文章目录
- 前言
- 一、CLIP模型原理
- 1.背景介绍
- 2.对比训练方式
- 3.prompt推理方式
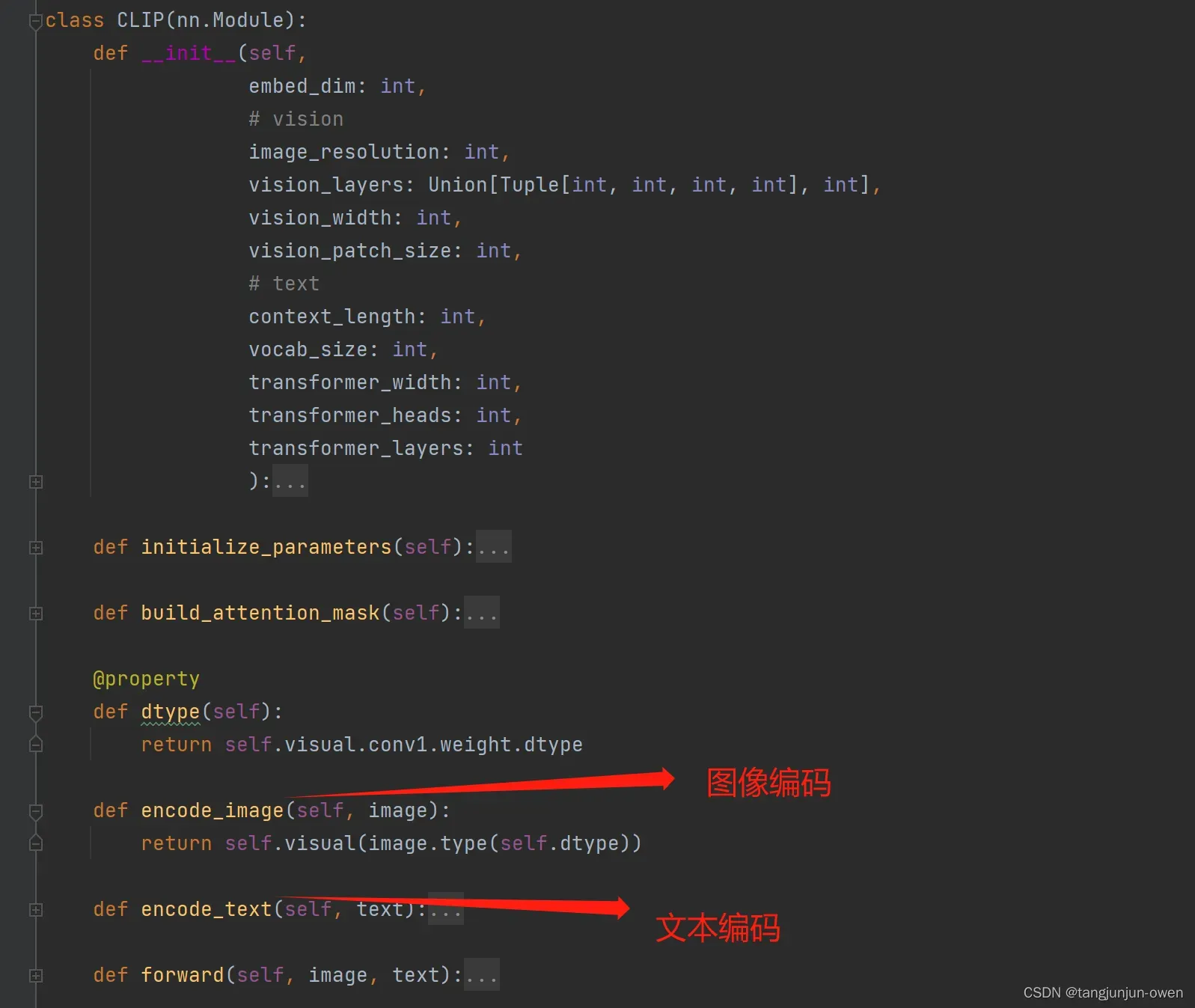
- 4.图像与文本编码结构
- 5.特征CLS token结构
- vit划分patch原理
- cls token原理
- 二、CLIP环境安装
- 1.官方环境安装
- 2.CLIP环境安装
- 3.CLIP运行结果
- 三.CLIP的Transformer结构代码解读
- 四、CLIP模型主函数代码解读
- 五、CLIP的image encode代码解读
- 1、主函数代码解读
- 2、VisionTransformer结构代码解读
- 3、图像patch方法代码解读
- 3、图像cls token编码代码解读
- 4、图像位置编码代码解读
- 5、图像cls token特征表达代码解读
- 6、图像特殊结构代码解读
- 六、CLIP的text encode代码解读
- 1、主函数代码解读
- 2、文本token代码解读
- 3、文本位置编码代码解读
- 4、文本特殊结构代码解读
- 七、CLIP多模态融合代码解读
- 八、CLIP推理结构解读
- 九、CLIP训练结构解读
- 总结
前言
目前,大模型十分活跃,openai公司呈现GPT系列,特别是Chat-GPT给人深刻印象,意识到大模型厉害之处,随后推出GPT4模型,更是将大模型进一步推到一个高度,并将多模态融合技术留下深刻印象,同时,学者也对多模态融合技术研究呈现百花齐放之势。然而,多模态模型大多以CLIP所提方法或思路实现多模态融合。为此,本文将重新回顾CLIP论文相关理论,也重点梳理其源码,并附其代码供读者参考(本文会涉及VIT与BERT代码解读)。
提示:代码环境安装、重点部分代码解释(如:image encode(VIT),text encode(BERT)等)
论文地址:点击这里
官网源代码:点击这里
我的代码:点击这里 名称为:CLIP模型.zip 提取码:r63z
一、CLIP模型原理
1.背景介绍
CLIP算是在跨模态训练无监督中的开创性工作,作者提到早在2017年之后就陆续有工作提出和本文类似的想法,但数据量太少,而无好结果。本文收集4亿数据的大数据集,才得到很好的效果。这种现象最近好像在机器学习领域越来越突出。本文采用对比方式,图像使用vit结构编码、文本使用bert编码,实现视觉与语言多模态融合。
2.对比训练方式
本文并非像图像caption方式,而是通过对比学习实现模型训练,我想也是这种对比学习才被目前多模态融合方法所借鉴。其采用对比学习原因如下:
- OpenAI是不愁计算资源的公司,喜欢将一切都gpt化(就是做生成式模型);
- 以往工作在1000类ImageNet数据训练方法,非常耗费资源,而CLIP要做的是开发世界的视觉识别任务,所以训练的效率对于自监督的模型至关重要;
- 如果任务改为给定一张图片去预测一个文本(或者给定一个文本去预测一张图片),那么训练效率将会非常低下(因为一个图片可能对应很多种说法,一个文本也对应着很多种场景);
- 与其做默写古诗词,不如做选择题!(只要判断哪一个文本与图片配对即可);
- 通过从预测任务改为只预测某个单词到只选出配对的答案,模型的训练效率一下提升了4倍;
为此,本文训练阶段使用对比学习,让模型学习文本-图像对的匹配关系,也就是下面模型原理图中,蓝色对角线为匹配的图文对。训练集用的他们自己采集的包含4亿个图文对的 WIT数据集。
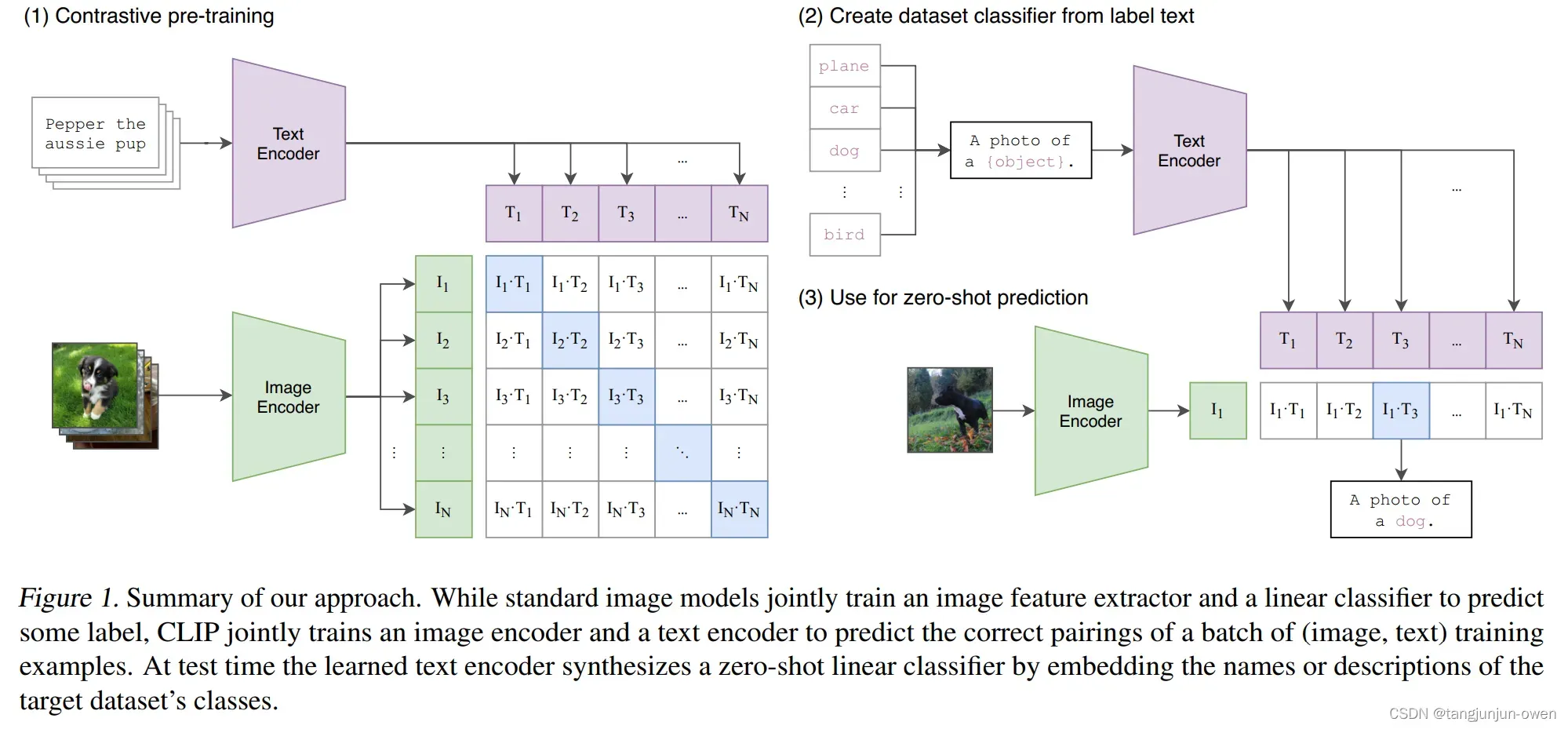
3.prompt推理方式
使用某种固定prompt结构,正如训练获得特征,通过图像与prompt特征相似度匹配,实现clip分类,如:图像猫、狗二分类,可分别输入 “ A photo of cat ” 和 “ A photo of dog ”,分别与图像特征算相似度,确定其图像类被。
4.图像与文本编码结构
CLIP为多模态模型是指图像维度与文本维度融合,那么需要对图像特征化与文本特征化,本文选择图像编码结构为VIT,文本编码结构为BERT。后面,代码讲解,我将有大量笔墨说明。
5.特征CLS token结构
对于图像数据而言,其数据格式为[H, W, C],分别代表的是图片的通道数Channel,图片的高Height和宽Width。但很明显的是三维数据并不是Transformer所需要的。所以需要通过使用一个Embedding层来对原始的图片数据进行变换。
vit划分patch原理
