一.数学符号解释

2.Attention and Self-Attention
注意力是神经网络中的一种机制,模型可以通过有选择地关注一组给定的数据来学习做出预测。注意力的数量由学习的权重量化,因此输出通常形成为加权平均值。
自注意是一种注意机制,其中模型使用对同一样本的观察的其他观察部分对数据样本的一部分进行预测。从概念上讲,它感觉与非本地手段非常相似。还要注意,自我注意是排列不变的;换句话说,它是对集合的运算。
有各种形式的注意力,Transformer依赖于缩放的点积关注:给定一个查询矩阵Q,键矩阵K和值矩阵V,则输出是值向量的加权和,其中分配给每个值槽的权重由具有相应键的查询的点积确定:
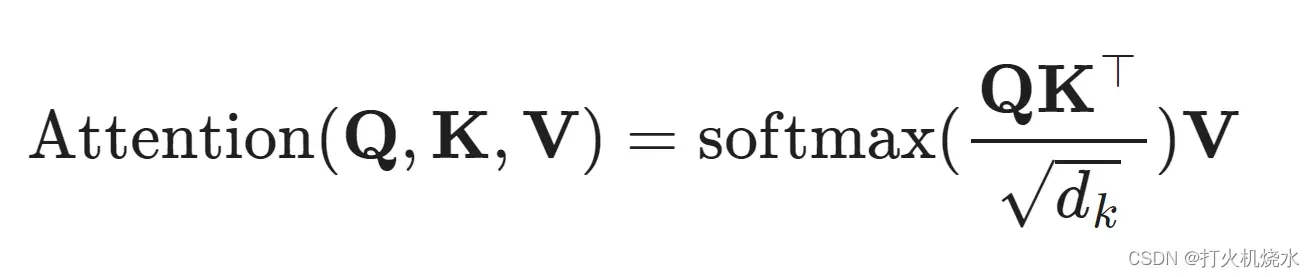
对于查询和关键向量(查询和键矩阵中的行向量),我们有一个标量分数:
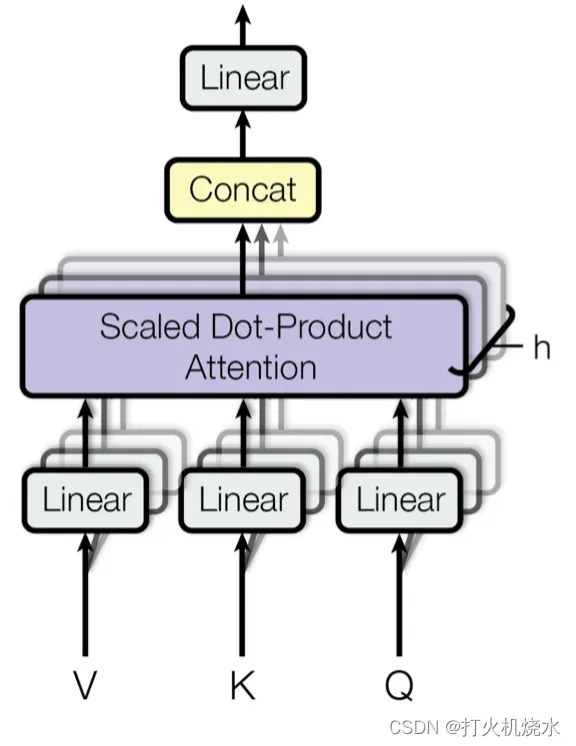
3.Multi-Head Self-Attention
多头自注意力模块是Transformer中的关键组件。多头机制不是只计算一次注意力,而是将输入分成更小的块,然后并行计算每个子空间上的缩放点积注意力。独立的注意力输出被简单地串联并线性转换为预期的维度。
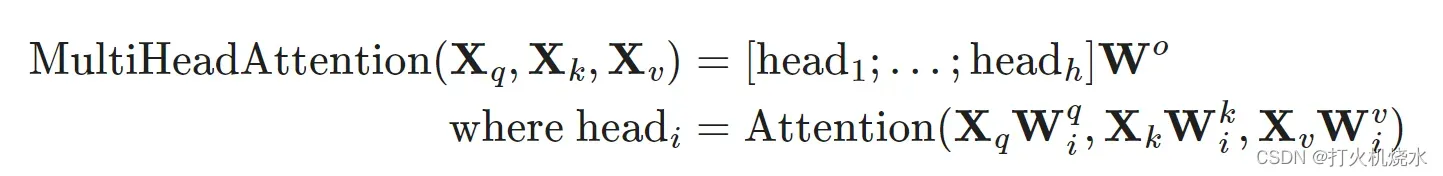
 # 4.Transformer
# 4.Transformer
Transformer模型具有编码器- 解码器体系结构,通常用于许多 NMT 模型。后来,仅解码器的 Transformer 被证明在语言建模任务中实现了出色的性能,例如在 GPT 和 BERT 中。
编码器-解码器架构
编码器生成基于注意力的表示,能够从大型上下文中定位特定信息。它由6个身份模块的堆栈组成,每个模块包含两个子模块,一个多头自注意层和一个按点连接的全连接前馈网络。通过点对点,这意味着它对序列中的每个元素应用相同的线性变换(具有相同的权重)。这也可以看作是过滤器尺寸为1的卷积层。每个子模块都有一个残差连接和层规范化。所有子模块输出相同维度的数据.
