目录
1 简介
1.1 什么是强化学习

强化学习是一种机器学习的学习方式(四种主要的机器学习方式解释见上图)。
上图没有提到深度学习,是因为从学习方式层面上来说,深度学习属于上述四种方式的子集。而强化学习是独立存在的,所以上图单独列出强化学习,而没有列出深度学习。
强化学习和其他三种学习方式主要不同点在于:强化学习训练时,需要环境给予反馈,以及对应具体的反馈值。它不是一个分类的任务,不是金融反欺诈场景中如何分辨欺诈客户和正常客户。强化学习主要是指导训练对象每一步如何决策,采用什么样的行动可以完成特定的目的或者使收益最大化。
- 比如AlphaGo下围棋,AlphaGo就是强化学习的训练对象,AlphaGo走的每一步不存在对错之分,但是存在“好坏”之分。当前这个棋面下,下的“好”,这是一步好棋。下的“坏”,这是一步臭棋。强化学习的训练基础在于AlphaGo的每一步行动环境都能给予明确的反馈,是“好”是“坏”?“好”“坏”具体是多少,可以量化。强化学习在AlphaGo这个场景中最终训练目的就是让棋子占领棋面上更多的区域,赢得最后的胜利。
1.2 强化学习的主要特点
- 试错学习:强化学习需要训练对象不停地和环境进行交互,通过试错的方式去总结出每一步的最佳行为决策,整个过程没有任何的指导,只有冰冷的反馈。所有的学习基于环境反馈,训练对象去调整自己的行为决策。
- 延迟反馈:强化学习训练过程中,训练对象的“试错”行为获得环境的反馈,有时候可能需要等到整个训练结束以后才会得到一个反馈,比如Game Over或者是Win。当然这种情况,我们在训练时候一般都是进行拆解的,尽量将反馈分解到每一步。
- 时间是强化学习的一个重要因素:强化学习的一系列环境状态的变化和环境反馈等都是和时间强挂钩,整个强化学习的训练过程是一个随着时间变化,而状态&反馈也在不停变化的,所以时间是强化学习的一个重要因素。
- 当前的行为影响后续接收到的数据:为什么单独把该特点提出来,也是为了和监督学习&半监督学习进行区分。在监督学习&半监督学习中,每条训练数据都是独立的,相互之间没有任何关联。但是强化学习中并不是这样,当前状态以及采取的行动,将会影响下一步接收到的状态。数据与数据之间存在一定的关联性。
1.3 强化学习的组成部分
- Agent(智能体、机器人、代理):强化学习训练的主体就是Agent,有时候翻译为“代理”,这里统称为“智能体”。Pacman中就是这个张开大嘴的黄色扇形移动体。
