1 网络结构
MTCNN 是多任务级联 CNN 的人脸检测深度学习模型,该模型不仅考虑了人脸检测概率,还综合训练了人脸边框回归和面部关键点检测,多任务同时建立 loss function 并训练,因此为 MTCNN。级联 CNN 主要由三个子网络组成:P-Net、R-Net 和 O-Net。
P-Net 的结构如下:
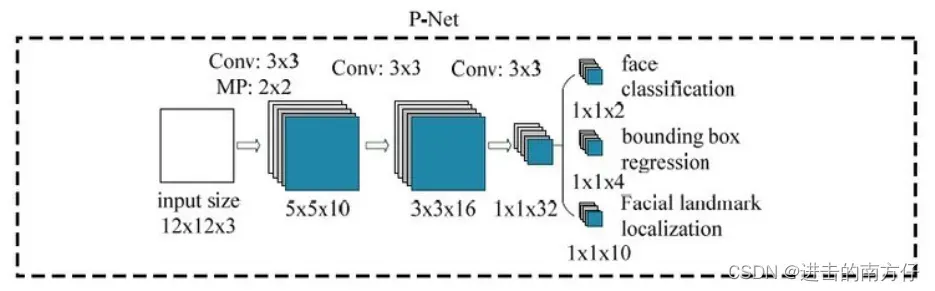
从网络结构上看,P-Net 接受大小为 (12,12,3) 的图片的输入,输出三种特征图,大小为 (1,1,C),也就是说最终得到的特征图每一点都对应着一个大小为 12×12 的感受野。三种输出如下:
- cls:图像是否包含人脸,输出向量大小为 (1,1,2),也就是两个值,即图像不是人脸的概率和图像是人脸的概率。这两个值加起来严格等于 1,之所以使用两个值来表示,是为了方便定义交叉熵损失函数;
- bounding_box:当前框位置相对完美的人脸框位置的偏移。这个偏移大小为 (1,1,4),即表示框左上角和右下角的坐标的偏移量。网络结构中的输出叫做 bounding_boxes,如果按代码来说应该是 offsets;
- landmark:5 个关键点相对于人脸框的偏移量。分别对应着左眼的位置、右眼的位置、鼻子的位置、左嘴巴的位置、右嘴巴的位置。每个关键点需要两维来表示,因此输出是向量大小为 (1,1,10)。
Tips:
- (12,12,3) 的输入大小指的是人脸框的大小,并不是真正图片的大小。在测试的时候大家会发现我们会输入各种缩放比例的图片,为什么可以这样?这是因为 P-Net 的输出是 特征图,没有 全连接层,这意味着网络对输出图片大小没有限制;
- 训练时是 (12,12,3) 的输入,(1,1,32) 的输出,但是这里的 (12,12) 输入只是一个示意,实际测试的时候由于 P-Net 的输出特征图的感受野是 (12, 12),输入任意尺寸的图片矩阵经过 P-Net 后可以看做经历了一个完整的卷积(kernel = 12,stride = 2),输出是 (H’,W’,32)。例如如果输入是 (48,48,3) 的图片矩阵,经过 P-Net 后输出为 (19,19,32) 了,并且 (19,19) 中每个二维点对应到原图中都是一个 (12,12) 的视野区域,可以理解为对原图进行了卷积的滑动并分别计算每个 (12,12) 窗口的人脸概率以及框回归;
- P-Net 实际上对输出特征图的 每一个像素格子 都进行人脸概率、边框、地标预测,因此开始时的预测框数量非常多,要根据人脸概率的阈值先进行初步筛选,在进行边界框的 非极大值抑制。那这里就有疑问了,为什么可以对每一个像素方格进行预测?这里可以在后面的 图像金字塔 中再做解释;
- 在实际测试中,P-Net 的输出中不包括 landmark。
R-Net 的网络结构如下:
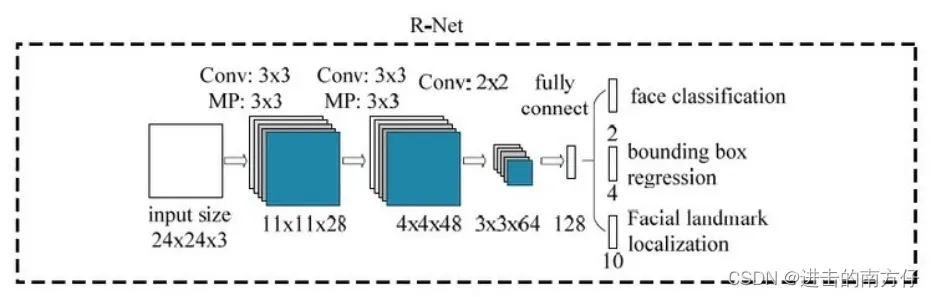
由于 P-Net 是对输出特征图的每一个像素进行预测,因此结果十分冗杂,所以接下来使用 R-Net 进一步优化。R-Net 和 P-Net 类似,不过这一步的输入是前面 P-Net 生成的边界框,不管实际边界框的大小,在输入 R-Net 之前,都需要缩放到 (24,24,3)。网络的输出和 P-Net 是一样的。这一步的目的主要是为了去除大量的非人脸框。
O-Net 的网络结构如下:
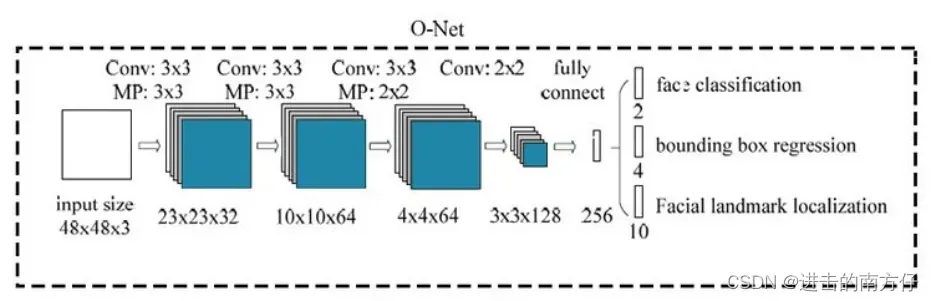
进一步将 R-Net 的所得到的区域缩放到 (48,48,3),输入到最后的 O-Net,O-Net 的结构与 P-Net 类似,只不过在测试输出的时候多了关键点位置的输出。输入大小为 (48,48,3) 的图像,输出包含 n 个人脸概率、边界框的偏移量和关键点的偏移量。三个字网络流程如下:
