文章目录
- 前期准备
- 1.通过DataFrame保存为EXCEL
- 2.查看数据行列数
- 3.提取popularity列中值大于3小于7的行
- 4.交换两列的位置
- 5.提取popularity列最大的行所在行
- 6.查看最后3行数据
- 7.删除最后一行数据
- 8.添加一行数据
- 9.队数据按照popularity列的值的大小进行排序
- 10.统计grammer列每个字符串的长度
前期准备
准备后期要使用的数据,使用字典创建DataFrame对象
import pandas as pd
import numpy as np
data = {
'grammer':['python','java','go',np.nan,'python','C','C++'],
'popularity':[1,np.nan,np.nan,4,5,7,8]
}
df = pd.DataFrame(data)
df

1.通过DataFrame保存为EXCEL
保存文件的函数一般是 to_xxx
# 保存为EXCEL文件
df.to_excel('text.xlsx')
# 保存为csv文件
df.to_csv('text.csv')
2.查看数据行列数
通过DataFrame的对象的属性查看数据行列数
也可以通过其他的方式进行查询,但是这种是最便捷的
# .shape是属性 不用加括号
df.shape
3.提取popularity列中值大于3小于7的行
使用的是布尔值索引还有进行合取操作
df[(df['popularity']>3) & (df['popularity']<7)]

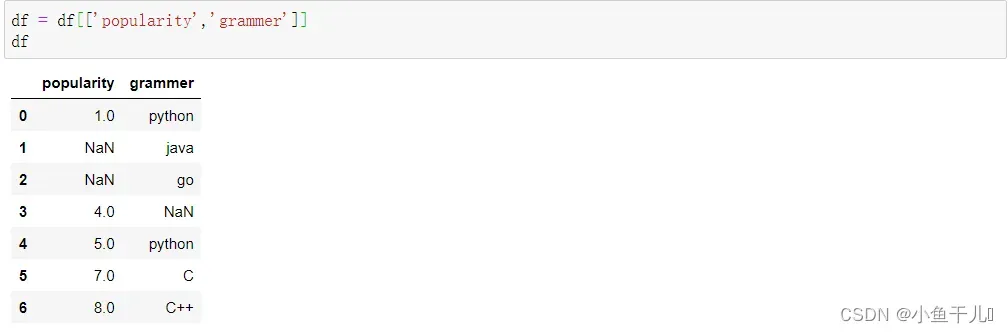
4.交换两列的位置
其实这个交换位置,内在的逻辑就是先取出交换后的数据,再将交换后的数据重新赋值给df
df = df[['popularity','grammer']]
df
5.提取popularity列最大的行所在行
使用到了max函数同样还有min函数,
使用这个方法避免了数据中出现两个最大值而而只取出一个的情况。
df[df['popularity']== df['popularity'].max()]

