在论文A Survey on Deep Learning(深度学习(Deep learning)) for Named Entity Recognition 中对NER工作进行了详尽的介绍。本文根据综述的行文顺序,快速的介绍NER使用的技术,并在最后一小节中附上bert+softmax与bert+crf的相关代码。
标注方案
- BIO
- BIOES
B,开始位置
I,中间位置
E,结束位置
O,other
S,single
问题建模
给定一个符号(symbol)(Token)序列 s=(w1,w2,...,wN)s = (w_1, w_2, …, w_N)s=(w1,w2,...,wN), NER的任务就是要输出一个元组序列 (Is,Ie,t)(I_s, I_e, t)(Is,Ie,t), 其中每一个元组表示序列s中出现的一个命名实体。 其中,Is∈[1,N],Ie∈[1,N]I_s \in [1,N], I_e \in [1,N]Is∈[1,N],Ie∈[1,N], 分别代表实体在符号(symbol)序列中的位置,ttt表示该实体的类(Cluster)别。比如:

评价指标
- 宽松匹配评估(Relaxed-match Evaluation):当实体位置区间部分重叠,或位置正确类(Cluster)别错误的,都记为正确或部分正确。但因为这样的评估方案不够直观,对于错误分析很不友好,所以并没有被广泛采用。
- 严格匹配评估(Exact-match Evaluation):当且仅当实体位置区间和类(Cluster)别都正确时判定其为正确。其中F1值又可以分为macro-averaged和micro-averaged,前者是按照不同实体类(Cluster)别计算F1,然后取平均;后者是把所有识别结果合在一起,再计算F1。 这两者的区别在于实体类(Cluster)别数目不均衡,因为通常语料集中类(Cluster)别数量分布(Distribution)不均衡,模型往往对于大类(Cluster)别的实体学习较好。
常用的NER方法

如上图所示,常用的NER方法主要分为四个大类(Cluster):
- 基于规则
- 无监督任务
- 基于人工特征的监督学习(Supervised learning)方法
- 深度学习(Deep learning)方法
目前,深度学习(Deep learning)方法是NER常用的方法,本文具体介绍深度学习(Deep learning)方法。
深度学习(Deep learning)方法(in survey)
本小结按照 综述 的顺序简要介绍 NER中常用的深度学习(Deep learning)方法。

输入(input)的分布(Distribution)式表示
输入(input)的分布(Distribution)式可以分为:词语级别表示、字符级别表示和混合(Mixing)表示。
-
词语级别表示: (word2vec/fasttest/glove等),对于英文而言就是单词,比如 hello。而对中文而言,可能字符级别的表示要更好一些,这是因为基于此的中文NER会受分词效果的影响,切词错误会传递到NER中,会造成累计误差。 但是也有的论文利用了中文词级别的信息来做的,比如:Lattice LSTM。
-
字符级别的表示:(CNN/RNN)。字符级别的表示方法可以比较有效地挖掘如前缀、后缀等sub-word级别的信息,另一方面的优势在于其天然地可以解决OOV问题。

对于中文而言,字符级别是比较常用的表示,但是每个字通常具有多重含义,比如说:“花哨”、“花茶”中的“花”显然含义不同;因此,想要捕捉语义层面的信息的话,就需要对上下文语义进行建模从而充分表达字的含义,常见的就是用CNN来做,RNN也可以。比如,18年的一项工作《Contextual String Embeddings for Sequence Labeling》,使用字符级别的神经语言模型(Neural Language Model)(language model)产生上下文相关的文本嵌入(Embedding)。大致思路为使用双向RNN编码(code)字符级别嵌入(Embedding),将一个词的前向和后向隐层状态与词嵌入(Embedding)(Word embedding)拼接作为最终词嵌入(Embedding)(Word embedding)向量,如下图所示。源码位置

-
混合(Mixing)表示:部分研究在词语级别和字符级别外还引入了其他额外信息,如词语相似度、语义依存关系、视觉特征、知识图谱(knowledge graph)等。某种程度上而言,使用Token Embedding、Position Embedding等预训练(pretraining)得到的类(Cluster)BERT模型也可以划分到混合(Mixing)表示方法中。
上下文编码(code)
- CNN: 如下图所示,主要用于捕捉局部依赖(dependency)特征。虽然可以通过多层CNN的叠加加大感受野而得到全局特征,但是,对于NER来说,这种长程依赖(dependency)性还是不足。因此,CNN大多后面可以接LSTM或者attention来强化长程依赖(dependency)能力。

