前言:
最近在整理资料,顺便把部分干货写出来供学习以交流
一、scrapy的介绍
(1)何为框架?如何学习框架
-
框架就是一个集成了很多功能的一个通用性比较高的模板;
-
学习框架就学习框架中封装好的各种功能的使用方法即可。
(2)什么是scrapy?
scrapy就是python开发的一个通用性比较好的爬虫框架,同时scrapy在当今市场中的应用也是比较广泛
(3)scrapy的优缺点。
1.优点:
-
异步网络爬虫框架;
-
xpath的解析已经是直接封装到了scrapy之中,可以直接进行使用,就不再去使用正则或者bs4这样的一些解析不太方便的方法;
-
日志,拥有比较完善的统计以及日志系统;
-
拥有独立的shell终端环境,方便开发人员进行独立的调试;
-
过滤器,过滤一些不需要爬取的url以及数据等等;
-
管道,主要是用于异步保存爬取下来的数据。
2.缺点:
-
扩展性比较差(基本上常用的功能都已经是封装好的,所以如果要在已经实现的功能上去完善或者补充相关功能,难度比较大);
-
scrapy是一个异步网络框架(twisted)爬虫,运行过程中如果遇到了异常,框架的运行是不会被中断的,数据如果出现错误的话,是难以发现异常的;
-
位置,控制性比较低。
(4)scrapy中的五大组件及其他组件
