文章目录
- 前言
- 一、DataLoader介绍
- 二、DataLoader的子方法(可调用方法)
前言
dataloader数据加载器属于是深度学习里面非常基础的一个概念了,基本所有的图像项目都会用上,这篇博客就把它的相关用法总结一下。
之所以要写这篇,是想分清楚len(data_loader)和len(data_loader.dataset)
一、DataLoader介绍
这里加载的数据我们以Mnist手写数据集为例子
import torch.utils.data as Data
import torchvision
from torchvision import transforms
data = torchvision.datasets.MNIST(
'data', #目标数据集路径
train=True, # 只使用train数据
transform=transforms.ToTensor(),#图像预处理,转为张量,并将像素值转到0-1
download=True)
data_loader=Data.DataLoader(
dataset=data,
batch_size=32,
shuffle=True,
num_workers=0
)
torchvision.datasets.MNIST是用来加载自带数据包,这里不在多说了。
我们主要看下面的Data.DataLoader
1)dataset指需要用数据加载器加载的数据,即上面的data
2) batch_size指每一批次图像的数量
3) shuffle指是否打乱
4)num_workers 进程数 我一般设为0,不然很可能报错
二、DataLoader的子方法(可调用方法)
紧接着上面的方法,我们进行一些操作,进一步了解DataLoader
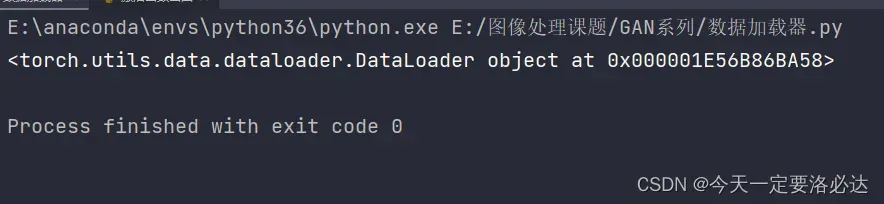
1)data_loader整体打印
print(data_loader)
2)数据加载器一共被分成了多少块(batch_size个图像为一块)
print(len(data_loader))
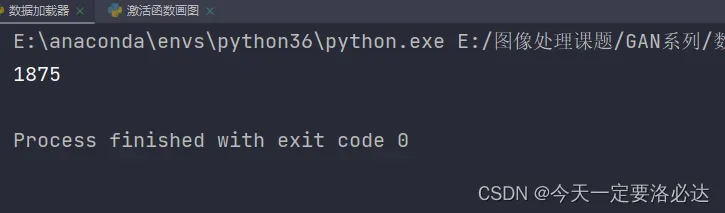
1875×32=60000
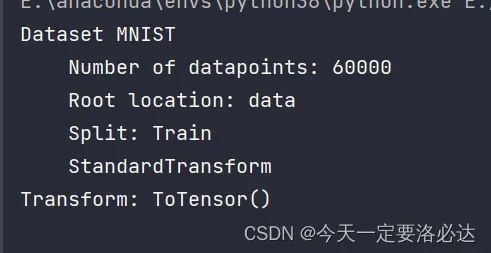
3)data_loader.dataset
print(data_loader.dataset)
如果我们换一种:len(data_loader.dataset)
print(len(data_loader.dataset))
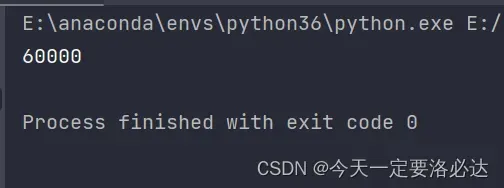
这里展示了整个数据集里图像的个数。 注意和len(data_loader)区别开,这也是我写这篇博客的原因。
4)打印数据加载器之前设定的batch_size
print(data_loader.batch_size)
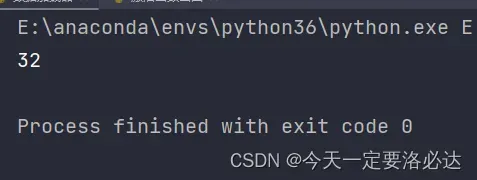
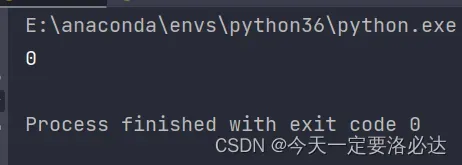
5)打印数据加载器之前设定的进程数
print(data_loader.num_workers)
文章出处登录后可见!
已经登录?立即刷新