- Environment(环境):整个游戏的大背景就是环境;Pacman中Agent、Ghost、豆子以及里面各个隔离板块组成了整个环境。
- State(状态):当前 Environment和Agent所处的状态,因为Ghost一直在移动,豆子数目也在不停变化,Agent的位置也在不停变化,所以整个State处于变化中;这里特别强调一点,State包含了Agent和Environment的状态。
- Action(行动):基于当前的State,Agent可以采取哪些action,比如向左or右,向上or下;Action是和State强挂钩的,比如上图中很多位置都是有隔板的,很明显Agent在此State下是不能往左或者往右的,只能上下;
- Reward(奖励):Agent在当前State下,采取了某个特定的action后,会获得环境的一定反馈就是Reward。这里面用Reward进行统称,虽然Reward翻译成中文是“奖励”的意思,但其实强化学习中Reward只是代表环境给予的“反馈”,可能是奖励也可能是惩罚。比如Pacman游戏中,Agent碰见了Ghost那环境给予的就是惩罚。
2 强化学习训练过程
下面我们需要介绍一下强化学习的训练过程。整个训练过程都基于一个前提,我们认为整个过程都是符合马尔可夫决策过程的。
- 马尔可夫决策过程(Markov Decision Process)
Markov是一个俄国的数学家,为了纪念他在马尔可夫链所做的研究,所以以他命名了“Markov Decision Process”,以下用MDP代替。
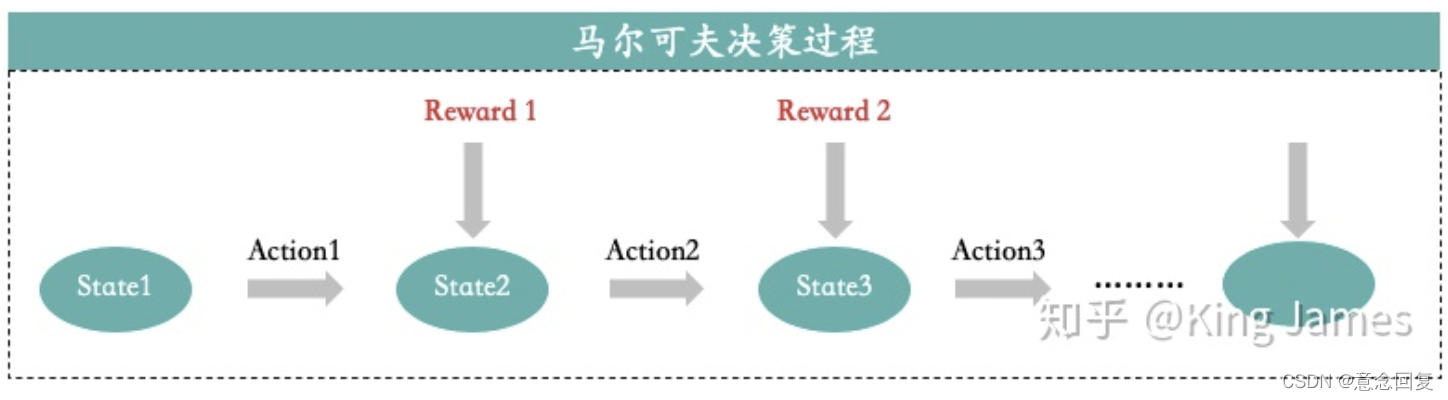
MDP核心思想就是下一步的State只和当前的状态State以及当前状态将要采取的Action有关,只回溯一步。比如上图State3只和State2以及Action2有关,和State1以及Action1无关。我们已知当前的State和将要采取的Action,就可以推出下一步的State是什么,而不需要继续回溯上上步的State以及Action是什么,再结合当前的(State,Action)才能得出下一步State。实际应用中基本场景都是马尔可夫决策过程,比如AlphaGo下围棋,当前棋面是什么,当前棋子准备落在哪里,我们就可以清晰地知道下一步的棋面是什么了。
为什么我们要先定义好整个训练过程符合MDP了,因为只有符合MDP,我们才方便根据当前的State,以及要采取的Action,推理出下一步的State。方便在训练过程中清晰地推理出每一步的State变更,如果在训练过程中我们连每一步的State变化都推理不出,那么也无从训练。
