-
I. 问题介绍
八数码问题是一种经典的智力游戏,也是一种搜索算法的经典案例。该问题是指在一个3×3的棋盘上,有8个方块和一个空格,每个方块上标有1~8的数字,空格可以和相邻的方块交换位置,目标是通过交换方块的位置,使得棋盘上的数字排列成目标状态。
对于八数码在程序中的处理,我们通过拉直的方式,将八数码棋盘拉成一条字符串,用0来表示空位,用1-8的数字来表示相应的数码。这样一来就可以将二维的矩阵作为一维的向量处理,大大简化了问题。通过移动规则,用一维字符串上的索引来表示二维矩阵中的移动规则。
我们可以通过移动规则,用来产生某种棋盘可移动的所有情况。某一个节点下均连接了若干个子节点,这就形成了一个逻辑上的树结构。
既然八数码的移动可以看作为一个树结构,那么我们就可以对这个树进行搜索。搜索方式为广度优先搜索、宽度优先搜索、启发式搜索。
-
II. 思路设计
程序使用open表与close表来组织节点的搜索。open表用来保存待搜索的节点,close表用来保存以搜索的节点。实现搜索本质上是对open表与close表进行维护,两者中更重要的是维护好open表。我们可以通过open表中不同的取值方式,来实现广度优先搜索、宽度优先搜索与启发式搜索。
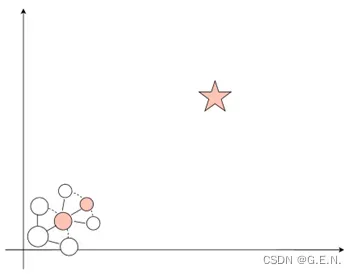
下图为open表与close表的示意图,先将open表中的某一节点取出来,判断其是否为目标节点,若不是目标节点,则将其展开,展开时要判断子节点是否再close表中,避免重复搜索,并将其子节点加入open表的尾部,再把展开的节点丢入close表,这就是搜索的基本过程。
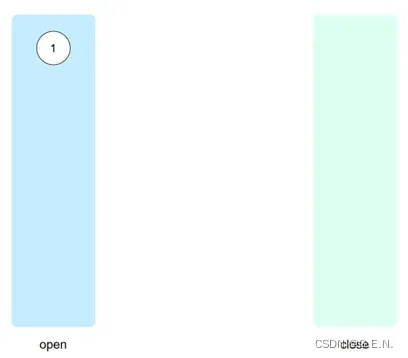
搜索的关键在于open表中的节点如何取,这也是实现不同搜索方式的关键。
-
广度优先搜索
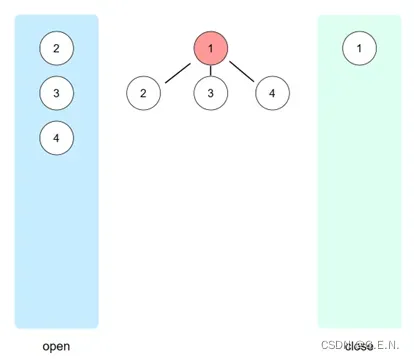
广度优先搜索的实现方式为:每次弹出open表中的第一个节点。如下图所示,在节点1展开完成后,open表继续弹出第一个节点,也就是节点2,节点2展开又形成新的节点5与节点6;当节点2完成展开后,open表将会弹出节点3;节点3完成展开后,open表将会弹出节点4;当节点2、3、4均完成展开后,接下来再展开节点5,然后是节点6……。
子节点将会在open表的尾部不断累积,要先将open表前面的父节点遍历完成后,才能开始遍历子节点。通过这种方式,实现了广度优先搜索。
-
深度优先搜索
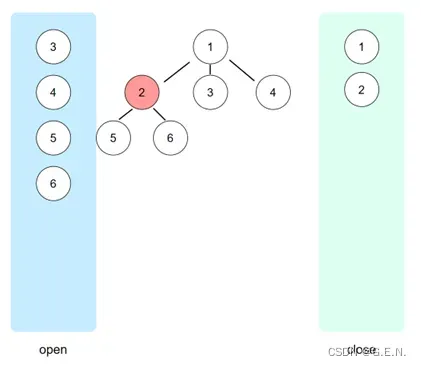
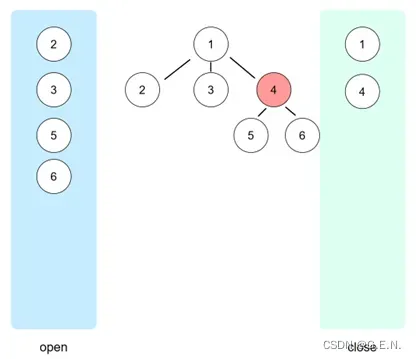
深度优先搜索的实现方式为:每次弹出open表的最后一个节点。如下图所示,在节点1完成展开后,open表弹出最后一个节点4,节点4展开形成节点5、6,并将其加入到open表的尾部,接下来将会弹出最后一个节点6,节点6的子节点又会加入到open表的尾部,接下来继续弹出最后一个节点,这个节点则是节点6的子节点。
子节点将会在open表的尾部不断弹出,每次都向更深层次的子节点搜索,这样就实现了深度遍历搜索。
-
启发式搜索
广度优先搜索与深度优先搜索虽然是有序的搜索,但其本质上还是盲目的搜索,搜索过程中程序并不知道目标在什么地方。启发式搜索其实就是告诉了程序,目标在哪里,让程序倾向于朝着目标距离小的方搜索。
如下图所示,启发式搜索在展开节点时,会先计算节点与目标之间的距离,并在下一步优先展开距离小的节点。这样一来程序就会避免展开很多不必要的节点,极大提高程序的搜索效率。
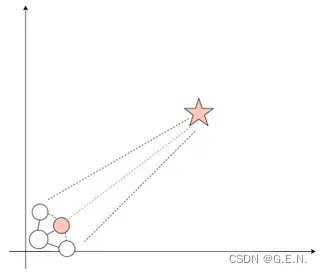
我们需要做的是定义一个代价函数,用来计算节点与目标节点之间的距离,这个距离也被称为代价。在open表弹出节点时,将会弹出代价最小的节点,一步步靠进目标节点。
计算距离的函数有很多,我定义了三种代价函数,一种是字符串对位距离,一种是曼哈顿距离,一种是欧式距离。我认为字符串距离存在着缺陷,比如索引2与索引3,他们在字符串中的距离只有1,但是在实际的网格中,他们的距离是大于1的,因此我个人更加倾向于曼哈顿距离与欧式距离,实践证明亦是如此。
-
III. 代码实现
在代码的实现中,我将广度优先搜索、深度优先搜索、启发式搜索全部整合到了一个框架中,可以通过修改全局变量,实现不同的模式。
我在代码中做了许多鲁棒性的操作,本来的想法是,将八数码问题很容易的扩展到十五数码问题,但是后来才想到,代码处理节点的方式是将其拉成一条字符串,这样以来,10以上的数字就没有办法表示了,因为他们占了两位字符,只能放弃了这个想法。但把代码中的鲁棒性操作都保留了下来。
-
check函数
