本次水平集图像分割并行加速算法设计与实现包含:原理篇、串行实现篇、OpenMP并行实现篇与CUDA GPU并行实现篇四个部分。具体各篇章链接如下:
- 水平集图像分割并行加速算法设计与实现——原理篇
- 水平集图像分割并行加速算法设计与实现——串行实现篇
- 水平集图像分割并行加速算法设计与实现——OpenMP并行实现篇
- 水平集图像分割并行加速算法设计与实现——CUDA GPU并行实现篇
原理篇主要讲解水平集图像分割的原理与背景。串行实现篇、OpenMP并行实现篇与CUDA GPU并行实现篇主要基于C++与OpenCV实现相应的图像分割与并行加速任务。本系列属于图像处理与并行程序设计结合类文章,希望对你有帮助😊。
CUDA并行程序流程
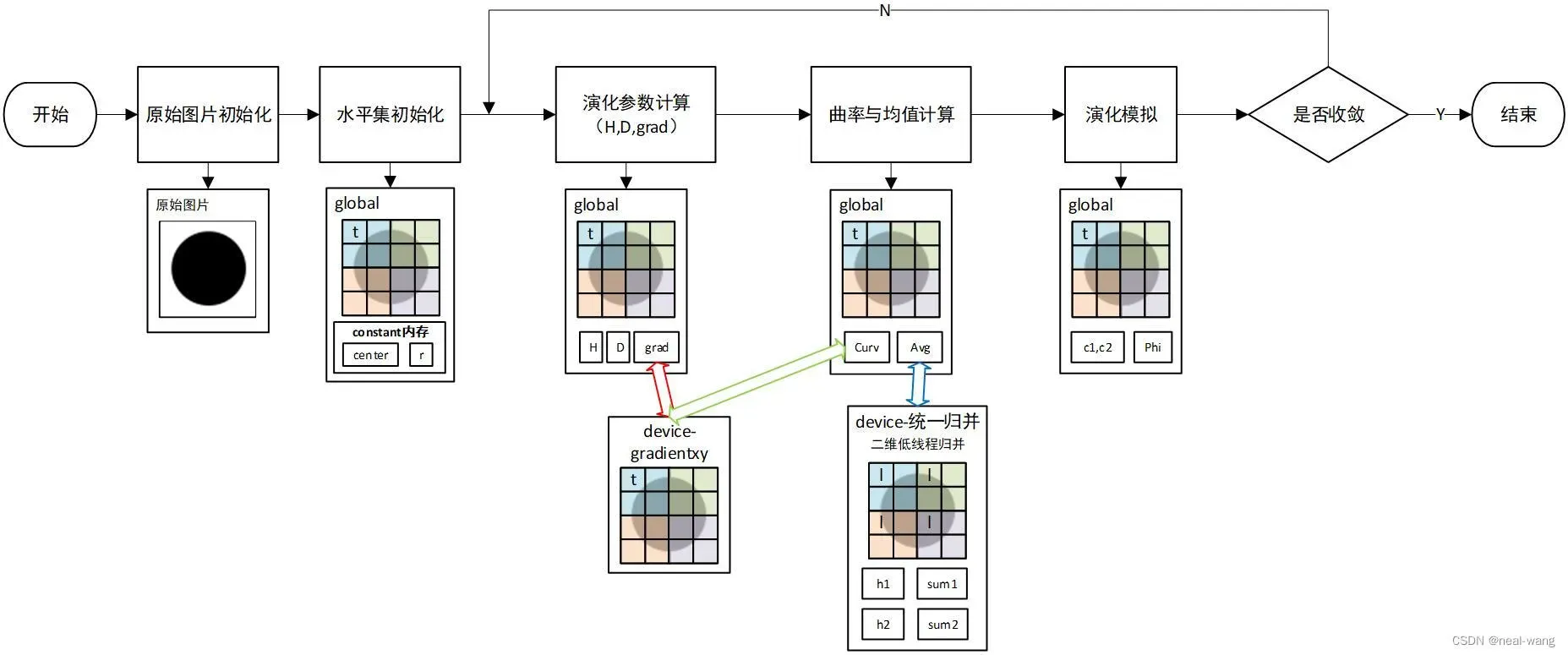
本次CUDA并行水平集图像分割程序的流程设计如上图所示。首先需要对待分割图像进行导入并对相关参数进行配置,其后结合常量内存运用GPU实现水平集并行初始化。接着进入演化参数计算全局kernel函数(global),其中的每个线程并行处理其所对应的像素块,根据公式可求得Heaviside函数与Dirac函数矩阵,且需要调用相应梯度求解device函数,完成梯度矩阵的计算。接着进入曲率与均值计算全局kernel函数,其将借助显存中的梯度数据完成曲率的计算,在这之后,将调用相应device函数运用块内二维低线程归并与块间原子操作的方式,对目标区域内像素数(sum1)、目标区域内像素值(h1)、目标区域外像素数(sum2)与目标区域外像素值(h2)进行统一归并。最后将进入演化模拟全局kernel函数(global),以此完成前景均值(c1)与背景均值(c2)的求解,以及整个水平集的演化迭代。详细原理见本系列原理篇讲解,此处不再赘述,下面将对上述各个模块的设计与实现进行介绍。
主要并行模块设计与实现
并行程序参数准备
为在GPU计算时实现参数数据的快速提取,程序采用常量存储对演化过程中所需参数进行配置,同时也在程序开头对部分待使用全局变量进行初始化,具体代码如下所示:
// GPU常量存储区域
__constant__ float d_lambda1 = 1.0f;
__constant__ float d_lambda2 = 1.0f;
__constant__ float d_mu = 0.1 * 255 * 255; //长度项
.....
__constant__ float d_epsilon = 1.0;
__constant__ float d_k1 = 1 / CV_PI; // d_epsilon=1的情况
__constant__ float d_k2 = 1.0; // d_epsilon=1的情况
__constant__ float d_k3 = 2 / CV_PI; // d_epsilon=1的情况
__constant__ float d_forntpro = 0.1; //前景均值调节系数
水平集初始化模块
由于在水平集函数的初始化过程中需要多次调用初始化中心与半径等参数,因此首先需要在程序开头设置常量内存,用于对上述必要参数进行存储,以便利用常量内存的缓存特性提高运行效率。在具体初始化流程中,每个线程依照倒置符号距离函数公式完成对应像素点水平集数值的计算,并将计算后值赋予全局变量中的水平集矩阵对应元素,具体代码如下所示:
__global__ void cudaInitializePhi(float* d_phi, uint imgWidth, uint imgHeight) {
// idx 为列号,纵坐标
int idx = threadIdx.x + blockIdx.x * blockDim.x;
// idy 为行号,横坐标
int idy = threadIdx.y + blockIdx.y * blockDim.y;
if (idx < imgWidth && idy < imgHeight)
{
float value = -sqrtf(powf((idx - d_phi0centerx), 2) + powf((idy - d_phi0centery), 2)) + d_phi0r;
if (abs(value) < 1e-3)
{
//在零水平集曲线上
d_phi[idy * imgWidth + idx] = 0;
}
else
{
// 在零水平集内:为正
// 在零水平集外:为负
d_phi[idy * imgWidth + idx] = value;
}
}
}
演化参数计算模块
演化参数计算模块主要用于对模型演化所需参数(如Heaviside函数与Dirac函数矩阵等)进行计算。其设定每个线程仅负责自己所对应坐标(idx,idy)位置上的像素,不会发生任何访问冲突,依靠公式便可求得对应位置参数值,具体代码如下所示:
__global__ void evolvingArg(float* d_phi, float* d_dirac, float* d_heaviside, float* d_curv, float* d_src, float* d_dx, float* d_dy, float* d_dxx,
float* d_dyy, uint imgWidth, uint imgHeight) {
// idx 为列号,纵坐标
int idx = threadIdx.x + blockIdx.x * blockDim.x;
// idy 为行号,横坐标
int idy = threadIdx.y + blockIdx.y * blockDim.y;
if (idx < imgWidth && idy < imgHeight)
{
d_dirac[idy * imgWidth + idx] = d_k1 / (d_k2 + powf(d_phi[idy * imgWidth + idx], 2));
d_heaviside[idy * imgWidth + idx] = 0.5 * (1.0 + d_k3 * atanf(d_phi[idy * imgWidth + idx] / d_epsilon));
// 曲率计算
gradient(d_src, d_dx, d_dy, idx, idy, imgWidth, imgHeight);
