Diffusion Model(扩散模型 )对标的是生成对抗网络(GAN),只要GAN能干的事它基本都能干。之前用GAN网络来实现一些图片生成任务其实效果并不是很理想,而且往往训练很不稳定。但是换成Diffusion Model后生成的图片则非常逼真,也明显感觉到每一轮训练的结果相比之前都更加优异,也即训练更加稳定。
本文将用通俗的语言和公式为大家介绍Diffusion Model,并且结合公式为大家梳理Diffusion Model的代码,探究其是如何通过代码实现的。
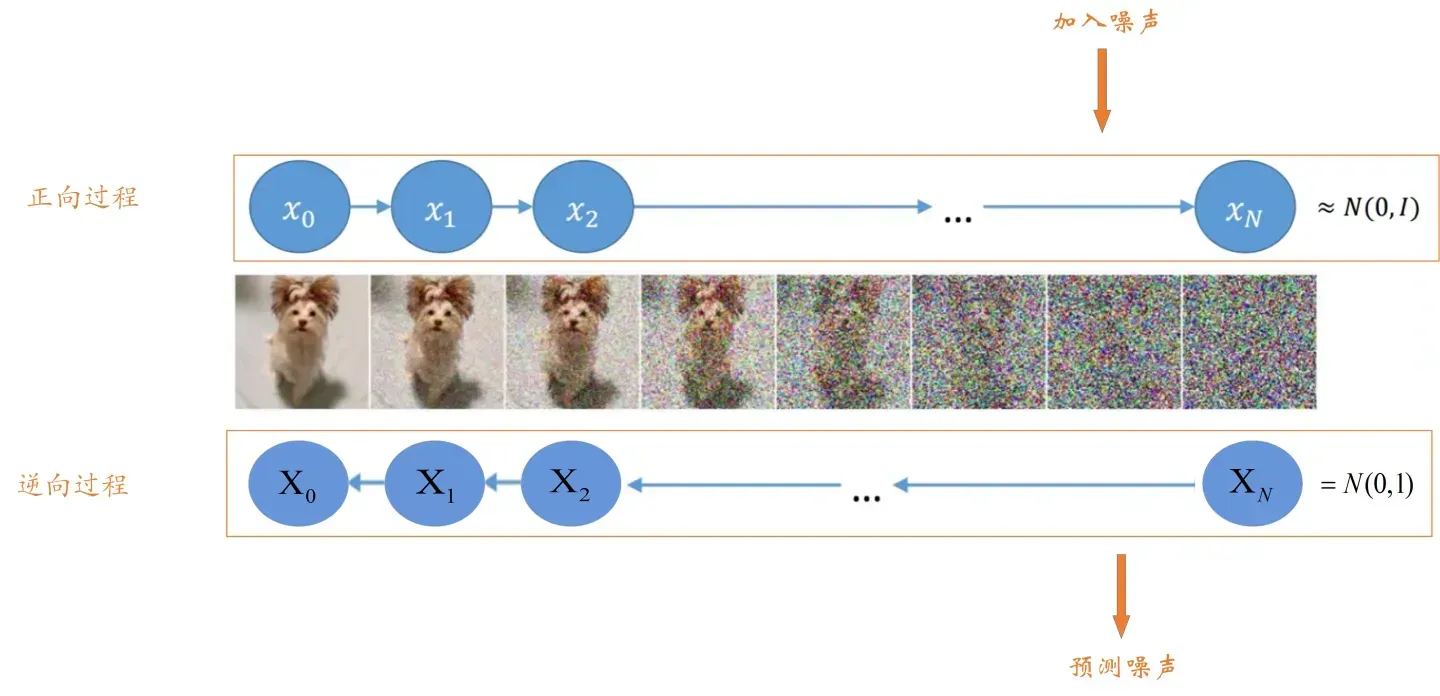
整体思路
Diffusion Model的整体思路如下图所示:
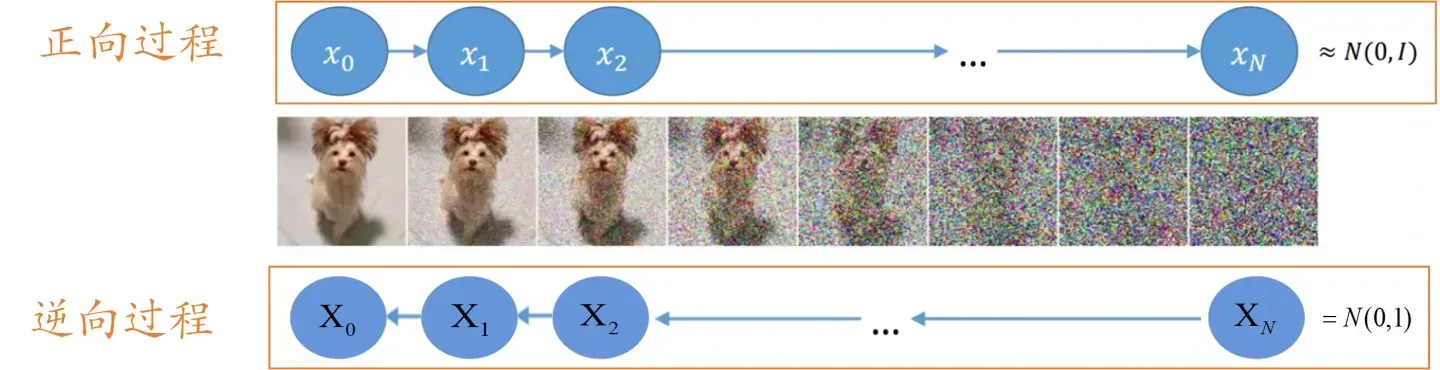
其主要分为正向过程和逆向过程,正向过程类似于编码,逆向过程类似于解码。
- 正向过程
首先,对于一张原始图片,我们给
。【注意:这里必须要加高斯噪声喔,因为高斯噪声服从高斯分布,后面的一些运算需要用到高斯分布的一些特性】」接着我们会在
- 逆向过程
首先,我们会随机生成一个服从高斯分布的噪声图片,然后一步一步的减少噪声直到生成预期图片。逆向过程大家先有这样的一个认识就好,具体细节稍后介绍。
实施细节
这一部分为大家介绍一下Diffusion Model正向过程和逆向过程的细节,主要通过推导一些公式来表示加噪前后图像间的关系。
正向过程
在整体思路部分我们已经知道了正向过程其实就是一个不断加噪的过程,于是我们考虑能不能用一些公式表示出加噪前后图像的关系呢。我想让大家先思考一下后一时刻的图像受哪些因素影响呢,更具体的说,比如由哪些量所决定呢?我想这个问题很简单,即
是由
和所加的噪声共同决定的,也就是说后一时刻的图像主要由两个量决定,其一是上一时刻图像,其二是所加噪声量。明白了这点,我们就可以用一个公式来表示
时刻和