vit论文做法为将给定的一堆图片按照给定的大小分成一堆Patches。本文将输入的图片尺寸为(224×224)按照16×16大小的Patch进行划分。其中(224×224)/(16×16)=196,因此我们会得到196个patches。到这里我们可以知道每一个Patches数据的shape为[16, 16, 3]。为了满足Transformer的需求,在这里,对每个Patch进行投影变化,映射到一维向量中。即完成如下转化。[16, 16, 3]->[768],那么这样一来,就将原始的[224, 224, 3]转化为[196, 768]。
cls token原理
在输入Transformer Encoder之前,值得注意的是需要加上[class] token。在原论文中,作者的意思是参考BERT,在上述得到的一堆tokens中插入一个专门用于分类操作的[class] token,这个[class] token是一个可训练的参数,数据格式和其他token保持一致,均为一个向量。
以本文为例,其维度大小为[1, 768]。注意的是,这里采取的是Concat操作。即cat cls token [1, 768]与图像pathch [196, 768] -> [197, 768],此时正好变成了二维矩阵。最终将图像patch变成维度是[197, 768],而本文是将cls token放在第一位,后面分类也是通过cls token给出,如下图。

注:cls token是一个可学习参数。
二、CLIP环境安装
本小节介绍如何使用官网代码安装环境,而不同电脑或cuda版本不一样,所安装也有所不同,但基本不影响,我的电脑相关属性:
gpu:RTX 3060显卡
CUDA:11.1
1.官方环境安装
官网代码安装如下命令:
$ conda install --yes -c pytorch pytorch=1.7.1 torchvision cudatoolkit=11.0
$ pip install ftfy regex tqdm
$ pip install git+https://github.com/openai/CLIP.git
2.CLIP环境安装
构建虚拟环境:
conda create -n clip python=3.8
安装torch相关包:
pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 torchaudio==0.8.0 -f https://download.pytorch.org/whl/torch_stable.html -i https://pypi.mirrors.ustc.edu.cn/simple/
安装相关依赖包:
pip install ftfy regex tqdm -i https://pypi.mirrors.ustc.edu.cn/simple/
运行源码setup.py,其一为install运行,该操作是一个包安装虚拟环境,其二为develop运行,该操作是开发安装,指向了源代码而不是安装它的位置,方便调试,其命令如下:
# 方法一安装命令
python setup.py install
# 方法二安装命令
python setup.py develop # 我采用该命令
注:建议使用方法二指向源码
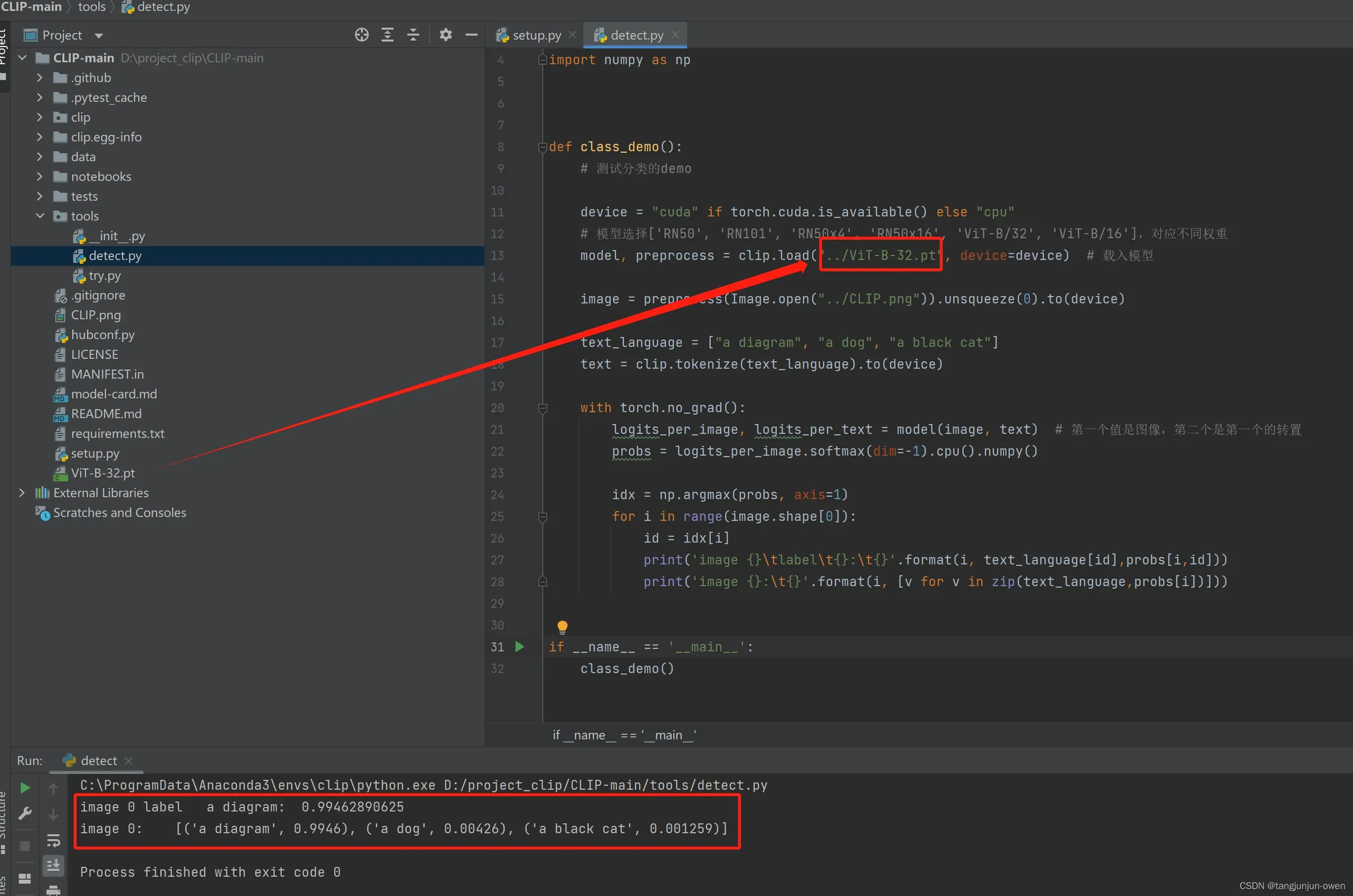
3.CLIP运行结果
以上安装即可运行检测命令,可测试安装成功,其结果如下:
三.CLIP的Transformer结构代码解读
无论是文本text或图像image的编码encode均大量使用Transformer结构(以VIT与BERT编码),其实质是Q K V结构,可参考文章点击这里,为此我将单独使用一小节介绍。
改代码在源码model.py文件中,其调用类如下代码:
class Transformer(nn.Module):
def __init__(self, width: int, layers: int, heads: int, attn_mask: torch.Tensor = None):
super().__init__()
self.width = width
self.layers = layers
self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
def forward(self, x: torch.Tensor):
return self.resblocks(x)
以上代码可知,该类为一个包装结构,重点是重复调用ResidualAttentionBlock结构,其结构如下代码:
class ResidualAttentionBlock(nn.Module):
def __init__(self, d_model: int, n_head: int, attn_mask: torch.Tensor = None):
super().__init__()
