👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。
当当书籍数据抓取分析与可视化(代码+报告)
目录
- 当当书籍数据抓取分析与可视化(代码+报告)
- 1. 数据抓取
- 2. 数据收集
- 3. 数据存储
- 3.1 excel存储
- 3.2 数据库存储
- 4. 数据清洗
- 5. 数据可视化
- 5.1单价前十名的书籍可视化
- 5.2 数据占据前十名的出版社
- 5.3出版年份可视化
本项目旨在研究和分析当当网上的书籍信息。当当网作为中国领先的在线零售平台之一,其上架的书籍种类繁多,涵盖了从文学、科技到教育等多个领域。这些书籍信息不仅能反映出市场上的流行趋势,还可以揭示消费者的购买偏好和出版业的发展动态。
项目的第一阶段集中在通过网络爬虫技术从当当网上爬取书籍数据。使用Python语言,结合requests和lxml库,项目团队成功地爬取了书名、作者、单价、出版日期、出版社和书籍简介等关键信息。在这个过程中,团队克服了多种网络爬虫的常见挑战,如网页编码处理、动态加载的内容、反爬机制的规避,以及数据的有效提取。
收集到的原始数据经过清洗和整理,移除了不完整或不符合要求的记录,以确保后续分析的准确性。这一步骤使用pandas等数据处理工具完成,有效地筛选出了高质量的数据集。
1. 数据抓取
发送HTTP请求:使用requests库发送HTTP GET请求,向当当网的多个页面获取网页内容。通过指定URL和参数,可以获取不同页面的图书信息。解析网页内容:使用lxml库对网页内容进行解析。通过使用XPath表达式,可以定位和提取所需的数据。在这段代码中,使用XPath表达式提取了书名、作者、价格、出版日期和出版社等信息。循环遍历页面:通过在代码中使用for循环,可以循环遍历多个页面。在每个页面上执行相同的爬取和解析操作,以获取更多的图书信息。处理异常情况:通过使用try-except语句,可以捕获可能的异常情况,例如在解析页面时出现的XPath定位错误。在这段代码中,使用try-except语句来处理可能出现的异常,并在出现异常时将相应字段设置为默认值。数据存储:图书信息被添加到一个二维列表data中,以便后续写入Excel文件。
from lxml import etree
import requests
import csv
from openpyxl import Workbook
data = [['书名', '作者', '单价', '出版日期', '出版社', '简介']]
for m in range(1, 6):
url = 'https://search.xxxx.com/?key=xxxxxx.page_index={}'.format(m)
response = requests.get(url)
if response.status_code == 200:
pass
👇👇👇 关注公众号,回复 “当当书籍数据抓取” 获取源码👇👇👇
2. 数据收集
从当当网爬取的数据包括书籍的各种信息。具体爬取的数据字段包括:
书名:每本书的标题。
作者:书籍的作者。
单价:书籍的价格。
出版日期:书籍的出版时间。
出版社:出版书籍的出版社。
简介:书籍的简短描述。
3. 数据存储
3.1 excel存储
通过如下代码,存储到excel表格中:
👇👇👇 关注公众号,回复 “当当书籍数据抓取” 获取源码👇👇👇
# 创建一个新的 Excel 文件
wb = Workbook()
sheet = wb.active
# 逐行写入数据
for row_index, row_data in enumerate(data, start=1):
for column_index, value in enumerate(row_data, start=1):
sheet.cell(row=row_index, column=column_index, value=value)
# 保存文件
wb.save('处理前数据.xlsx')
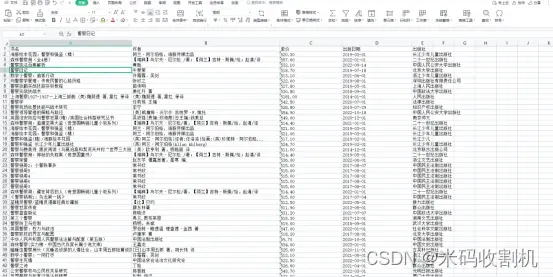