时刻两个图像的关系,如下:
——公式1
其中,表示
时刻的图像,
表示
时刻图像,
表示添加的高斯噪声,其服从N(0,1)分布。【注:N(0,1)表示标准高斯分布,其方差为1,均值为0】目前你可以看出
和
、
都有关系,这和我们前文所述
后一时刻的图像由前一时刻图像和噪声决定相符合。这个公式前面的和
表示这两个量的权重大小,它们的平方和为1。
我想你已经明白了公式1,但是你可能对和
的理解还存在一些疑惑,如为什么要设置这样的权重?这个权重的设置是我们预先设定的吗? 其实,
还和另外一个量
有关,关系式如下:
——公式2
其中,是预先给定的值,它是一个随时刻不断增大的值,论文中它的范围为[0.0001,0.02]。既然
越来越大,则
越来越小,
越来越小,1−
越来越大。现在我们在来考虑公式1,
的权重
随着时刻增加越来越大,表明我们所加的高斯噪声越来越多,这和我们整体思路部分所述是一致的,即越往后所加的噪声越多。
现在,我们已经得到了时刻和
时刻两个图像的关系,但是
时刻的图像是未知的。【注:只有
阶段图像是已知的,即原图】我们需要再由
时刻推导出
时刻图像,然后再由
时刻推导出
时刻图像,依此类推,直到由
时刻推导出
时刻图像即可。既然这样我们不妨先试试
时刻图像和
时刻图像的关系,如下:
——公式3
这个公式就是公式1的一个类推公式,此时我们将公式3代入公式1中得:
——公式4
这个公式4大家能理解吗? 我觉得大家应该对最后一个等式存在疑惑,也即怎么等于
?其实这个用到了高斯分布的一些知识,这部分见附录部分。看了附录中高斯分布的相关性质,我想这里你应该能够理解了,我在帮大家整理一下,如下图所示:
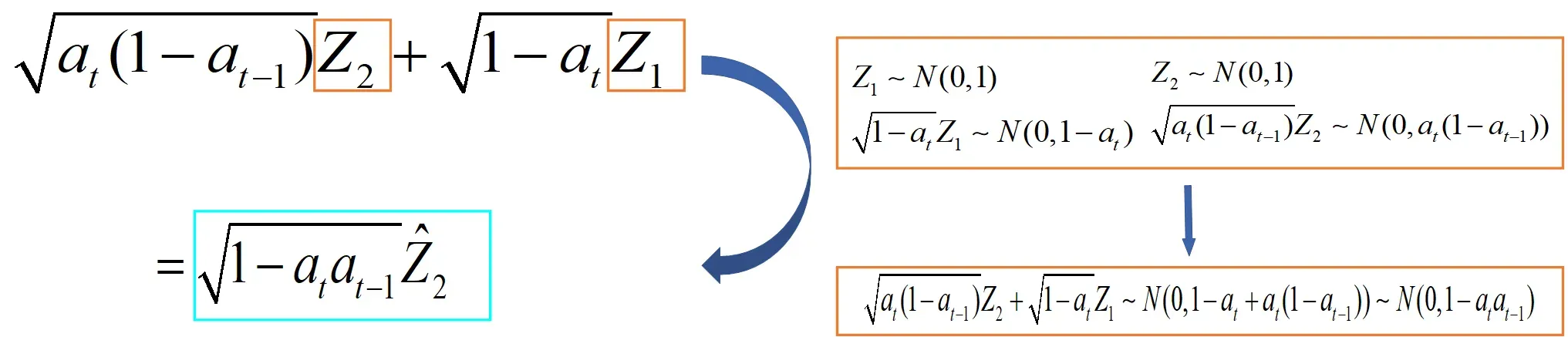
这下对于公式4的内容都明白了叭。注意这里的也是服从
(0,1)高斯分布的,
服从
。我们来看看公式4得到了什么——其得到了