self.attn = nn.MultiheadAttention(d_model, n_head) # n_head 头,d_model 表示维度。
self.ln_1 = LayerNorm(d_model)
self.mlp = nn.Sequential(OrderedDict([
("c_fc", nn.Linear(d_model, d_model * 4)),
("gelu", QuickGELU()),
("c_proj", nn.Linear(d_model * 4, d_model))
]))
self.ln_2 = LayerNorm(d_model)
self.attn_mask = attn_mask
def attention(self, x: torch.Tensor):
self.attn_mask = self.attn_mask.to(dtype=x.dtype, device=x.device) if self.attn_mask is not None else None
return self.attn(x, x, x, need_weights=False, attn_mask=self.attn_mask)[0] # 三个x表示Q K V计算值,x最后维度=n_head*d_model
def forward(self, x: torch.Tensor):
x = x + self.attention(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
return x
从上面forward代码结构可知。
首先使用 x = x + self.attention(self.ln_1(x)),类似残差方式x+transform后的结果,该结构类似进行了attention方法,等同于transform结构的attention,该结构也被torch所集成,可直接调用其源码,如下:
self.attn = nn.MultiheadAttention(d_model, n_head) # n_head 头,d_model 表示维度。
其次又调用 x = x + self.mlp(self.ln_2(x)),类似FFN结构,进行nn.Linear常规线性操作,在来一个激活GELU结构,最后在来一次线性操作,符合mlp结构,具体如下:
self.mlp = nn.Sequential(OrderedDict([
("c_fc", nn.Linear(d_model, d_model * 4)),
("gelu", QuickGELU()),
("c_proj", nn.Linear(d_model * 4, d_model))
]))
其中GELU使用QuickGELU方法,其代码如下:
class QuickGELU(nn.Module):
def forward(self, x: torch.Tensor):
return x * torch.sigmoid(1.702 * x)
注:该部分结构类似transformer结构,并n次使用于image与text的编码。
四、CLIP模型主函数代码解读
CLIP模型主函数也在源码model.py文件中,如下图所示:
其中forward为模型流走向,其代码如下:
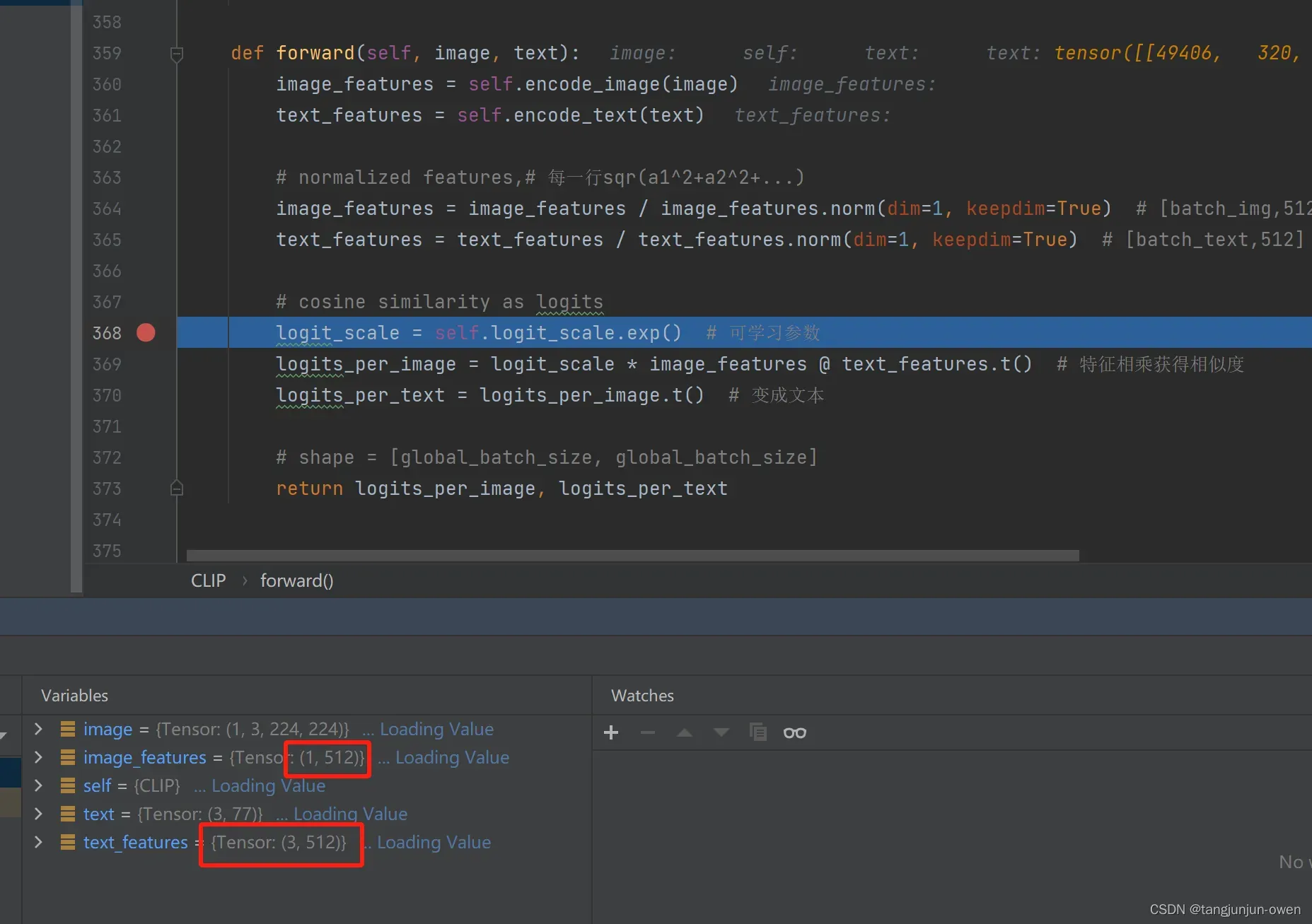
def forward(self, image, text):
image_features = self.encode_image(image)
text_features = self.encode_text(text)
# normalized features,# 每一行sqr(a1^2+a2^2+...)
image_features = image_features / image_features.norm(dim=1, keepdim=True) # [batch_img,512]
text_features = text_features / text_features.norm(dim=1, keepdim=True) # [batch_text,512]
# cosine similarity as logits
logit_scale = self.logit_scale.exp() # 可学习参数
logits_per_image = logit_scale * image_features @ text_features.t() # 特征相乘获得相似度
logits_per_text = logits_per_image.t() # 变成文本
# shape = [global_batch_size, global_batch_size]
return logits_per_image, logits_per_text
