目录
1 朴素贝叶斯的算法原理
2 一维特征变量下的贝叶斯模型
3 二维特征变量下的贝叶斯模型
4 n维特征变量下的贝叶斯模型
5 朴素贝叶斯模型的sklearn实现
6 案例:肿瘤预测模型
6.1 读取数据与划分
6.1.1 读取数据
6.1.2 划分特征变量和目标变量
6.2 模型的搭建与使用
6.2.1 划分训练集和测试集
6.2.2 模型搭建
6.2.3 模型预测与评估
参考书籍
1 朴素贝叶斯的算法原理
贝叶斯分类是机器学习中应用极为广泛的分类算法之一。
朴素贝叶斯是贝叶斯模型当中最简单的一种,其算法核心为如下所示的贝叶斯公式。
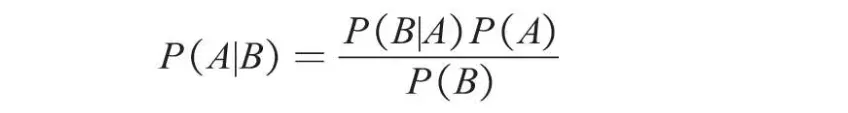
其中P(A)为事件A发生的概率,P(B)为事件B发生的概率,P(A|B)表示在事件B发生的条件下事件A发生的概率,同理P(B|A)则表示在事件A发生的条件下事件B发生的概率。
举一个简单的例子:已知冬季一个人感冒(事件A)的概率P(A)为40%,一个人打喷嚏(事件B)的概率P(B)为80%,一个人感冒时打喷嚏的概率P(B|A)为100%,那么如果一个人开始打喷嚏,他感冒的概率P(A|B)为多少?求解过程如下。
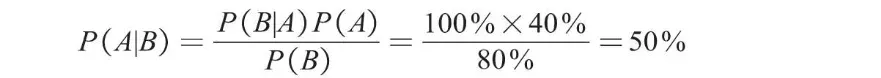
2 一维特征变量下的贝叶斯模型
以一个详细的例子来说:如何判断一个人是否感冒。假设已经有5组样本数据,见下表。
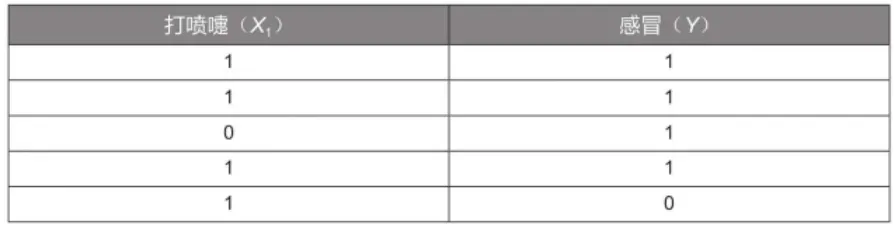
只选取了一个特征变量“打喷嚏(X1)”,其值为1表示打喷嚏,为0表示不打喷嚏;目标变量是“感冒(Y)”,其值为1表示感冒,为0表示未感冒。
现在要根据上述数据,利用贝叶斯公式预测一个人是否感冒。
例如,一个人打喷嚏了(X1=1),那么他是否感冒了呢?这个问题实际上是要预测他感冒的概率P(Y|X1)。将特征变量和目标变量代入贝叶斯公式,可获得如下所示的计算公式。
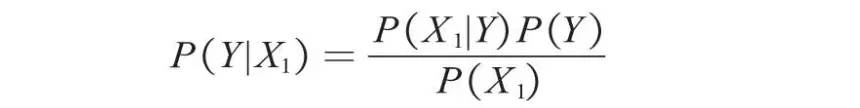
根据上述数据,可以计算在打喷嚏(X1=1)的条件下,感冒(Y=1)的概率,计算过程如下。
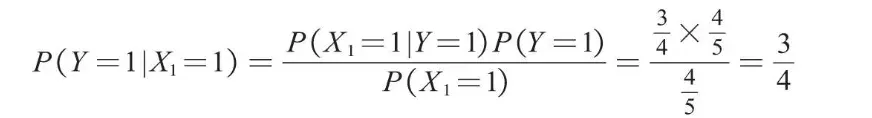
其中P(X1=1|Y=1)为在感冒的条件下打喷嚏的概率,这里感冒的4个样本中有3个样本打喷嚏,所以该概率为3/4;P(Y=1)为所有样本中感冒的概率,这里5个样本中有4个样本感冒,所以该概率为4/5;P(X1=1)为所有样本中打喷嚏的概率,这里5个样本中有4个样本打喷嚏,所以该概率为4/5。
同理,在打喷嚏(X1=1)的条件下,未感冒(Y=0)的概率的计算过程如下。
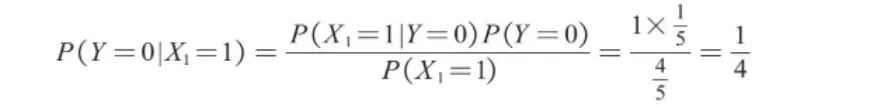
其中P(X1=1|Y=0)为在未感冒的条件下打喷嚏的概率,为1;P(Y=0)为所有样本中未感冒的概率,为1/5;P(X1=1)为所有样本中打喷嚏的概率,为4/5。