3.2 数据库存储
安装和配置:MySQL可以通过官方网站下载并按照指南进行安装。安装完成后,可以通过配置文件对MySQL进行各种设置,如端口号、字符集、缓冲区等。
连接数据库:在Python中,可以使用多个库(如mysql-connector-python、PyMySQL、MySQLdb)来连接MySQL数据库。需要提供主机地址、用户名、密码和数据库名等连接信息。连接成功后,可以创建游标对象用于执行SQL语句。
执行SQL语句:可以使用SQL语句对数据库进行各种操作,如创建表、插入数据、查询数据、更新数据和删除数据等。通过游标对象的execute()方法执行SQL语句,可以使用参数绑定来安全地插入数据。
事务处理:MySQL支持事务,可以使用commit()方法提交事务,将更改保存到数据库中,或使用rollback()方法回滚事务,撤销未提交的更改。
查询数据:可以使用SELECT语句从表中检索数据。执行查询后,可以使用fetchone()、fetchall()或fetchmany()等方法获取查询结果。
数据类型:MySQL提供了多种数据类型,如整数、浮点数、字符串、日期和时间等。合理选择和使用适当的数据类型有助于提高数据库性能和数据存储的效率。
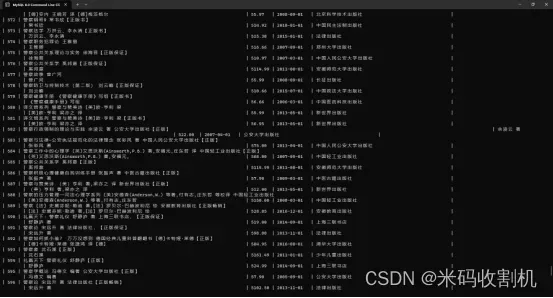
4. 数据清洗
导入库:import pandas as pd:导入了pandas库,它是一个强大的数据处理库,常用于数据分析。
文件路径设置:excel_file_path:设置了原始数据文件(data.xlsx)的路径。output_excel_file_path:定义了清洗后数据要保存的文件路径(处理后的数据.xlsx)。
读取Excel文件:使用pd.read_excel(excel_file_path, engine=“openpyxl”)读取Excel文件。这里指定了openpyxl作为引擎,因为它支持.xlsx格式的文件。
数据清洗:df_filtered = df[~df.apply(lambda x: x.astype(str).str.contains(‘无’)).any(axis=1)]:这一行代码是数据清洗的关键。
它将DataFrame中包含“无”的行排除。apply(lambda x: x.astype(str).str.contains(‘无’))将DataFrame的每个元素转换为字符串,然后检查是否包含“无”字样。
~符号表示否定,因此这行代码的含义是选择那些不包含“无”字样的行。
any(axis=1)确保任何列中出现“无”的行都将被排除。
保存清洗后的数据:df_filtered.to_excel(output_excel_file_path, index=False):将清洗后的数据保存到Excel文件。index=False表示在保存时不包括行索引。
打印DataFrame:print(df)将打印原始数据的DataFrame。这可能用于检查数据载入是否正确,但在实际的数据处理脚本中可能不是必要的。
清洗后的数据如下:
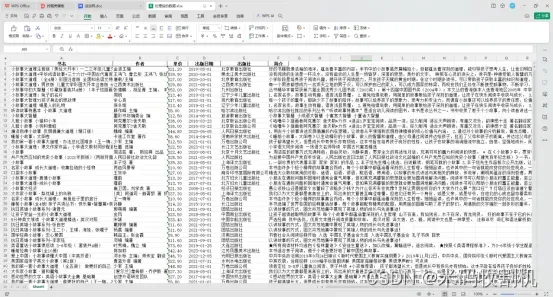
5. 数据可视化
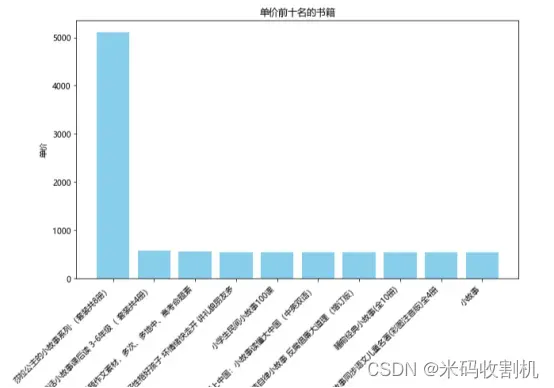
5.1单价前十名的书籍可视化
top_10_prices = df.nlargest(10, ‘单价’):这行代码使用pandas的nlargest方法从DataFrame df 中提取单价最高的前10本书。这个方法根据单价列的值排序并选择前10个最大值。
绘制柱状图:plt.figure(figsize=(10, 6)):设置图表的大小为10×6英寸。这有助于确保图表在展示时有足够的空间来清晰地显示所有信息。
plt.bar(top_10_prices[‘书名’], top_10_prices[‘单价’], color=‘skyblue’):使用柱状图(bar)来展示数据。top_10_prices[‘书名’] 和 top_10_prices[‘单价’] 分别指定了X轴和Y轴的数据。color=’skyblue’设置了柱子的颜色为天蓝色。