以上可知,CLIP实现多模态融合,实际是对图像编码与文本编码,使其分别获得对应的特征表达,在将表达特征进行norm(我的理解减小偏差,是一个常规操作),随后将图像特征与对应文本特相差,便可获得相似值。
假设以2个图像与3个文本表示,其图像特征获得对应文本特征得到相似值,简易说明如下:

将其转职获得文本特征获得对应图像特征相似值,简易说明如下:

其中,每个图像与文本特征表达维度为512(CLIP使用此维度),获得对应相似值如上图V**,每一行的最大值分别是CLIP模型认为最相似的,也得到图像获得文本标签,或文本获得匹配的图像。
五、CLIP的image encode代码解读
图像编码使用VIT编码结构,将图片划分为多个patch,然后使用transformer结构编码提取特征,最终获得特征表达。接下来,我将详细阐述。
1、主函数代码解读
CLIP使用encode_image函数调用,如下:
image_features = self.encode_image(image)
而encode_image函数如下:
def encode_image(self, image):
return self.visual(image.type(self.dtype))
CLIP使用图像编码有ResNet结构与VisionTransformer,前者是CNN方式,后者是transformer方式,我将以transformer方式解读,如下代码:
if isinstance(vision_layers, (tuple, list)):
vision_heads = vision_width * 32 // 64
self.visual = ModifiedResNet(
layers=vision_layers,
output_dim=embed_dim,
heads=vision_heads,
input_resolution=image_resolution,
width=vision_width
)
else:
vision_heads = vision_width // 64
self.visual = VisionTransformer(
input_resolution=image_resolution,
patch_size=vision_patch_size,
width=vision_width,
layers=vision_layers,
heads=vision_heads,
output_dim=embed_dim
)
2、VisionTransformer结构代码解读
该类是图像encode的所有精华所在,代码已有我的注释,其代码如下:
class VisionTransformer(nn.Module):
def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):
super().__init__()
self.input_resolution = input_resolution
self.output_dim = output_dim
self.conv1 = nn.Conv2d(in_channels=3, out_channels=width, kernel_size=patch_size, stride=patch_size, bias=False)
# width相当于transform中的d_model
scale = width ** -0.5
self.class_embedding = nn.Parameter(scale * torch.randn(width))
self.positional_embedding = nn.Parameter(scale * torch.randn((input_resolution // patch_size) ** 2 + 1, width))
self.ln_pre = LayerNorm(width)
self.transformer = Transformer(width, layers, heads)
self.ln_post = LayerNorm(width)
self.proj = nn.Parameter(scale * torch.randn(width, output_dim))
def forward(self, x: torch.Tensor):
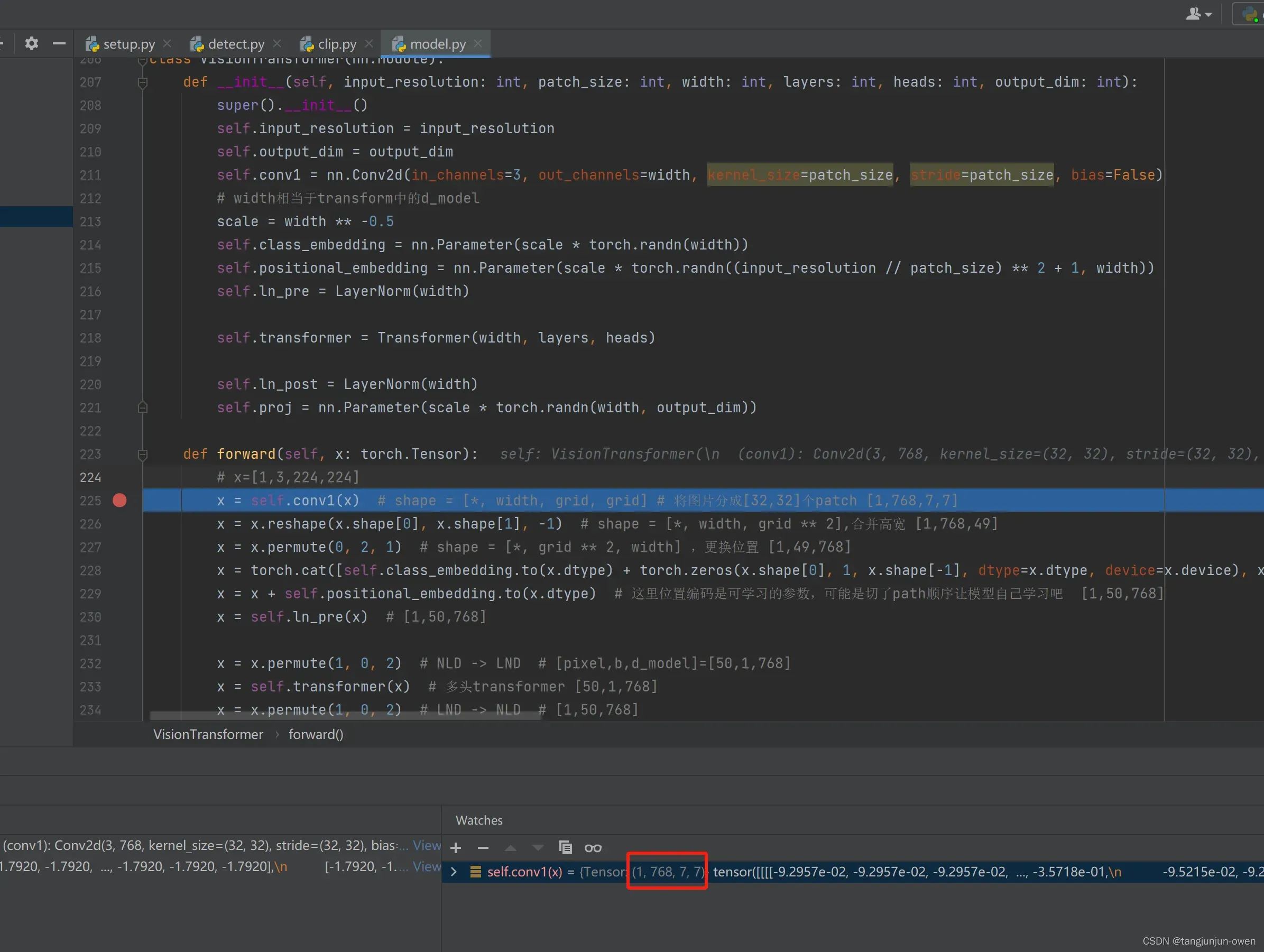
# x=[1,3,224,224]
x = self.conv1(x) # shape = [*, width, grid, grid] # 将图片分成[32,32]个patch [1,768,7,7]
