文章目录
- 1 KNN算法原理
- 1.1 基本概念
- 1.2 KNN算法原理
- 1.3 实现步骤
- 1.3 KNN算法优缺点
- 2 python手工实现KNN算法
- 2.1 KNN算法预测单个数据
- 2.2 KNN算法预测数据集
- 2.3 sklearn实现KNN算法
1 KNN算法原理
1.1 基本概念
KNN(K-NearestNeighbor)即K近邻算法,是数据挖掘分类技术中最简单的方法之一。所谓K近邻,就是K个最近的邻居的意思,说的是每个样本都可以用它最接近的K个邻近值来代表。
1.2 KNN算法原理
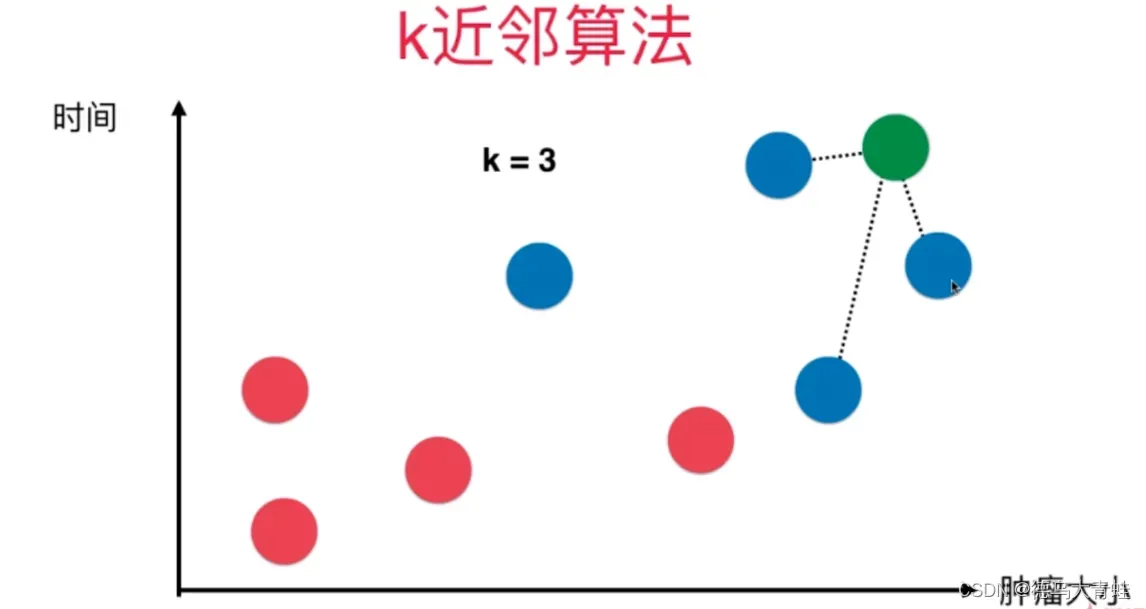
假设特征空间有8个样本点,其中红色点为良性肿瘤,蓝色点为恶性肿瘤,现在要预测绿色点是良性肿瘤还是恶性肿瘤,我们需要计算出绿色点到所有其他样本点的距离,选择出距离最小的K个点,对K个点所属的类别进行比较,根据少数服从多数的原则,将测试样本点归入在K个点中占比最高的那一类。计算距离方法一般采用欧拉距离公式: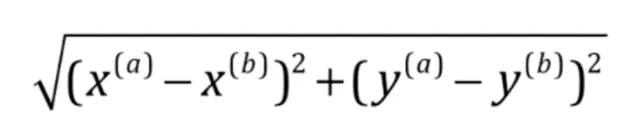
n维特征空间欧式距离计算公式
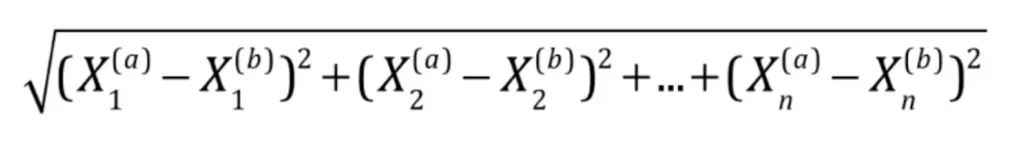
1.3 实现步骤
总体来说,KNN分类算法包括以下4个步骤:
①准备数据,对数据进行预处理
②计算测试样本点(也就是待分类点)到其他每个样本点的距离 。
③对每个距离进行排序,然后选择出距离最小的K个点。
④对K个点所属的类别进行比较,根据少数服从多数的原则,将测试样本点归入在K个点中占比最高的那一类。
1.3 KNN算法优缺点
优点:
1)思想简单、效果强大。
2)天然可解决多分类问题。
2)重新训练的代价较低(类别体系的变化和训练集的变化,在Web环境和电子商务应用中是很常见的)。
3)计算时间和空间线性于训练集的规模(在一些场合不算太大)。
缺点:
1)效率低下,如果训练集有m个样本,n个特征,则预测每一个新的数据,计算复杂度O(m*n)
2)高度数据相关,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数;对数据的局部结构比较敏感。如果查询点是位于训练集较密集的区域,那预测相对比其他稀疏集来说更准确。
3)预测结果不具有可解释性,只是找到了预测样本距离最近的样本点,不知道为什么属于预测类别。
4)维数灾难:随着维度增加,看似距离很近的2个点距离越来越大

2 python手工实现KNN算法
2.1 KNN算法预测单个数据
import matplotlib.pyplot as plt
import numpy as np
#创建样本数据
x_data = [[1,2],[3,7],[4,3],[2,5],[5,1],[8,2]]
x_data = np.array(x_data)
y_data = [1,1,0,1,0,0]
y_data = np.array(y_data)
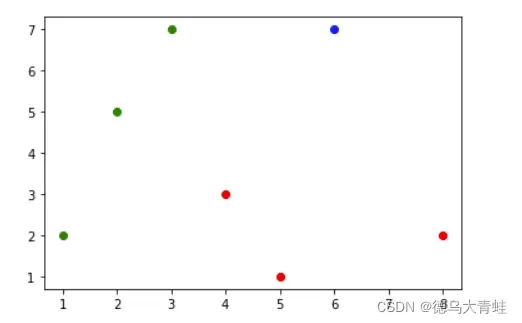
样本数据分布情况
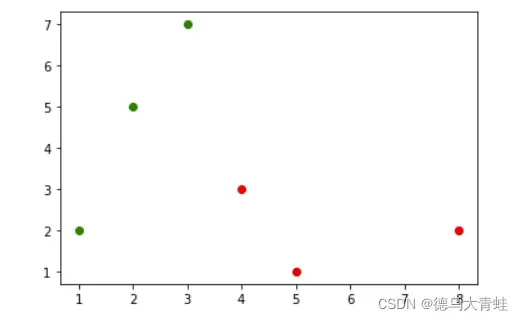
假设测试数据为(6,7),在特征空间分布情况如下
from math import sqrt
#计算测试数据到所有样本点距离
distance = []
for data in x_data:
d = sqrt(np.sum((data-x_test)**2))
distance.append(d)
nearest = np.argsort(distance)