1.引擎:负责scrapy框架中整个模块之间的通信以及数据的传输,属于五大组件中最核心的部分,如果缺少引擎,那么整个scrapy框架都将无法运行
2.调度器,用于存放引擎传过来的请求,也可以理解为用于存放需要请求的url的队列
3.下载器:用于向网站服务器发起请求,并且获取到网站服务器返回的响应对象(引擎、下载器、调度器,都不需要开发人员自己去编写代码,当创建好一个scrapy项目的时候,这三个组件就已经是存在了的)
4.爬虫组件:此处爬虫组件就不再负责请求的发起或响应的获取,只负责数据的提取
5.管道:主要也是由开发人员编写,主要功能是为了存储相关数据,也可以实现简单的数据分析工作
6.下载中间件:拦截请求或者响应,位置位于引擎与下载器之间,可以将拦截下来的请求或者响应中的信息进行修改之后再提交给载器或返回到引擎
7.爬虫中间件:位置:位于引擎与爬虫之间,主要作用就是在响应进入到爬虫之前对其进行拦截或者返回到引擎时,进行拦截

注意:所有模块(除引擎外)之间是相互独立的,只跟引擎进行交互,并不能直接交互。即各大组件(除了引擎之外)之间一定是不能够直接进行交流的
(5)scrapy工作流程
1.基本爬虫工作流程回顾
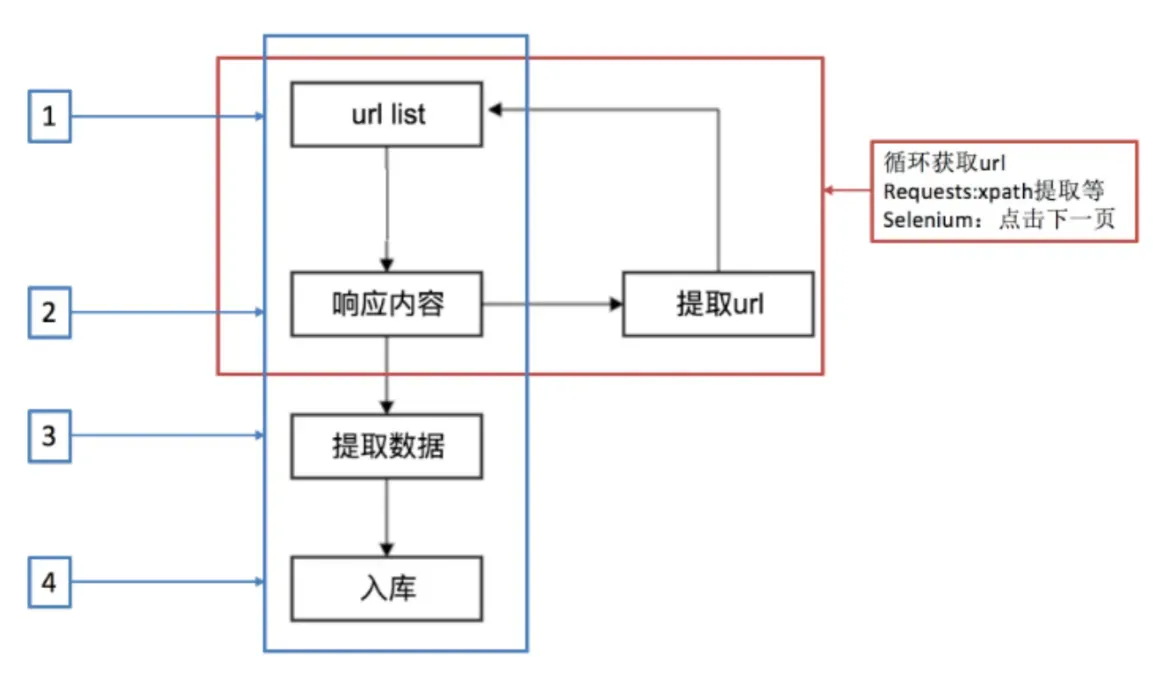
2.scrapy工作流程
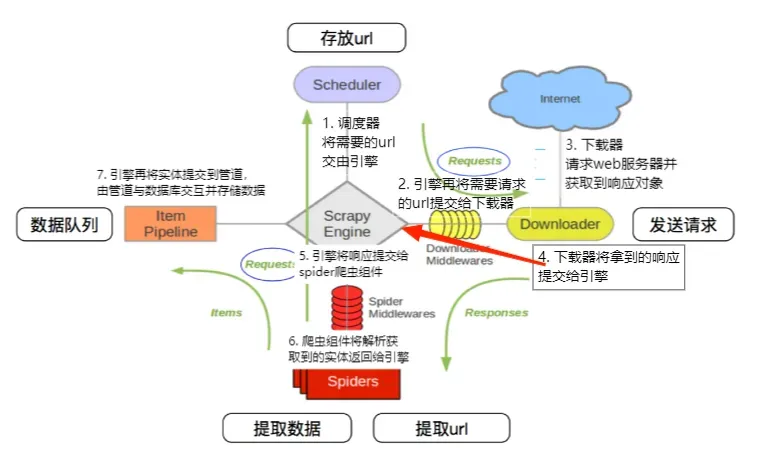