因为3/4大于1/4,所以在打喷嚏的条件下感冒的概率要高于未感冒的概率。
3 二维特征变量下的贝叶斯模型
在上边的一个特征变量的基础上加入另一个特征变量——头痛(X2),其值为1表示头痛,为0表示不头痛;目标变量仍为感冒(Y)。样本数据见下表。
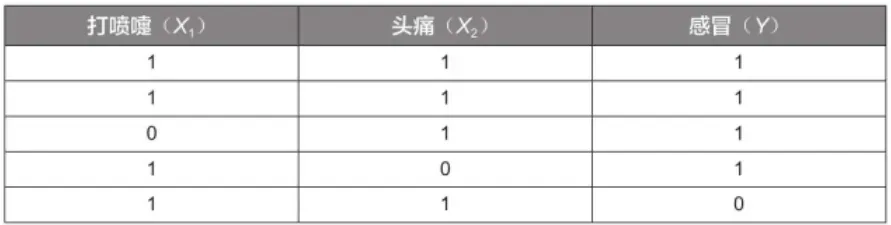
根据上述数据,仍利用贝叶斯公式来预测一个人是否感冒。例如,一个人打喷嚏且头痛(X1=1,X2=1),那么他是否感冒了呢?这个问题实际上是要预测他感冒的概率P(Y|X1,X2)。将特征变量和目标变量代入贝叶斯公式,可获得如下所示的计算公式。
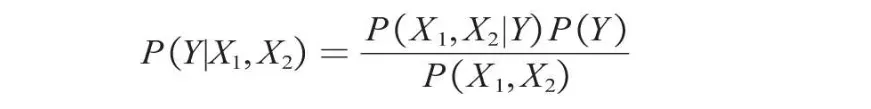
现在要计算并比较P(Y=1|X1,X2)与P(Y=0|X1,X2)的大小,由上述公式可知,两者的分母P(X1,X2)是相同的,所以直接计算并比较两者的分子P(X1,X2|Y)P(Y)的大小即可。
在计算之前,需要先引入朴素贝叶斯模型的独立性假设:朴素贝叶斯模型中的各个特征之间相互独立,即P(X1,X2|Y)=P(X1|Y)P(X2|Y)。因此,分子的计算公式可以转换为如下形式。
在独立性假设的前提下,计算打喷嚏且头痛(X1=1,X2=1)的条件下感冒(Y=1)的概率P(Y=1|X1=1,X2=1),就转化为计算P(X1=1|Y=1)P(X2=1|Y=1)P(Y=1)的值,计算过程如下。
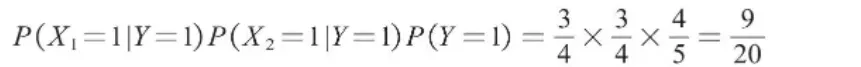
同理,计算打喷嚏且头痛(X1=1,X2=1)的条件下未感冒(Y=0)的概率P(Y=0|X1=1,X2=1),即转化为计算P(X1=1|Y=0)P(X2=1|Y=0)P(Y=0)的值,计算过程如下。
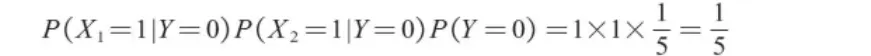
因为9/20大于1/5,所以在打喷嚏且头痛的条件下感冒的概率要高于未感冒的概率。
4 n维特征变量下的贝叶斯模型
在2个特征变量的基础上将贝叶斯公式推广至n个特征变量X1,X2,…,Xn,公式如下。
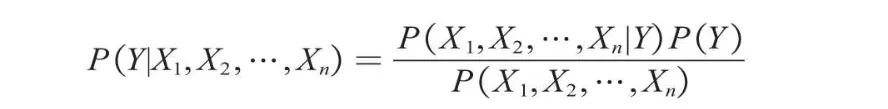
朴素贝叶斯模型假设给定目标值后各个特征之间相互独立,分子的计算公式可以写成如下形式。
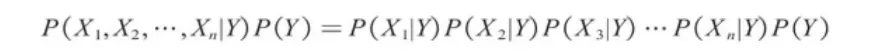
其中P(X1|Y)、P(X2|Y)、P(Y)等数据都是已知的,由此可以计算在n个特征变量取不同的值的条件下,目标变量取某个值的概率,并且选择概率更高者对样本进行分类。
5 朴素贝叶斯模型的sklearn实现
# 这里用的是高斯贝叶斯模型
from sklearn.naive_bayes import GaussianNB
X = [[1,2],[3,4],[5,6],[7,8],[9,10]]
y = [0,0,0,1,1]
