系列文章目录
第一章 Python 基础知识
第二章 python 字符串处理
第三章 python 数据类型
第四章 python 运算符与流程控制
第五章 python 文件操作
第六章 python 函数
第七章 python 常用内建函数
第八章 python 类(面向对象编程)
第九章 python 异常处理
第十章 python 自定义模块及导入方法
第十一章 python 常用标准库
第十二章 python 正则表达式
第十三章 python 操作数据库
文章目录
- 系列文章目录
- 描述
- 系统管理:os
- 获取文件属性:os.path
- 与解释器交互:sys
- 获取系统信息:platform
- 查找文件:glob
- 生成随机数:random
- 执行shell命令:subprocess
- 序列化与反序列化:pickle
- JSON数据编码和解码:json
- 时间处理
- time
- datetime
- 访问URL:urllib
- 总结
描述
标准库是Python的内置库,直接可以用,不需要安装操作
| 模块 | 描述 |
|---|---|
| os | 操作系统管理 |
| sys | 解释器交互 |
| platform | 操作系统信息 |
| glob | 查找文件 |
| shutil | 文件管理 |
| random | 随机数 |
| subprocess | 执行shell命令 |
| pickle | 对象数据持久化 |
| json | JSON编码和解码 |
| time | 时间访问和转换 |
| datetime | 日期和时间 |
| urllib | HTTP访问 |
官方文档标准库列表:https://docs.python.org/zh-cn/3.8/library/index.html
系统管理:os
os:库主要对目标和文件操作
| 方法 | 描述 |
|---|---|
| os.name | 返回操作系统类型 |
| os.environ | 以字典形式返回系统变量 |
| os.putenv(key,value) | 改变或添加黄集变量 |
| os.listdir(path=’ .’) | 列表形式列出目录下所有目录和文件名 |
| os.getcwd() | 获取当前路径 |
| os.chdir(path) | 改变当前工作目录到指定目录 |
| os.mkdir(path [,mode=0777]) | 创建目录 |
| os.makedirs(path [, mode=0777]) | 递归创建目录 |
| os.rmdir(path) | 移除空目录,不能删除有文件的目录 |
| os.remove(path) | 移除文件 |
| os.rename(‘old’, ‘new’) | 重命名文件或目录 |
| os.stat(path) | 获取文件或目录属性 |
| os.chown(path, uid, gid) | 改变文件或目录所有者 |
| os.chmod(path, mode) | 改变文件访问权限 |
| os.symlink(src, dst) | 创建软链接 |
| os.unlink(path) | 移除软链接 |
| os.getuid() | 返回当前进程UID |
| os.getlogin() | 返回登录用户名 |
| os.getpid() | 返回当前进程ID |
| os.kill(pid, sig) | 发送一个信号给进程 |
| os.walk(path) | 目录树生成器,生成一个三元组 (dirpath, dirnames, filenames) |
| os.system(command) | 执行shell命令,不能存储结果 |
