python读取通达信每日数据和五分钟数据,并且上传到clickhouse
本文主要是借助txd和python实现数据下载,并上传到数据库,实现高效的数据查询和统计
通达信读取五分钟数据
通达信将分钟数据文件.lc 转换为cvs格式,这里可以通过Dbeaver直接导入cvs格式文件,转换代码在下面,导入后是多个文件夹,表名为股票代码
import os
import struct
import math
from tqdm import tqdm
# 根据二进制前两段拿到日期分时
def get_date_str(h1, h2) -> str: # H1->0,1字节; H2->2,3字节;
year = math.floor(h1 / 2048) + 2004 # 解析出年
month = math.floor(h1 % 2048 / 100) # 月
day = h1 % 2048 % 100 # 日
hour = math.floor(h2 / 60) # 小时
minute = h2 % 60 # 分钟
if hour < 10: # 如果小时小于两位, 补0
hour = "0" + str(hour)
if minute < 10: # 如果分钟小于两位, 补0
minute = "0" + str(minute)
return str(year) + "-" + str(month) + "-" + str(day) + " " + str(hour) + ":" + str(minute)
# 根据通达信.lc5文件,生成对应名称的csv文件
def stock_lc5(filepath, name, targetdir) -> None:
# (通达信.lc5文件路径, 通达信.lc5文件名称, 处理后要保存到的文件夹)
with open(filepath, 'rb') as f: # 读取通达信.lc5文件,并处理
file_object_path = targetdir + name + '.csv' # 设置处理后保存文件的路径和名称
file_object = open(file_object_path, 'w+') # 打开新建的csv文件,开始写入数据
title_list = "date,open,high,low,close,open_interest,volume,settlement_price\n" # 定义csv文件标题
file_object.writelines(title_list) # 将文件标题写入到csv中
while True:
li2 = f.read(32) # 读取一个5分钟数据
if not li2: # 如果没有数据了,就退出
break
data2 = struct.unpack('HHffffllf', li2) # 解析数据
date_str = get_date_str(data2[0], data2[1]) # 解析日期和分时
data2_list = list(data2) # 将数据转成list
data2_list[1] = date_str # 将list二个元素更改为日期 时:分
del (data2_list[0]) # 删除list第一个元素
for dl in range(len(data2_list)): # 将list中的内容都转成字符串str
data2_list[dl] = str(data2_list[dl])
data2_str = ",".join(data2_list) # 将list转换成字符串str
data2_str += "\n" # 添加换行
file_object.writelines(data2_str) # 写入一行数据
file_object.close() # 完成数据写入
# 设置通达信.day文件所在的文件夹
path_dir = 'C://new_tdx//vipdoc//sh//fzline'
# 设置数据处理好后,要将csv文件保存的文件夹
target_dir = 'D:\TDXdata\lc/'
# 读取文件夹下的通达信.day文件
listfile = os.listdir(path_dir)
tq = tqdm(listfile, leave=False, position=None)
# 逐个处理文件夹下的通达信.day文件,并生成对应的csv文件,保存到../day/文件夹下
for fname in tq:
stock_lc5(path_dir+os.sep+fname, fname, target_dir)
else:
print('The for ' + path_dir + ' to ' + target_dir + ' loop is over')
print("文件转换已完成")
# 配置部分开始
debug = False # 是否开启调试日志输出 开=True 关=False
# 目录最好事先手动建立好,不然程序会出错
tdx = {
'tdx_path': 'C:/new_tdx', # 指定通达信目录
'csv_lday': 'd:/TDXdata/lday_qfq', # 指定csv格式日线数据保存目录
'pickle': 'd:/TDXdata/pickle', # 指定pickle格式日线数据保存目录
'csv_index': 'd:/TDXdata/index', # 指定指数保存目录
'csv_cw': 'd:/TDXdata/cw', # 指定专业财务保存目录
'csv_gbbq': 'd:/TDXdata', # 指定股本变迁保存目录
'pytdx_ip': '123.125.108.23', # 指定pytdx的通达信服务器IP