Scheduler(调度器) 将需要的url交由Scrapy Engine(引擎),引擎再将需要请求的url提交给 Downloader (下载器),下载器请求web服务器并获取到 Response(响应对象),下载器将拿到的响应提交给引擎,将响应提交给Spiders(爬虫组件),爬虫组件将解析获取到的实体返回给引擎,引擎再将实体提交到 Item Pipeline(管道),由管道与数据库交互并存储数据
二、scrapy框架的安装
(1)安装及其注意事项
Tips(可忽略):
-
建议先更新pip包管理工具:python -m pip install –upgrade pip
-
推荐安装2.5.1的scrapy版本,因为3.8以下的python版本不兼容2.5.1以上的scrapy
-
安装时最好换到国内下载源,以便自动安装依赖包。例如:pip install scrapy==2.5.1 -i https://pypi.douban.com/simple/
1.安装
安装命令:
pip install scrapy我这里因为本人的python版本是3.7所以安装的2.5.1版本的scrapy,用的是国内豆瓣源,故以下代码:
pip install scrapy==2.5.1 -i https://pypi.douban.com/simple/步骤一:在pycharm命令行(Terminal)下输入安装指定命令并回车

安装结束后,末行出现 Successfully 即为操作成功

步骤二:在控制台命令行输出scrapy,如果显示scrapy的版本号信息,则证明安装成功
步骤三: 若 安装失败 或 scrapy已存在 问题,可尝试卸载重装
卸载命令:
pip uninstall scrapy操作如图:
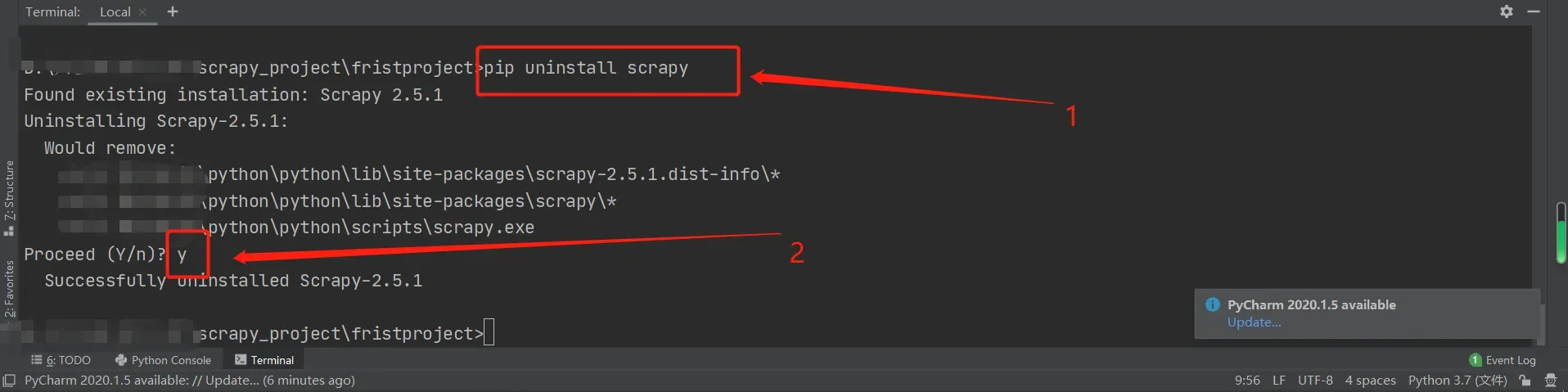
出现 Successfully 即为卸载操作成功!
三、scrapy基本命令
(1)创建scrapy项目:
scrapy startproject proName(项目名称)例如:scrapy startproject myproject
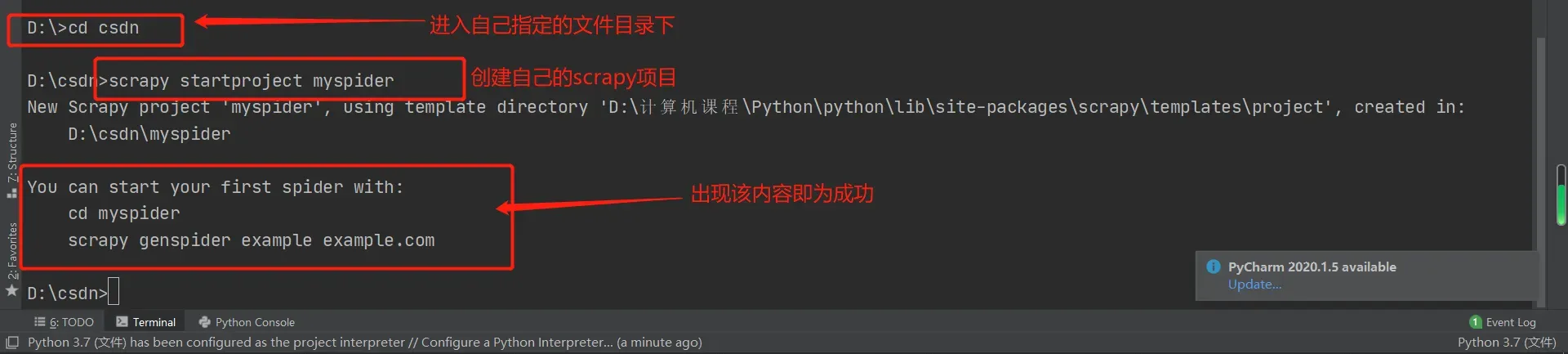
成功后会在该目录下生成对应项目文件:
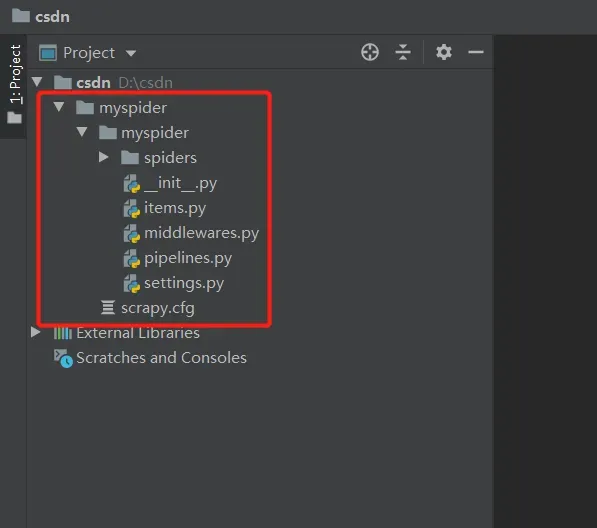
tips:
-
scrapy配置文件:默认情况下就是scrapy.cfg这个文件所在的目录就是项目根目录。这里的根目录即为第一个mysqider的路径
-
项目配置文件:一般情况下指的是子级项目文件夹中的settings文件
(2)显示scrapy的版本:
scrapy version(3)测试scrapy是否能够搭建成功能够运行:
scrapy bench