- RNN,常用的有LSTM和GRU,可以获得较好的长程依赖(dependency)能力。而且由于门机制的存在,也能获得较好的局部依赖(dependency)性。在NLP中常用BILSTM获得上下文特征。

- 递归神经网络(Recursive Neural Network)。把句子当作树状结构而非序列进行处理,从理论上而言具有更强的表示能力,但其存在样本标注难度大(需标注语法解析树(Parse tree))、深层易梯度(gradient)消失、难以并行计算等弱点,因此在实际应用中使用较少。
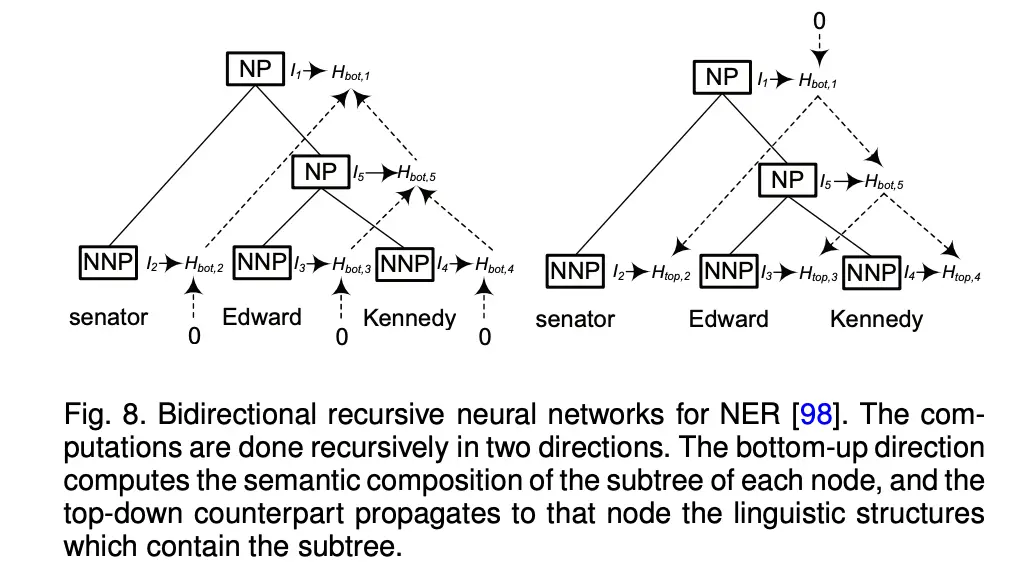
- Transformer:是近年来使用广泛的网络,transformer在长距离文本依赖(dependency)上相较RNN有更好的效果。
但是将transformer直接应用于NER任务时,可能效果不那么理想,原因可能是对于NER而言,它需要的是:(1)局部依赖(dependency)的捕捉;(2)位置信息;(3)更 sharp 的attention 分布(Distribution)(NER不需要太多的全局信息)。有论文表明,这些问题解决后,呈现出比CNN+BiLSTM+CRF更好的效果。
- 语言模型(language model):大规模预训练(pretraining)语言模型(language model)近年来在各种NLP任务中取得巨大成功,如GPT(Generative Pre-trained Transformer)、ELMo、BERT等。这些预训练(pretraining)语言模型(language model)不但有效地捕捉了文本中的上下文关系,且不需要如Word2Vec、GloVe等传统词向量进行分布(Distribution)式表示。
解码器(decoder)
标注解码器(decoder)是NER模型的最后一部分,其将经过上下文编码(code)器得到的表征作为输入(input),常用的解码器(decoder)组合有:MLP+Softmax,CRF,RNN,Pointer Networks等。
先说MLP+softmax和CRF:
CRF有一系列特征函数,相当于增加了一系列约束条件。比如说:E 后面跟 B的可能性比E后面跟I的可能性(这个几乎不可能)要大得多。但是softmax就不存在这样的约束,这样的话就相当于这一部分需要在放在前面的模型去学习。这也就是为什么CRF解码器(decoder)如此常见的原因。
但是,为什么Bert+CRF相对于Bert+softmax性能没什么提升呢?甚至有的时候会带来一些负面影响?
可以参考 你的 CRF 层的学习率(Learning rate)可能不够大 这篇文章。
简单来说就是,BERT 的拟合能力太强了,导致不需要转移矩阵(matrix)效果都很好。而不好的转移矩阵(matrix)会给结果带来负面的影响。
RNN:
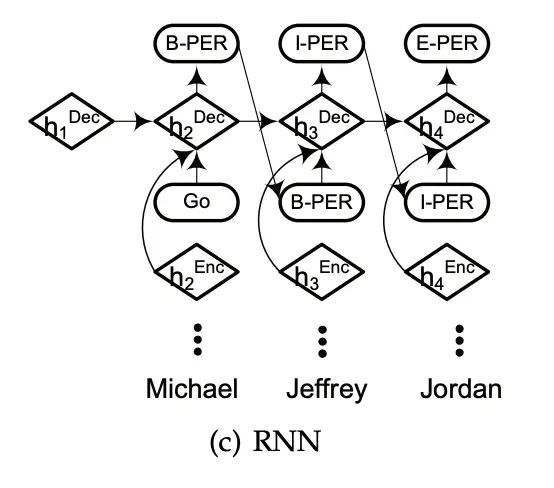
Pointer Networks:使用指针网络解码,是将NER任务当作先识别“块”即实体范围,然后再对其进行分类(Cluster)。指针网络通常是在Seq2seq框架中