用于检查用户的输入是否符合规范。若不符合,则抛出异常。
def check():
"""检查用户输入"""
# 检查节点长度是否符合要求
check_len = len(start) == len(target) and len(start) ** 0.5 % 1 == 0
assert check_len, f'请检查开始节点与目标节点的长度是否合理 开始节点长度{len(start)} 目标节点长度{len(target)}'
# 检查节点中的数字是否符合要求
# 节点中的数字查全
check_recall = lambda x: all([str(flag) in x for flag in range(int(len(start)))])
assert check_recall(start) and check_recall(target), f'请检查开始节点与目标节点是否输入正确 开始节点{start} 目标节点{target}'
# 检查搜索模式
assert mode in ALLOW_MODE, f'搜索模式 {mode} 不支持'
# 检查搜索方式
if mode == ALLOW_MODE[2]:
cod = list(cost_func.values())
count = 0
for i in cod:
if i:
count += 1
# 只允许有一个True
assert count == 1, f'请检查代价方程的选择是否合理, {cod}'-
get_rules函数
本来的想法是将八数码扩展到更多数码的情况,因而使用get_rules产生空位的移动规则。函数的思想为:将字符串的索引还原至网格的坐标内,并获取上下左右四个方位的索引值,再将越界值删除,最后保存在字典内。
def get_rules():
# 用于存放规则的字典
rules = dict()
# 字符串长度
length = len(start)
# 棋盘的边长
size = int(length ** 0.5)
# 遍历所有索引
for i in range(length):
# 将坐标还原至网格
row, col = i // size, i % size
# 获取四个方位的坐标
up, down, left, right = i - size, i + size, i - 1, i + 1
d = [up, down, left, right]
# 若当前索引处于边界,删除越界值
if row == 0:
d.remove(up)
if row == size - 1:
d.remove(down)
if col == 0:
d.remove(left)
if col == size - 1:
d.remove(right)
# 创建键值对
rules[i] = d
return rules-
swap_puzzle函数
swap_puzzle函数用于交换两个数码的位置,实际上就是移动空位。参数node表示要进行交换操作的节点,i和j表示要交换哪两处的索引。字符串可以通过索引访问,但不可通过索引修改,因此要将其先转换为列表,交换完成后再还原为字符串。
def swap_puzzle(node, i, j):
"""交换数码盘"""
temp = list(node)
temp[i], temp[j] = temp[j], temp[i]
return ''.join(temp)
-
expand函数
expand函数用于展开节点,根据空位的移动规则,生成某一节点的所有未遍历的子节点。参数info的格式如下:[节点,距离,展开次数],info不仅仅是一个节点,而是一个携带了节点与距离信息的列表。并在展开节点时,计算出各子节点与目标节点的距离。
def expand(info):
node = info[0]
zero_idx = node.index("0")
infos = []
for idx in RULES[zero_idx]:
new_node = swap_puzzle(node, zero_idx, idx)
if new_node not in close:
infos.append([new_node, cost(new_node, **cost_func), info[2]+1])
return infos-
cost函数
用于计算代价,也就是当前节点与目标节点之间的距离。我在函数中提供了三种代价函数,一种是直接计算字符串的对位距离,一种是曼哈顿距离,一种是欧式距离。计算曼哈顿距离与欧式距离时,要先将索引还原到网格坐标中。
def cost(node, str_dis=True, mhd_dis=False, o_dis=False):