| os.popen(command [, mode=‘r’ [, bufsize]]) | 打开管道来自shell命令,并返回一个文件对象 |
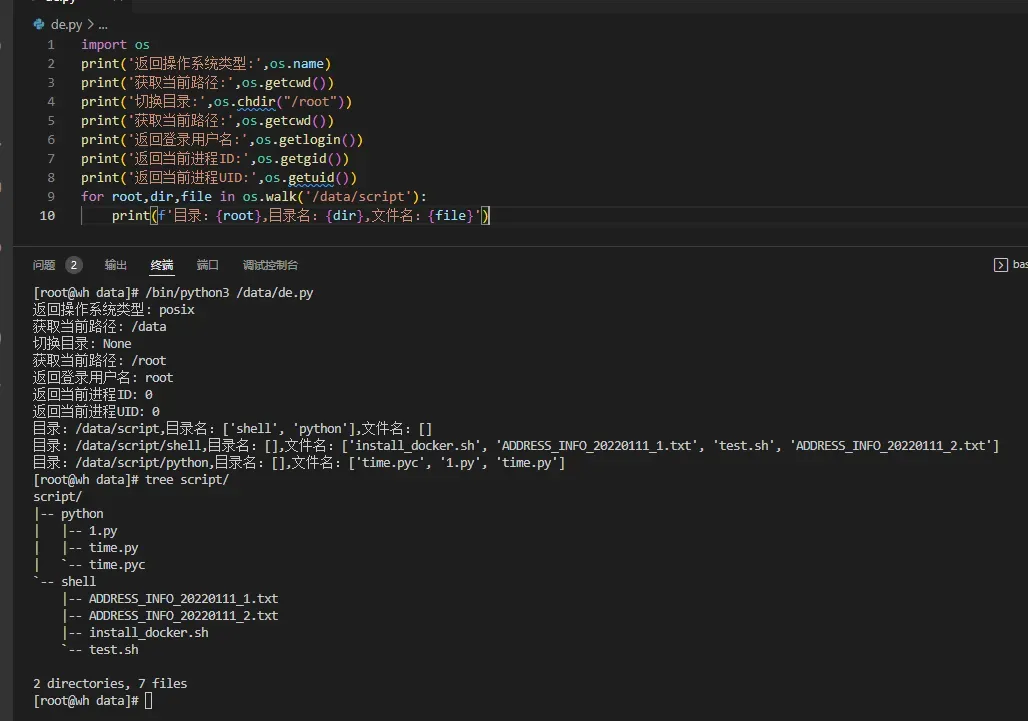
import os
print('返回操作系统类型:',os.name)
print('获取当前路径:',os.getcwd())
print('切换目录:',os.chdir("/root"))
print('获取当前路径:',os.getcwd())
print('返回登录用户名:',os.getlogin())
print('返回当前进程ID:',os.getgid())
print('返回当前进程UID:',os.getuid())
for root,dir,file in os.walk('/data/script'):
print(f'目录:{root},目录名:{dir},文件名:{file}')
获取文件属性:os.path
os.path类用于获取文件属性
| 方法 | 描述 |
|---|---|
| os.path.basename(path) | 返回最后一个文件或目录名 |
| os.path.dirname(path) | 返回最后一个文件所属目录 |
| os.path.abspath(path) | 返回一个绝对路径 |
| os.path.exists(path) | 判断路径是否存在,返回布尔值 |
| os.path.isdir(path) | 判断是否是目录 |
| os.path.isfile(path) | 判断是否是文件 |
| os.path.islink(path) | 判断是否是链接 |
| os.path.ismount(path) | 判断是否挂载 |
| os.path.getatime(filename) | 返回文件访问时间戳 |
| os.path.getctime(filename) | 返回文件变化时间戳 |
| os.path.getmtime(filename) | 返回文件修改时间戳 |
| os.path.getsize(filename) | 返回文件大小,单位字节 |
| os.path.join(a,*p) | 加入两个或两个以上路径,以正斜杠”/”分隔。常用于拼接路径 |
| os.path.split() | 分隔路径名 |
| os.path.splitext() | 分隔扩展名 |
import os
print('返回最后一个文件或目录名:',os.path.basename('/data/script/python/1.py'))
print('返回最后一个文件所属目录:',os.path.dirname('/data/script/python/1.py'))
print('返回一个绝对路径:',os.path.abspath('time.py')) # 当前目录没有time.py,可用再生成文件时候绝对路径
print('判断是否是目录:',os.path.isdir('/adsgdasg'))
print('判断是否是目录:',os.path.isdir('/data'))
print('拼接:',os.path.join('/data/pppp','adsfsda.txt'))
print('分割路径:',os.path.split('/data/pppp/adsfsda.txt'))
print('分隔扩展名:',os.path.splitext('/data/pppp/adsfsda.txt'))
print('分隔扩展名:',os.path.splitext('/data/pppp/adsfsda.txt')[1]])###