x = x.reshape(x.shape[0], x.shape[1], -1) # shape = [*, width, grid ** 2],合并高宽 [1,768,49]
x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width] ,更换位置 [1,49,768]
x = torch.cat([self.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1) # shape = [*, grid ** 2 + 1, width],添加cls token[1,50,768]
x = x + self.positional_embedding.to(x.dtype) # 这里位置编码是可学习的参数,可能是切了path顺序让模型自己学习吧 [1,50,768]
x = self.ln_pre(x) # [1,50,768]
x = x.permute(1, 0, 2) # NLD -> LND # [pixel,b,d_model]=[50,1,768]
x = self.transformer(x) # 多头transformer [50,1,768]
x = x.permute(1, 0, 2) # LND -> NLD # [1,50,768]
x = self.ln_post(x[:, 0, :]) # x[:, 0, :] 将所有信息汇聚到cls token中,只需前面来做下游任务 [1,768]
if self.proj is not None: # self.proj是可学习参数,维度为[768,512]
x = x @ self.proj # 通过学习参数将维度再次融合变成512特征,最终为[1,512]
return x
以上可知,图片首先切成patch块,然后转成transformer能使用的结构,该结构可参考这里,同时,代码也有位置编码模块与特征结合,随后将所有信息汇聚到cls token,可实现下游任务,最后也通过可学习参数实现最终图像特征提取。我将在下面具体解读。
3、图像patch方法代码解读
将图像划分patch实际是VIT最重要思想,意在解决训练和推理速度问题,代码层面处理,实际为卷积核与步长来处理,代码如下:
self.conv1 = nn.Conv2d(in_channels=3, out_channels=width, kernel_size=patch_size, stride=patch_size, bias=False)
以上代码简单一句,即可将如[1,3,224,224]的一个图片分成3232尺寸(vit使用1616,这个根据模型而定,仅是一个参数而已)化成768个patch,高宽分别为7,格式为[1,768,7,7]:
# x=[1,3,224,224]
x = self.conv1(x) # shape = [*, width, grid, grid] # 将图片分成[32,32]个patch [1,768,7,7]
结果如图:
768来源:VIT模型将输入224224尺寸化成1616像素的patch,那么每个patch为16163=768,其中3为图像通道,将每个patch投影为768维度表示,也就是本文中self.conv1通道为768的缘故。
196与49区别:196也是来源VIT将224变成16尺寸的patch,那么共有224224/(1616)=196,而本文的patch尺寸为32,变成224224/(3232)=49。
最终图像使用reshape将宽高7*7合并转为49的像素,成为[1,49,768],可理解1为batch在NLP中表示一句话,49为像素在NLP中表示文字,768为每个patch投影表达在NLP中表示d_model为每个文字使用d_model表达特征。其代码如下:
x = x.reshape(x.shape[0], x.shape[1], -1) # shape = [*, width, grid ** 2],合并高宽 [1,768,49]
x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width] ,更换位置 [1,49,768]
3、图像cls token编码代码解读
cls token为VIT较为特殊设置,是一个可学习参数,我已在上面原理中介绍,不在细说,只解读实现方式,实现代码如下:
scale = width ** -0.5
self.class_embedding = nn.Parameter(scale * torch.randn(width))
将cls token嵌入,原来[1,49,768]变为[1,50,768],其代码中如下:
x = torch.cat([self.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1) # shape = [*, grid ** 2 + 1, width],添加cls token[1,50,768]
若在VIT模型cls token嵌入,将[1,196,768]变成[1,197,768]。
4、图像位置编码代码解读
位置编码也是一个可学习参数,实现代码如下:
self.positional_embedding = nn.Parameter(scale * torch.randn((input_resolution // patch_size) ** 2 + 1, width))
将位置编码嵌入,实际是x加上了位置信息,和我之前attention is all you need文章解释类似,该结构代码如下:
x = x + self.positional_embedding.to(x.dtype) # 这里位置编码是可学习的参数,可能是切了path顺序让模型自己学习吧 [1,50,768]
5、图像cls token特征表达代码解读
最终每张图像特征表达直接使用cls token来代替,直接取前第一个,如下图显示:
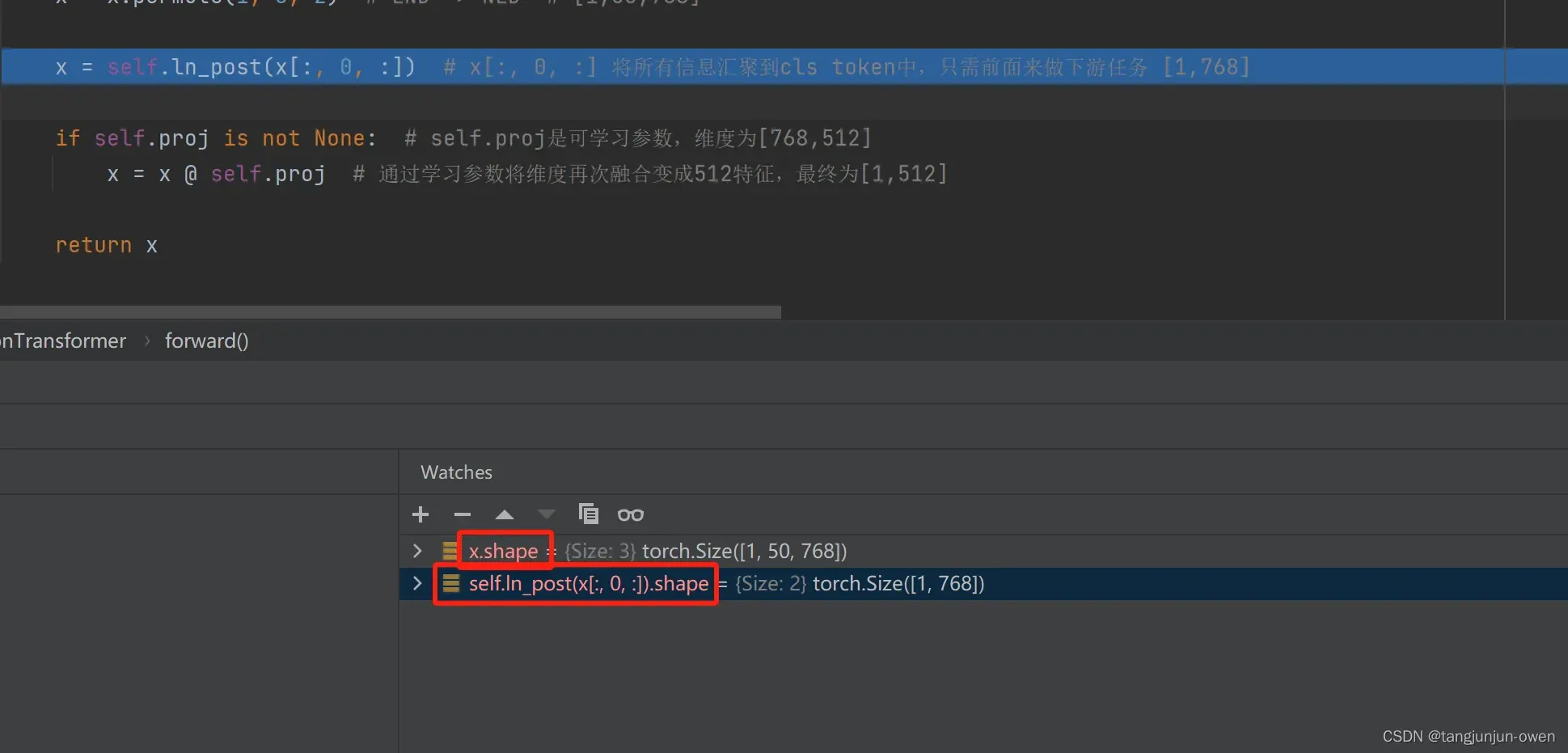
6、图像特殊结构代码解读
proj特殊结构,该结构若使用将进一步将图像特征表达进行变换,该变换的self.proj是可学习参数,代码如下:
self.proj = nn.Parameter(scale * torch.randn(width, output_dim))
将该结构嵌入,我理解可进一步特征混合整合或组合获得图像特征表达,该结构代码如下:
if self.proj is not None: # self.proj是可学习参数,维度为[768,512]
x = x @ self.proj # 通过学习参数将维度再次融合变成512特征,最终为[1,512]
代码运行图像显示如下:
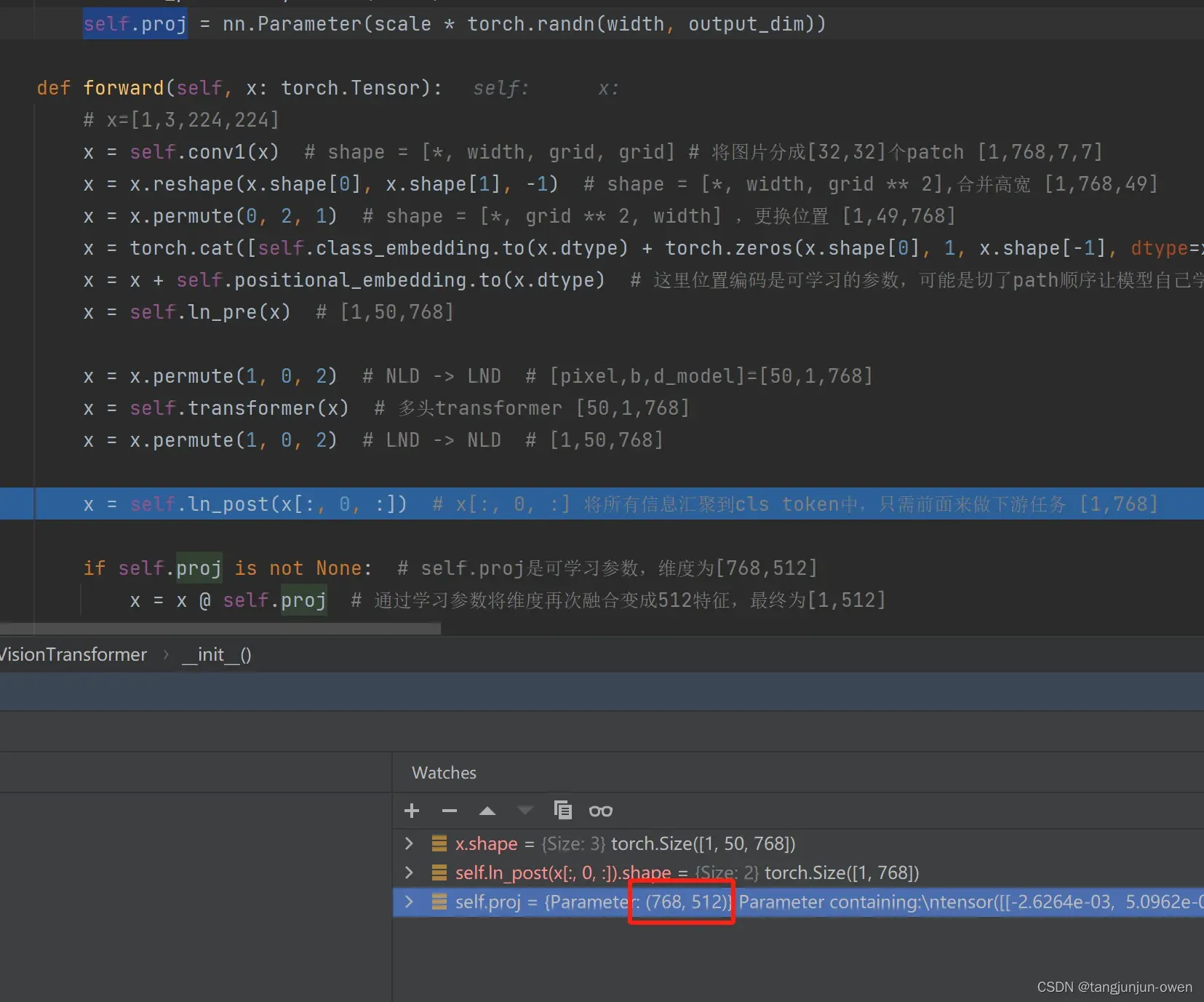
我个人觉得该结构可被借鉴。
六、CLIP的text encode代码解读
文本编码使用BERT编码结构,显然使用transformer结构编码提取文本特征,最终获得特征表达。接下来,我将详细阐述。
1、主函数代码解读
CLIP使用encode_text函数调用,如下:
text_features = self.encode_text(text)
而encode_text函数如下:
def encode_text(self, text):
# x 每个句子前面有值,有2个特殊符号[CLS]与[Seq]
x = self.token_embedding(text).type(self.dtype) # [batch_size, n_ctx, d_model],[3,77,512]
x = x + self.positional_embedding.type(self.dtype) # 位置编码直接赋可学习位置,添加位置信息[3,77,512]
x = x.permute(1, 0, 2) # NLD -> LND,[77,3,512]
x = self.transformer(x) # 共11个 和图像encode结构一致 [77,3,512]
x = x.permute(1, 0, 2) # LND -> NLD,[3,77,512]
x = self.ln_final(x).type(self.dtype)
# x.shape = [batch_size, n_ctx, transformer.width]
# take features from the eot embedding (eot_token is the highest number in each sequence)
# text.argmax(dim=-1) 句子最后有一个seq字段,是最大的,因此能获得句子个数数量
x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
return x
2、文本token代码解读
文本编码和我之前文章点击这里解释transform的encode基本相同,读者可查看。很多与我之前文章相同内容将不在解释,该小节说明如何使用文本token。首先文本为text_language = ["a diagram", "a dog", "a black cat"],也就是三句话,每句话大概几个词,其转码为下图计算机可识别符号方法,查阅我的博客点击这里。其代码如下:
x = self.token_embedding(text).type(self.dtype) # [batch_size, n_ctx, d_model],[3,77,512]
其结果如下图:
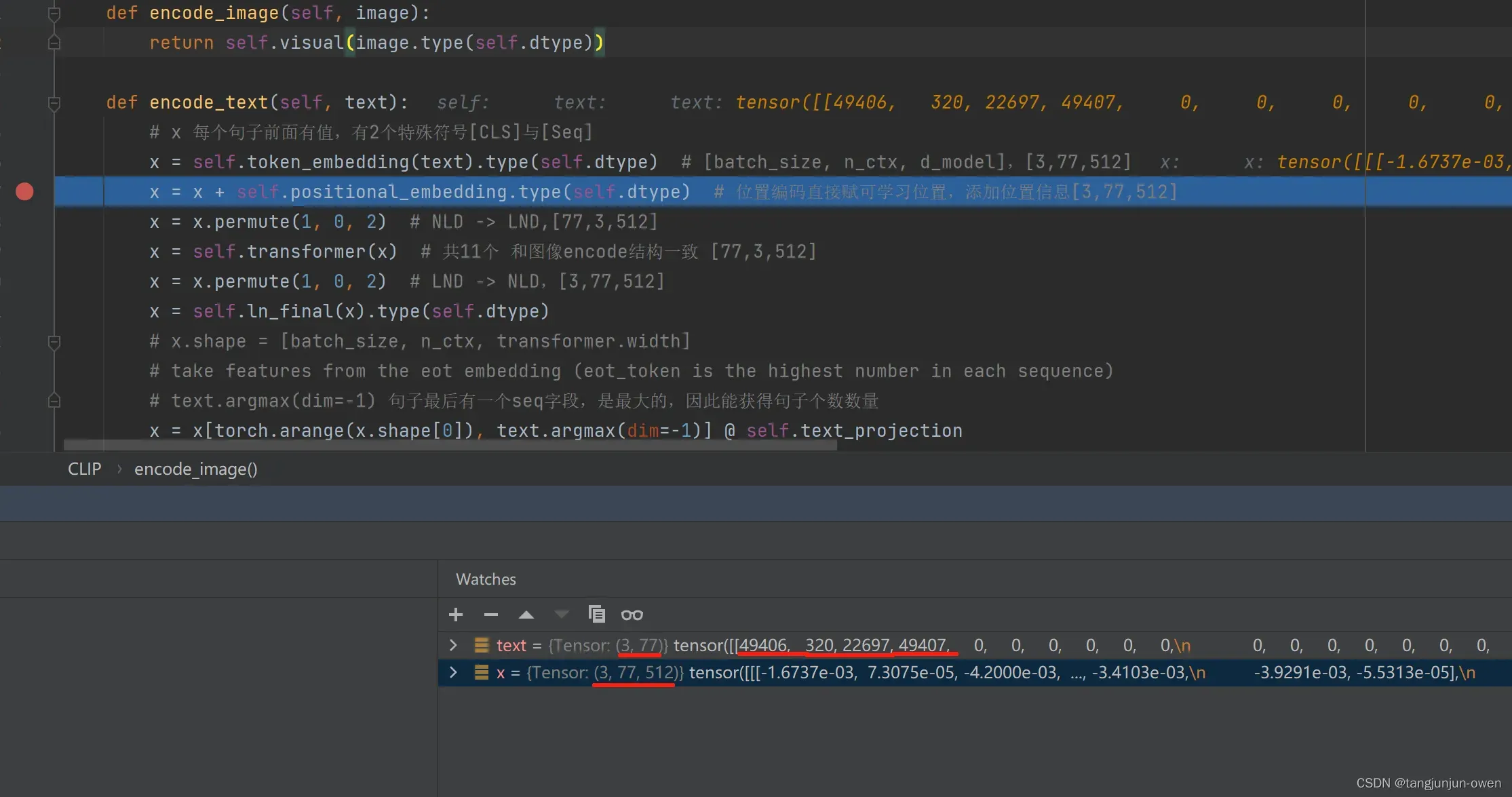
以上可知,文本变成[3,77]结构,如输入text第一行文本为”a diagram”,理论映射只有2个,但有四个数字,其中第一个为[CLS]值,最后一个为[Seq]值,本文设置每个句子长度为77,不足使用0表示,最终变成[3,77]表示为3个句子有77个文字(不足用0表示)。最终使用512维度表达,成为[3,77,512]结构,该部分与我之前文章内容一致,详情可参考之前文章。
3、文本位置编码代码解读
位置编码也是一个可学习参数,实现代码如下:
self.positional_embedding = nn.Parameter(torch.empty(self.context_length, transformer_width))
将位置编码嵌入,实际是x加上了位置信息,和我之前attention is all you need文章解释类似,该结构代码如下:
x = x + self.positional_embedding.type(self.dtype) # 位置编码直接赋可学习位置,添加位置信息[3,77,512]
4、文本特殊结构代码解读
self.text_projection特殊结构,该结构若使用将进一步将文本特征表达进行变换,该变换的self.text_projection是可学习参数,代码如下:
self.text_projection = nn.Parameter(torch.empty(transformer_width, embed_dim))
将该结构嵌入,与图像变啊特殊结构类似,该结构代码如下:
# text.argmax(dim=-1) 句子最后有一个seq字段,是最大的,因此能获得句子个数数量
x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
注:x[torch.arange(x.shape[0]), text.argmax(dim=-1)]改代码表达取x为[3,77,512]维度索引分别[0,3],[1,3],[2,4],得到三个句子512维度特征表达,而每个句子都是取第二个维度77文字最大那一个,我的理解是每句话都是从第一个文字[CLS]叠加到最后一个文字[Seq],因此使用最后一个就有时序表达该句话的特征。
代码运行图像显示如下:
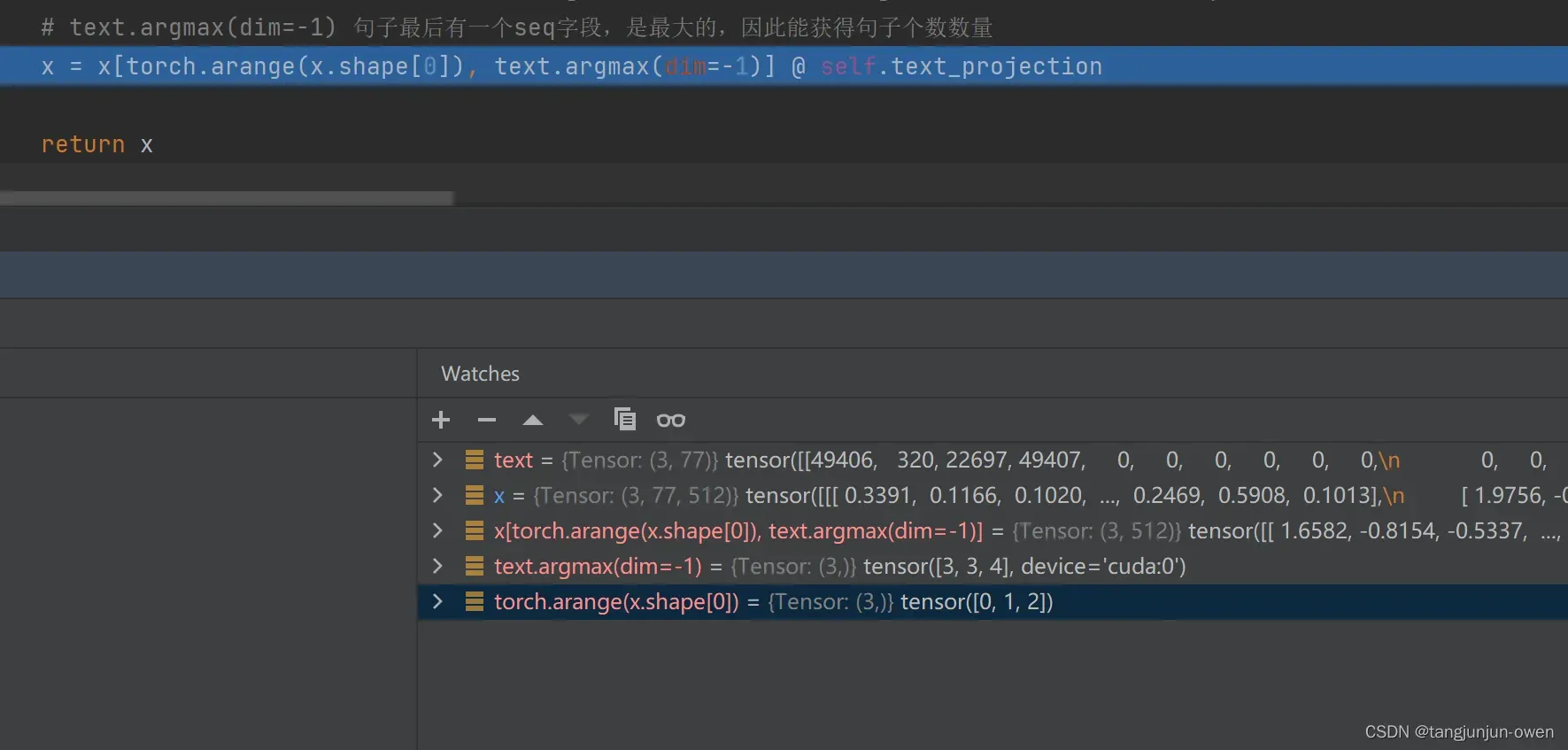
至于文本encode过程可参考代码走向,因其过于简单,我不在说明。
七、CLIP多模态融合代码解读
在上面小节中我们已然知晓图像编码与文本编码方式,该小节说明获得图像、文本特征表达融合方式,其代码如下:
def forward(self, image, text):
image_features = self.encode_image(image)
text_features = self.encode_text(text)
# normalized features,# 每一行sqr(a1^2+a2^2+...)
image_features = image_features / image_features.norm(dim=1, keepdim=True) # [batch_img,512]
text_features = text_features / text_features.norm(dim=1, keepdim=True) # [batch_text,512]
# cosine similarity as logits
logit_scale = self.logit_scale.exp() # 可学习参数
logits_per_image = logit_scale * image_features @ text_features.t() # 特征相乘获得相似度
logits_per_text = logits_per_image.t() # 变成文本
# shape = [global_batch_size, global_batch_size]
return logits_per_image, logits_per_text
从代码可知,图像特征与文本特征进行norm(其作用在上面已说明),然后求解其相似度获得图像与文本匹配结果。其过程也较为简单,可直接参考以上源码,其图示如下:
图像特征为[1,512]表示一个图像被512维度表达;
文本特征[3,512]表示3个句子分别被512维度表达;
八、CLIP推理结构解读