float norm = powf(d_dx[idy * imgWidth + idx] * d_dx[idy * imgWidth + idx] + d_dy[idy * imgWidth + idx] * d_dy[idy * imgWidth + idx], 0.5);
d_dx[idy * imgWidth + idx] = d_dx[idy * imgWidth + idx] / norm;
d_dy[idy * imgWidth + idx] = d_dy[idy * imgWidth + idx] / norm;
}
}
曲率与均值计算模块
本次CUDA水平集图像分割曲率与均值计算模块运用块内二维低线程归并、块间原子操作实现相关变量的全局归并,具体流程如下图所示。
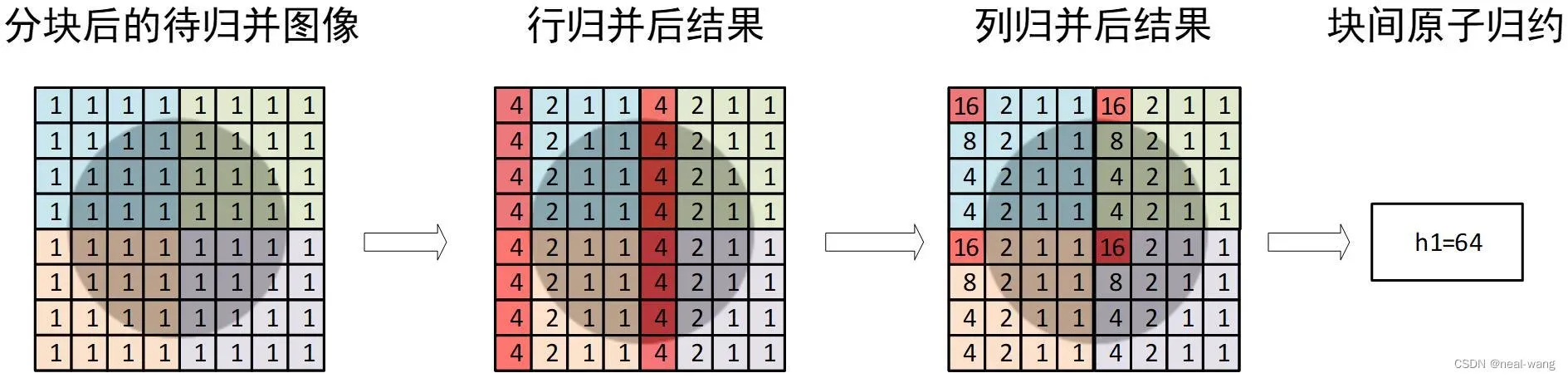
在二维归并之前,先要在各block内设置对应共享存储数组,用于归并过程中存储最终结果与中间计算数值。接着首先对行进行归约,循环将后一半线程所存取数据累加到前一半中,并最终将block内各行数据汇总到各行首元素位置。其后调用block内各行的首个线程(threadIdx.x=0),以上述类似的方式将各block中的第一列元素汇总到列首位置(threadIdx.x=0且threadIdx.y=0)。上述操作后,即可完成块内归并,最后将运用原子操作完成块间的归并。
在上述归并的过程中可能会出现图像大小与grid大小不匹配的情况,具体如下图所示。
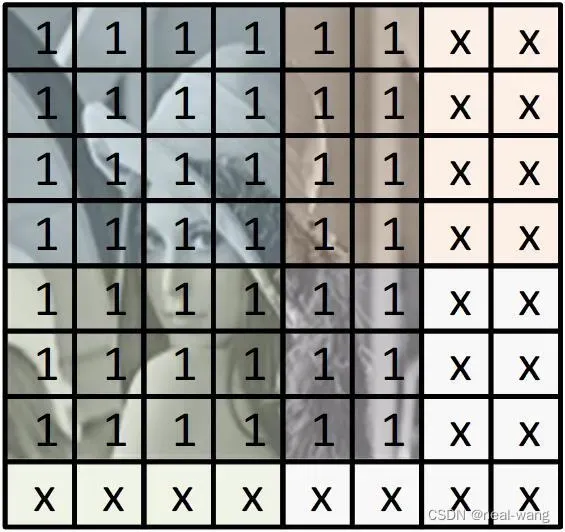
在上图情况中,由于待分割图片存在宽高为奇数、grid边缘线程无像素值对应等问题,无法直接进行块内二维低线程归并,故需要对这种情况进行特殊处理。根据上述不匹配情况特点,在CUDA并行程序中,首先通过取余运算符对是否存在上图所示不匹配情况进行判断,其后若进入归并程序的线程属于不匹配块(含超出图像区域线程的块),则其直接将自身对应数值运用原子操作赋予待归约的全局变量。若进入归并程序的线程不属于不匹配块,则进入二维低线程归并步骤。
同时,为最大程度提升程序的性能,程序对待归约的4个全局变量进行统一归并,在程序的开头对所有归并所需共享内存数组进行创建。在归并的过程中,每次都对所有待归并变量的共享内存进行操作(一次全局归并操作完成4个变量的全局统计)。具体代码如下所示。
// 统一归并函数
__device__ void gpuReduction2zong(float* d_a, float* d_value, uint imgWidth, uint imgHeight)
{
__shared__ float temph1[BLOCKHEIGHT][BLOCKWIDTH], temph2[BLOCKHEIGHT][BLOCKWIDTH], tempsum1[BLOCKHEIGHT][BLOCKWIDTH], tempsum2[BLOCKHEIGHT][BLOCKWIDTH];
// idx 为列号,纵坐标
int idx = threadIdx.x + blockIdx.x * blockDim.x;
// idy 为行号,横坐标
int idy = threadIdx.y + blockIdx.y * blockDim.y;
if (idx < imgWidth && idy < imgHeight)
