前言
WMT是机器翻译和机器翻译研究的主要活动。 该会议每年与自然语言处理方面的大型会议联合举行。2006年,第一届机器翻译研讨会在计算语言学协会北美分会年会上举行。2016年,随着神经机器翻译的兴起,WMT成为了一个自己的会议。 机器翻译会议仍然主要被称为WMT[1]。
有些机器翻译工作会使用历年WMT公开的数据集作为他们的数据集[2],如下图所示:
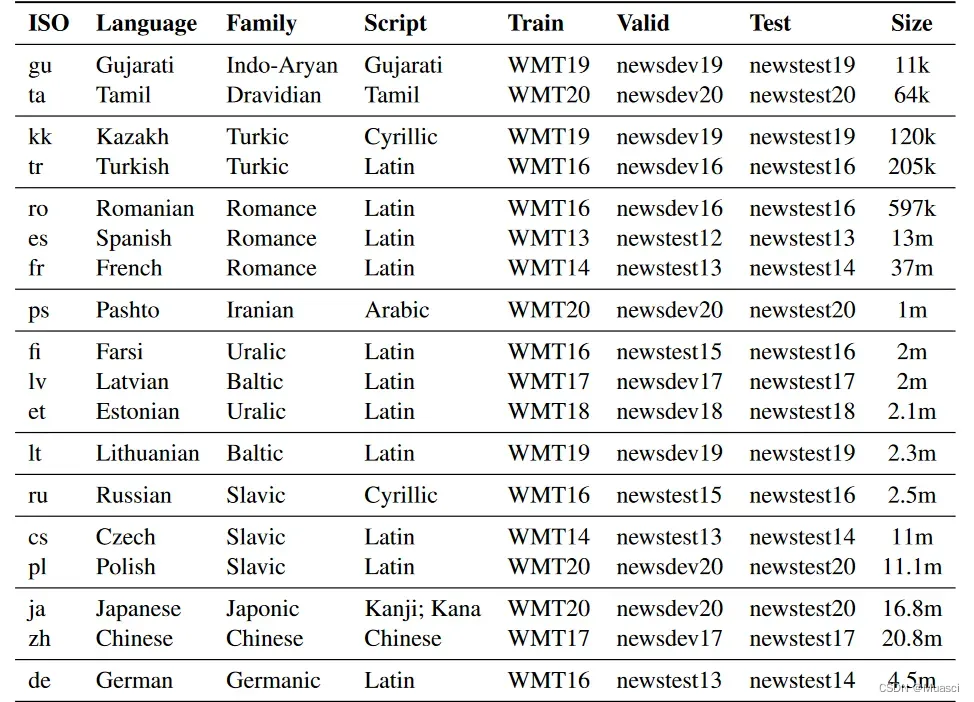
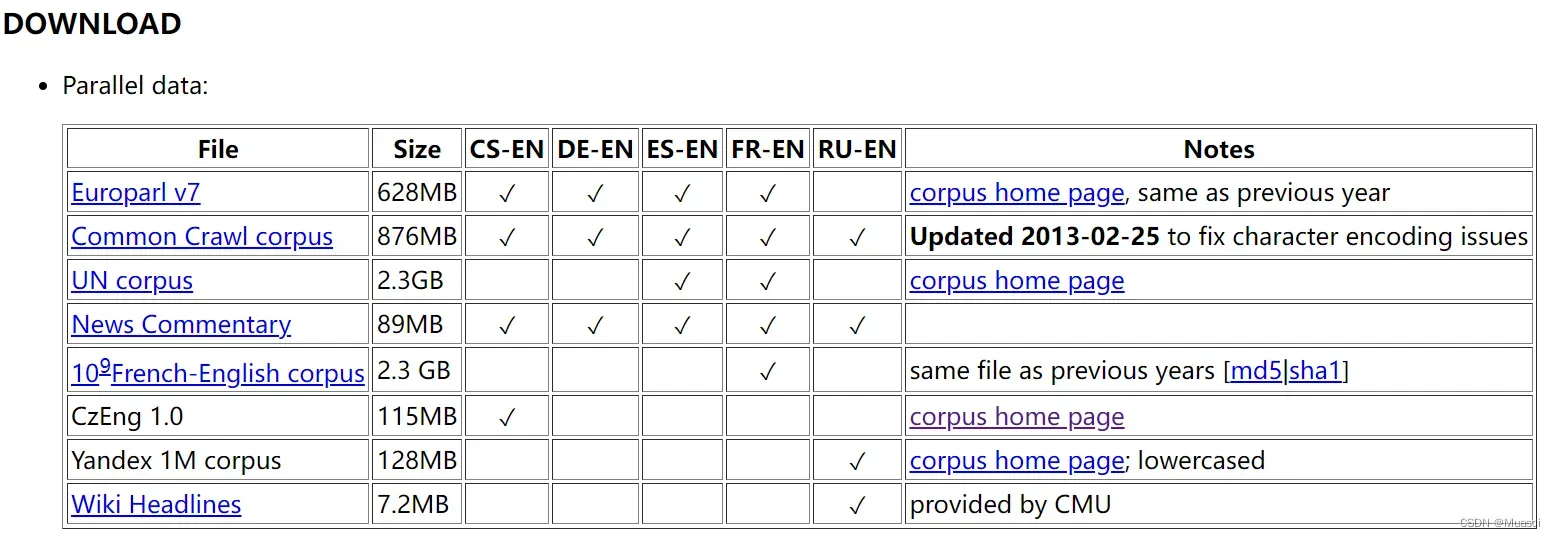
当笔者想要复现工作结果时,首先需要收集得到这样的数据集。而以WMT13[3]为例。如下图所示,笔者需要手动点击下载上面公开的每一个子数据集,然后汇总得到整个WMT13的训练、验证和测试集。而由于每一个子数据集的形式也不同,且数量较多…总的来说还是很麻烦的。
而笔者发现,huggingface[4]上面已经收集了部分年份的WMT数据,并提供了下载接口。以wmt14的所有hi-en数据为例,最终的下载结果如下图所示:

(笔者后知后觉意识到,只要想办法打开.arrow文件就可以得到对应数据了…艹)
本文旨在总结批量获取所有WMT数据的初步解决方案,通过修改huggingface datasets库的源码实现。
具体实现
第一步,pip install datasets安装datasets库。
第二步,通过git clone https://github.com/huggingface/datasets克隆datasets库,datasets/datasets路径下面包含了该库提供的所有数据集的相关代码:
第三步,创建主程序文件(run.py),代码如下,其中,py_file_path为上面说的datasets/datasets路径,save_dir为保存到本地的路径:
from datasets import load_dataset
import os
wmt_dict = {
"wmt14": [(lang, "en") for lang in ["cs", "de", "fr", "hi", "ru"]],
"wmt15": [(lang, "en") for lang in ["cs", "de", "fi", "fr", "ru"]],
"wmt16": [(lang, "en") for lang in ["cs", "de", "fi", "ro", "ru", "tr"]],
"wmt17": [(lang, "en") for lang in ["cs", "de", "fi", "lv", "ru", "tr", "zh"]],
"wmt18": [(lang, "en") for lang in ["cs", "de", "et", "fi", "kk", "ru", "tr", "zh"]],
"wmt19": [(lang, "en") for lang in ["cs", "de", "fi", "gu", "kk", "lt", "ru", "zh"]] + [("fr", "de")],
}
py_file_path = r"C:\Users\13359\PycharmProjects\for_fun\other\wmt_datasets\datasets\datasets"
save_dir = r"D:\dataset\mt"
for wmt in wmt_dict:
for lang_tuple in wmt_dict[wmt]:
lang_pair = "-".join(lang_tuple)
print(f"wmt: {wmt} | lang_pair: {lang_pair}")
load_dataset(os.path.join(py_file_path, wmt), name = lang_pair, cache_dir = save_dir)
第四步,在上述datasets/datasets路径下面随便选择一个wmt文件夹,比如wmt14,将里面的wmt_utils.py复制到run.py的同级目录下。(暂时不知道为何,尝试下来这样没有错),也就是文件目录结构如下:
第五步,如果此时运行run.py,则会像前言中的那样,得到所有wmt的所有语言对的数据,但数据格式是arrow的。笔者脑抽,没有直接去想如何把.arrow文件转成更好理解的格式,而是通过修改pip install下来的datasets源码,来直接修改保存数据的过程。具体来说,通过ctrl+B追溯run.py中load_dataset的执行顺序,最终找到了保存数据的源码位置:load_dataset(run.py)->builder_instance.download_and_prepare(load.py,1738行)->self._download_and_prepare(builder.py, 638行)->self._prepare_split(builder.py, 723行),由于此时的self是一个wmtxx object,从具体的wmtxx.py(如wmt14.py,位于datasets/datasets/wmt14/wmt14.py)可知,wmtxx类的继承顺序是:wmtxx->Wmt(wmt_utils.py)->GeneratorBasedBuilder(builder.py)->DatasetBuilder(builder.py),所以self._prepare_split最终方法实现是GeneratorBasedBuilder类的_prepare_split方法。
该方法中完成了.arrow数据的创建,具体代码如下所示:
with ArrowWriter(
features=self.info.features,
path=fpath,
writer_batch_size=self._writer_batch_size,
hash_salt=split_info.name,
check_duplicates=check_duplicate_keys,
) as writer:
try:
for key, record in logging.tqdm(
generator,
unit=" examples",
total=split_info.num_examples,
leave=False,
disable=not logging.is_progress_bar_enabled(),
desc=f"Generating {split_info.name} split",
):
example = self.info.features.encode_example(record)
writer.write(example, key)
finally:
num_examples, num_bytes = writer.finalize()
split_generator.split_info.num_examples = num_examples
split_generator.split_info.num_bytes = num_bytes
其中,generator就是包含了所有数据的生成器。于是,笔者在上述代码的前面,加上了下面这段代码,完成了对数据保存的修改:
# ...其它代码
generator = self._generate_examples(**split_generator.gen_kwargs)
# 新增代码
import itertools
generator, generator2 = itertools.tee(generator) # 生成器只能被遍历一次
user_name = "xushaoyang"
str_lst = fpath.split("\\")
index = str_lst.index(self.name)
lang_pair = str_lst[index + 1]
source, target = lang_pair.split("-")
path_lst = str_lst[:index + 2]
path_lst[index] += f"_{user_name}"
dir_path = os.path.join(*path_lst)
os.makedirs(dir_path, exist_ok=True)
source_file_name = f"{self.name}.{lang_pair}-{split_generator.name}.{source}"
source_path = os.path.join(dir_path, source_file_name)