'pytdx_port': 7709, # 指定pytdx的通达信服务器端口。int类型
}
index_list = [ # 通达信需要转换的指数文件。通达信按998查看重要指数
'sh999999.day', # 上证指数
'sh000300.day', # 沪深300
'sz399001.day', # 深成指
]
# 配置部分结束
这里的代码来自参考代码的第一条,主要是这个大佬,文件处理的很好,因此这里不做修改
由于本地转成excel查询很麻烦,然后数据库的效率很高,因此采用clickhouse数据库搭建
通达信读取每日数据
这里直接参考参考文献第一条的代码,缺的代码,请到链接处自己下载
#!/usr/bin/python
# -*- coding: UTF-8 -*-
"""
在网络读取通达信代码上修改加工,增加、完善了一些功能
1、增加了读取深市股票功能。
2、增加了在已有数据的基础上追加最新数据,而非完全删除重灌。
3、增加了读取上证指数、沪深300指数功能。
4、没有使用pandas库,但输出的CSV格式是pandas库的dataFrame格式。
5、过滤了无关的债券指数、板块指数等,只读取沪市、深市A股股票。
数据单位:金额(元),成交量(股)
作者:wking [http://wkings.net]
"""
import os
import sys
import time
import pandas as pd
import argparse
from tqdm import tqdm
from multiprocessing import Pool, RLock, freeze_support
import func
import user_config as ucfg
from clickhouse_driver import Client
def check_files_exist():
# 判断目录和文件是否存在。不存在则创建,存在且运行带有del参数则删除。
if os.path.exists(ucfg.tdx['csv_lday']) or os.path.exists(ucfg.tdx['csv_index']):
# choose = input("文件已存在,输入 y 删除现有文件并重新生成完整数据,其他输入则附加最新日期数据: ")
if 'del' in str(sys.argv[1:]):
for root, dirs, files in os.walk(ucfg.tdx['csv_lday'], topdown=False):
for name in files:
os.remove(os.path.join(root, name))
for name in dirs:
os.rmdir(os.path.join(root, name))
for root, dirs, files in os.walk(ucfg.tdx['csv_index'], topdown=False):
for name in files:
os.remove(os.path.join(root, name))
for name in dirs:
os.rmdir(os.path.join(root, name))
for root, dirs, files in os.walk(ucfg.tdx['pickle'], topdown=False):
for name in files:
os.remove(os.path.join(root, name))
for name in dirs:
os.rmdir(os.path.join(root, name))
try:
os.mkdir(ucfg.tdx['csv_lday'])
except FileExistsError:
pass
try:
os.mkdir(ucfg.tdx['csv_index'])
except FileExistsError:
pass
try:
os.mkdir(ucfg.tdx['pickle'])
except FileExistsError:
pass
else:
os.mkdir(ucfg.tdx['csv_lday'])
os.mkdir(ucfg.tdx['csv_index'])
def update_lday():
# 读取通达信正常交易状态的股票列表。infoharbor_spec.cfg退市文件不齐全,放弃使用
tdx_stocks = pd.read_csv(ucfg.tdx['tdx_path'] + '/T0002/hq_cache/infoharbor_ex.code',
sep='|', header=None, index_col=None, encoding='gbk', dtype={0: str})
file_listsh = tdx_stocks[0][tdx_stocks[0].apply(lambda x: x[0:1] == "6")]
file_listsz = tdx_stocks[0][tdx_stocks[0].apply(lambda x: x[0:1] != "6")]
'''
print("从通达信深市股票导出数据")
# file_list = os.listdir(ucfg.tdx['tdx_path'] + '/vipdoc/sz/lday')
for f in tqdm(file_listsz):
f = 'sz' + f + '.day'
if os.path.exists(ucfg.tdx['tdx_path'] + '/vipdoc/sz/lday/' + f): # 处理深市sh00开头和创业板sh30文件,否则跳过此次循环