2 图像金字塔
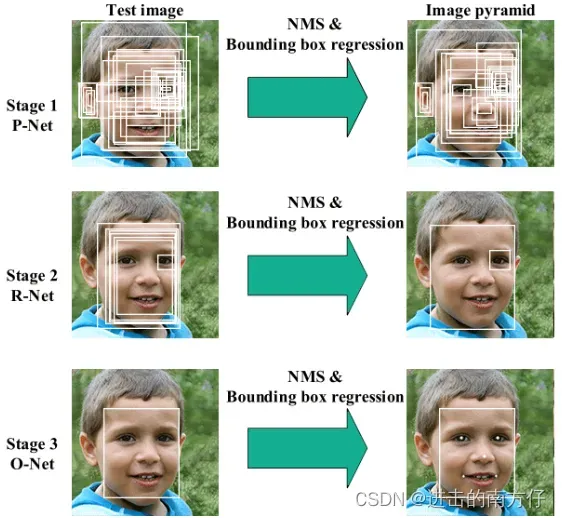
MTCNN基于卷积神经网络,通常只适用于检测一定尺寸范围内的人脸,比如其中的 P-Net,用于判断 12 × 12 大小范围内是否含有人脸,但是输入图像中人脸的尺寸未知,需要构建图像金字塔获得不同尺寸的图像,缩放图像是为了将图像中的人脸缩放到网络能检测的适宜尺寸,只要某个人脸被放缩到 12 × 12 左右,就可以被检测出来,下图为MTCNN人脸检测流程。

在人脸检测中,通常要设置要原图中要检测的最小人脸尺寸,原图中小于这个尺寸的人脸不必关心,MTCNN 代码中为 minsize = 20,MTCNN P-Net 用于检测 12 × 12 大小的人脸,这需要我们将不同的人脸大小都要缩放到 12 × 12。在 P-Net 中我们为什么可以对输出特征图中的每一个像素方格进行预测,正是因为原图中的人脸都被缩放到 12 × 12,而且输出特征图的感受野正是 12 × 12。
Tips:
人脸检测中的图像金字塔构建,涉及如下数据:
- 输入图像尺寸:
(h, w); - 最小人脸尺寸:
min_face_size; - 最大人脸尺寸:
max_face_size,如果不设置,为图像高宽中较短的那个; - 网络/方法能检测的人脸尺寸:
net_face_size; - 金字塔层间缩放比率:
factor;
缩放图像是为了将图像中的人脸缩放到网络能检测的适宜尺寸,图像金字塔中:
- 最大缩放尺度(最小缩小比例):
max_scale = net_face_size / min_face_size; - 最小缩放尺度(最大缩小比例):
min_scale = net_face_size / max_face_size; - 中间的尺度:
scale_n = max_scale * (factor ^ n); - 对应的图像尺寸为:
(h_n, w_n) = (h * scale_n, w_n * scale_n); - 保证
min(h_n, w_n) >net_face_size。
注: 缩小比例为缩放尺寸的倒数。
在 MTCNN 的实际测试中,如果输入图像为 (100,120),其中人脸最小为 (20,20),最大为 (20,20)——对应图像较短边长,为了将人脸放缩到 (12,12),同时保证相邻层间缩放比率 factor = 0.709,依据上述公式则最大缩放尺度为 12 / 20,最小缩放尺度为 12 / 20,金字塔中图像尺寸依次为 (60,72)、(52,61)、(36,43)、(26,31)、(18,22)、(13,16),其中 (60,72) 对应把 (20,20) 的人脸缩放到 (12,12),(13,16)对应把 (100,100) 的人脸缩放到 (12,12),在保证缩放比率一致的情况下近似。
综上,构建图像金字塔有两个步骤:
- 给定输入图像,根据设置的最小人脸尺寸以及网络能检测的人脸尺寸,确定最大缩放图像和最小缩放图像;
- 根据设置的金字塔层间缩放比率,确定每层图像的尺寸。
3 其他
Tips:
- 测试时只使用 onet.eval(),这是因为只有 O-Net 中有 Dropout 层。如果模型中有 BN 层和 Dropout,在测试时添加 model.eval()。model.eval() 是保证 BN 层能够用全部训练数据的均值和方差,即测试过程中要保证 BN 层的均值和方差不变。对于 Dropout,model.eval() 是利用到了所有网络连接,即不进行随机舍弃神经元;
- 将 255 的 RGB 图像归一化到了 [-1,1] 的区间,归一化操作,加快收敛速度。由于图片每个像素点上是 [0,255] 的数,都是非负数,对每个像素点做 (x – 127.5) / 128,可以把 [0,255] 映射为 (-1,1)。有正有负的输入,损失函数收敛速度更快。因为 MTCNN 的训练中有次操作,因此测试时也要做。