设置图表细节:plt.xlabel(‘书名’) 和 plt.ylabel(‘单价’):分别设置X轴和Y轴的标签为“书名”和“单价”。plt.title(‘单价前十名的书籍’):设置图表的标题。
plt.xticks(rotation=45, ha=‘right’):设置X轴的刻度标签(即书名)旋转45度,并且对齐方式为右对齐。这样做可以防止标签文字相互重叠,确保每个书名都清晰可读。plt.tight_layout():这个方法用于自动调整子图参数,确保图表的元素(如标题、轴标签)都被整齐地展示,而不会发生重叠或遮挡的情况。
👇👇👇 关注公众号,回复 “当当书籍数据抓取” 获取源码👇👇👇
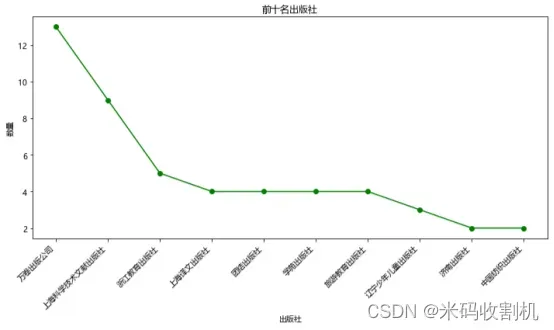
5.2 数据占据前十名的出版社
计算出版社出现频率:top_publishers = df[‘出版社’].value_counts().head(10):这行代码首先对df中的出版社列使用value_counts方法,该方法统计了每个独特出版社出现的次数。随后,通过.head(10)提取了频率最高的前10个出版社。
绘制折线图:plt.figure(figsize=(10, 6)):设置图表的大小为10×6英寸,以确保图表的可读性。plt.plot(top_publishers.index, top_publishers.values, marker=‘o’, linestyle=‘-’, color=‘green’):绘制折线图。这里,top_publishers.index代表出版社名称,top_publishers.values代表相应的出现次数。marker=‘o’设置了数据点的标记为圆形,linestyle=’-‘设置了线型为实线,color=’green’设置了线条颜色为绿色。
设置图表细节:plt.xlabel(‘出版社’) 和 plt.ylabel(‘数量’):分别为X轴和Y轴设置标签,分别表示出版社和对应的出版数量。plt.title(‘前十名出版社’):设置图表的标题。plt.xticks(rotation=45, ha=‘right’):将X轴的刻度标签(即出版社名称)旋转45度,并设置为右对齐。这有助于防止标签文字相互重叠,确保每个出版社名称都清晰可读。plt.tight_layout():调整子图参数,确保图表的元素(如标题、轴标签)整齐展示,避免重叠或遮挡。
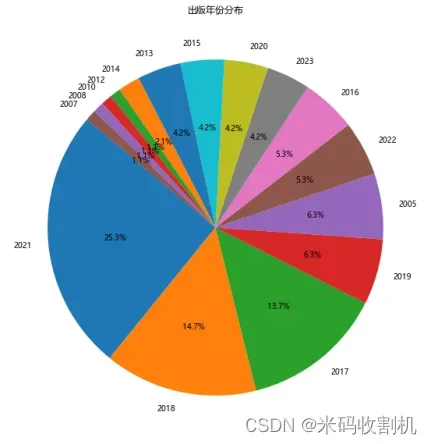
5.3出版年份可视化
转换出版日期为年份:df[‘出版年份’] = pd.to_datetime(df[‘出版日期’]).dt.year:这行代码首先使用pandas的to_datetime函数将出版日期列转换为datetime对象,随后通过.dt.year属性获取每个日期的年份部分。这样,每本书的出版年份就被提取并存储在新的出版年份列中。
计算年份分布:year_counts = df[‘出版年份’].value_counts():使用value_counts方法计算出版年份列中每个年份出现的次数,即每个年份出版的书籍数量。
绘制饼图:plt.figure(figsize=(8, 8)):设置饼图的大小为8×8英寸,保证足够的展示空间。plt.pie(year_counts, labels=year_counts.index, autopct=‘%1.1f%%’, startangle=140):使用pie方法绘制饼图。year_counts为各年份的书籍数量,labels=year_counts.index设置了饼图中每部分的标签为年份,autopct=’%1.1f%%’设置了每部分的百分比格式,startangle=140设定了饼图的起始角度。设置图表标题和布局:plt.title(‘出版年份分布’):为饼图设置标题“出版年份分布”。plt.tight_layout():调整子图参数,确保图表的元素(如标题)整齐展示,避免重叠或遮挡。
👇👇👇 关注公众号,回复 “当当书籍数据抓取” 获取源码👇👇👇
文章出处登录后可见!