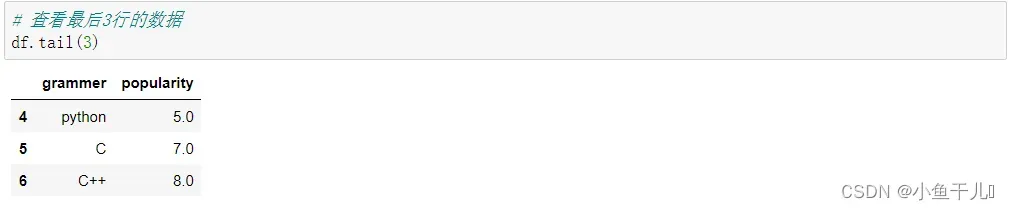
6.查看最后3行数据
使用的是tail()函数,默认是最后5行,在括号里面传入X就会返回最后X条
同样还用head() 用法是一样的
# 查看最后3行的数据
df.tail(3)
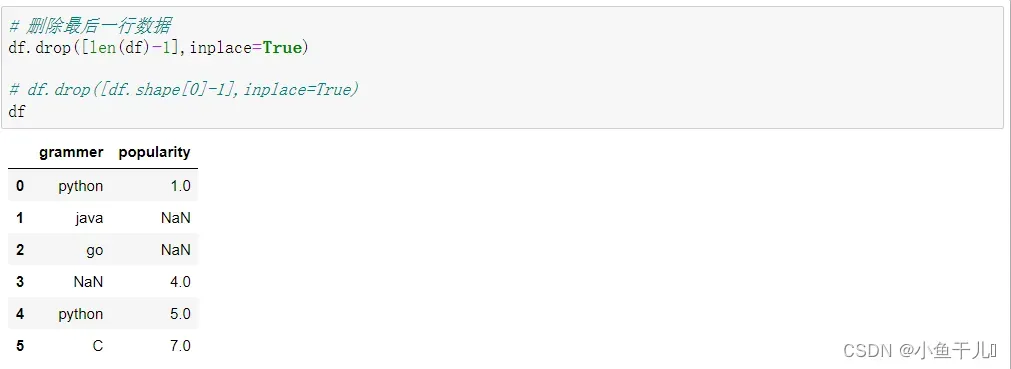
7.删除最后一行数据
主要的思路是选中最后一行,然后删除,这种方式还可以删除多行
# 方式1
df.drop([len(df)-1],inplace=True)
# 方式2
df.drop([df.shape[0]-1],inplace=True)
df
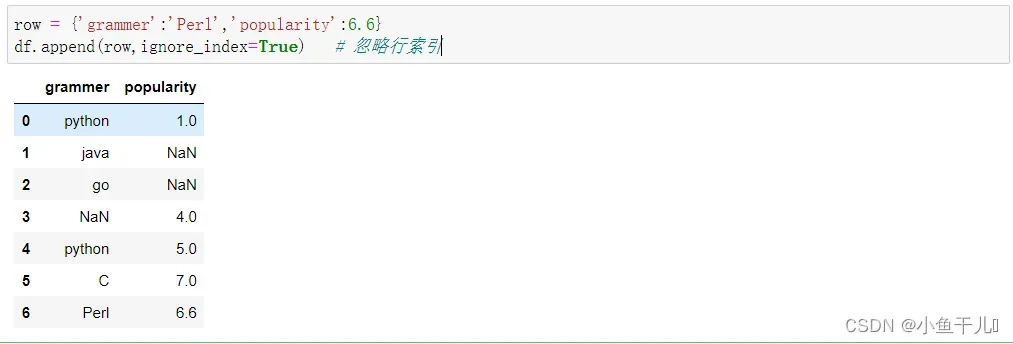
8.添加一行数据
append() 添加数据,使用字典添加,字典的键是列名,值是要添加的数据,如果字典的键在DataFrame
中不存在,则会新建一列,其余的行设置为NaN
row = {'grammer':'Perl','popularity':6.6}
df.append(row,ignore_index=True) # 忽略行索引
9.队数据按照popularity列的值的大小进行排序
使用sort_values函数,按值排序,默认是升序 添加参数ascending=False可以变为降序
df.sort_values('popularity') # 不会修改原数据
df.sort_values('popularity',inplace=True) # 修改原数据

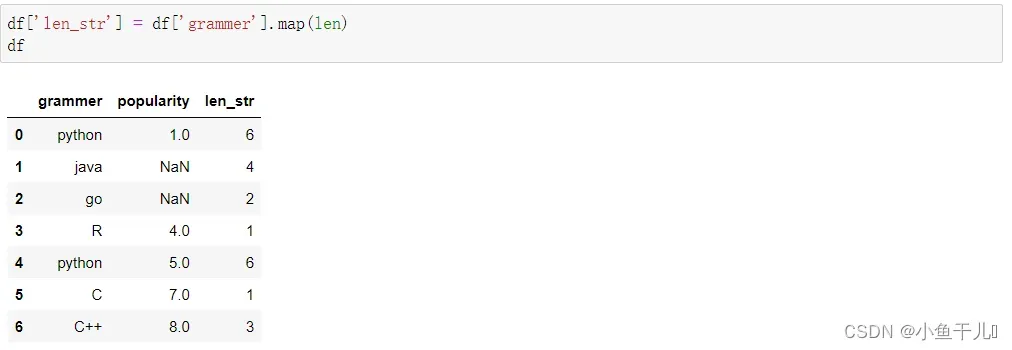
10.统计grammer列每个字符串的长度
因为计算字符的长度,不能为NaN不然会报错,所以我们在计算字符串的长度的时候可以选择先将孔空缺的数据填充上去,然后在计算长度
df['grammer'] = df['grammer'].fillna("R") # 将空缺的数据填充为R 也可以填充为一个空字符
df['len_str'] = df['grammer'].map(len) # 使用map函数,map函数传入一个函数,每一行的数据会依次调用这个函数
df
今天这10道题还是比较轻松的,希望大家能够多多拓展,拓宽自己的思路,尝试一些新的方法。
这里我推荐大家去 牛客网 继续练习,牛客网里面有相应题目的专项突破
文章出处登录后可见!
已经登录?立即刷新