#最近的3个样本点
top_k = y_data[nearest[:3]]
#k个样本点投票最多的
from collections import Counter
y_predict = Counter(top_k).most_common(1)[0][0]
2.2 KNN算法预测数据集
import numpy as np
from collections import Counter
from math import sqrt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
class KNNClassifier:
# 初始化KNN分类器,并对k赋值
def __init__(self, k):
self.k = k
self.x_train = None
self.y_train = None
# 根据训练数据集x_train和y_train训练kNN分类器
def fit(self, x_train, y_train):
self.x_train = x_train
self.y_train = y_train
return self
# 给定单个待预测数据x,返回x的预测结果值
def __predict(self, x_test):
distance = [sqrt(np.sum((data - x_test) ** 2)) for data in self.x_train]
aa = np.argsort(distance)
top_k = self.y_train[aa[:self.k]]
votes = Counter(top_k).most_common(1)[0][0]
return votes
# 给定待预测数据集X_predict,返回表示X_predict的结果向量
def predict(self, X_test):
y_predict = [self.__predict(x) for x in X_test]
return y_predict
def score(self, y_true, y_predict):
percent = np.sum(y_true == y_predict) / len(y_true)
return percent
iris = load_iris()
x_data = iris.data
y_data = iris.target
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.2)
knn = KNNClassifier(k=3)
knn.fit(x_train, y_train)
y_predict = knn.predict(x_test)
percent = knn.sores(y_test, y_predict)
2.3 sklearn实现KNN算法
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris = load_iris()
x_data = iris.data
y_data = iris.target
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.2)
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(x_train, y_train)
y_predict = knn.predict(x_test)
percent = knn.score(x_test,y_test)
文章出处登录后可见!