{
int ycrow = imgHeight % BLOCKHEIGHT;
int yccol = imgWidth % BLOCKWIDTH;
// 待归并变量提取
float h1per = d_a[idy * imgWidth + idx];
float h2per = 1 - d_a[idy * imgWidth + idx];
float sum1per = d_a[idy * imgWidth + idx] * d_value[idy * imgWidth + idx];
float sum2per = (1 - d_a[idy * imgWidth + idx]) * d_value[idy * imgWidth + idx];
// 当存在块超出图片的情况
if (ycrow > 0 || yccol > 0)
{
int ycblocky = imgHeight / BLOCKHEIGHT;
int ycblockx = imgWidth / BLOCKWIDTH;
if ((blockIdx.x > (ycblockx - 1)) || (blockIdx.y > (ycblocky - 1)))
{
atomicAdd(&h1result, h1per);
atomicAdd(&h2result, h2per);
atomicAdd(&sum1result, sum1per);
atomicAdd(&sum2result, sum2per);
}
else
{
temph1[threadIdx.y][threadIdx.x] = h1per;
temph2[threadIdx.y][threadIdx.x] = h2per;
tempsum1[threadIdx.y][threadIdx.x] = sum1per;
tempsum2[threadIdx.y][threadIdx.x] = sum2per;
__syncthreads();
// 对行进行归并
for (int i = (BLOCKWIDTH >> 1); i > 0; i >>= 1) {
if (threadIdx.x < i) {
temph1[threadIdx.y][threadIdx.x] += temph1[threadIdx.y][threadIdx.x + i];
temph2[threadIdx.y][threadIdx.x] += temph2[threadIdx.y][threadIdx.x + i];
tempsum1[threadIdx.y][threadIdx.x] += tempsum1[threadIdx.y][threadIdx.x + i];
tempsum2[threadIdx.y][threadIdx.x] += tempsum2[threadIdx.y][threadIdx.x + i];
}
__syncthreads();
}
// 对列进行归并
if (threadIdx.x == 0)
{
for (int i = (BLOCKHEIGHT >> 1); i > 0; i >>= 1) {
if (threadIdx.y < i) {
