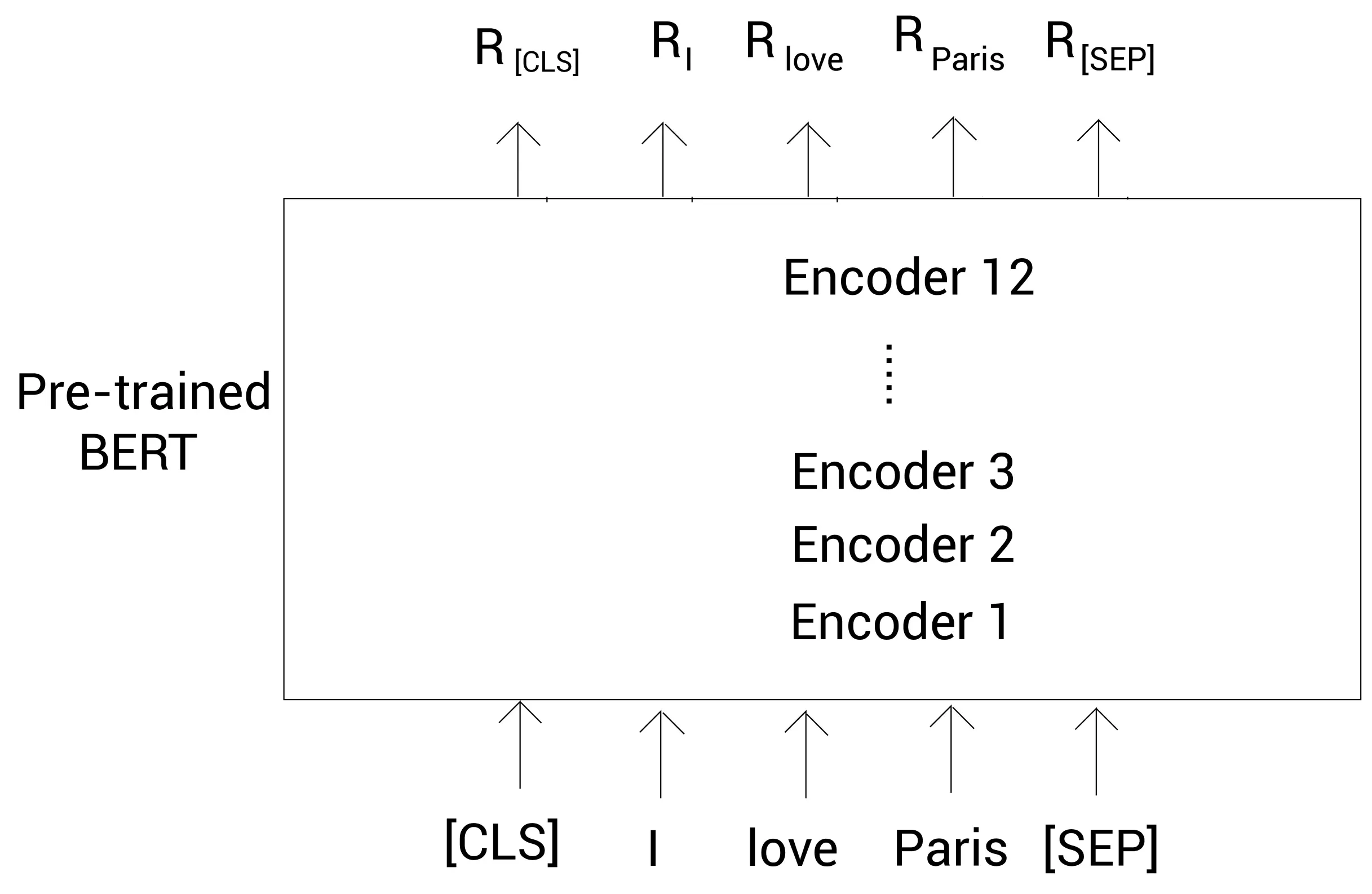
这样就是标记
[CLS]的嵌入,是标记
I的嵌入,等等。
在本例中,每个标记的嵌入表示大小为768。
我们现在得到了句子中每个单词的嵌入表示,那我们如何得到整个句子的嵌入表示呢?