推理代码官网也有提供,直接官网下载权重便可实现,我使用VIT-B-32模型结构,实现推理分类任务。该模型使用对比学习,可定义很多文本,让每个图像与多个文本特征相似匹配,匹配值越高,自然就是那个类。如同,我在上面CLIP模型主函数代码解读说明一样。其代码如下:
import torch
import clip
from PIL import Image
import numpy as np
def class_demo():
# 测试分类的demo
device = "cuda" if torch.cuda.is_available() else "cpu"
# 模型选择['RN50', 'RN101', 'RN50x4', 'RN50x16', 'ViT-B/32', 'ViT-B/16'],对应不同权重
model, preprocess = clip.load("../ViT-B-32.pt", device=device) # 载入模型
image = preprocess(Image.open("../CLIP.png")).unsqueeze(0).to(device)
text_language = ["a diagram", "a dog", "a black cat"]
text = clip.tokenize(text_language).to(device)
with torch.no_grad():
logits_per_image, logits_per_text = model(image, text) # 第一个值是图像,第二个是第一个的转置
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
idx = np.argmax(probs, axis=1)
for i in range(image.shape[0]):
id = idx[i]
print('image {}\tlabel\t{}:\t{}'.format(i, text_language[id],probs[i,id]))
print('image {}:\t{}'.format(i, [v for v in zip(text_language,probs[i])]))
if __name__ == '__main__':
class_demo()
其结果如下:

九、CLIP训练结构解读
分类的CLIP训练实际是交叉熵方法,我们获得匹配值,可看成每个图像分别与不同文本相似值为预测类别值,进行类似交叉熵运算即可,另外反过来也可看成每个文本与分别与不同图像相似值为预测值,亦可进行交叉熵运算。我大概查了github其它训练方法,可供参考,其代码如下:
with torch.no_grad():
for i, batch in enumerate(dataloader):
images, texts = batch
images = images.to(device=device, non_blocking=True)
texts = texts.to(device=device, non_blocking=True)
with autocast():
image_features, text_features, logit_scale = model(images, texts)
# features are accumulated in CPU tensors, otherwise GPU memory exhausted quickly
# however, system RAM is easily exceeded and compute time becomes problematic
all_image_features.append(image_features.cpu())
all_text_features.append(text_features.cpu())
logit_scale = logit_scale.mean()
logits_per_image = logit_scale * image_features @ text_features.t()
logits_per_text = logits_per_image.t()
batch_size = images.shape[0]
labels = torch.arange(batch_size, device=device).long()
total_loss = (
F.cross_entropy(logits_per_image, labels) +
F.cross_entropy(logits_per_text, labels)
) / 2
博客可参考:点击这里
总结
CLIP为多模态融合奠定了基准,也是通过对比训练可实现无监督大模型预训练。个人觉得还是比较重要。
文章出处登录后可见!