与解释器交互:sys
sys库用于与Python解释器交互
| 方法 | 描述 |
|---|---|
| sys.argv | 从程序外部传递参数 argv[0] #代表本身名字 argv[1] #第一个参数 argv[2] #第二个参数 argv[3] #第三个参数 argv[N] #第N个参数 argv # 参数以空格分割储存到列表 |
| sys.exit([status]) | 退出Python解释器 |
| sys.path | 当前Python解释器查找模块搜索的路径,列表返回sys.path.append() |
| sys.getdefaultencoding() | 获取系统当前编码 |
| sys.platform | 返回操作系统类型 |
| sys.version | 获取Python版本 |
import sys
print('======================argv==============')
print(sys.argv)
print(sys.argv[0])
print(sys.argv[1])
print(sys.argv[2])
print(sys.argv[3])
print('======================path==============')
print(sys.path) # 引用模块时的默认路径 sys.path.append()
print('======================getdefaultencoding==============')
print('获取系统当前编码:',sys.getdefaultencoding())
print('======================version==============')
print('返回操作系统类型:','\n',sys.version)
print('======================exit==============')
print('hello')
sys.exit(22) # 0是正常退出,非0异常退出
print('hello2')

获取系统信息:platform
platform库用于获取操作系统详细信息
| 方法 | 描述 |
|---|---|
| platform.platform() | 返回操作系统平台 |
| platform.uname() | 返回操作系统信息 |
| platform.system() | 返回操作系统平台 |
| platform.version() | 返回操作系统版本 |
| platform.machine() | 返回计算机类型 |
| platform.processor() | 返回计算机处理器类型 |
| platform.node() | 返回计算机网络名 |
| platform.python_version() | 返回Python版本号 |
import platform
print('返回操作系统平台:',platform.platform())
print('返回操作系统信息:',platform.uname())
print('返回操作系统平台:',platform.system())
print('返回操作系统版本:',platform.version())
print('返回计算机类型:',platform.machine())
print('返回计算机处理器类型:',platform.processor())
print('返回计算机网络名:',platform.node())
print('返回Python版本号:',platform.python_version())

查找文件:glob
glob库用于文件查找,支持通配符(*、?、[])
import glob
print('查找目录中所有以.py为后缀的文件:',glob.glob('/data/script/python/*.py'))
print('查找目录中出现单个字符并以.sh为后缀的文件:',glob.glob('/data/script/python/?.py'))
print('查找目录中出现1.py或2.py的文件:',glob.glob('/data/script/python/[1|2].py'))
print('查看包含.py和.txt后缀文件:',glob.glob('/data/*[.py|.txt]'))

生成随机数:random
random库用于生成随机数
| 方法 | 描述 |
|---|---|
| random.randint(a,b) | 随机返回整数a和b范围内数字 |
| random.random() | 生成随机数,它在0和1范围内 |
| random.randrange(start,stop[,stop]) | 返回整数范围的随机数,并可以设置只返回跳数 |
| random.sample(array,x) | 从数组中返回随机x个元素 |
| random.choice(seq) | 从序列中返回一个元素 |
import random
aa = random.randint(1,10)
print('随机1:',aa)
print('随机2:',aa)
print('随机3:',random.random())
bb = ['张三','李四','王五']
print('列表随机一个值:',random.choice(bb))
print('列表随机两个值:',random.sample(bb,2))
print(random.randrange(1,10,2)) # 只打印1,3,5,7,9
print(random.randrange(1,10,2))

执行shell命令:subprocess
ubprocess库用于执行Shell命令
工作时会fork一个子进程去执行任务,连接到子进程的标准输入、输出、错误,并获得 它们的返回代码
这个模块将取代os.system、os.spawn*、os.popen*、popen2.和commands.
subprocess的主要方法:
python3.5以上版本使用run,以前是Popen
subprocess.run(),subprocess.Popen(),subprocess.call
语法:
subprocess.run(args, *, stdin=None, stdout=None, stderr=None, shell=False, cwd=None, timeout=None, check=False, encoding=None)
| 方法 | 描述 |
|---|---|
| args | 要执行的shell命令,默认是一个字符串序列,如[‘ls’, ‘-al’]或(‘ls’, ‘-al’);也可是一个字符串,如’ls -al’,同时需要设置shell=True。 |
| stdin stdout stderr | run()函数默认不会捕获命令运行结果的正常输出和错误输出,可以设置stdout=PIPE, stderr=PIPE来从子进程中捕获相应的内容;也可以设置stderr=STDOUT,使标准错误通过标准输出流输出。 |
| shell | 如果shell为True,那么指定的命令将通过shell执行。 |
| cwd | 改变当前工作目录 |
| timeout | 设置命令超时时间。如果命令执行时间超时,子进程将被杀死,并弹出TimeoutExpired |
| check | 如果check参数的值是True,且执行命令的进程以非0状态码退出,则会抛出一个CalledProcessError的异常,且该异常对象会包含参数、退出状态码、以及stdout和stderr(如果它们有被捕获的话)。 |
| encoding | 如果指定了该参数,则 stdin、stdout 和 stderr 可以接收字符串数据,并以该编码方式编码。否则只接收 bytes 类型的数据。 |
import subprocess
cmd = 'pwd'
result = subprocess.run(cmd,shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE)
print(result)
print('获取命令执行返回状态码:',result.returncode)
print('命令执行标准输出:',result.stdout)
print('解码--命令执行标准输出:',result.stdout.decode())
print('命令执行错误输出:',result.stderr)
print('======================================')
cmd = 'pwdaaaa'
result = subprocess.run(cmd,shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE)
print(result)
print('获取命令执行返回状态码:',result.returncode)
print('命令执行标准输出:',result.stdout)
print('命令执行错误输出:',result.stderr)