temph1[threadIdx.y][threadIdx.x] += temph1[threadIdx.y + i][threadIdx.x];
temph2[threadIdx.y][threadIdx.x] += temph2[threadIdx.y + i][threadIdx.x];
tempsum1[threadIdx.y][threadIdx.x] += tempsum1[threadIdx.y + i][threadIdx.x];
tempsum2[threadIdx.y][threadIdx.x] += tempsum2[threadIdx.y + i][threadIdx.x];
}
__syncthreads();
}
}
__syncthreads();
// 全局归并结果汇总
if (threadIdx.x == 0 && threadIdx.y == 0)
{
atomicAdd(&h1result, temph1[0][0]);
atomicAdd(&h2result, temph2[0][0]);
atomicAdd(&sum1result, tempsum1[0][0]);
atomicAdd(&sum2result, tempsum2[0][0]);
}
}
}
// 当不存在块超出图片的情况
else
{
temph1[threadIdx.y][threadIdx.x] = h1per;
temph2[threadIdx.y][threadIdx.x] = h2per;
tempsum1[threadIdx.y][threadIdx.x] = sum1per;
tempsum2[threadIdx.y][threadIdx.x] = sum2per;
__syncthreads();
// 对行进行归并
for (int i = (BLOCKWIDTH >> 1); i > 0; i >>= 1) {
if (threadIdx.x < i) {
temph1[threadIdx.y][threadIdx.x] += temph1[threadIdx.y][threadIdx.x + i];
temph2[threadIdx.y][threadIdx.x] += temph2[threadIdx.y][threadIdx.x + i];
tempsum1[threadIdx.y][threadIdx.x] += tempsum1[threadIdx.y][threadIdx.x + i];
tempsum2[threadIdx.y][threadIdx.x] += tempsum2[threadIdx.y][threadIdx.x + i];
}
__syncthreads();
}
// 对列进行归并
if (threadIdx.x == 0)
{
for (int i = (BLOCKHEIGHT >> 1); i > 0; i >>= 1) {
if (threadIdx.y < i) {
temph1[threadIdx.y][threadIdx.x] += temph1[threadIdx.y + i][threadIdx.x];