我们在句首位置有[CLS]标记,该标记的输出会保存了整个完整句子的聚合信息。所以,我们可以忽略所有其他标记的嵌入,仅用[CLS]标记的输出嵌入来作为我们句子的表示。
使用同样的方式,我们可以计算训练集中所有句子的向量表示。一旦我们有了这些句子表示,我们就可以把它们作为输入去训练一个分类器完成情绪识别任务。
请注意使用[CLS]标记的输出向量作为句子表示并不总是一个好主意。获得句子表示的有效方法是对所有标记进行平均或池化(pooling)。
在下节中,我们会学习如何使用Hugging Face🤗提供的transformers库来实现我们上面说的这些事情。
Hugging Face transformers
Hugging Face🤗总部位于纽约,是一家专注于自然语言处理、人工智能和分布式系统的创业公司。他们所提供的聊天机器人技术一直颇受欢迎,但更出名的是他们在NLP开源社区上的贡献。Hugging Face一直致力于自然语言处理NLP技术的平民化(democratize),希望每个人都能用上最先进(SOTA, state-of-the-art)的NLP技术,而非困窘于训练资源的匮乏。他们的transformers库同时提供了TesnforFlow和PyTorch版。
我们可以使用pip安装transformers:
pip install transformers==4.10.0
生成BERT嵌入
本节中,我们会学习如何从预训练的BERT模型中抽取嵌入表示。考虑句子:I love Paris。我们来看看如何获得句子中所有单词的上下文单词嵌入。
首先我们引入需要的包:
from transformers import BertModel, BertTokenizer
import torch
下面我们下载预训练好的BERT模型。我们可以从https://huggingface.co/models页面查看所有可用的预训练模型。我们使用的是bert-base-uncased模型,它基于12个编码器层、并且在小写的标记中训练,表示向量的大小为768。
下载并加载预训练的bert-base-uncased模型:
model = BertModel.from_pretrained('bert-base-uncased')
下面我们下载并加载用来预训练bert-base-uncased模型的分词器:
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
现在,我们看看如何处理输入。
预处理输入
定义句子:
sentence = 'I love Paris'
分词并获得分词后的标记:
tokens = tokenizer.tokenize(sentence)
print(tokens)
输出:
['i', 'love', 'paris']
接着,我们增加[CLS]标记到标记列表头部;增加[SEP]到标记列表尾部:
tokens = ['[CLS]'] + tokens + ['[SEP]']
print(tokens)
输出:
['[CLS]', 'i', 'love', 'paris', '[SEP]']
现在我们的标记列表tokens大小为。假设我们想保持
tokens长度为;此时,我们增加两个填充标记
[PAD]到tokens末尾:
tokens = tokens + ['[PAD]'] + ['[PAD]']
tokens
输出:
['[CLS]', 'i', 'love', 'paris', '[SEP]', '[PAD]', '[PAD]']
下面,我们创建一个注意力屏蔽attention_mask:
attention_mask = [1 if i!= '[PAD]' else 0 for i in tokens]
attention_mask
输出:
[1, 1, 1, 1, 1, 0, 0]
接着,我们将所有的标记转换为对应的ID:
token_ids = tokenizer.convert_tokens_to_ids(tokens)token_ids
输出:
[101, 1045, 2293, 3000, 102, 0, 0]
现在,我们通过将token_ids和attention_mask转换为Tensor:
token_ids = torch.tensor(token_ids).unsqueeze(0)attention_mask = torch.tensor(attention_mask).unsqueeze(0)
接下来,我们把这两个变量喂给预训练的BERT模型得到嵌入表示。
获得嵌入表示
如下面的代码所示,我们将token_ids和attention_mask传入模型得到嵌入表示。注意模型返回的输出是有两个值的元组。第一个值代表隐藏状态表示hidden_rep,它包含从最终编码器(encoder 12)获取的所有标记的嵌入表示;第二个值cls_head包含[CLS]标记的嵌入表示:
hidden_rep, cls_head = model(token_ids, attention_mask=attention_mask,return_dict=False)
hidden_rep包含输入中所有单词的嵌入表示,我们打印一下它的形状:
print(hidden_rep.shape)
输出:
torch.Size([1, 7, 768]) # [batch_size, sequence_length, hidden_size]
我们的批大小为;序列长度就是标记列表长度,为
;隐藏大小是嵌入表示大小,为
。
我们可以像下面的方式获取每个表示的嵌入表示:
hidden_rep[0][0]返回第一个标记[CLS]的嵌入表示hidden_rep[0][1]返回第二个标记I的嵌入表示hidden_rep[0][2]返回第三个标记love的嵌入表示
这样,我们就得到了所有标记的上下文表示。这基本上是给定句子中所有单词的上下文词嵌入表示。
现在,我们来看下cls_head。它包含[CLS]标记的嵌入表示,我们打印一下它的形状:
print(cls_head.shape)
输出:
torch.Size([1, 768]) # [batch_size, hidden_size]
我们知道cls_head包含整个句子的聚合表示,所以我们可以使用该对象作为句子I love Paris的嵌入表示。
我们学习了如何从预训练的 BERT 模型中提取嵌入。 但这些是仅从 BERT 的最顶层编码器层(即encoder 12)获得的嵌入。我们是否也可以从 BERT 的所有编码器层中提取嵌入?
我们将在下一节中了解如何做到这一点。
从BERT所有编码器层中抽取嵌入
我们已经知道如何从预训练的BERT中抽取嵌入。那如何从BERT的所有编码器层中抽取嵌入呢?
假设输入层为,第一个编码器层为
,第二个编码器层为
,以此类推。最后一个编码器层为
:
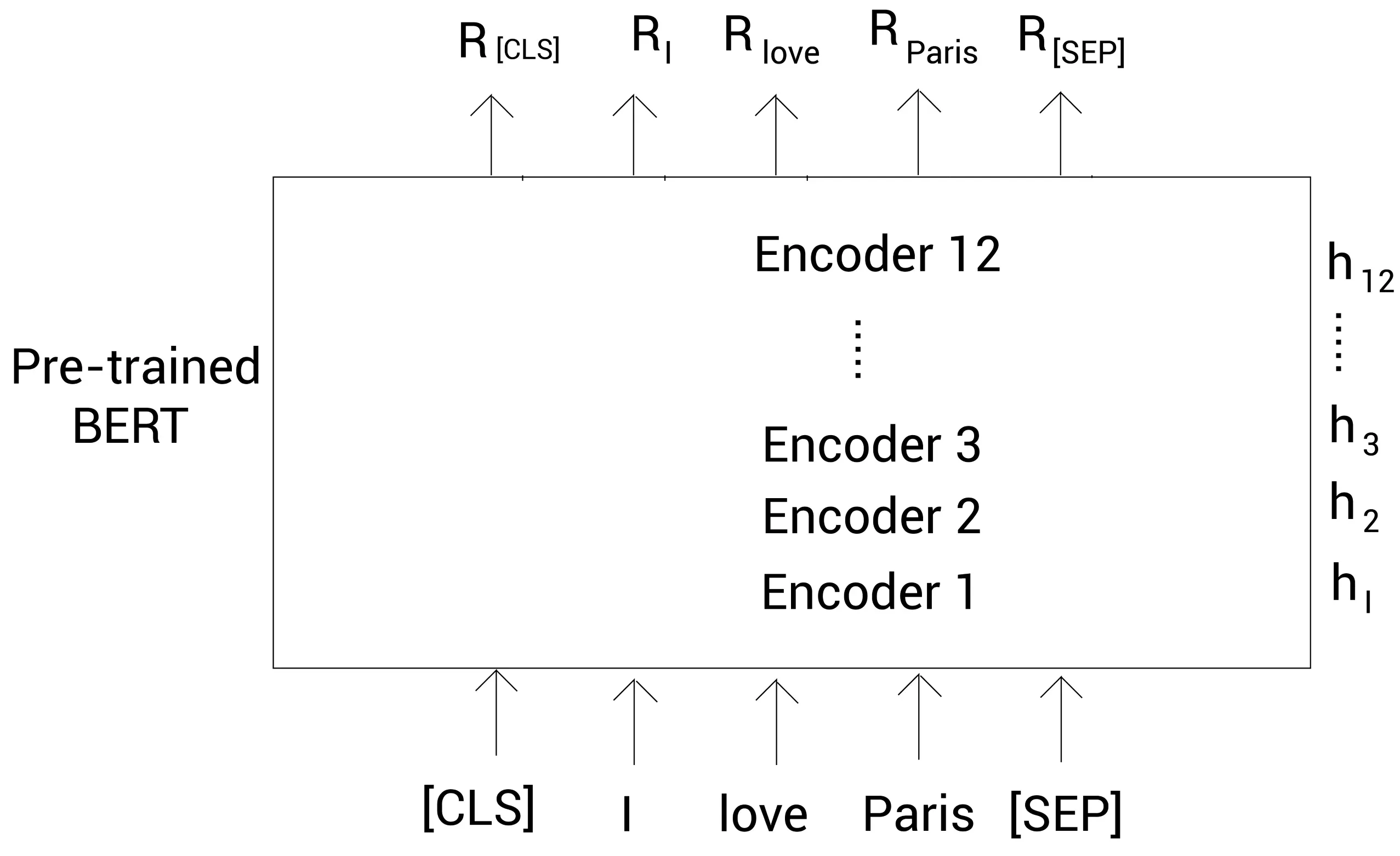
BERT的研究者已经实验过从不同的编码器层中提取嵌入。
比如,以NER任务来说,研究者已经使用与训练的BERT模型来抽取特征。他们实验了不同编码器层的特征,然后得到了如下的F1值:
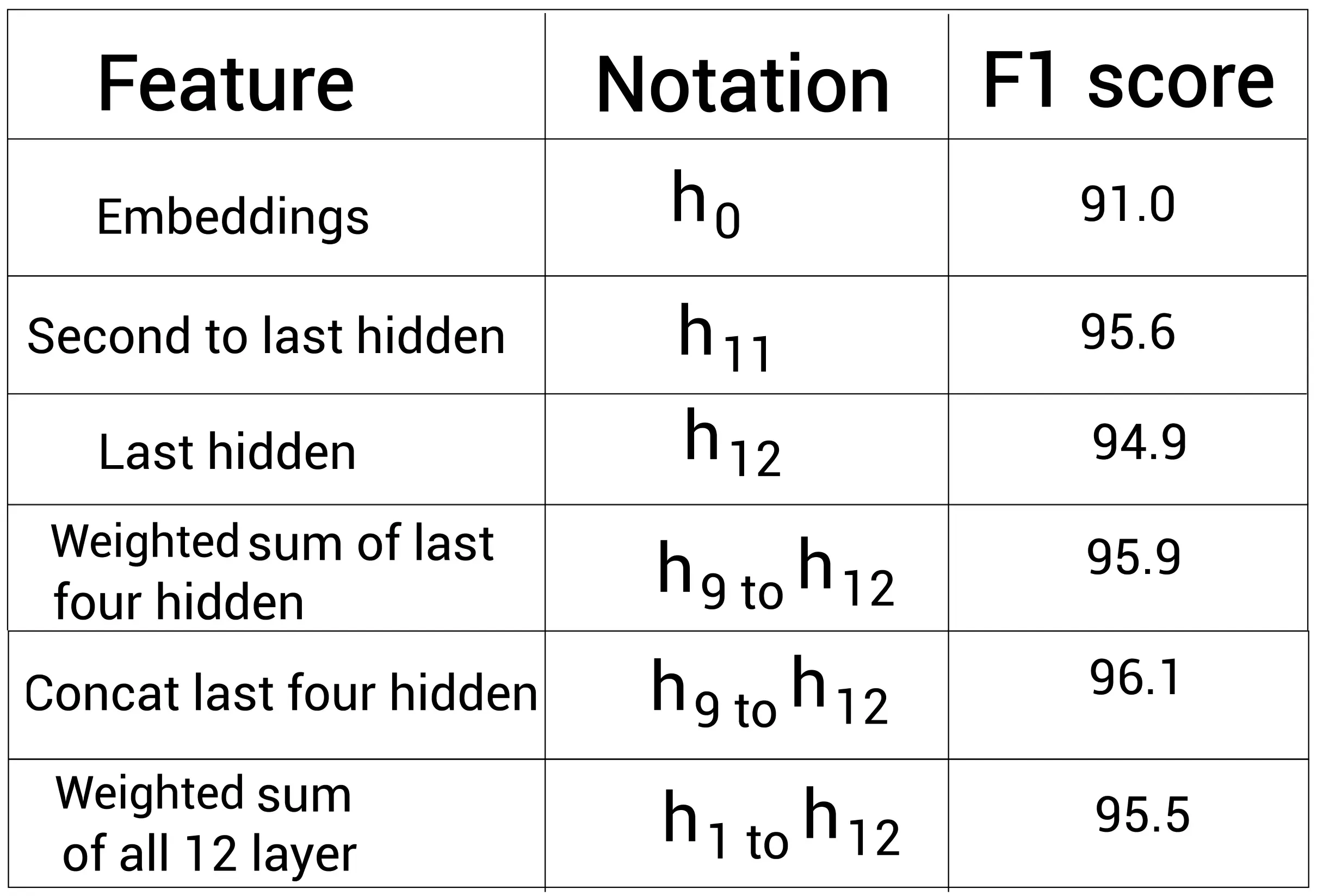
如上表所示,拼接最后4个编码器层的表示(conncat last four hidden)可以得到最好的F1值——96.1%。这说明了,不仅仅是抽取最后一个编码器层的输出,我们也可以尝试使用其他编码器层。
现在, 我们接下来会学习如何使用transformers从所有的编码器层中抽取嵌入表示。
抽取嵌入表示
首先,我们导入必须的包:
from transformers import BertModel, BertTokenizer
import torch
接着,下载预训练的BERT模型和分词器。正如我们看到的,在下载预训练的BERT模型时,我们需要设置output_hidden_states=True,这样我们就能获得所有编码器层的嵌入:
model = BertModel.from_pretrained('bert-base-uncased', output_hidden_states = True)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
下面,我们对输入进行一些预处理。
预处理输入
假设我们还是考虑上小节看到的例子。首先,我们对句子进行分词并增加[CLS]和[SEP]标记:
sentence = 'I love Paris'
tokens = tokenizer.tokenize(sentence)
tokens = ['[CLS]'] + tokens + ['[SEP]']
假设我们需要保证标记列表的长度为。所以,我们增加填充标记
[PAD]同时定义注意力mask:
tokens = tokens + ['[PAD]'] + ['[PAD]']attention_mask = [1 if i!= '[PAD]' else 0 for i in tokens]
下面我们将tokens转换为对应的ID:
token_ids = tokenizer.convert_tokens_to_ids(tokens)
现在, 我们转换token_ids和attention_mask到Tensor:
token_ids = torch.tensor(token_ids).unsqueeze(0)
attention_mask = torch.tensor(attention_mask).unsqueeze(0)
这样我们就处理完毕了,下面可以获取嵌入了。
得到嵌入表示
由于我们在定义模型时设置了 output_hidden_states = True 以从所有编码器层获取嵌入,现在模型返回一个三个元素的元组:
last_hidden_state, pooler_output, hidden_states = model(token_ids, attention_mask = attention_mask, return_dict = False)
在上面的代码中,分析如下:
- 第一个值,
last_hidden_state包含所有标记的嵌入表示,但是仅来自最后一个编码器层(encoder 12) pooler_output代表从最后的编码器层得到的[CLS]标记对应的嵌入表示,但进一步地通过一个线性和tanh激活函数(BertPooler)处理。hidden_states包含从所有编码器层得到的所有标记的嵌入表示
class BertPooler(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
# 线性
pooled_output = self.dense(first_token_tensor)
# tanh
pooled_output = self.activation(pooled_output)
return pooled_output
现在,我们逐个了解下每个值。
首先,我们看一下last_hidden_state,我们输出它的形状:
last_hidden_state.shape.shape
输出:
torch.Size([1, 7, 768]) # [batch_size, sequence_length, hidden_size]
我们的批大小为。序列长度就是标记列表长度,为
。隐藏大小是嵌入表示的大小,这里是
。
我们可以通过类似下面的方法获取每个标记的嵌入表示:
-
last_hidden_state[0][0]输出第一个标记[CLS]的嵌入表示 -
last_hidden_state[0][1]输出第二个标记I的嵌入表示 -
last_hidden_state[0][2]输出第三个标记love的嵌入表示
类似地,我们就可以从最后一个编码器层得到所有标记的嵌入表示。
下面,我们来看pooler_output,它包含最后的编码器层得到的[CLS]标记对应的嵌入表示。我们打印它的形状:
pooler_output.shape
输出:
torch.Size([1, 768]) # [batch_size, hidden_size]
我们知道[CLS]标记保存的是整个句子的聚合表示。我们就可以使用pooler_output来作为句子I love Paris的句子表示。
最后,我们来看一下hidden_states。它是一个包含13个值的元组,保存了从输入层到最后一个编码器层
的所有嵌入表示:
len(hidden_states)
输出:
13
我们可以看到,这13个值包含了所有层的表示:
-
hidden_states[0]包含输入嵌入层的所有标记的嵌入表示
-
hidden_states[1]包含第一个编码器嵌入层的所有标记的嵌入表示
-
hidden_states[2]包含第二个编码器嵌入层的所有标记的嵌入表示
-
hidden_states[12]包含最后一个编码器嵌入层的所有标记的嵌入表示
我们接着打印hidden_states[0]的形状:
hidden_states[0].shape
输出:
torch.Size([1, 7, 768]) # [batch_size, sequence_length, hidden_size]
然后,打印hidden_states[1]的形状:
hidden_states[1].shape
输出:
torch.Size([1, 7, 768])
这样我们就可以得到所有编码器层的标记对应的嵌入表示。下面我们来学习下如何把预训练的BERT模型
应用到下游任务,比如情绪分析。
为下游任务微调BERT
注意微调意味着我们不会从头开始训练BERT。而是使用预训练的BERT,然后根据任务来更新它的权重参数。
在本节中,我们会学习到如何为以下的下游任务微调BERT模型:
-
文本分类
-
自然语言推理
-
命名实体识别
-
问答任务
文本分类
我们先来学习如何为一个文本分类任务微调BERT模型。假设我们具体要做的是情绪识别。在情绪识别任务中,我们的目标是判断一个句子到底是正向的还是负向的。假设我们有一个包含句子和对应标签的数据集。
考虑句子:I love Paris。首先,当然还是分词,然后增加[CLS]和[SEP]标记。
然后我们将这些标记输入到BERT模型,得到每个标记的嵌入表示。
下面我们只拿[CLS]标记对应的嵌入表示,而忽略所有其他的标记。因为我们知道
[CLS]的嵌入包含了整个句子的聚合表示。我们将喂给一个分类器(带有softmax函数的前馈神经网络),然后训练该分类器去做情绪识别任务。
等等!这和我们在本节开头看到的有什么不同?微调预训练的 BERT 模型与使用预先训练的 BERT 模型作为特征提取器有何不同?