序列化与反序列化:pickle
pickle模块实现对一个Python对象结构的二进制序列和反序列化
主要用于将对象持久化到文件存储
pickle模块主要有两个函数
1.dump()把对象保存到文件中(序列化),使用load()函数从文件中读取(反序列化)
2.dumps()把对象保存到内存中,使用loads()函数读取
示例
# 序列化
import pickle
computer = {“主机”:5000,“显示器”:1000,“鼠标”:60,“键盘”:1500}
with open(“data.pki”,“wb”) as f: # 写入到的二进制文件
pickle.dump(computer,f)
# 反序列化
import pickle
with open(“data.pki”,“rb”) as f:
print(pickle.load(f))
import pickle
import os
computer = {"主机":5000,"显示器":1000,"鼠标":60,"键盘":1500}
with open("data.pki","wb") as f: # 写入到命名为data.pki的二进制文件中
pickle.dump(computer,f)
print('========================================')
print(os.system('cat data.pki')) # 查看data.pki的二进制文件
print('========================================')
with open("data.pki","rb") as f: # 反解析data.pki的二进制文件
print(pickle.load(f))

JSON数据编码和解码:json
JSON是一种轻量级数据交换格式,一般API返回的数据大多是JSON,XML,如果返回JSON的话,需将获取的数据转换成字典,方便再程序中处理
json与pickle有相似的接口,主要提供两种方法:
1.dumps()对数据进行编码
2.loads()对数据进行解码
示例
将字典类型转换为JSON对象
import json
computer={“主机”:5000,“显示器”:1000,“鼠标”:60,“键盘”:150}
json_obj = json.dumps(computer)
print(type(json_obj))
print(json_obj)
将JSON对象转换为字典
import json
data = json.loads(json_obj)
print(type(data))
import json
computer={"主机":5000,"显示器":1000,"鼠标":60,"键盘":150}
# 编码
json_obj = json.dumps(computer)
print(type(json_obj))
print(computer)
print(json_obj)
print('================================================')
# 解码
data = json.loads(json_obj)
print(type(data))
print(data) # 原先是双引号,解码后是单引号

时间处理
time
time库用于满足简单的时间处理,例如获取当前时间戳、日期、时间、休眠
| 方法 | 描述 |
|---|---|
| time.ctime(seconds) | 返回当前时间时间戳 |
| time.localtime([seconds]) | 当前时间,以stuct_time时间类型返回 |
| time.mktime(tuple) | 将一个stuct_time时间类型转换成时间戳 |
| time.strftime(format[,tuple]) | 将元组时间转换成指定格式。[tuple]不指定默认是当前时间 |
| time.time() | 返回当前时间时间戳 |
| time.sleep(seconds) | 延迟执行给定的秒数 |
import time
print('当前时间戳:',time.time())
print('指定时间格式:',time.strftime("%Y-%m-%d %H:%M:%S"))
print('struct时间类型:',time.localtime())
print('struct时间类型-->指定时间格式:',time.strftime("%Y-%m-%d %H:%M:%S",time.localtime()))
print('==========================将时间戳转换指定格式==========================')
print('思路:时间戳->struct->strftime')
now = time.time()
struct_time = time.localtime(now)
print('struct时间类型-->指定时间格式:',time.strftime("%Y-%m-%d %H:%M:%S",struct_time))
print('==========================休眠==========================')
d1 = time.time()
time.sleep(3)
d2 = time.time()
print(d2-d1)