"""
计算代价函数
:param now: 字符串类型 表示当前节点
:param str_dis: 布尔类型 表示是否使用字符串距离(将当前节点与目标节点的字符索引做差)
:param mhd_dis: 布尔类型 表示是否曼哈顿距离(将字符串还原至网格坐标中)
:param o_dis: 布尔类型 是否使用欧式距离(将字符串还原至网格坐标中)
:return:
"""
cost = 0
# 遍历每个字符及其索引
for i, char in enumerate(node):
# 将网络视为为一条向量(字符串)
# 用这条向量计算代价
# "541203786"情况下遍历了310个节点
if str_dis:
cost += abs(i - target.index(char))
# 0 1 2
# 3 4 5
# 6 7 8
# 将字符串还原为网格,计算其曼哈顿距离
# 曼哈顿距离为 x轴距离+y轴距离
else:
# 计算这个索引属于哪一行
row = i // 3
# 计算这个索引属于哪一列
con = i % 3
# 获取目标位置的行和列
end_idx = target.index(char)
end_row = end_idx // 3
end_con = end_idx % 3
# 计算曼哈顿距离
# "541203786"情况下遍历了240个节点
if mhd_dis:
cost += abs(row-end_row) + abs(con-end_con)
# 计算欧几里得距离(欧式距离)
# "541203786"情况下遍历了214个节点
elif o_dis:
cost += ((row-end_row) ** 2 + (con-end_con) ** 2)**0.5
return cost-
print_node函数、find_path函数、final_print函数
这三个函数对于算法没有直接的意义,算是工具函数,是用来向控制台输出最后的移动路径的。这里在产生移动路径时,程序的搜索树的结构为,键为子节点,值为父节点,这种设计可以更方便的帮助程序找到移动路径。
def print_node(node):
"""将节点以特定格式输出"""
length = len(start)
size = int(length ** 0.5)
for i in range(0, length, size):
print(' '.join(node[i: i + size]))
def find_path():
""" 通过nodes找到路径 """
path = []
# 树的结构为 键为子节点 值为父节点
son = target
while True:
father = tree[son]
path.append(son)
if father != -1:
son = father
else:
break
return path
def final_print():
"""最终的输出"""
print("\n移动顺序如下")
total_path = find_path()
for path in total_path + [target]:
print_node(path)
print()
print(f"遍历节点个数: {len(close)} 移动步数: {len(total_path)}")
print(f"累计用时: {time.time() - start_time:.2f}秒")-
主程序
主程序中规定了全局变量,全局变量包括了初始节点,目标节点,模式设置等一系列参数,提供了多种选项与功能。
在程序的主循环中,实现了根据不同的模式弹出不同的节点。在启发式搜索弹出节点时,不仅仅参考了节点与目标节点之间的距离,还参考了展开次数。可以理解为,程序不仅要通过最短的距离找到目标节点,还要尽量减少节点展开的次数。
if __name__ == '__main__':
# 开始节点
start = "541203786"
# start = "134082576"
# 目标节点
target = "123804765"
# 是否随机打乱开始状态
shuffle_start = False
ALLOW_MODE = ['广度优先搜索', '深度优先搜索', '启发式搜索']
# 搜索模式 支持的模式:0 广度优先搜索 1 深度优先搜索 2 启发式搜索
mode = ALLOW_MODE[2]
cost_func = {'str_dis': False, 'mhd_dis': False, 'o_dis': True}
# open表
open = []
# close表
close = []
# 搜索树
tree = dict()