在从预训练的BERT中抽取嵌入表示小节中,我们知道在提取句子的嵌入后,我们将提供给分类器并训练分类器执行分类。类似地,在微调期间,我们也将
喂给一个分类并训练分类器执行分类。
不同点在于当我们微调预训练的BERT模型时,我们在更新分类器的参数时也会更新BERT的参数。但当我们使用预训练的BERT模型作为特征抽取器时,我们只更新分类器的参数,而不更新预训练的BERT模型。
在微调期间,我们可以通过以下两个方式调整BERT模型的参数:
- 随着分类器一起更新预训练的BERT模型的参数
- 仅更新分类器的参数而不更新预训练BERT模型的。此时,这种方式类似将预训练的BERT模型作为特征抽取器的情况。
下图阐述了我们如何为一个情绪分类任务微调预训练的BERT模型:
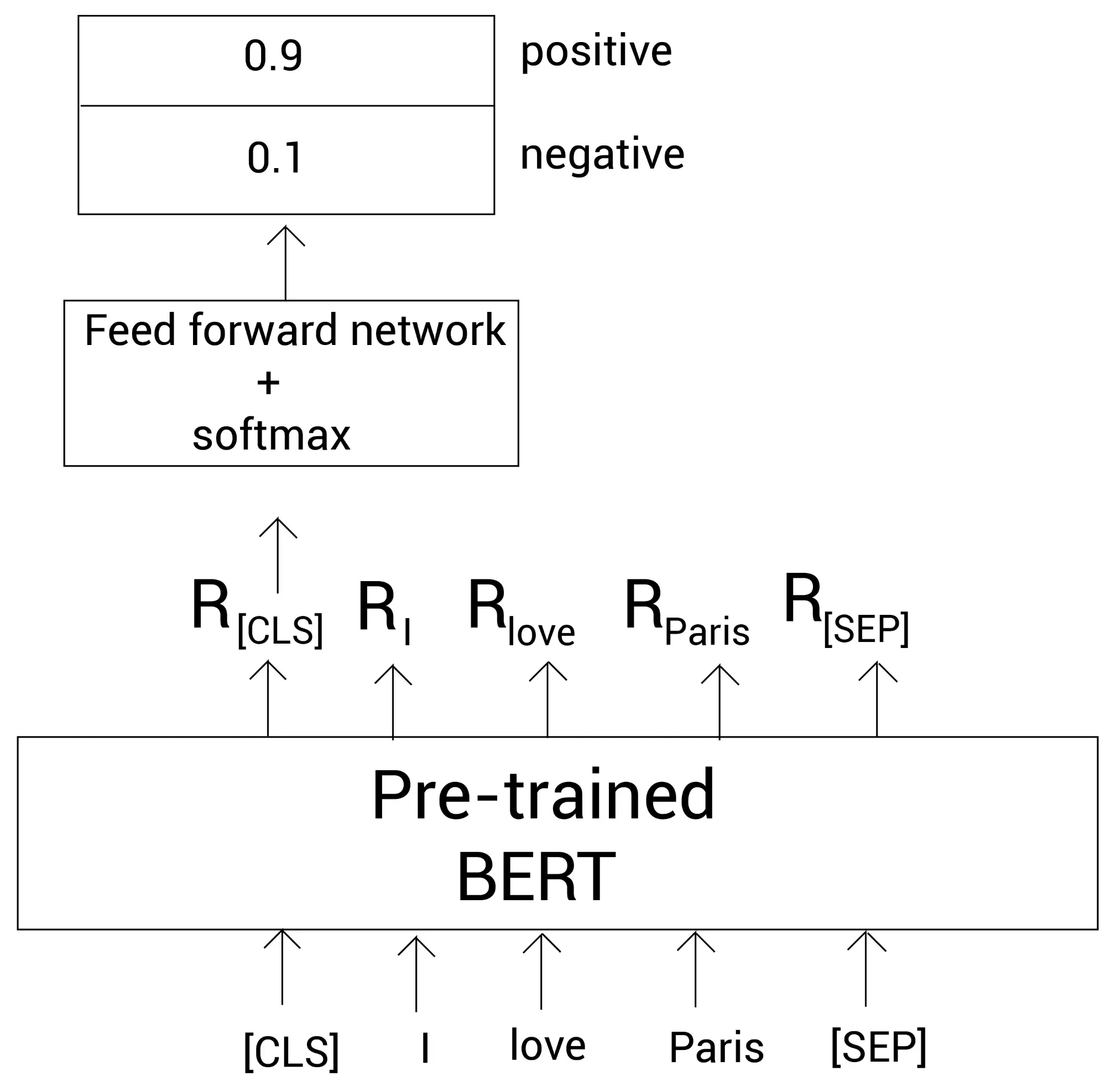
正如我们看到的,我们将标记列表喂给BERT模型并得到这些标记的嵌入。然后我们拿[CLS]标记的嵌入作为前馈神经网络的输入,并进行分类任务。
在下一小节中,让我们通过代码对预训练的 BERT 模型进行微调来更好地了解微调的工作原理。
为情绪识别微调BERT
让我们探索如何使用 IMDB 数据集为情感分析任务微调预训练的 BERT 模型。 IMDB 数据集由电影评论以及评论对应情绪组成。
引入依赖
首先我们安装必要的依赖:
!pip install nlp==0.4.0
!pip install transformers==4.10.0
引入必要的包:
from transformers import BertForSequenceClassification, BertTokenizerFast, Trainer, TrainingArguments
from nlp import load_dataset
import torch
import numpy as np
加载模型和数据集
imdbs数据集网上很常见,也可关注文章底部的公众号,回复 imdbs获取。
首先,我们使用nlp包下载并加载数据集:
dataset = load_dataset('csv', data_files='./imdbs.csv', split='train')
我们查看数据类型:
type(dataset)
输出:
nlp.arrow_dataset.Dataset
下面,将数据集拆分为训练和测试集:
dataset = dataset.train_test_split(test_size=0.3)
我们输出数据集dataset:
{'test': Dataset(features: {'text': Value(dtype='string', id=None), 'label': Value(dtype='int64', id=None)}, num_rows: 30),
'train': Dataset(features: {'text': Value(dtype='string', id=None), 'label': Value(dtype='int64', id=None)}, num_rows: 70)}
现在我们创建训练和测试集:
train_set = dataset['train']
test_set = dataset['test']
接下来,我们下载并加载预训练的BERT模型。在本例中,我们使用预训练的bert-base-uncased模型。因为我们在做序列分类任务,我们就可以使用BertForSequenceClassification类:
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
下面,我们下载并加载用于预训练bert-base-uncased模型的分词器。
这里我们使用BertTokenizerFast类创建分词器而不是BertTokenizer。因为BertTokenizerFast相比BertTokenizer具有很多优势。我们下节会探讨这一点。
tokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased')
现在我们已经加载好了数据集赫尔模型,让我们开始预处理数据集吧。
预处理数据集
我们可以使用我们的分词器快速地预处理数据集。比如,考虑句子:I love Paris。
首先,我们分词并增加[CLS]和[SEP]标记:
tokens = [ '[CLS]', 'I', 'love', 'Paris', '[SEP]' ]