temph2[threadIdx.y][threadIdx.x] += temph2[threadIdx.y + i][threadIdx.x];
tempsum1[threadIdx.y][threadIdx.x] += tempsum1[threadIdx.y + i][threadIdx.x];
tempsum2[threadIdx.y][threadIdx.x] += tempsum2[threadIdx.y + i][threadIdx.x];
}
__syncthreads();
}
}
__syncthreads();
// 全局归并结果汇总
if (threadIdx.x == 0 && threadIdx.y == 0)
{
atomicAdd(&h1result, temph1[0][0]);
atomicAdd(&h2result, temph2[0][0]);
atomicAdd(&sum1result, tempsum1[0][0]);
atomicAdd(&sum2result, tempsum2[0][0]);
}
}
}
}
演化模拟并行模块
在该模块中,首先运用grid中的第一个线程对前景与背景均值进行计算,并初始化收敛性判断标签。其后便可运用演化公式,完成水平集的演化任务。具体代码如下所示:
__global__ void evolvingProAndCheck(float* d_phi, float* d_dirac, float* d_heaviside, float* d_curv, float* d_src, float* d_dx, float* d_dy, float* d_dxx,
float* d_dyy, int* d_flag, uint imgWidth, uint imgHeight) {
// idx 为列号,纵坐标
int idx = threadIdx.x + blockIdx.x * blockDim.x;
// idy 为行号,横坐标
int idy = threadIdx.y + blockIdx.y * blockDim.y;
//float c1, c2;
if (idx == 0 && idy == 0)
{
d_c1 = d_forntpro * sum1result / (h1result + 1e-10);
d_c2 = sum2result / (h2result + 1e-10);
*d_flag = 0;
}
__threadfence();
if (idx < imgWidth && idy < imgHeight)
{
float curv = d_curv[idy * imgWidth + idx];
float dirac = d_dirac[idy * imgWidth + idx];
float u0 = d_src[idy * imgWidth + idx];
float lengthTerm = d_mu * dirac * curv;
float areamterm = d_nu * dirac;
float fittingterm = dirac * (-d_lambda1 * powf(u0 - d_c1, 2) + d_lambda2 * powf(u0 - d_c2, 2));