RULES = get_rules()
# 检查变量是否设置正确
check()
print(f"搜索方式 {mode} ", end='')
if mode == ALLOW_MODE[2]:
print(f"{'字符串距离' if cost_func['str_dis'] else ''}", end='')
print(f"{'曼哈顿距离' if cost_func['mhd_dis'] else ''}", end='')
print(f"{'欧式距离' if cost_func['o_dis'] else ''}", end='')
print()
if shuffle_start:
# 随机打乱初始节点
start = list(start)
random.shuffle(start)
start = ''.join(start)
print('初始节点')
print_node(start)
# 将第一个节点放入open表中 [节点,代价,步数]
open.append([start, cost(start, **cost_func), 0])
# tree['root'] = start
tree[start] = -1
# 获取程序开始时间
start_time = time.time()
while len(open) > 0:
# 输出日志信息
print(f"\r正在搜索...{time.time() - start_time:.0f}s 已遍历节点数:{len(close)}", end='')
# 不同的模式弹出不同的节点
if mode == ALLOW_MODE[0]:
#
info = open.pop(0)
elif mode == ALLOW_MODE[1]:
info = open.pop(-1)
elif mode == ALLOW_MODE[2]:
info = min(open, key=lambda x: x[1] + x[2])
open.remove(info)
# 获取节点值
node = info[0]
# 将节点保存至close表
close.append(node)
# 判断是否为目标节点
if node == target:
final_print()
break
# 展开节点
infos = expand(info)
open.extend(infos)
for info in infos:
tree[info[0]] = node
else:
# while循环正常结束,open表为空,所有节点搜索完毕
print("问题无解")
print(f"遍历节点个数: {len(close)}")
print(f"累计用时: {time.time() - start_time:.2f}秒")
-
IV. 实验结果
对于541203786这种情况:
-
盲目搜索
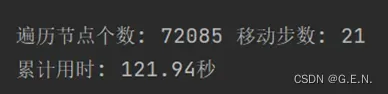
当使用广度优先搜索时,遍历节点72085个,移动步数21步,累计时间121.94秒。时间消耗与遍历节点数每个人可能不同,因为这个结果受到移动规则中的排列顺序影响较大。广度优先搜索移动步数较少,因为其按层搜索,每一层就是一个移动。
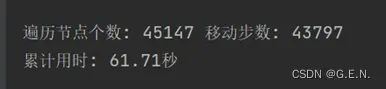
当使用深度优先搜索时,遍历节点45147个,移动步数43797步,累计时间61.71秒。深度优先搜索遍移动步数较多,因为其大多数情况展开一次就是一个移动。
上述两种为盲目搜索的实验结果,两种搜索中的运气成分还是比较多的。
-
启发式搜索:
使用字符串对位距离:遍历节点数727个,移动步数23步,累计用时0.11秒。启发式相较于盲目搜索的几万个搜索节点,可以说是提升巨大,但代价函数不合适的情况下,可能会找到多余的移动步数。
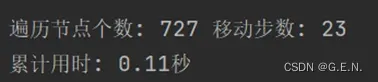
曼哈顿距离:遍历节点数605个,移动步数21步,累计用时0.09秒。相较字符串的对位距离,曼哈顿距离显然在每个数值上都优于字符串对位距离,原因可能是前文提到的字符串对位距离的不合理性。
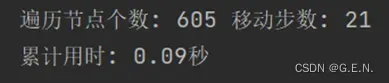
欧式距离:遍历节点数837个,移动步数21步,累计用时0.13秒。结果依然优于字符串对位距离,但要略差于曼哈顿距离。

-
V.总结
在八数码问题中,启发式搜索无疑碾压盲目搜索,但启发式搜索也不一定是快最优的解。报告仅针对一种初始状态做了实验,还需要更多的实验次数来支撑实验结果,还有更多的代价函数等待应用,此外,还可以通过调节展开次数与距离之间的占比,以获取更佳的效果。
文章出处登录后可见!