当出现类似内容时,即为测试成功
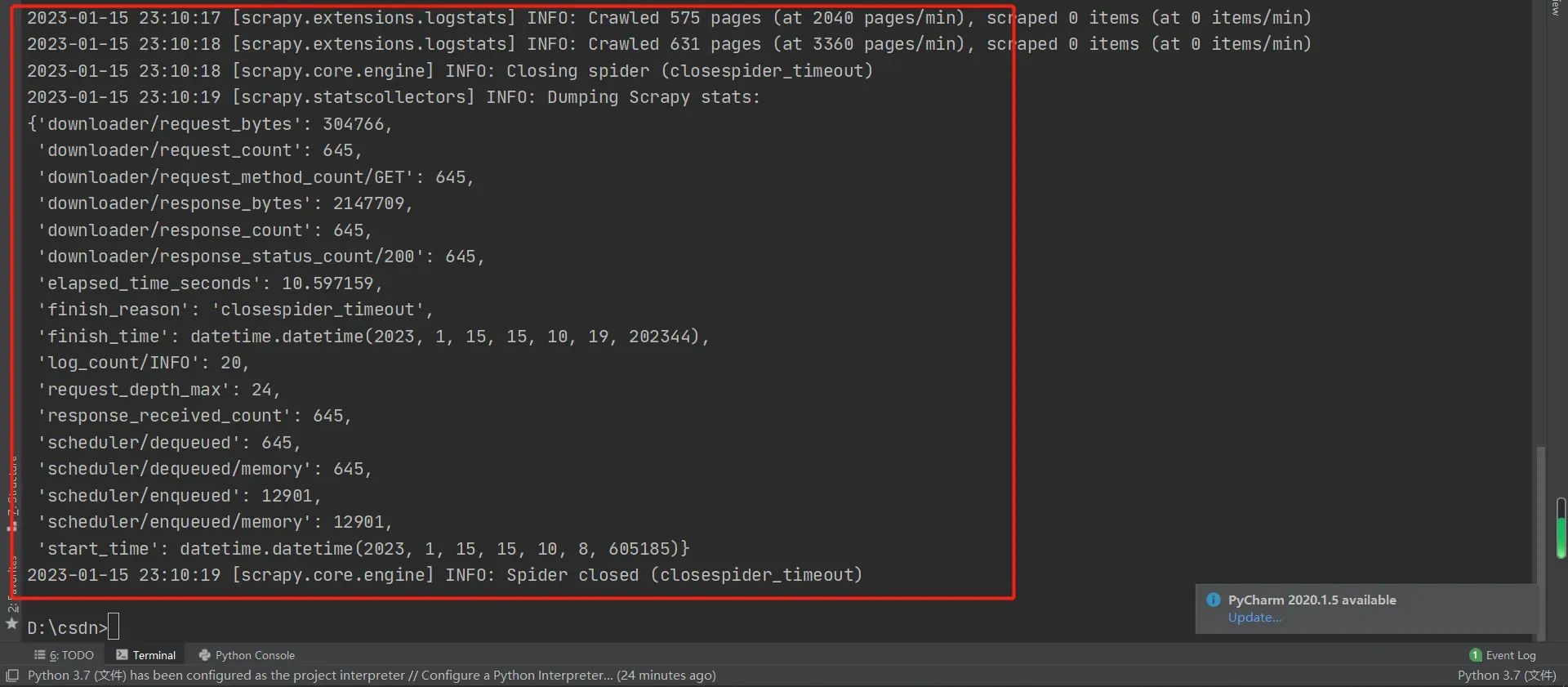
(4)测试一个url是否能够直接连通获取到响应(一般情况下为文本):
scrapy fetch www.xxx.com这里以百度首页为例;
scrapy fetch https://www.baidu.com
出现以下类似内容即为获取响应成功(该处虽然成功获取到了响应,但是因为遵守了robots协议请求是被拒绝了的,后期可自行更改为不遵守即可获取正确响应内容)

(4)创建爬虫任务
scrapy genspider 爬虫任务名 模板url例如:
scrapy genspider myspider01 www.xxx.comtips:模板url必须要携带!!!模板url必须要携带!!!模板url必须要携带!!!

目录文件这边也生成了我们创建的爬虫任务
这边对任务的内容写了一些基本的注释:
import scrapy
class Myspider01Spider(scrapy.Spider):
name = 'myspider01' # 爬虫任务名
allowed_domains = ['www.xxx.com'] # url过滤器,与起始url列表没有任何关系,并不会对起始url列表造成任何的影响