下面,我们映射标记到独立的输入ID。假设我们得到下面的ID:
input_ids = [101, 1045, 2293, 3000, 102]
然后,我们需要增加片段ID(segment ID,标记类型ID)。??什么片段ID?假设我们的输入有两个句子,此时,片段ID用于区分这两个句子。所有来自第一个句子的标记会映射到0;所有来自第二个句子的标记会映射到1。因为我们这里只有一个句子,所以所有的标记都会映射到0:
token_type_ids = [0, 0, 0, 0, 0]
现在我们需要创建注意力mask。我们知道注意力mask用于区分真实标记和填充标记[PAD]。假设我们的标记列表长度应该为。我们这里的标记列表的长度应是
了,所以不需要增加
[PAD]标记。那么我们的注意力mask就会如下:
attention_mask = [1, 1, 1, 1, 1]
我们可以使用分词器来为我们做上面这些手动的步骤。只需要将句子传递给分词器即可:
tokenizer('I love Paris')
输出如下,我们可以看到,输入句子被分词了并且映射到input_ids、token_type_ids,同时还有attention_mask:
{
'input_ids': [101, 1045, 2293, 3000, 102],
'token_type_ids': [0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1]
}
通过分词器,我们也可以传入任意数量的句子并动态地执行填充。我们执行需要设置padding为True和最大的句子长度max_length。比如,下面的代码中,我们传入3个句子,并将max_length设为5:
tokenizer(['I love Paris', 'birds fly','snow fall'], padding = True, max_length=5)
前面的代码将返回以下内容。 如我们所见,所有句子都映射到 input_ids、token_type_ids和 attention_mask。 第二句和第三句只有两个标记,加上[CLS]和[SEP]后,就会有4个标记。 由于我们将 padding 设置为 True 并将 max_length 设置为 5,因此第二个和第三个句子中会添加一个额外的[PAD]标记,这就是我们在第二个和第三个句子的注意力mask中值为 0 的原因:
{
'input_ids': [[101, 1045, 2293, 3000, 102], [101, 5055, 4875, 102, 0], [101, 4586, 2991, 102, 0]],
'token_type_ids': [[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1], [1, 1, 1, 1, 0], [1, 1, 1, 1, 0]]
}
看,通过分词器我们就可以很容易的预处理数据集。所以我们可以定义如下函数来预处理数据集:
def preprocess(data):
return tokenizer(data['text'], padding=True, truncation=True)
现在,我们使用preprocess函数预处理训练和测试数据集:
train_set = train_set.map(preprocess, batched=True,
batch_size=len(train_set))
test_set = test_set.map(preprocess, batched=True, batch_size=len(test_set))
下面,我们使用set_format函数来选择我们在数据集中需要的列:
train_set.set_format('torch',
columns=['input_ids', 'attention_mask', 'label'])
test_set.set_format('torch',
columns=['input_ids', 'attention_mask', 'label'])
这样,我们的数据集准备好了。可以开始训练模型了。
训练模型
我们先定义批大小和epoch大小:
batch_size = 8
epochs = 2
定义热身步数和权重衰减:
warmup_steps = 500
weight_decay = 0.01
定义训练参数:
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=epochs,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
warmup_steps=warmup_steps,
weight_decay=weight_decay,
logging_dir='./logs'
)
然后定义训练器:
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_set,
eval_dataset=test_set
)
开始训练:
trainer.train()
在训练完成之后,我们可以通过evaluate函数评估模型:
trainer.evaluate()
输出为:
{'epoch': 2.0,
'eval_loss': 0.6827354431152344,
'eval_runtime': 2.131,
'eval_samples_per_second': 14.078,
'eval_steps_per_second': 1.877}
这样我们就能微调预训练的BERT模型。既然我们已经学会了如何为一个文本分类任务微调BERT模型,在下一小节中,我们看看如何为自然语言推理任务微调BERT模型。
自然语言推理
在自然语言推理中,我们模型的目标是在给定前提(premise)的情况下,确定假设(hypothesis)是蕴涵(true)、矛盾(false)还是不确定(neutral)。 让我们通过微调 BERT 来学习如何解决自然语言推理任务。
考虑下面的数据集。
我们有一个前提和一个带有标签的假设,表明它们是蕴涵、矛盾还是不确定:

现在,我们模型的目标是确定句子对(前提-假设对)是蕴涵、矛盾还是不确定。 让我们通过一个例子来了解如何做到这一点。 考虑以下前提-假设对:
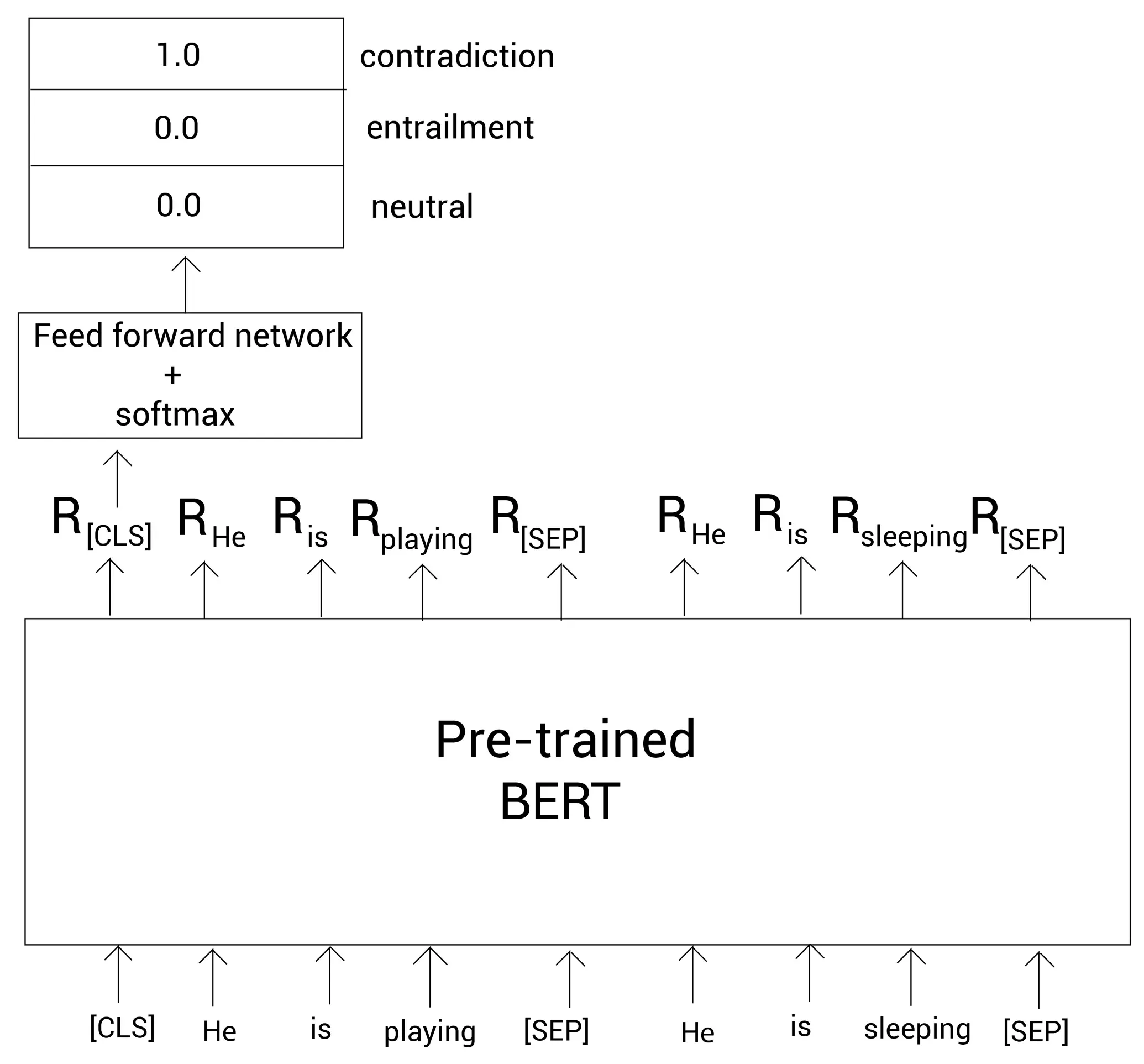
Premise: He is playing
Hypothesis: He is sleeping
首先我们对句子分词,然后增加[CLS]和[SEP]标记:
tokens = [ [CLS], He, is, playing, [SEP], He, is, sleeping [SEP]]
现在, 我们将这些标记喂给预训练的BERT模型并得到每个单词的嵌入。
我们拿出[CLS]标记的嵌入表示,并喂给一个分类器(前馈网络+softmax),该分类器会返回句子是蕴含、矛盾还是不确定的概率:
为问答任务微调BERT
在本节中,我们学习如何用一个预训练的问答BERT模型来做问答任务。首先,我们导入必要的包:
from transformers import BertForQuestionAnswering, BertTokenizer
import torch
现在,我们下载并加载模型。我们使用bert-large-uncased-whole-word-masking-finetuned-squad模型,它是在SQUAD数据集上微调过的:
model = BertForQuestionAnswering.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')
然后,我们下载并加载分词器:
tokenizer = BertTokenizer.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')
预处理输入
首先,我们定义BERT的输入,为问题和文本段落:
question = "What is the immune system?"
paragraph = "The immune system is a system of many biological structures and processes within an organism that protects against disease. To function properly, an immune system must detect a wide variety of agents, known as pathogens, from viruses to parasitic worms, and distinguish them from the organism's own healthy tissue."