时刻图像和
时刻图像的关系。按照我们先前的理解,我们再列出
时刻图像和
时刻图像的关系,如下:
——公式5
同理,我们将公式5代入到公式4中,得到时刻图像和
时刻图像的关系,公式如下:
——公式6
公式5我没有带大家一步步的计算了,只写出了最终结果,大家可以自己算一算,非常简单,也只用到了高斯分布的相关性质。注意上述的同样服从
(0,1)的高斯分布。那么公式6就得到了
时刻图像和
时刻图像的关系,我们如果这么一直计算下去,就会得到
时刻图像和
时刻图像的关系。但是这样的推导貌似很漫长,随着向后推导你会发现这种推导是有规律的。我们可以来比较一下公式4和公式6的结果,你会发现很明显的规律,这里我就根据这个规律直接写出
时刻图像和
时刻图像的关系,公式如下:
——公式7
其中表示累乘操作,即
,
样服从
(0,1)的高斯分布。【这里\hat{Z}_t只是一个表示,只要
服从标准高斯分布即可,用什么表示都行】这个公式7就是整个正向过程的核心公式,「其表示
时刻的图像可以由
时刻的图像和一个标准高斯噪声表示」,大家需要牢记这个公式,在后文以及代码中会用到。
逆向过程
逆向过程是将高斯噪声还原为预期图片的过程。先来看看我们已知条件有什么,其实就一个时刻的高斯噪声。我们希望将
时刻的高斯噪声变成
时刻的图像,是很难一步到位的,因此我们思考能不能和正向过程一样,先考虑
时刻图像和
时刻的关系,然后一步步向前推导得出结论呢。好的,思路有了,那就先来想想如何由已知的
时刻图像得到
时刻图像。
这里我们需要利用正向过程中的结论,我们在正向过程中可以由时刻图像得到
时刻图像,然后利用贝叶斯公式即可求解。贝叶斯公式的表达式如下:
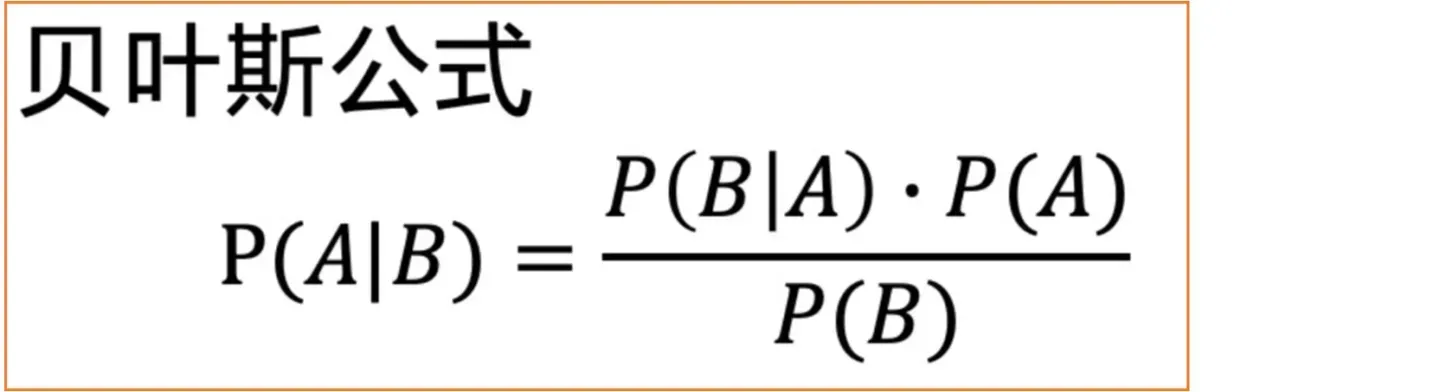
那么我们将利用贝叶斯公式来求时刻图像,公式如下:
——公式8
公式8中我们可以求得,就是刚刚正向过程求的嘛。 但
和