4 效果
本次代码实现了两种检测方式:静态图像检测和摄像头实时检测。GitHub:https://github.com/aishangcengloua/mtcnn-PyTorch
- 静态图像检测
from src import FaceDetector
from PIL import Image
# 人脸检测对象。优先使用GPU进行计算
detector = FaceDetector()
image = Image.open("./images/face_1.jpg")
# 检测人脸,返回人脸位置坐标
bboxes, landmarks = detector.detect(image)
# 绘制并保存标注图
drawed_image = detector.draw_bboxes(image)
drawed_image.save("./images/drawed_image.jpg")
drawed_image.show()
# 裁剪人脸图片并保存
# face_img_list = detector.crop_faces(image, size=64)
# for i in range(len(face_img_list)):
# face_img_list[i].save("./images/face_" + str(i + 1) + ".jpg")

- 摄像头实时检测
import cv2
from src import FaceDetector
from PIL import Image
import numpy as np
detector = FaceDetector()
def camera_detect():
video = cv2.VideoCapture(0)
while True:
ret, frame = video.read()
# 将 OpenCV 格式的图片转换为 PIL.Image,注意 PIL 图片是 (width, height)
pil_im = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
# 绘制带人脸框的标注图
drawed_pil_im = detector.draw_bboxes(pil_im)
# 再转回 OpenCV 格式用于视频显示
frame = cv2.cvtColor(np.asarray(drawed_pil_im), cv2.COLOR_RGB2BGR)
cv2.imshow("Face Detection", frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
video.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
camera_detect()
5 参考
- https://its301.com/article/weixin_41721222/88084549
- https://www.i4k.xyz/article/yanxueotft/99696057
- https://www.twblogs.net/a/5eef9bb51f92b2f1a17d09ef/?lang=zh-cn
- https://github.com/inkuang/MTCNN-PyTorch
- https://github.com/TropComplique/mtcnn-pytorch
- https://github.com/kpzhang93/MTCNN_face_detection_alignment
- Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
文章出处登录后可见!