# print(time.strftime("[%H:%M:%S] 处理 ", time.localtime()) + f)
func.day2csv(ucfg.tdx['tdx_path'] + '/vipdoc/sz/lday', f, ucfg.tdx['csv_lday'])
'''
print("从通达信导出沪市股票数据")
# file_list = os.listdir(ucfg.tdx['tdx_path'] + '/vipdoc/sh/lday')
for f in tqdm(file_listsh):
# 处理沪市sh6开头文件,否则跳过此次循环
f = 'sh' + f + '.day'
if os.path.exists(ucfg.tdx['tdx_path'] + '/vipdoc/sh/lday/' + f):
# print(time.strftime("[%H:%M:%S] 处理 ", time.localtime()) + f)
func.day2csv(ucfg.tdx['tdx_path'] + '/vipdoc/sh/lday', f, ucfg.tdx['csv_lday'])
print("从通达信导出指数数据")
for i in tqdm(ucfg.index_list):
# print(time.strftime("[%H:%M:%S] 处理 ", time.localtime()) + i)
if 'sh' in i:
func.day2csv(ucfg.tdx['tdx_path'] + '/vipdoc/sh/lday', i, ucfg.tdx['csv_index'])
elif 'sz' in i:
func.day2csv(ucfg.tdx['tdx_path'] + '/vipdoc/sz/lday', i, ucfg.tdx['csv_index'])
def qfq(file_list, df_gbbq, cw_dict, tqdm_position=None):
tq = tqdm(file_list, leave=False, position=tqdm_position)
for filename in tq:
# process_info = f'[{(file_list.index(filename) + 1):>4}/{str(len(file_list))}] {filename}'
df_bfq = pd.read_csv(ucfg.tdx['csv_lday'] + os.sep + filename, index_col=None, encoding='gbk',
dtype={'code': str})
df_qfq = func.make_fq(filename[:-4], df_bfq, df_gbbq, cw_dict)
#conn.execute('INSERT INTO test VALUES' , df_qfq)
# lefttime_tick = int((time.time() - starttime_tick) / (file_list.index(filename) + 1) * (len(file_list) - (file_list.index(filename) + 1)))
if len(df_qfq) > 0: # 返回值大于0,表示有更新
client.execute('INSERT INTO test VALUES', qfq)
df_qfq.to_csv(ucfg.tdx['csv_lday'] + os.sep + filename, index=False, encoding='gbk')
df_qfq.to_pickle(ucfg.tdx['pickle'] + os.sep + filename[:-4] + '.pkl')
tq.set_description(filename + "复权完成")
# print(f'{process_info} 复权完成 已用{(time.time() - starttime_tick):.2f}秒 剩余预计{lefttime_tick}秒')
else:
tq.set_description(filename + "无需更新")
# print(f'{process_info} 无需更新 已用{(time.time() - starttime_tick):.2f}秒 剩余预计{lefttime_tick}秒')
if __name__ == '__main__':
if 'del' in str(sys.argv[1:]):
print('检测到参数del, 删除现有文件并重新生成完整数据')
else:
print('附带命令行参数 readTDX_lday.py del 删除现有文件并重新生成完整数据')
if 'single' in sys.argv[1:]:
print(f'检测到参数 single, 单进程执行')
else:
print(f'附带命令行参数 single 单进程执行(默认多进程)')
# print('参数列表:', str(sys.argv[1:]))
# print('脚本名:', str(sys.argv[0]))
# 主程序开始
check_files_exist()
update_lday()
# 通达信文件处理完成
# 处理生成的通达信日线数据,复权加工代码
file_list = os.listdir(ucfg.tdx['csv_lday'])
starttime_tick = time.time()
df_gbbq = pd.read_csv(ucfg.tdx['csv_gbbq'] + '/gbbq.csv', encoding='gbk', dtype={'code': str})