是未知的。又由公式7可知,可由
得到每一时刻的图像,那当然可以得到
和
时刻的图像,故将公式8加一个
作为已知条件,将公式8变成公式9,如下:
——公式9
现在可以发现公式9右边3项都是可以算的,我们列出它们的公式和对应的分布,如下图所示:
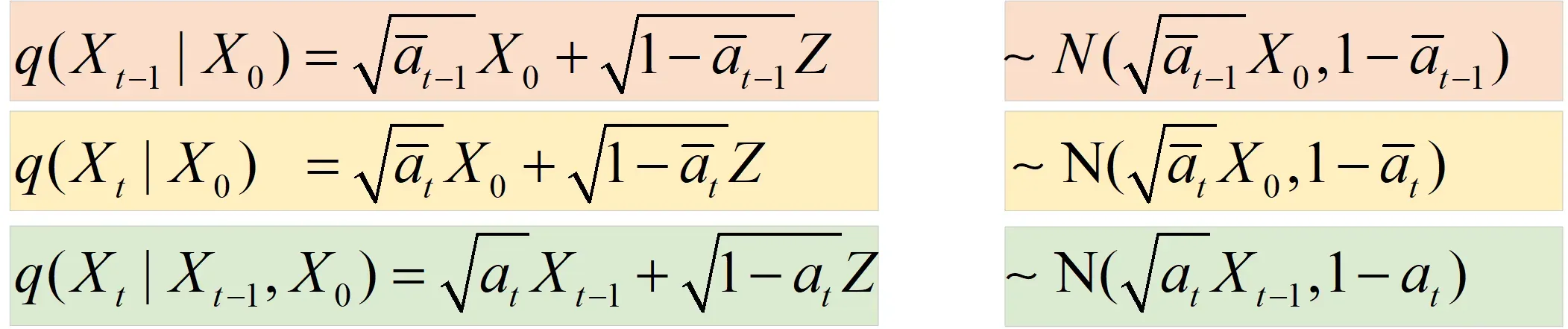
知道了公式9等式右边3项服从的分布,我们就可以计算出等式左边的。这个计算很简单,没有什么技巧,就是纯算。在附录->高斯分布性质部分我们知道了高斯分布的表达式为:
。那么我们只需要求出公式9等式右边3个高斯分布表达式,然后进行乘除运算即可求得
。
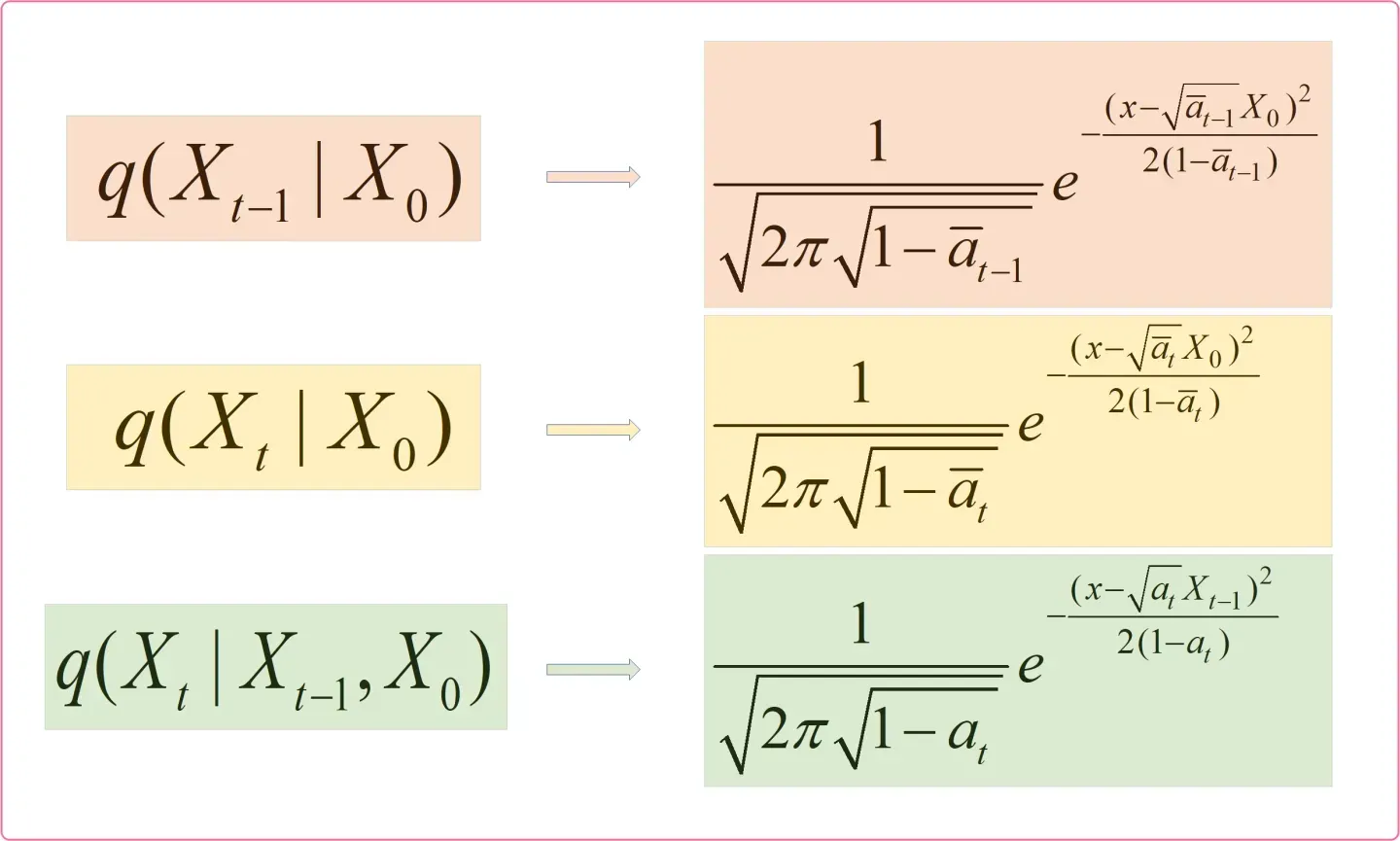
上图为等式右边三个高斯分布表达式,这个结果怎么得的大家应该都知道,就是把各自的均值和方差代入高斯分布表达式即可。现我们只需对上述三个式子进行对应乘除运算即可,如下图所示:
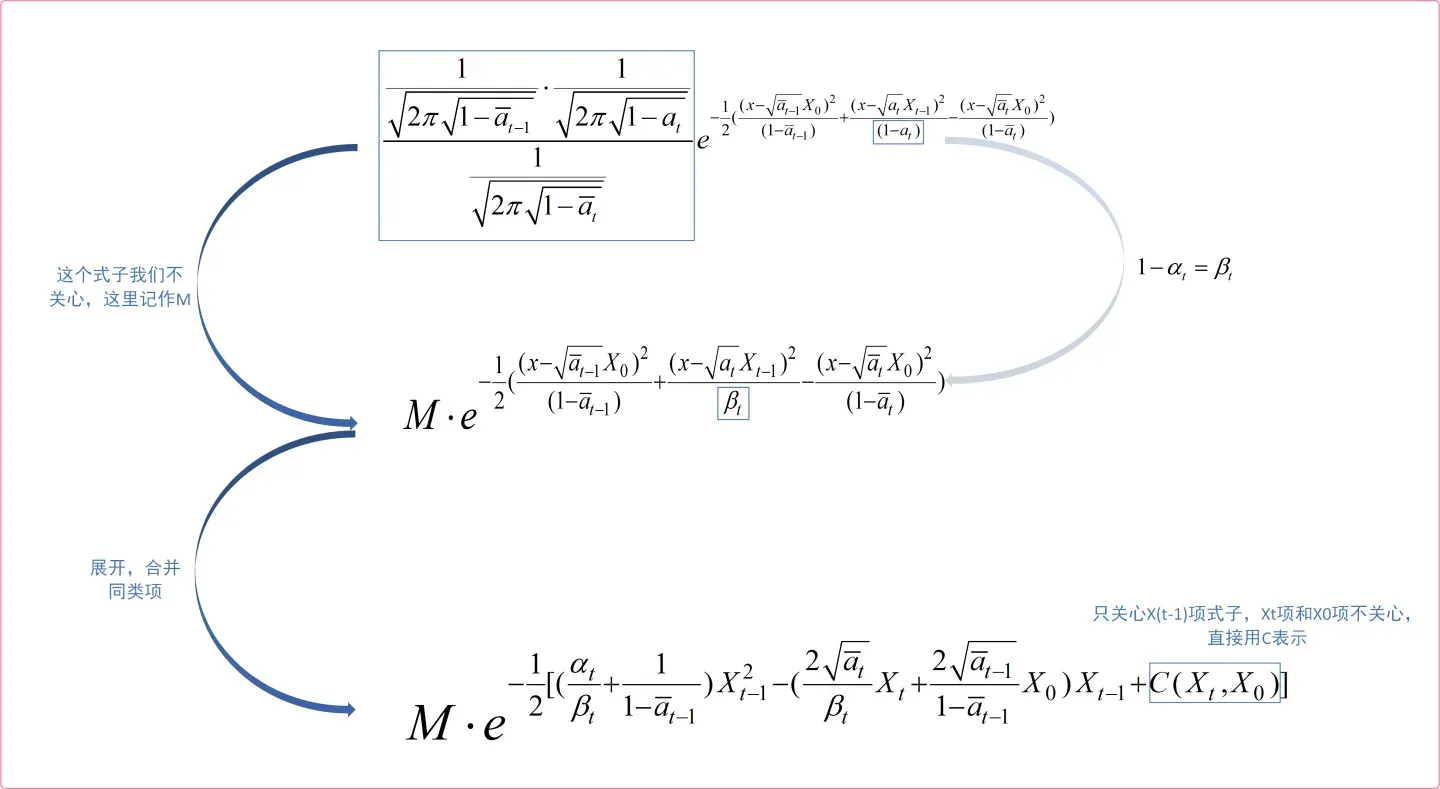
好了,我们上图中得到了式子其实就是
的表达式了。知道了这个表达式有什么用呢,主要是求出均值和方差。首先我们应该知道对高斯分布进行乘除运算的结果仍然是高斯分布,也就是说
服从高斯分布,那么他的表达式就为
,我们对比两个表达式,就可以计算出
和
,如下图所示:
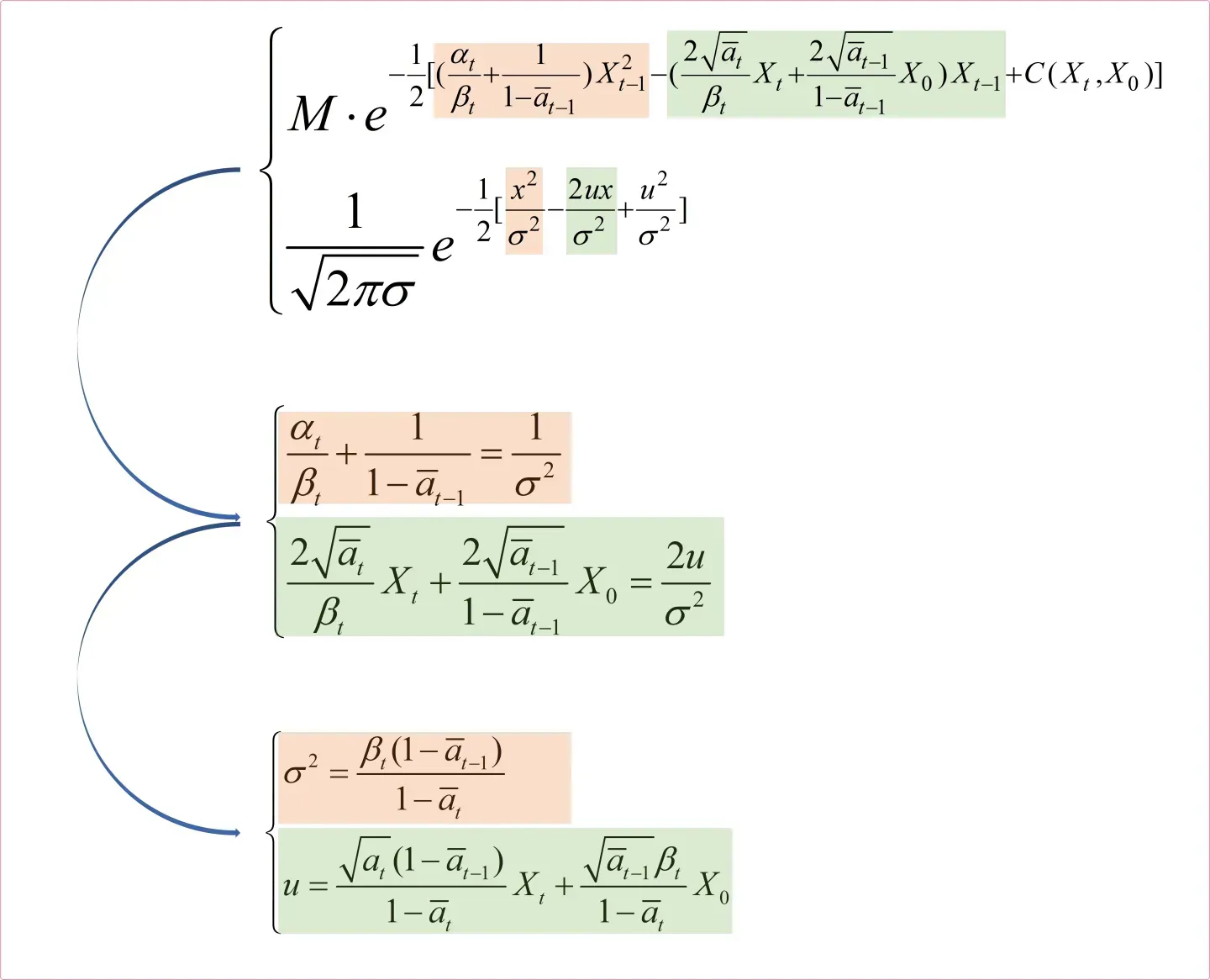
现在我们有了均值和方差
就可以求出
了,也就是求得了
时刻的图像。推导到这里不知道大家听懂了多少呢?其实你动动小手来算一算你会发现它还是很简单的。但是不知道大家有没有发现一个问题,我们刚刚求得的最终结果
和
中含义一个
,这个
是什么啊,他是我们最后想要的结果,现在怎么当成已知量了呢?这一块确实有点奇怪,我们先来看看我们从哪里引入了
。往上翻翻你会发现使用贝叶斯公式时我们利用了正向过程中推导的公式7来表示