float term = lengthTerm + areamterm + fittingterm;
float newphi = d_phi[idy * imgWidth + idx] + d_timestep * term;
float oldphi = d_phi[idy * imgWidth + idx];
d_phi[idy * imgWidth + idx] = newphi;
if (*d_flag == 0)
{
if (oldphi * newphi < 0)
{
*d_flag = 1;
}
__threadfence();
}
}
}
由于篇幅所限,文内仅仅展现部分主要代码,详细代码见本人github仓库所示,具体链接如下 。
水平集图像分割算法串行与并行代码以及相关测试用例
测试用例
本次并行加速算法的测试用例主要分为实体测试用例与性能测试用例两部分,下面将分别对两部分测试用例进行介绍。
实体测试用例
实体测试用例主要来源于实际生活中存在,或虚拟应用场景中存在的图形图像。针对实际存在实物方面,选取人脸嘴唇图片作为测试用例,其尺寸为883像素*594像素,具体如下图所示。

针对虚拟业务场景方面,本次个人实验选取两张飞机游戏图片作为测试用例,其中飞机游戏图片一尺寸为320像素*570像素,飞机游戏图片二尺寸为476像素*752像素,具体如下所示。(左小图为飞机游戏一,右小图为飞机游戏二)
性能测试用例
性能测试用例主要通过随机生成的图形进行构建,其包含有尺寸从400像素*400像素到1000像素*1000像素的7张图片,以此来对并行算法针对不同数据量的处理性能进行测试,具体图片示例如下图所示。
运行环境说明
硬件运行环境
CPU:Intel® Core™ i5-9300H 4核CPU处理器
GPU:NVIDIA GeForce GTX 1050显卡
软件运行环境
OpenCV: v4.5.0
CUDA: v11.0
运行结果与性能测试
经过多次测试分析,在下面的测试中将选用16*16尺寸的block,grid的大小将按如下公式计算得到:
由此保证图像中的每一个像素块都仅仅可以被一个线程访问。
实体测试用例结果与性能分析
针对人脸嘴唇图片,CUDA并行程序以时间步长为1进行测试,最大迭代次数为1000,得到的测试结果与演化过程如下图中左小图所示。同时为充分对比CUDA并行加速效果,在下图右小图中提供对应串行演化过程进行对比分析,具体如下图所示。(左小图为并行结果,右小图为串行结果)

| 图片名称 | 人脸嘴唇 | 飞机游戏一 | 飞机游戏二 |
|---|---|---|---|
| 时间(ms) | 5046.7 | 616.1 | 3928.4 |
| 加速比 | 67.79836329 | 56.4031813 | 56.0085531 |
(备注:加速比=串行时间/并行时间)
从上表中可看出,CUDA并行程序针对实体测试用例可将加速比提升到55以上,程序的整体运行效率得到显著提高。具体CUDA并行程序与串行程序运行时间对比如下所示:
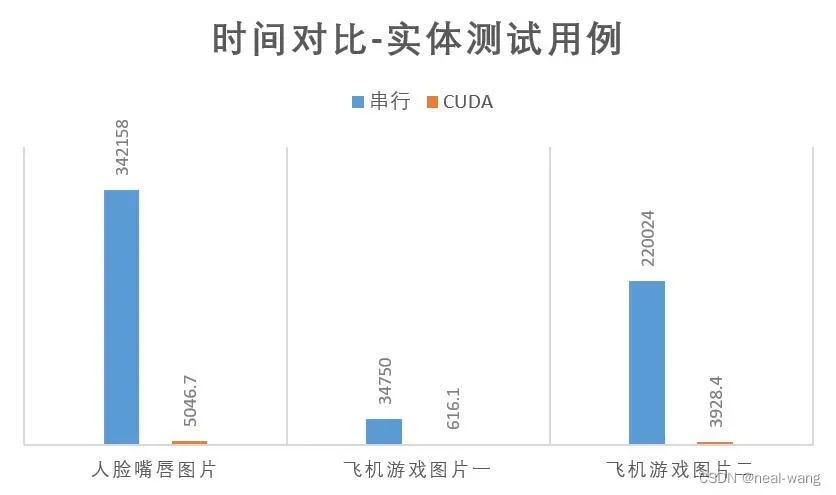