实践
Bert + Softmax
class BertSoftmax(BertPreTrainedModel): # 大部分与transformer 提供的BertForTokenClassification相同,这里只是改了点loss
# config 来自bertconfig,其实本质是一个分类(Cluster)问题。即每个token属于什么类(Cluster)别
def __init__(self,config):
super(BertSoftmax, self).__init__(config)
self.num_labels = config.num_labels
self.bert = BertModel(config)
self.dropout = nn.Dropout(Dropout)(config.hidden_dropout_prob)
self.classifier=nn.Linear(config.hidden_size,config.num_labels)
self.loss_type=config.loss_type
self.init_weights()
def forward(self, input_ids, attention_mask=None, token_type_ids=None, labels=None):
# last hidden state,pooler output, past_key_values, hidden_states,attentions,cross_attentions
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
sequence_output = outputs[0]
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output)
outputs = (logits,) + outputs[2:] # add hidden states and attention if they are here
if labels is not None:
loss_fct = CrossEntropyLoss(ignore_index=0)
if attention_mask is not None:
active_loss = attention_mask.view(-1) == 1
active_logits = logits.contiguous().view(-1, self.num_labels)[active_loss]
active_labels = labels.contiguous().view(-1)[active_loss]
loss = loss_fct(active_logits, active_labels)
else:
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
outputs = (loss,) + outputs
return outputs # (loss), scores, (hidden_states), (attentions)
Bert + CRF
CRF: 这里展示的代码没展示解码(也就是维特比算法(Viterbi algorithm)):
# CRF class
class CRF(nn.Module):
"""
发射矩阵(matrix)(来自于bert层),其shape为(seq_length,batch_size,num_tags),如果batch_first=true,那么应该是(batch_size,seq_length,num_tags)
转移矩阵(matrix):shape是(num_tags,num_tags)
训练: 主要是计算max的正确路径/总路径的大小
预测: 维特比算法(Viterbi algorithm)
"""
def __init__(self,num_tags,batch_first=False):
super().__init__()
self.num_tags=num_tags
self.batch_first=batch_first
# 转移矩阵(matrix)
self.transitions=nn.Parameter(torch.empty(num_tags, num_tags))
# 初始化
self.init_parameter()
def init_parameter(self):
nn.init.uniform_(self.transitions, -0.1, 0.1)
def forward(self, emissions,tags,mask):
"""
batch_first表征batch是不是在头部
emissions: 从bert层传过来的发射矩阵(matrix)。
tags: seq labels, shape:(seq_length, batch_size)
mask: mask tensor, shape:(seq_length,batch_size)
返回值: log likelihood, shape: (batch_size,)
"""
# 处理mask的格式
if mask is None:
# 如果mask是None,那么所有的分数都是有效的
mask = torch.ones_like(tags, dtype=torch.uint8, device=tags.device)
if mask.dtype != torch.uint8:
mask = mask.byte()
# 处理batch first
if self.batch_first:
emissions = emissions.transpose(0, 1)
tags = tags.transpose(0, 1)
mask = mask.transpose(0, 1)
# 计算正确的label的分数
# shape: (batch_size,)
numerator = self._compute_score(emissions, tags, mask)
# 计算归一化(Normalization)因子
denominator = self._compute_normalizer(emissions, mask)
# shape: (batch_size,)
llh = numerator - denominator