datetime
datetime库用于处理更复杂的日期和时间
(红色常用些)
| 方法 | 描述 |
|---|---|
| datetime.date | 日期,年月日组成 |
| datetime.datetime | 包括日期和时间 |
| datetime.time | 时间,时分秒及微秒组成 |
| datetime.timedelta | 时间间隔 |
| datetime.tzinfo | 时区信息对象 |
from datetime import date,datetime
print('====================将当前系统时间转换指定格式====================')
now = datetime.now()
print('获取当前时间:',now)
print('指定格式时间:',date.strftime(now,"%Y-%m-%d %H:%M:%S"))
print('====================将时间戳转换指定格式==========================')
import time
date_array = datetime.fromtimestamp(time.time())
print('获取当前时间:',date_array)
print('指定格式时间:',date_array.strftime("%Y-%m-%d %H:%M:%S"))
print('====================获取日期======================================')
from datetime import timedelta
print('获取今天日期:',date.today())
print('获取今天日期2:',date.isoformat(date.today()))
######################################
yesterday = date.today() - timedelta(days=1)
yesterday = date.isoformat(yesterday)
print('获取昨天日期:',yesterday)
######################################
tomorrow = date.today() + timedelta(days=1)
print('获取明天日期:',tomorrow)
tomorrow = date.isoformat(tomorrow)
print('获取明天日期2:',tomorrow)

访问URL:urllib
urllib库用于访问URL
urllib包含以下类:
1.urllib.request 打开和读取URL
2.urllib.error 包含urllib.request抛出的异常
3.urllib.parse用于解析URL
4.urllib.tobotparser 用于解析robots.txt文件
用的最多是urllib.request 类,它定义了适用于在各种复杂情况下打开 URL,例如基本认证、重定向、Cookie、代理等
格式:
from urllib import request
res = request.urlopen(‘http://www.ctnrs.com’)
res是一个HTTPResponse类型的对象,包含以下方法和属性:
| 方法 | 描述 |
|---|---|
| getcode() | 获取相应额HTTP状态码 |
| geturl() | 返回真是URL。有可能URL3xx跳转,那么这个将活的跳转后的URL |
| headers | 返回服务器header信息 |
| read(size=-1) | 返回网页所有内容,size正整数指定读取多少字节 |
| readline(limit=-1) | 读取下一行,size正整数指定读取多少字节 |
| readlines(hint=0,/) | 列表形式返回网页所有内容,以列表形式返回,sizehint正整数指定读取多少字节 |
from urllib import request
res = request.urlopen('http://www.baidu.com')
print('获取状态码:',res.getcode())
print('获取URL:',res.geturl())
print('============================================================')
url = ["http://www.baidu.com","http://www.jd.com"]
for i in url:
res = request.urlopen(i)
if res.getcode() == 200 or res.getcode() == 301:
print(f"{i} 访问成功")
else:
print(f"{i} 访问失败")
print('===================自定义用户代理============================')
print('带有请求头')
url = "http://www.ctnrs.com"
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108Safari/537.36"
header = {"User-Agent": user_agent}
req = request.Request(url, headers=header)
res = request.urlopen(req)
print(res.getcode())
print('===================向接口提交用户数据=========================')
from urllib import parse
url = "http://www.ctnrs.com/login"
post_data = {"username":"user1","password":"123456"}
post_data = parse.urlencode(post_data).encode("utf8") #将字典转为URL查询字符串格式,并转为bytes类型
req = request.Request(url, data=post_data, headers=header)
res = request.urlopen(req)
print(res.read())

总结
以上就是今天学习的内容,本文仅仅简单学习了python的标准库,os\platform\glob\random\subprocess\pickle\json\时间处理(time\datetime)等。
文章出处登录后可见!