接下来我们使用强化学习来指导Agent如何行动了。
3 强化学习算法归类
我们选择什么样的算法来指导Agent行动了?本身强化学习算法有很多种,关于强化学习算法如何分类,有很多种分类方式,这里我选择三种比较常见的分类方式。
3.1 Value Based
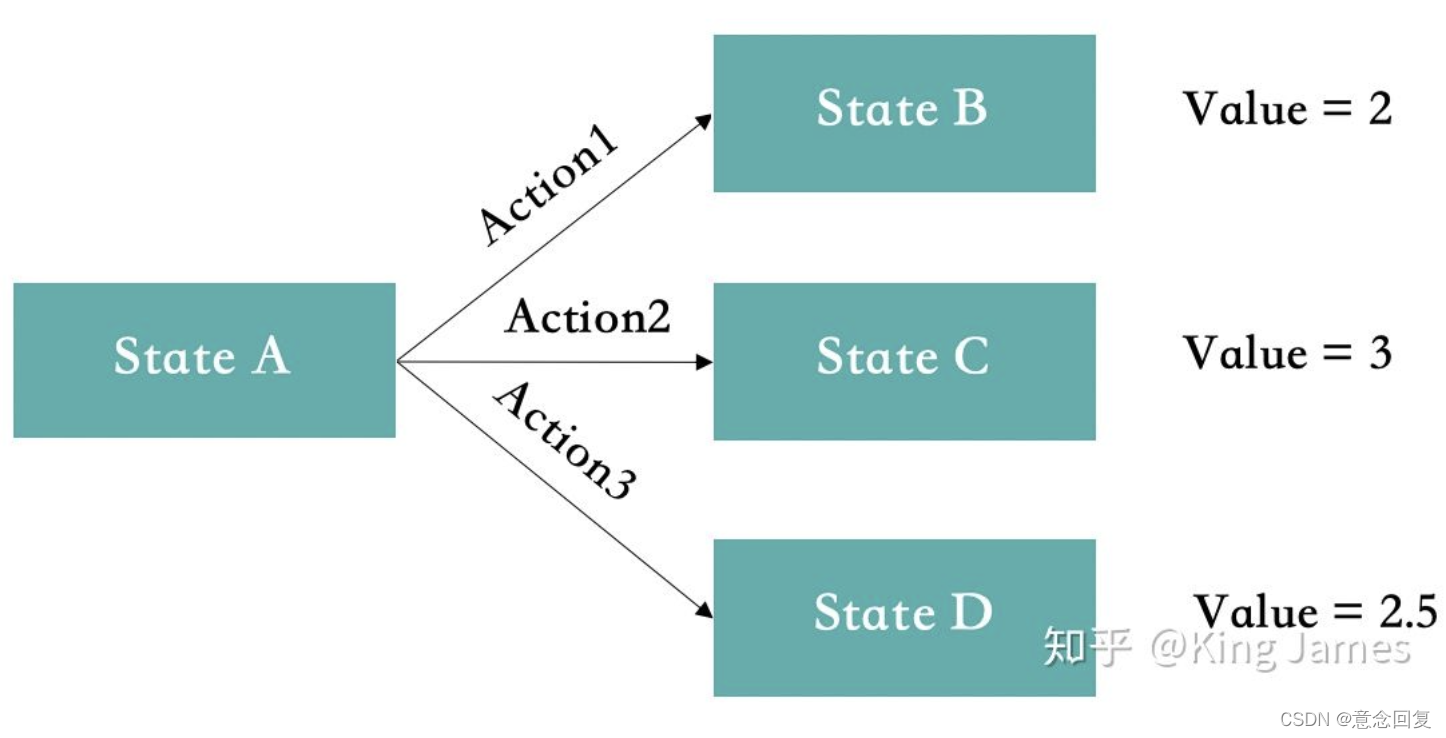
- 说明:
- 基于每个State下可以采取的所有Action,这些Action对应的Value,来选择当前State如何行动。强调一点这里面的Value并不是从当前State进入下一个State,环境给的Reward,Reward是Value组成的一部分。但我们实际训练时既要关注当前的收益,也要关注长远的收益,所以这里面的Value是通过一个计算公式得出来的,而不仅仅是状态变更环境立即反馈的Reward。因为Value的计算较为复杂,通常使用贝尔曼方程,在此不再细述。
- 如何选择Action:
- 简单来说,选择当前State下对应Value最大的Action。选择能够带来最大Value加成的Action。比如下图StateA状态下,可以采取的Action有3个,但是Action2带来的Value最大,所以最终Agent进入StateA状态时,就会选择Action2。(强调一点这里面的Value值,在强化学习训练开始时都是不知道的,我们一般都是设置为0。然后让Agent不断去尝试各类Action,不断与环境交互,不断获得Reward,然后根据我们计算Value的公式,不停地去更新Value,最终在训练N多轮以后,Value值会趋于一个稳定的数字,才能得出具体的State下,采取特定Action,对应的Value是多少)
- 代表性算法:
- Q-Learning、SARSA(State-Action-Reward-State-Action);
- 适用场景:
- Action空间是离散的,比如Pacman里面的动作空间基本是“上下左右”,但有些Agent的动作空间是一个连续的过程,比如机械臂的控制,整个运动是连续的。如果强行要将连续的Action拆解为离散的也是可以的,但是得到的维度太大,往往是指数级的,不适宜训练。同时在Value-Based场景中,最终学习完每个State对应的最佳Action基本固定。但有些场景即使最终学习完每个State对应的最佳Action也是随机的,比如剪刀石头布游戏,最佳策略就是各1/3的概率出剪刀/石头/布。