和
,但是现在看来那个地方会引入一个新的未知量
,该怎么办呢?这时我们考虑用公式7来反向估计
,即反解公式7得出
的表达式,如下:
——公式10
得到的估计值,此时将公式10代入到上图的
中,计算后得到最后估计的
,表达式如下:
——公式11
好了,现在在整理一下−1时刻图像的 均值
和方差
,如下图所示:
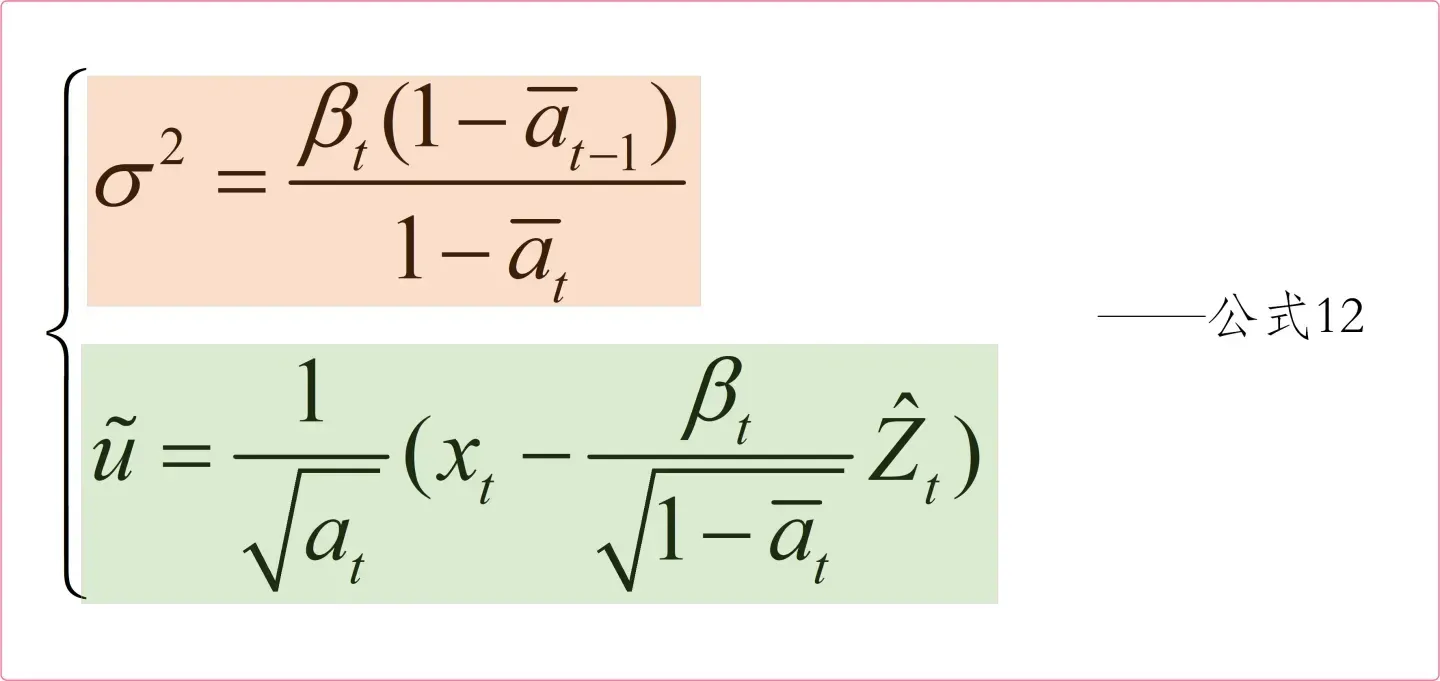
有了公式12我们就可以估计出时刻的图像了,接着就可以一步步求出
、
、
、
的图像啦。
原理小结
这一小节原理详解部分就为大家介绍到这里了,大家听懂了多少呢。相信你阅读了此部分后,对Diffusion Model的原理其实已经有了哥大概的解了,但是肯定还有一些疑惑的地方,不用担心,代码部分会进一步帮助大家。
Diffusion Model源码解析
代码下载及使用
本次代码下载地址:Diffusion Model代码
先来说说代码的使用,代码包含两个项目,一个的ddpm.py,另一个是ddpm_condition.py。大家可以理解为ddpm.py是最简单的扩散模型,ddpm_condition.py是ddpm.py的优化。本节会以ddpm.py为大家讲解。代码使用起来非常简单,首先在ddpm.py文件中指定数据集路径,即设置dataset_path的值,然后我们就可以运行代码了。需要注意的是,如果你使用的是CPU的话,那么你可能还需要修改一下代码中的device参数。
这里来简单说说ddpm的意思,英文全称为Denoising Diffusion Probabilistic Model,中文译为去噪扩散概率模型。
代码流程图
这里我们直接来看论文中给的流程图好了,如下:

这个图表示整个算法的流程分为了训练阶段(Training)和采样阶段(Sampling)。
- Training
