文章目录
- Pandas.rank() 函数详解
- 一、参数解析
- 二、案例分享
- 默认排名
- `降序: ascending = False`
- `method = ‘min’`
- `method = ‘max’`
- `method = ‘first’`
- `method = ‘dense’`
- `na_option=’bottom’`
- `pct = True`
Pandas.rank() 函数详解
一、参数解析
method:指定排名时的策略。- 默认值为
'average',表示相同值的项将会获得平均排名。 - 可选的取值还包括
'min':相同值的项将获得最小排名;'max':相同值的项将获得最大排名;'first':相同值的项将获得第一次出现时的排名;'dense'。相同值的项将获得连续排名。
- 默认值为
ascending:指定排名的顺序。- 默认值为
True,升序。 - 设置为
False降序。
- 默认值为
na_option:指定如何处理缺失值(NaN)。- 默认值为
'keep',缺失值不参与排名。 - 设置为
'top'则将缺失值放在排名结果的顶部。 - 设置为
'bottom'则将缺失值放在排名结果的底部。
- 默认值为
pct:指定是否返回百分比排名。- 默认值为
False表示返回实际的排名值。 - 设置为
True则返回相对于总项数的百分比排名值。
- 默认值为
二、案例分享
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Emma', 'Frank'],
'Score': [90, 85, 85, 75, None, 78]}
df = pd.DataFrame(data)
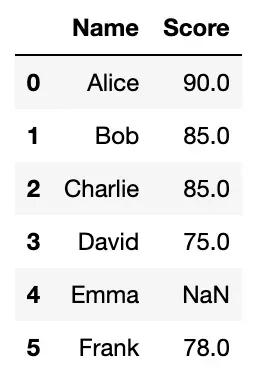
默认排名
- 升序、忽略缺失值;
- 遇到相同数值(如score=85),排名会平分
df['Rank'] = df['Score'].rank()
降序: ascending = False
df['Rank'] = df['Score'].rank(ascending=False)
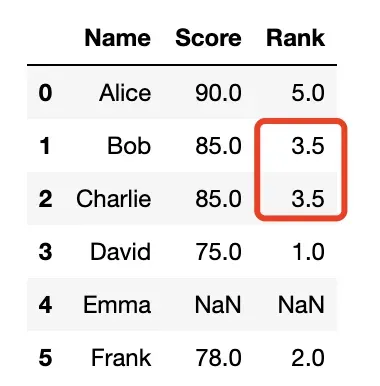
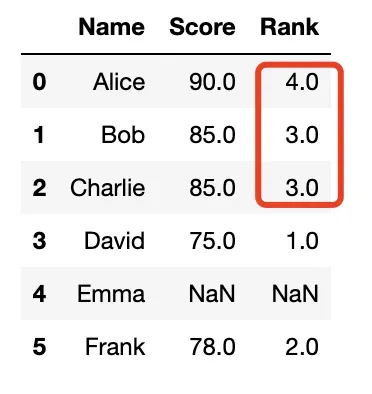
method = 'min'
- 相同值的项将获得最小排名;
- 此处相同值为85,占排名3、4位,取最小3;
- 此时排名会出现断层
df['Rank'] = df['Score'].rank(method='min')
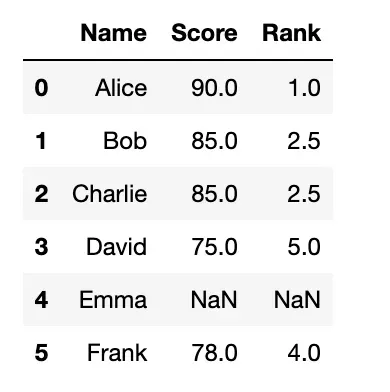
method = 'max'
- 相同值的项将获得最大排名;
- 此处相同值为85,占排名3、4位,取最大4;
- 此时排名会出现断层
df['Rank'] = df['Score'].rank(method='max')
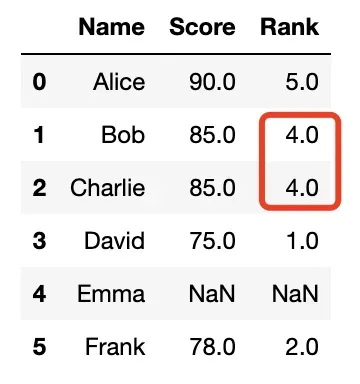
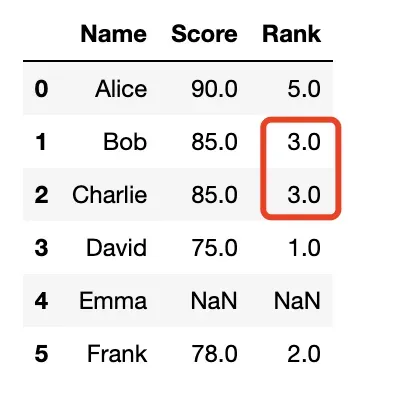
method = 'first'
- 相同值的项将获得第一次出现时的排名;
- 此处相同值为85,占排名3、4位,Name=Bob出现在前,Name=Charlie出现在后;
- 此时排名不会出现断层
df['Rank'] = df['Score'].rank(method='first')
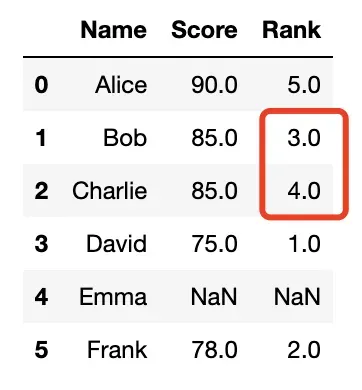
method = 'dense'
- 相同值的项将获得连续排名;
- 此时排名不会出现断层
df['Rank'] = df['Score'].rank(method='dense')
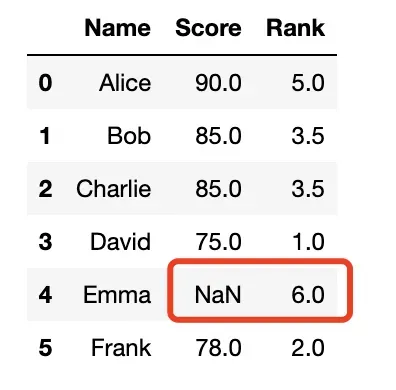
na_option='bottom'
- 缺失值参与排名;
- 缺失值排名靠后
df['Rank'] = df['Score'].rank(na_option='bottom')
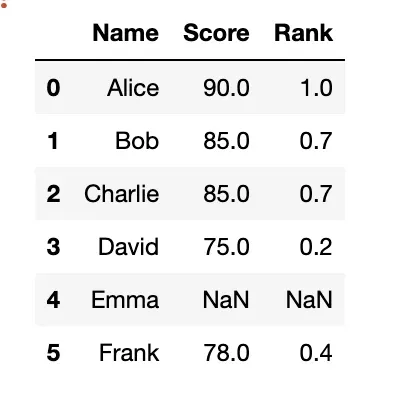
pct = True
- 返回百分比排名,如此处score=75排名第1(升序),总项数是5,1/5=0.2;
- 该参数可以扩展的实际需求:求销售额Top20的商品等
df['Rank'] = df['Score'].rank(pct=True)
文章出处登录后可见!
已经登录?立即刷新