3.2 Policy Based
Policy Based策略就是对Value Based的一个补充,
- 说明:
- 基于每个State可以采取的Action策略,针对Action策略进行建模,学习出具体State下可以采取的Action对应的概率,然后根据概率来选择Action。如何利用Reward去计算每个Action对应的概率里面涉及到大量的求导计算,对具体过程感兴趣的可以参考这篇文章:基于值和策略的强化学习入坑 – 知乎
- 如何选择Action:
- 基于得出的策略函数,输入State得到Action。
- 代表性算法:
- Policy Gradients
- 适用场景:
- Action空间是连续的&每个State对应的最佳Action并不一定是固定的,基本上Policy Based适用场景是对Value Based适用场景的补充。对于Action空间是连续的,我们通常会先假设动作空间符合高斯分布,然后再进行下一步的计算。
3.3 Actor-Critic
AC分类就是将Value-Based和Policy-Based结合在一起,里面的算法结合了3.1和3.2。
上述就是三大类常见的强化学习算法,而在Pacman这个游戏中,我们就可以适用Value-Based算法来训练。因为每个State下最终对应的最优Action是比较固定的,同时Reward函数也容易设定。
3.4 其他分类
上述三种分类是常见的分类方法,有时候我们还会通过其他角度进行分类,以下分类方法和上述的分类存在一定的重叠:
- 根据是否学习出环境Model分类:
- Model-based指的是,agent已经学习出整个环境是如何运行的,当agent已知任何状态下执行任何动作获得的回报和到达的下一个状态都可以通过模型得出时,此时总的问题就变成了一个动态规划的问题,直接利用贪心算法即可了。这种采取对环境进行建模的强化学习方法就是Model-based方法。
- 而Model-free指的是,有时候并不需要对环境进行建模也能找到最优的策略。虽然我们无法知道确切的环境回报,但我们可以对它进行估计。Q-learning中的Q(s,a)就是对在状态s下,执行动作a后获得的未来收益总和进行的估计,经过很多轮训练后,Q(s,a)的估计值会越来越准,这时候同样利用贪心算法来决定agent在某个具体状态下采取什么行动。
