一、如何使用bert度量句子的相似度
目前业内常用的度量文本相似性的做法有两种,效果差不多:
- 把文本A和文本B拼接起来,进行二分类任务,分类标签为相似或不相似,最后可以输出相似和不相似的概率。github有该方法的具体实现:https://github.com/Brokenwind/BertSimilarity
- 直接用文本A和文本B在预训练模型上度量相似性,得到的是两个tensor,计算余弦相似度即可。这样可以得到一个数值,来衡量相似性。
二、sbert是啥意思
挛生网络Siamese network(后简称SBERT),其中Siamese意为“连体人”,即两人共用部分器官。SBERT模型的子网络都使用BERT模型,且两个BERT模型共享参数。当对比A,B两个句子相似度时,它们分别输入BERT网络,输出是两组表征句子的向量,然后计算二者的相似度;利用该原理还可以使用向量聚类,实现无监督学习任务。
三、如何通过bert获取句子向量:
由于输入的Sentence长度不一,而我们希望得到统一长度的Embeding,所以当Sentence从BERT输出后我们需要执行pooling操作。实验中采取了三种pooling策略做对比:
3. CLS向量策略,直接采用CLS位置的输出向量代表整个句子的向量表示
4. MEAN策略,计算各个token输出向量的平均值代表句子向量
5. MAX策略,取所有输出向量各个维度的最大值代表句子向量。
作者做了大量的实验,比较三种求句子向量策略的好坏,认为平均池化策略最优,并且在多个数据集上进行了效果验证。虽然效果没有bert输入两句话的效果好,但是比其他方法还是要好的,并且速度很快。
三个策略的实验对比效果如下:
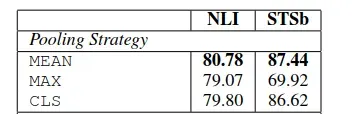
可见三个策略中,MEAN策略是效果最好的,所以后面实验默认采用的是MEAN策略。
四、如何训练sbert
SBERT(SNLI) :用SNLI训练集进行监督训练SBERT,因为SNLI是三元组(anchor, positive, negative)的形式,所以这里损失函数为TripleLoss
SBERT(STS-B):用STS-B训练集进行监督训练SBERT,因为把STS-B标签的0·5映射为相似度0, 0.2, 0.4, 0.6, 0.8, 1。损失函数采用与评价指标一样的CosineSimilarLoss
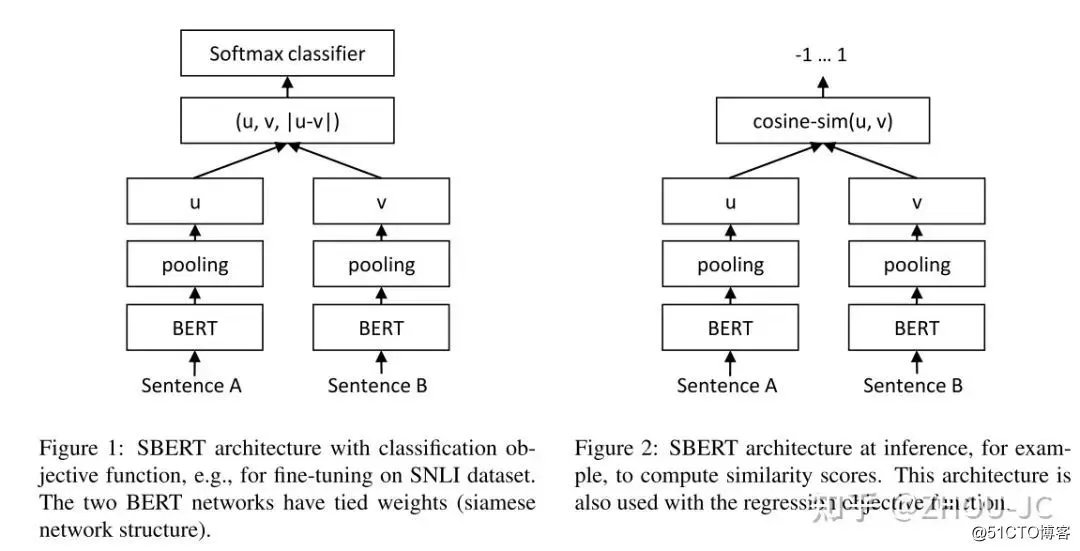 其中左图是训练的模型,右图是训练好模型之后利用句向量计算2个句子之间的相似度。u,v分别表示输入的2个句子的向量表示,|u-v|表示取两个向量的绝对值,(u, v, |u-v|)表示将三个向量在-1维度进行拼接,因此得到的向量的维度为 3*d,d表示隐层维度。
其中左图是训练的模型,右图是训练好模型之后利用句向量计算2个句子之间的相似度。u,v分别表示输入的2个句子的向量表示,|u-v|表示取两个向量的绝对值,(u, v, |u-v|)表示将三个向量在-1维度进行拼接,因此得到的向量的维度为 3*d,d表示隐层维度。
当损失函数是softmax时,论文里提到把u,v,|u-v|拼接起来后接分类层效果是最好的,其实sbert库SoftmaxLoss也是默认采用这种做法,但做inference的时候,sbert还是默认拿mean pooling后的向量做后续相似度计算。
五、如何评价句向量生成的好坏
句向量评测 SentEval
参考文献:
- https://www.jianshu.com/p/3b1bad16c351
- https://zhuanlan.zhihu.com/p/113133510?from_voters_page=true
- https://www.cnblogs.com/gczr/p/12874409.html
- https://zhuanlan.zhihu.com/p/388680608
- https://blog.51cto.com/u_13707997/5067160
- https://blog.csdn.net/weixin_43922901/article/details/106014964
- https://mimiyouyou.com/2021/11/04/transformers-BERT%E9%A2%84%E8%AE%AD%E7%BB%83%E6%A8%A1%E5%9E%8B%E5%BA%A6%E9%87%8F%E6%96%87%E6%9C%AC%E7%9B%B8%E4%BC%BC%E6%80%A7/
文章出处登录后可见!