model = GaussianNB()
model.fit(X,y)
model.predict([[5,5]])
# 输出结果
# array([0])6 案例:肿瘤预测模型
以一个医疗行业较为经典的肿瘤预测模型为例,讲解如何在实战中应用朴素贝叶斯模型来预测肿瘤为良性肿瘤还是恶性肿瘤。
肿瘤性质的判断影响着患者的治疗方式和痊愈速度。传统的做法是医生根据数十个指标来判断肿瘤的性质,预测效果依赖于医生的个人经验而且效率较低,而通过机器学习,我们有望能快速预测肿瘤的性质。
6.1 读取数据与划分
6.1.1 读取数据
首先通过如下代码导入某医院乳腺肿瘤患者的6个特征维度及肿瘤性质的数据。共569个患者,其中良性肿瘤358例、恶性肿瘤211例。
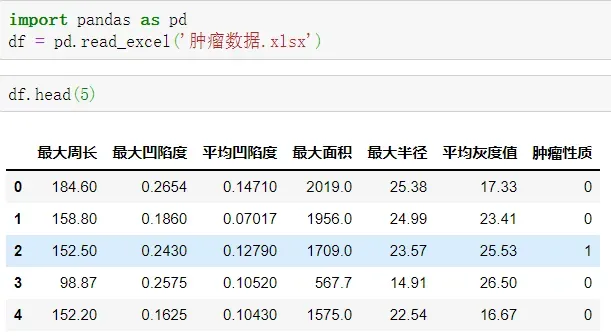
其中6个特征变量分别为“最大周长”“最大凹陷度”“平均凹陷度”“最大面积”“最大半径”“平均灰度值”。
目标变量为“肿瘤性质”,0代表肿瘤为恶性,1代表肿瘤为良性。
6.1.2 划分特征变量和目标变量

6.2 模型的搭建与使用
6.2.1 划分训练集和测试集

6.2.2 模型搭建
6.2.3 模型预测与评估
使用训练集拟合的模型对测试集进行预测。
利用创建DataFrame的相关知识点,汇总预测结果y_pred和测试集中的实际值y_test,代码如下。
注意:y_pred为一维数组,y_test为Series对象,需要统一类型
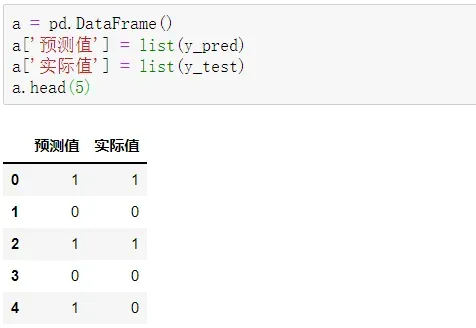
可以看到,前5项的预测准确度为80%。
通过如下代码可以查看所有测试集数据的预测准确度。
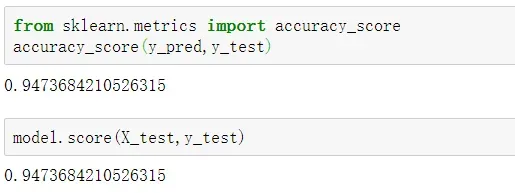
朴素贝叶斯模型属于分类模型,所以也可以利用ROC曲线来评估其预测效果。
from sklearn.metrics import roc_curve
fpr,tpr,thres = roc_curve(y_test,y_pred_proba[:,1])
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #设置正常显示中文
plt.plot(fpr,tpr)
plt.xlabel('假警报率')
plt.ylabel('命中率')
plt.title('ROC曲线')
plt.show()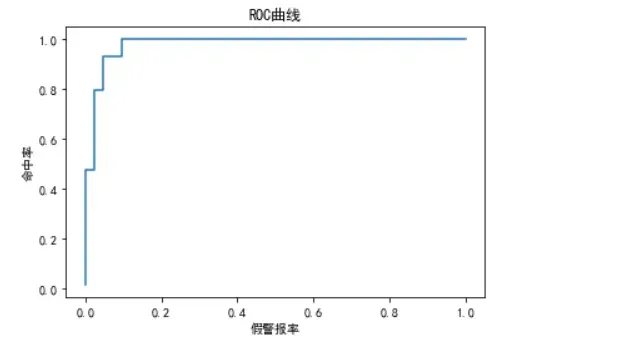
总结来说,朴素贝叶斯模型是一种非常经典的机器学习模型,它主要基于贝叶斯公式,在应用过程中会把数据集中的特征看成是相互独立的,而不需考虑特征间的关联关系,因此运算速度较快。相比于其他经典的机器学习模型,朴素贝叶斯模型的泛化能力稍弱,不过当样本及特征的数量增加时,其预测效果也是不错的。
参考书籍
《Python大数据分析与机器学习商业案例实战》
文章出处登录后可见!