如何判断该强化学习算法是Model-based or Model-free, 我们是否在agent在状态s下执行它的动作a之前,就已经可以准确对下一步的状态和回报做出预测,如果可以,那么就是Model-based,如果不能,即为Model-free。
4 EE(Explore & Exploit)探索与利用
3里面介绍了各种强化学习算法:Value-Based、Policy-Based、Actor-Critic。但实际我们在进行强化学习训练过程中,会遇到一个“EE”问题。这里的Double E是“Explore & Exploit”,“探索&利用”。比如在Value-Based中,如下图StateA的状态下,最开始Action1&2&3对应的Value都是0,因为训练前我们根本不知道,初始值均为0。如果第一次随机选择了Action1,这时候StateA转化为了StateB,得到了Value=2,系统记录在StateA下选择Action1对应的Value=2。如果下一次Agent又一次回到了StateA,此时如果我们选择可以返回最大Value的action,那么一定还是选择Action1。因为此时StateA下Action2&3对应的Value仍然为0。Agent根本没有尝试过Action2&3会带来怎样的Value。
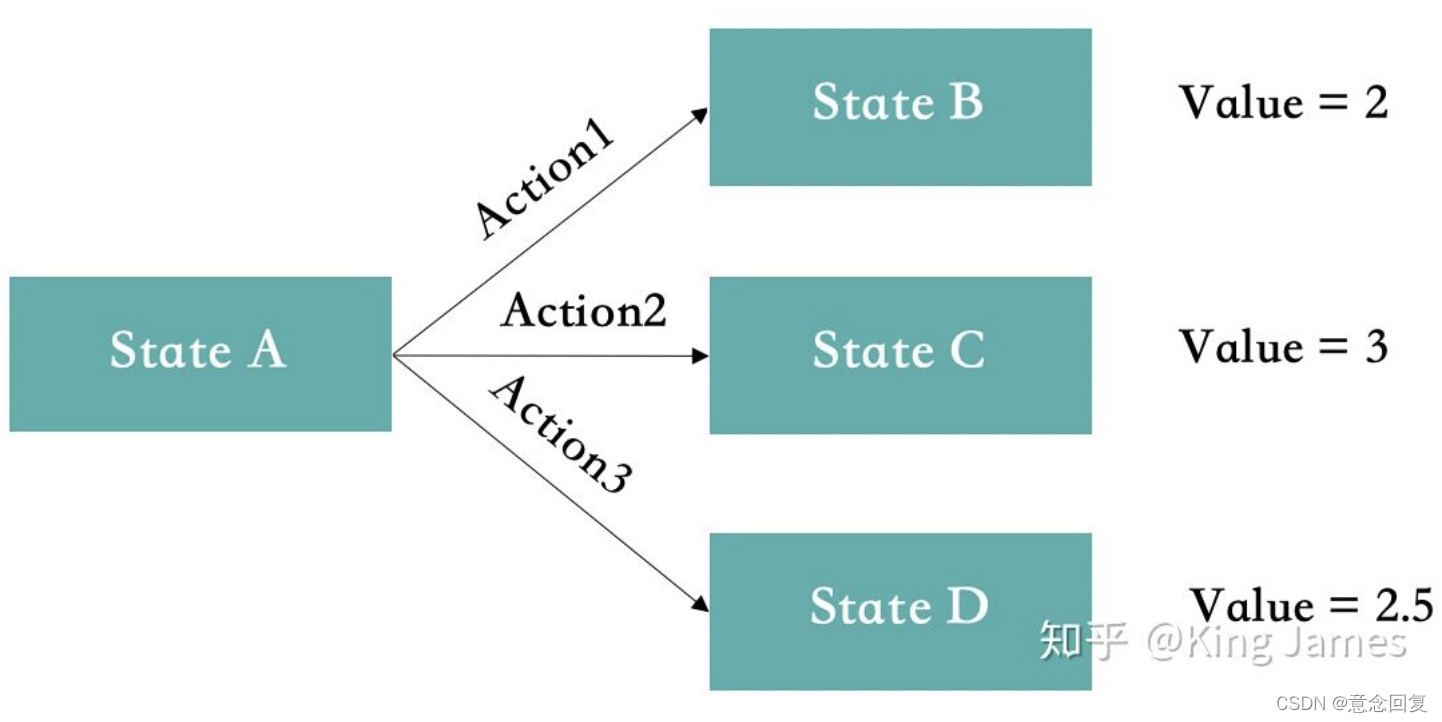
所以在强化学习训练的时候,
- 一开始会让Agent更偏向于探索Explore,并不是哪一个Action带来的Value最大就执行该Action,选择Action时具有一定的随机性,目的是为了覆盖更多的Action,尝试每一种可能性。
- 等训练很多轮以后各种State下的各种Action基本尝试完以后,我们这时候会大幅降低探索的比例,尽量让Agent更偏向于利用Exploit,哪一个Action返回的Value最大,就选择哪一个Action。
Explore&Exploit是一个在机器学习领域经常遇到的问题,并不仅仅只是强化学习中会遇到,在推荐系统中也会遇到,比如用户对某个商品 or 内容感兴趣,系统是否应该一直为用户推送,是不是也要适当搭配随机一些其他商品 or 内容。
5 强化学习实际开展中的难点
我们实际在应用强化学习去训练时,经常会遇到各类问题。虽然强化学习很强大,但是有时候很多问题很棘手无从下手。
- Reward的设置:如何去设置Reward函数,如何将环境的反馈量化是一个非常棘手的问题。比如在AlphaGo里面,如何去衡量每一步棋下的“好”与“坏”,并且最终量化,这是一个非常棘手的问题。有些场景下的Reward函数是很难设置的。