众所周知,训练我们需要有真实值和预测值,那么对于本例的真实值和预测值是什么呢?真实值是我们输入的图片,预测值是我们输出的图片吗?其实不是,对于本例来说,真实值和预测值都是噪声,同样拿下图为大家做个示范。
我们在正向过程中加入的噪声其实都是已知的,是可以作为真实值的。而逆向过程相当于一个去噪过程,我们用一个模型来预测噪声,让正向过程每一步加入的噪声和逆向过程对应步骤预测的噪声尽可能一致,而逆向过程预测噪声的方式就是丢入模型训练,其实就是Training中的第五步。
- Sampling
知道了训练过程,采样过程就很简单了,其实采样过程就对应我们理论部分介绍的逆向过程,由一个高斯噪声一步步向前迭代,最终得到时刻图像。
代码解析
首先,按照我们理论部分应该有一个正向过程,其最重要的就是最后得出的公式7,如下:
那么我们在代码中看一看是如何利用这个公式7的,代码如下:
def noise_images(self, x, t):
sqrt_alpha_hat = torch.sqrt(self.alpha_hat[t])[:, None, None, None]
sqrt_one_minus_alpha_hat = torch.sqrt(1 - self.alpha_hat[t])[:, None, None, None]
Ɛ = torch.randn_like(x)
return sqrt_alpha_hat * x + sqrt_one_minus_alpha_hat * Ɛ, Ɛ
Ɛ为随机的标准高斯分布,其实也就是真实值。大家可以看出,上式的返回值sqrt_alpha_hat * x + sqrt_one_minus_alpha_hat其实就表示公式7。【注:这个代码我省略了很多细节,我只把关键的代码展示给大家看,要想完全明白,还需要大家记住调试调试了】
接着我们就通过一个模型预测噪声,如下:
predicted_noise = model(x_t, t)
