Q-learning基本思想
Q-learning是一种value-based算法,它学习一个最优动作价值函数,那么能够获得最优策略
Q-learning算法的基本思想是,鼓励最优动作价值函数逐渐接近TD Target
,最优动作价值函数
全部基于预测,而TD Target
部分基于观测,比最优动作价值函数
更靠谱些
下面推导TD Target

接下来,分别介绍这两种方法。
Q-Table
Q-Table学习最优动作价值函数的基本思想是,建立一张Q表,更新Q值的方法是
把代入,进一步得到
其中记作
,是TD error,这里没有将全部的TD error用于更新
,而是乘以了一个系数
,有点学习率的意味,是为了避免陷入局部最优解
更新式子中,表示
现实,
表示
估计,这里很奇妙的地方是,
现实里边也包含了一个对下一步的最大估计,将对下一步衰减的最大估计和当前所获得的奖励当成这一步的现实,是不是非常迷人
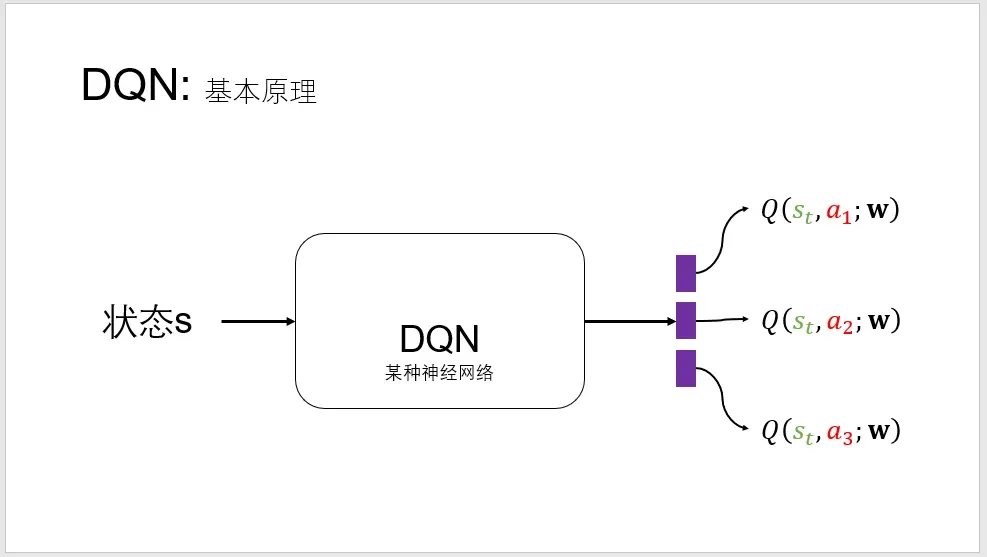
DQN中的Q-learning
DQN的基本思想是,学习一个神经网络近似最优动作价值函数
,示意图如下,神经网络的输入是状态
,输出是对动作状态的打分
Q&A
(1)on-policy和off-policy
Q-learning算法是一种off-policy,它产生动作的策略(动作策略)和评估改进的策略(目标策略)不是同一个策略

(2)TD/蒙特卡洛/动态规划
Q-learning采用了时间差分算法(Temporal-Difference,TD),它的基本思想是,在更新当前动作价值函数时,用到了下一个状态的动作价值函数
我关于TD/蒙特卡洛/动态规划的理解并不深刻,可以看看下面两篇参考资料:
https://zhuanlan.zhihu.com/p/25913410
https://www.jianshu.com/p/0bfeb09b7d5f
(3)有模型/无模型学习方法
Q-learning算法是一种无模型(model-free)学习方法,它无需提前获取完备的模型,主要是无法获取状态转移概率、奖励函数模型等,这更加符合现实应用,那么智能体不断与环境交互一定先验信息后再去探索学习
后记
强化学习涉及超多概念名词,它们很相似容易混淆,例如动作价值函数/策略价值函数、蒙特卡洛/动态规划、策略评估、on-policy/off-policy等等,让初学者眼花缭乱,我的建议是不要被名字表面蒙蔽,多刷几遍教学视频,脑子对以上名词留下印象而不必强求区分概念,然后动手写伪代码、画算法框图、写代码操作一种算法例子,例如Q-learning,动手实践后对区分概念印象更深。
推荐的教学视频:
(1)王树森讲解强化学习教程,它的特点是带有一点点数学理论推导,适合进阶
https://www.bilibili.com/video/BV12o4y197US/?p=9&vd_source=1565223f5f03f44f5674538ab582448c
(2)莫烦Python讲解的强化学习教程,很经典的人工智能教程了,有点科普,适合初学者了解强化学习的思想和概念
(3)李宏毅讲解的强化学习教程,很详细的数学理论,适合预期深入探索强化学习原理的学习者
(4)Sutton的强化学习著作,看过这部经典之后会觉得前面的教程有点快餐化的味道
我的建议是从适合初学者教程开始了解强化学习基本概念,培养一些兴趣之后逐步深入,一点点慢慢积累,遇到不理解的概念不要怕,间隔时间的反复看。
我在最初了解强化学习的时候就陷入了细节困境,琢磨不清楚怎么定义动作/价值/策略/状态/奖励,也困惑怎样设置初始值,然而这些不是强化学习的精髓和算法核心,我们可以默认理解了概念,看看后面怎么使用它们,初始化问题可以默认随机设置,看看后面有没有更好的设置方法,而把更多的注意力放在强化学习的算法迭代、设计思路上。
欢迎小伙伴们交流学习体会哟,欢迎小伙伴们批评指正、点赞、收藏、转发呐
文章出处登录后可见!