增加[CLS]和[SEP]标记到问题和段落中:
question = '[CLS] ' + question + '[SEP]'
paragraph = paragraph + '[SEP]'
然后,对问题和段落进行分词:
question_tokens = tokenizer.tokenize(question)
paragraph_tokens = tokenizer.tokenize(paragraph)
组合问题和段落标记,并将它们转换为input_ids:
tokens = question_tokens + paragraph_tokens
input_ids = tokenizer.convert_tokens_to_ids(tokens)
接下来,定义segment_ids。这里,segment_ids会把所有来自问题的标记映射为0;把所有来自段落的标记映射为1:
segment_ids = [0] * len(question_tokens)
segment_ids += [1] * len(paragraph_tokens)
然后,把input_ids和segment_ids转换为Tensor:
input_ids = torch.tensor([input_ids])
segment_ids = torch.tensor([segment_ids])
获取答案
我们将input_ids和segment_ids输入到模型中,它会返回所有标记作为答案开始位置和结束位置的得分:
start_scores, end_scores = model(input_ids, token_type_ids = segment_ids, return_dict = False)
接着,我们找到start_index,就是最高答案开始位置得分对应的标记索引,和end_index,为最高答案结束位置得分对应的标记索引:
start_index = torch.argmax(start_scores)
end_index = torch.argmax(end_scores)
好了,我们就可以输出开始索引和结束索引之间的问题片段了:
print(' '.join(tokens[start_index:end_index+1]))
输出:
a system of many biological structures and processes within an organism that protects against disease
命名实体识别
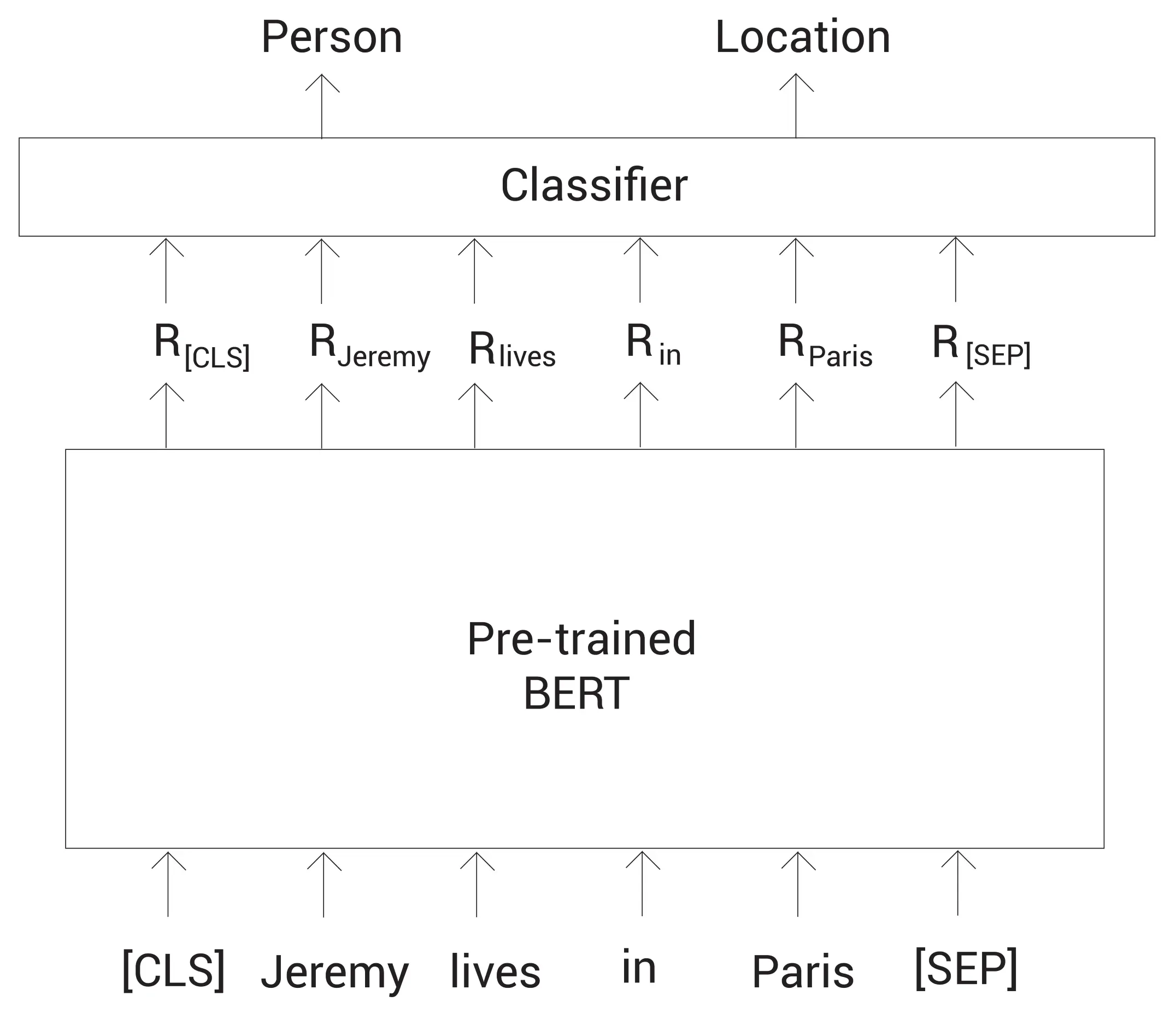
在命名实体识别(NER)中,我们的目标是将命名实体分类到预设好的类别中。比如,考虑句子: Jeremy lives in Paris,其中的Jeremy应该被分类为人名,Paris应该分类为地点。
现在,我们学习如何微调预训练的BERT模型去做NER任务。首先,我们对句子分词,然后增加[CLS]和[SEP]标记。接着,我们将这些标记喂给预训练的BERT模型,得到每个标记的嵌入表示。然后,将这些嵌入表示都喂给一个分类器(前馈网络+softmax函数)。最后,该分类器返回每个命名实体对应的类别。
如下图所示:
参考
Getting Started with Google BERT
文章出处登录后可见!