model的结构很简单,就是一个Unet结构,然后里面嵌套了几个Transformer机制,我就不带大家跳进去慢慢看了。现在有了预测值,也有了真实值Ɛ【返回后Ɛ用noise表示】,就可以计算他们的损失并不断迭代了。
loss = mse(noise, predicted_noise)
optimizer.zero_grad()
loss.backward()
optimizer.step()
上述其实就是训练过程的大体结构,我省略了很多,现在来看看采样过程的代码。
def sample(self, model, n):
logging.info(f"Sampling {n} new images....")
model.eval()
with torch.no_grad():
x = torch.randn((n, 3, self.img_size, self.img_size)).to(self.device)
# for i in tqdm(reversed(range(1, self.noise_steps)), position=0):
for i in tqdm(reversed(range(1, 5)), position=0):
t = (torch.ones(n) * i).long().to(self.device)
predicted_noise = model(x, t)
alpha = self.alpha[t][:, None, None, None]
alpha_hat = self.alpha_hat[t][:, None, None, None]
beta = self.beta[t][:, None, None, None]
if i > 1:
noise = torch.randn_like(x)
else:
noise = torch.zeros_like(x)
x = 1 / torch.sqrt(alpha) * (x - ((1 - alpha) / (torch.sqrt(1 - alpha_hat))) * predicted_noise) + torch.sqrt(beta) * noise
model.train()
x = (x.clamp(-1, 1) + 1) / 2
x = (x * 255).type(torch.uint8)
return x
上述代码关键的就是 x = 1 / torch.sqrt(alpha) * (x - ((1 - alpha) / (torch.sqrt(1 - alpha_hat))) * predicted_noise) + torch.sqrt(beta) * noise这个公式,其对应着代码流程图中Sampling阶段中的第4步。需要注意一下这里的跟方差这个公式给的是
,但其实在我们理论计算时为
,这里做了近似处理计算,即
和
都是非常小且近似0的数,故把
当成1计算,这里注意一下就好。
代码小结
可以看出,这一部分所用的篇幅很少,只列出了关键的部分,很多细节需要大家自己感悟。比如代码中时刻T的用法,其实是较难理解的,代码中将其作为正余弦位置编码处理。如果你对位置编码不熟悉,可以看一下这篇文章,有详细的介绍位置编码。
附录
高斯分布性质
高斯分布又称正态分布,其表达式为:
其中为均值,
为方差。若随机变量服
从正态均值为
,方差为
的高斯分布,一般记为
。此外,有一点大家需要知道,如果我们知道一个随机变量服从高斯分布,且知道他们的均值和方差,那么我们就能写出该随机变量的表达式。
高斯分布还有一些非常好的性质,现举一些例子帮助大家理解。
- 若
,则
。
- 若
,则
。
参考内容:Diffusion Model原理详解及源码解析 – 知乎 (zhihu.com)
文章出处登录后可见!