return llh.sum() / mask.float().sum()
def _compute_score(self,emissions,tags,mask):
# 需要计算point label 和 trans_label
seq_length, batch_size = tags.shape
mask = mask.float()
score = torch.zeros(batch_size)
# shape:(batch_size,)
# 第一步,加的是所有batch的seq第0个位置的point score
# tags[0]:(batch_size,)
# emissions (seq_len,batch_size,num_tags)
score += emissions[0, torch.arange(batch_size),tags[0]]
# 开始计算转移分数 与 余下的point分数
for i in range(1,seq_length):
# 如果这个分数是有效的,则加入(mask=1)
score += emissions[0, torch.arange(batch_size),tags[i]] * mask[i]
# 开始计算转移分数
score += self.transitions[tags[i - 1], tags[i]] * mask[i]
return score
def _compute_normalizer(self,emissions,mask):
# 计算归一化(Normalization)因子,逐标签得分 + 转移概率得分(考虑的是全状态)
# return:归一化(Normalization)分数,shape:(batch_size,)
# emissions (seq_len,batch_size,num_tags)
seq_length = emissions.size(0)
# 考虑某一个batch,每一个num_tags可以作为一个hidden state(考虑rnn的图,所以一开始应该是 batch_size, num_tags)
score = emissions[0] # shape:(batch_size,num_tags) 这个是在位置0每个num_tags的标签得分
for i in range(1,seq_length):
# shape : (batch_size, num_tags, 1)
# 之前的state h_t
broadcast_score = score.unsqueeze(2)
# shape: (batch_size, 1, num_tags)
# x_t+1
broadcast_emissions = emissions[i].unsqueeze(1)
# h_t+1 = f(h_t,x_t+1), h_t+1=h_t*x_t+1*g
next_score = broadcast_score + self.transitions + broadcast_emissions
# (batch_size,num_tags,num_tags)
next_score = torch.logsumexp(next_score, dim=1)
# Set score to the next score if this timestep is valid (mask == 1)
# (seq_length,1, batch_size)
score = torch.where(mask[i].unsqueeze(1), next_score, score)
# (batch_size,)
return torch.logsumexp(score, dim=1)
Bert+CRF:
class BertCRF(BertPreTrainedModel):
def __init__(self,config):
super(BertCRF, self).__init__(config)
self.bert=BertModel(config)
self.dropout=nn.Dropout(Dropout)(config.hidden_dropout_prob)
# 这是crf的发射概率
self.classifier=nn.Linear(config.hidden_size,config.num_labels)
self.crf = CRF(num_tags=config.num_labels, batch_first=True)
self.init_weights()
def forward(self, input_ids, token_type_ids=None, attention_mask=None,labels=None):
# last hidden state,pooler output, past_key_values, hidden_states,attentions,cross_attentions
outputs =self.bert(input_ids = input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)
sequence_output = outputs[0]
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output)
outputs = (logits,)
if labels is not None:
loss = self.crf(emissions = logits, tags=labels, mask=attention_mask)
outputs =(-1*loss,)+outputs
return outputs # (loss), scores
参考
A Survey on Deep Learning(深度学习(Deep learning)) for Named Entity Recognition
最通俗易懂的BILSTM-CRF的CRF层介绍
简明条件随机场(Conditional random field)CRF介绍 | 附带纯Keras实现
keras实现源码
BERT标注为何不使用CRF
NER综述
命名实体识别(Named entity recognition)NER
NER论文大礼包
版权声明:本文为博主一只小菜狗:D原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。