start_urls = ['https://www.xxx.com/'] # 起始url列表,该列表中每一个存在的url都会被请求,起始url列表中的url不会受到url过滤器的影响
def parse(self, response):
pass(5)运行爬虫项目
1.scrapy crawl spidername(爬虫任务名,不是爬虫文件名)
2.scrapy runspider spidername(爬虫文件名,而不是爬虫任务名)
# 使用runspider时候,首先要进入到爬虫文件所在的目录例如 一方法:
运行前将 myspider01.py文件中start_urls 中的值改为’https://www.baidu.com/’
scrapy crawl myspider01
出现类似内容即为成功
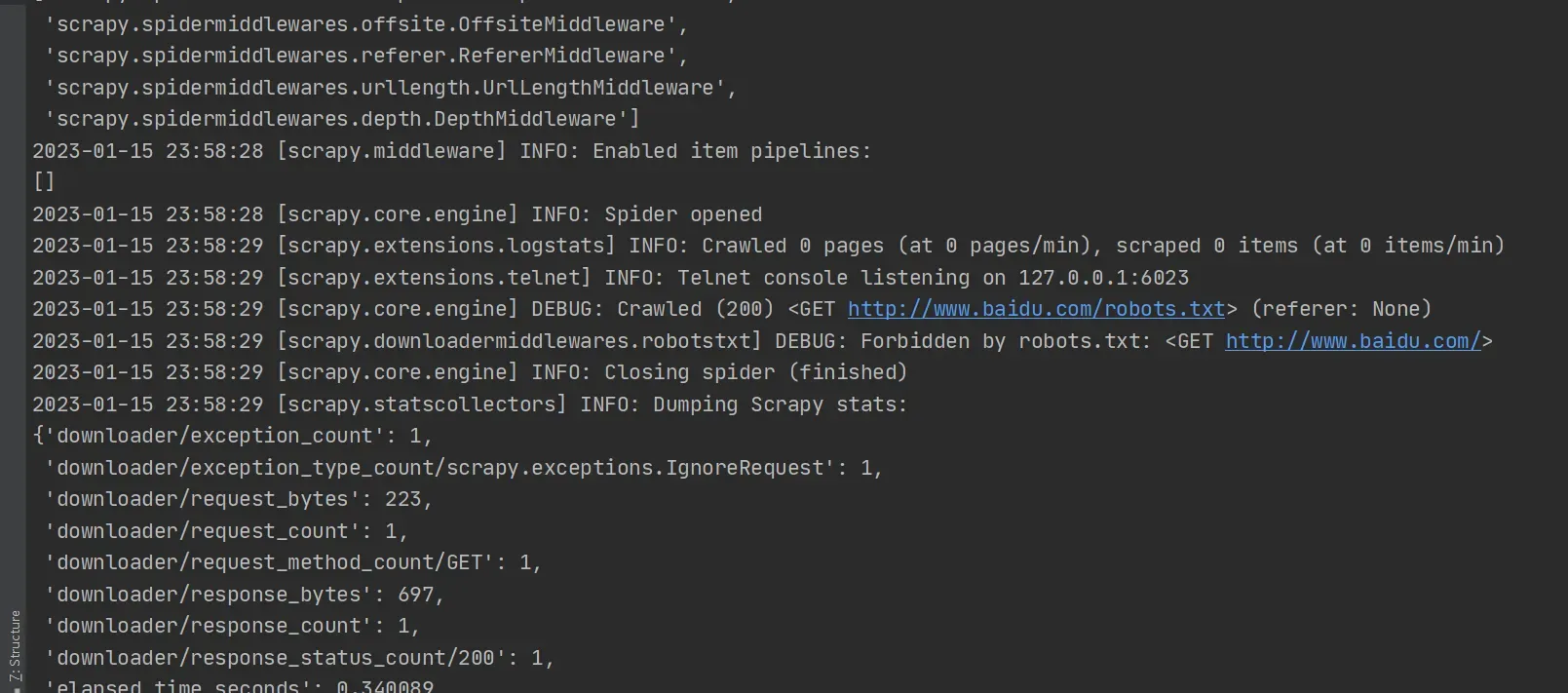
tips:如果myspider01.py文件中name 中任务名的值更改为’其他任务名’,则对应命令也需更改,即:
scrapy crawl 其他任务名例如 二方法:
使用该方法前,首先要进入到爬虫文件所在的目录
scrapy runspider myspider01.py
三、scrapy项目目录结构一览
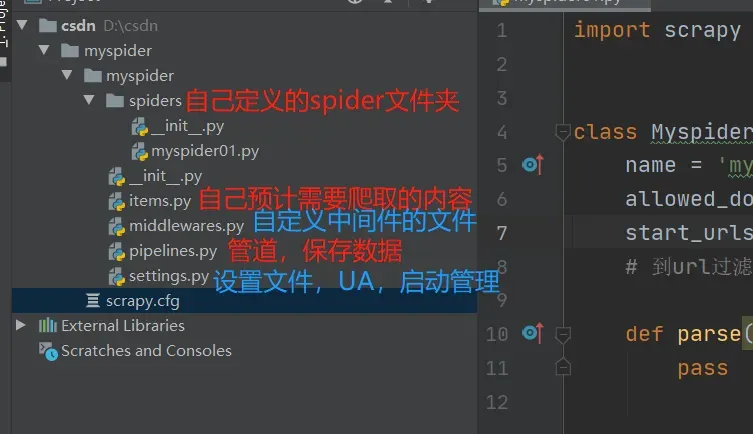
以上为本次发布全部内容,如有错漏,欢迎及时指正
文章出处登录后可见!