变压器解码器的功能是从编码表示中检索信息。该架构与编码器非常相似,不同之处在于解码器包含两个多头注意力子模块,而不是每个相同的重复模块中一个。第一个多头注意力子模块被屏蔽,以防止职位关注未来。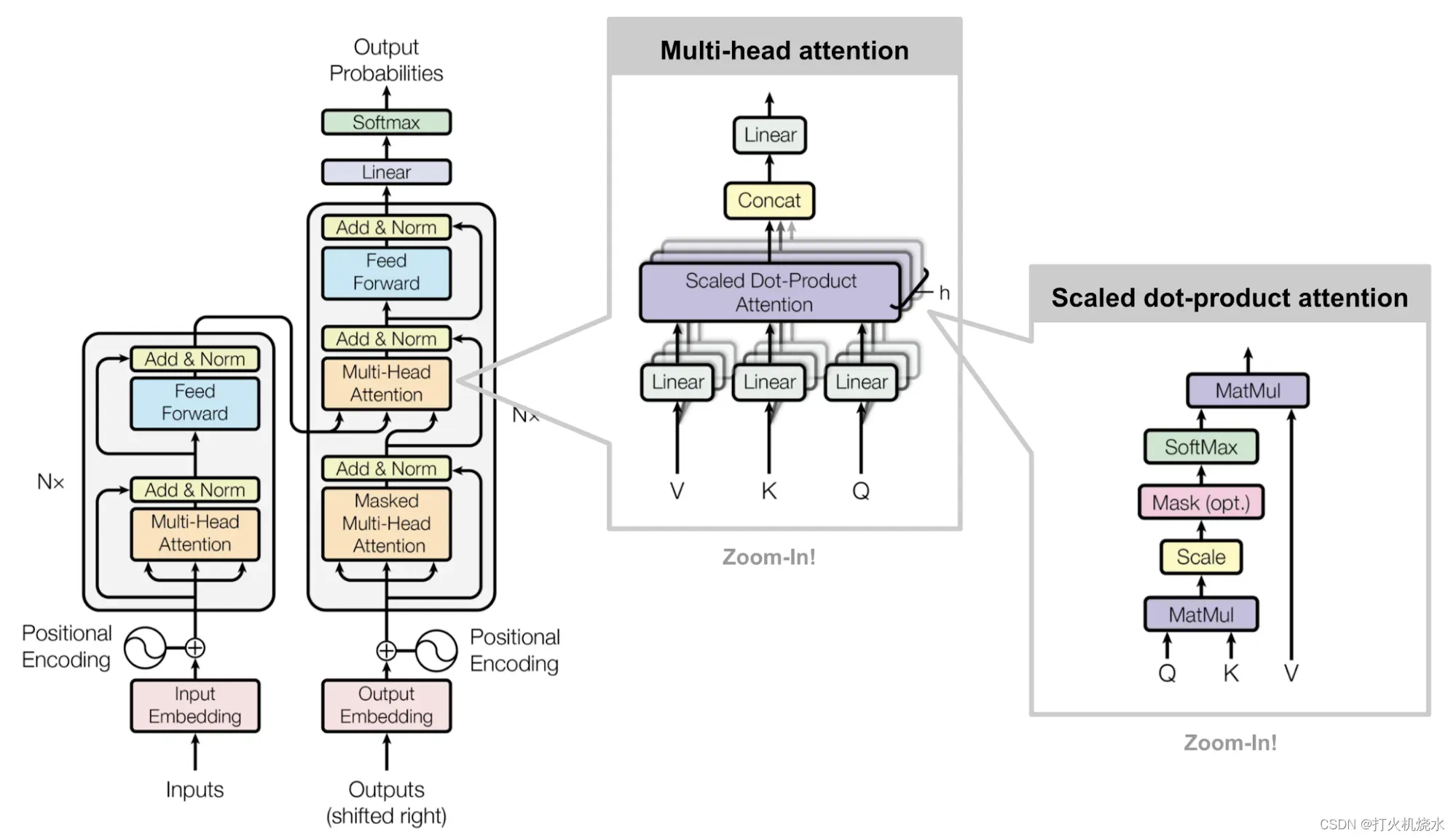
文章出处登录后可见!