- 采样训练耗时过长,实际工业届应用难:强化学习需要对每一个State下的每一个Action都要尽量探索到,然后进行学习。实际应用时,部分场景这是一个十分庞大的数字,对于训练时长,算力开销是十分庞大的。很多时候使用其他的算法也会获得同样的效果,而训练时长,算力开销节约很多。强化学习的上限很高,但如果训练不到位,很多时候下限特别低。
- 容易陷入局部最优:部分场景中Agent采取的行动可能是当前局部最优,而不是全局最优。网上经常有人截图爆出打游戏碰到了王者荣耀AI,明明此时推塔或者推水晶是最合理的行为,但是AI却去打小兵,因为AI采取的是一个局部最优的行为。再合理的Reward函数设置都可能陷入局部最优中。
6 强化学习的实际应用
虽然强化学习目前还有各种各样的棘手问题,但目前工业界也开始尝试应用强化学习到实际场景中了,除了AlphaGo还有哪些应用了:
6.1 自动驾驶
目前国内百度在自动驾驶领域中就使用了一定的强化学习算法,但是因为强化学习需要和环境交互试错,现实世界中这个成本太高,所以真实训练时都需要加入安全员进行干预,及时纠正Agent采取的错误行为。
6.2 游戏
游戏可以说是目前强化学习应用最广阔的,目前市场上的一些MOBA游戏基本都有了强化学习版的AI在里面,最出名的就是王者荣耀AI。游戏环境下可以随便交互,随便试错,没有任何真实成本。同时Reward也相对比较容易设置,存在明显的奖励机制。
6.3 推荐系统
目前一些互联网大厂也在推荐系统中尝试加入强化学习来进行推荐,比如百度&美团。使用强化学习去提高推荐结果的多样性,和传统的协同过滤&CTR预估模型等进行互补。
7 Q-learning
视频:【莫烦Python】强化学习 Reinforcement Learning_哔哩哔哩_bilibili
什么是 Q-learning? – 简书百度安全验证
如何用简单例子讲解 Q – learning 的具体过程? – 知乎
A Painless Q-learning Tutorial (一个 Q-learning 算法的简明教程)_皮果提的博客-CSDN博客_qlearning算法
8 策略梯度


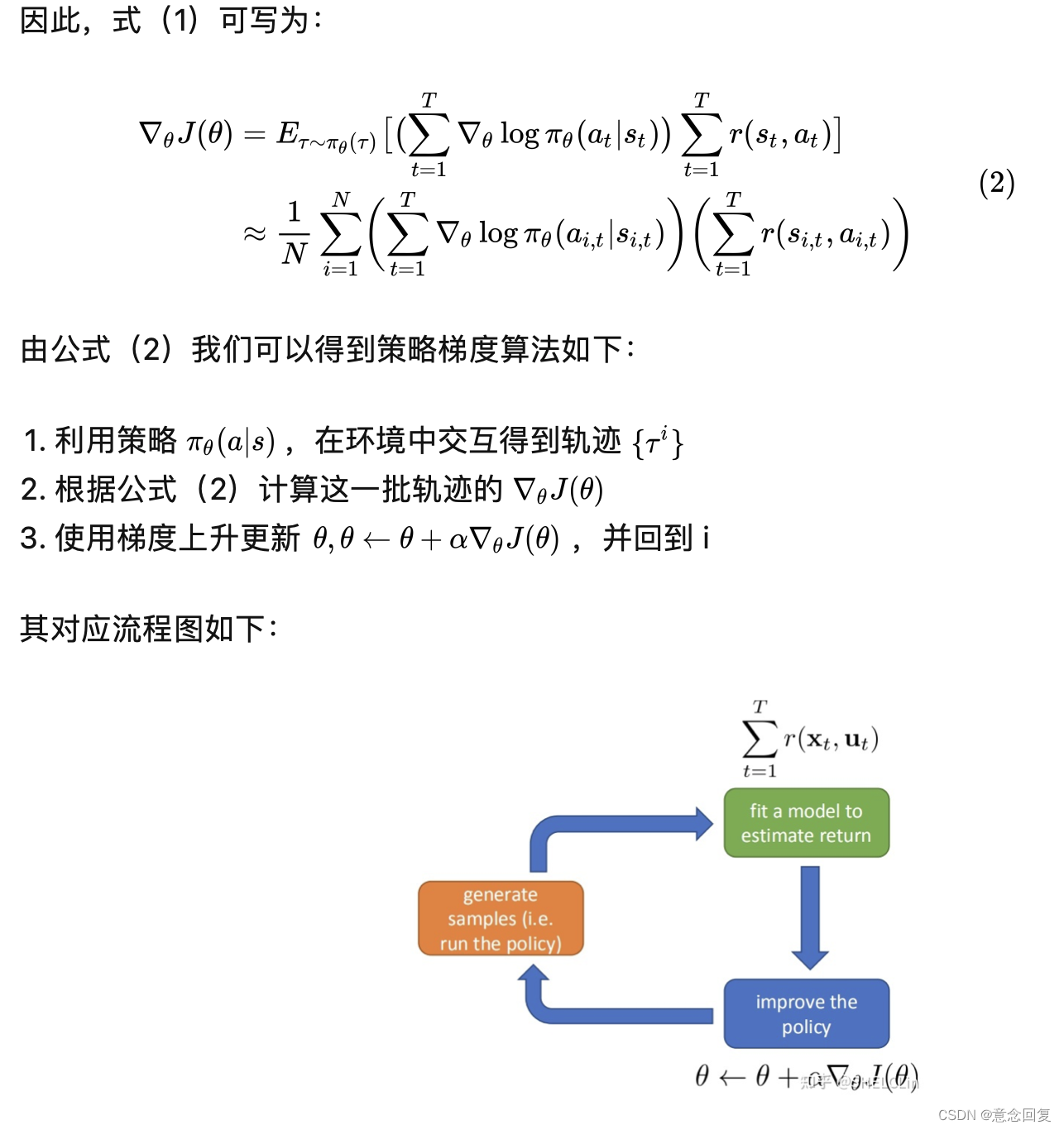
总的来说,策略梯度法就是让高回报的轨迹出现的概率更大,低回报的轨迹出现的概率变小,从而得到一个较好的策略。
文章出处登录后可见!