target_file_name = f"{self.name}.{lang_pair}-{split_generator.name}.{target}"
target_path = os.path.join(dir_path, target_file_name)
source_f = open(source_path, mode="w", encoding="utf-8")
target_f = open(target_path, mode="w", encoding="utf-8")
for one_data in generator2:
assert len(one_data) == 2
key, translation = one_data
assert list(translation.keys()) == ["translation"]
source_sentence = translation['translation'][source]
target_sentence = translation['translation'][target]
source_f.write(source_sentence + "\n")
target_f.write(target_sentence + "\n")
source_f.close()
target_f.close()
# ...其它代码
with ArrowWriter(
完成修改后执行run.py,以wmt14的hi-en数据为例,得到的数据如下图所示,文件的命名仿照了OPUS100[5]:
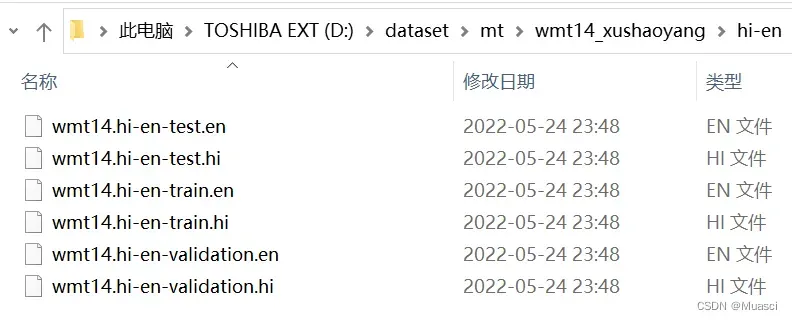
不足之处
- 总体来说,本篇博客价值不大。因为如果直接读取.arrow应该也行,比如参考:https://blog.csdn.net/wowotuo/article/details/110497489。如果这样的话,那完成前四步,直接运行run.py即可。
- huggingface datasets库只提供了WMT14-19的下载,其它年份的WMT还是需要自行下载,当然也可以继续修改源码,把其它年份的加进去(TODO1)。
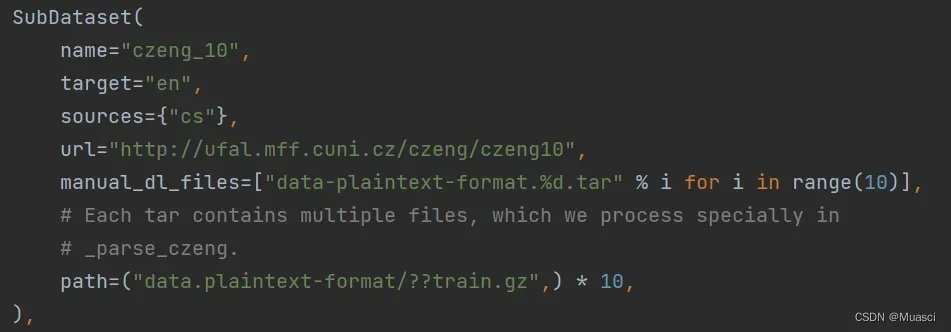
- 下载的数据不是很全。wmt_utils.py中以SubDataset类的形式定义了所有WMT可能需要下载到的所有数据集,而以czeng_10为例,定义了manual_dl_files的数据集就是需要手动下载的。笔者目前的解决方案是,在下载过程中记录哪些数据集没有自动下载,所有下载完成之后再去补上(包括手动补上第2条中缺少的WMT数据),记录的代码见“补充”。
补充
补充一:记录暂时只能手动下载的数据集
如”不足之处”的第3点所述,有一些文件没有提供自动下载的url,笔者的解决方案是在下载过程中记录哪些数据集没有自动下载,所有下载完成之后再去手动补上。具体来说,笔者在wmt_utils.py中的_split_generators函数中的 if dataset.get_manual_dl_files(source):语句下,加入了如下语句:
with open(f"{self.name}_error_log", mode="a", encoding="utf-8") as file:
file.write(f"lang: {'-'.join(self.config.language_pair)} | data_name: {dataset.name} | url: {str(dataset.get_manual_dl_files(source))}" + "\n")
在运行run.py的过程中,出现数据集缺失的情况,这样的记录就会被保存在wmtxxx_error_log日志文件中,如下图所示:

参考
[1]https://machinetranslate.org/wmt
[2]https://arxiv.org/pdf/2105.09259v1.pdf
[3]https://www.statmt.org/wmt14/translation-task.html
[4]https://github.com/huggingface/datasets
[5]https://github.com/EdinburghNLP/opus-100-corpus
文章出处登录后可见!