从上图中也可以看出,CUDA并行程序相比于串行程序,运行时间极大减少。
性能测试用例结果与性能分析
针对性能测试用例中的7张图片,运用步长为5进行测试,最大迭代次数为10000,得到的并行与串行测试结果对比如下图所示。(左小图为并行结果,右小图为串行结果,以尺寸为500像素*500像素运行结果为例)


从上图中可看出,CUDA并行程序的运行结果与串行程序相同,且同时具有较好的加速效果。
在GTX 1050显卡上,针对CUDA并行程序的性能测试用例结果进行性能分析,分别取各图片十次运行时间进行平均,得到性能测试用例CUDA并行程序时间表,同时可计算其相对于串行程序的加速比,具体如下表所示:
| 测试图像大小 | 时间(ms) | 加速比 |
|---|---|---|
| 400 | 1018.5 | 54.70397644 |
| 500 | 2687.8 | 50.0122777 |
| 600 | 5542.1 | 59.76254488 |
| 700 | 10174.5 | 74.40866873 |
| 800 | 22540.9 | 55.95730428 |
| 900 | 34611.4 | 55.31119804 |
| 1000 | 56473.7 | 53.68817697 |
由上表可看出,CUDA并行程序针对性能测试用例,可实现55左右的加速比,其中针对部分尺寸加速比最高可以达到74,性能优化良好,具体时间对比图如下所示。
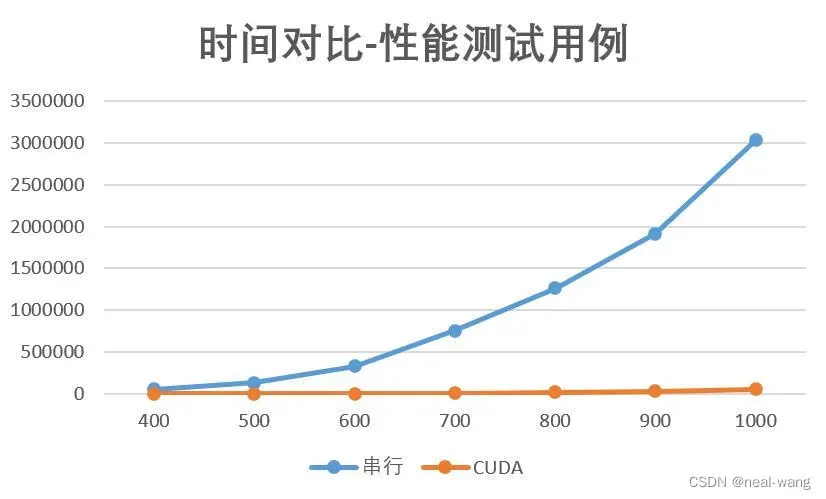
从上图中可看出,随着图片的不断变大,串行运行时间增加迅速,而CUDA并行程序运行时间几乎无变化,并行化效果显著。
GPU补充测试
下面将分别采用GTX 1050与GTX 3060显卡(均为笔记本端显卡)运行CUDA水平集图像分割并行程序,其选取400像素*400像素至1000像素*1000像素尺寸的性能测试用例,运用步长为5进行测试,最大迭代次数为10000。具体运行时间与加速比对比如下图所示。
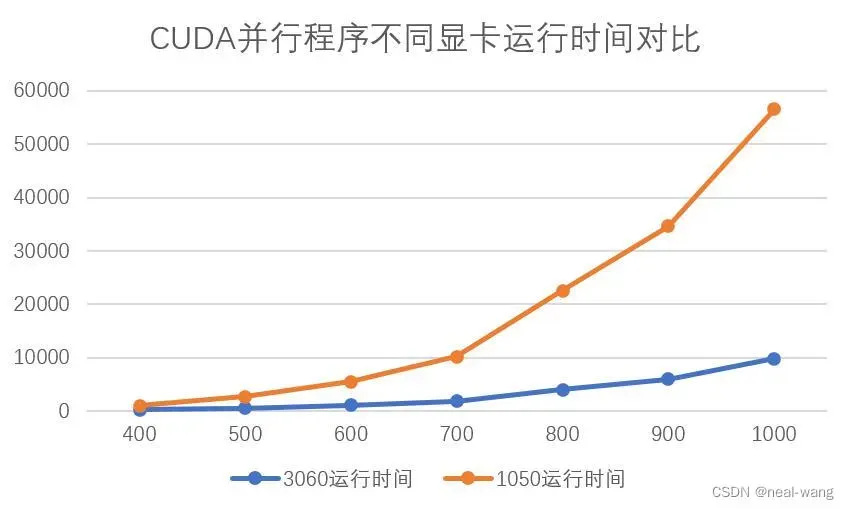
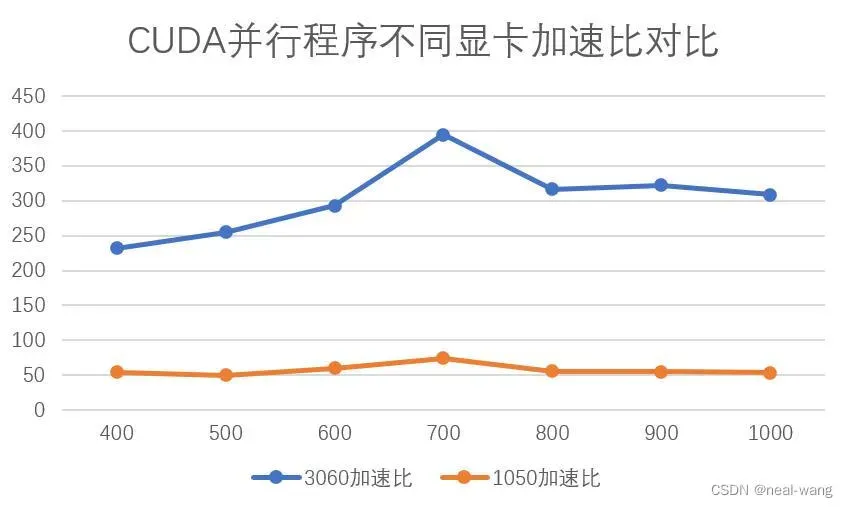
进一步对两块显卡的加速比进行对比分析,可得如下表所示关系:
| 测试图像大小 | 3060相比1050加速 |
|---|---|
| 400 | 4.241982507 |
| 500 | 5.102126044 |
| 600 | 4.90191049 |
| 700 | 5.301703924 |
| 800 | 5.651331294 |
| 900 | 5.823599684 |
| 1000 | 5.749656387 |
从上表可看出,GTX 3060显卡针对CUDA并行程序的运行效率相比于GTX 1050显卡提高了5-6倍,最高加速比可达到400,这也进一步验证了本次设计的CUDA水平集并行图像分割程序的加速潜力。
最后😃感谢各位对水平集图像分割并行加速算法设计与实现系列的支持,本人也会持续更新图像处理与并行计算相关领域的文章,欢迎大家点赞关注。如有疑问或意见可在评论区留言或私聊,本人一定会在第一时间给予回复。😊
文章出处登录后可见!