cw_dict = func.readall_local_cwfile()
if 'single' in sys.argv[1:]:
qfq(file_list, df_gbbq, cw_dict)
else:
# 多进程
# print('Parent process %s' % os.getpid())
t_num = os.cpu_count()-2 # 进程数 读取CPU逻辑处理器个数
div, mod = int(len(file_list) / t_num), len(file_list) % t_num
freeze_support() # for Windows support
tqdm.set_lock(RLock()) # for managing output contention
p = Pool(processes=t_num, initializer=tqdm.set_lock, initargs=(tqdm.get_lock(),))
for i in range(0, t_num):
if i + 1 != t_num:
# print(i, i * div, (i + 1) * div)
p.apply_async(qfq, args=(file_list[i * div:(i + 1) * div], df_gbbq, cw_dict, i))
else:
# print(i, i * div, (i + 1) * div + mod)
p.apply_async(qfq, args=(file_list[i * div:(i + 1) * div + mod], df_gbbq, cw_dict, i))
p.close()
p.join()
print('日线数据全部处理完成')
搭建clickhouse数据库
clickhouse的性能
单个大查询的吞吐量
吞吐量可以使用每秒处理的行数或每秒处理的字节数来衡量。如果数据被放置在page cache中,则一个不太复杂的查询在单个服务器上大约能够以2-10GB/s(未压缩)的速度进行处理(对于简单的查询,速度可以达到30GB/s)。如果数据没有在page cache中的话,那么速度将取决于你的磁盘系统和数据的压缩率。例如,如果一个磁盘允许以400MB/s的速度读取数据,并且数据压缩率是3,则数据的处理速度为1.2GB/s。这意味着,如果你是在提取一个10字节的列,那么它的处理速度大约是1-2亿行每秒。
对于分布式处理,处理速度几乎是线性扩展的,但这受限于聚合或排序的结果不是那么大的情况下。
处理短查询的延迟时间
如果一个查询使用主键并且没有太多行(几十万)进行处理,并且没有查询太多的列,那么在数据被page cache缓存的情况下,它的延迟应该小于50毫秒(在最佳的情况下应该小于10毫秒)。 否则,延迟取决于数据的查找次数。如果你当前使用的是HDD,在数据没有加载的情况下,查询所需要的延迟可以通过以下公式计算得知: 查找时间(10 ms) * 查询的列的数量 * 查询的数据块的数量。
处理大量短查询的吞吐量
在相同的情况下,ClickHouse可以在单个服务器上每秒处理数百个查询(在最佳的情况下最多可以处理数千个)。但是由于这不适用于分析型场景。因此我们建议每秒最多查询100次。
数据的写入性能
我们建议每次写入不少于1000行的批量写入,或每秒不超过一个写入请求。当使用tab-separated格式将一份数据写入到MergeTree表中时,写入速度大约为50到200MB/s。如果您写入的数据每行为1Kb,那么写入的速度为50,000到200,000行每秒。如果您的行更小,那么写入速度将更高。为了提高写入性能,您可以使用多个INSERT进行并行写入,这将带来线性的性能提升。
ReplacingMergeTree引擎
该引擎和 MergeTree 的不同之处在于它会删除排序键值相同的重复项。
数据的去重只会在数据合并期间进行。合并会在后台一个不确定的时间进行,因此你无法预先作出计划。有一些数据可能仍未被处理。尽管你可以调用 OPTIMIZE 语句发起计划外的合并,但请不要依靠它,因为 OPTIMIZE 语句会引发对数据的大量读写。
因此,ReplacingMergeTree 适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。挺适合股票分析,因此主要用这个
搭建过程
安装 | ClickHouse Docs
请直接参考官方文件,里面有详细的描述,另外,数据大约为40g,历史的五分钟数据和day数据,我用的是腾讯云服务器
数据上传代码
from clickhouse_driver import Client
import re
from tqdm import tqdm
import os
import pandas as pd
import user_config as ucfg
client = Client('ip',database='jj', user='c',password='password',settings={"use_numpy":True})
file_list = os.listdir(ucfg.tdx['csv_lday'])
tq = tqdm(file_list, leave=False, position=None)
for filename in tq:
df=pd.read_csv('D:\TDXdata\lday_qfq\\'+filename)
df['date']=df['date'].apply(str)
df['code']=df['code'].apply(str)
#client.execute('DROP TABLE IF EXISTS test')
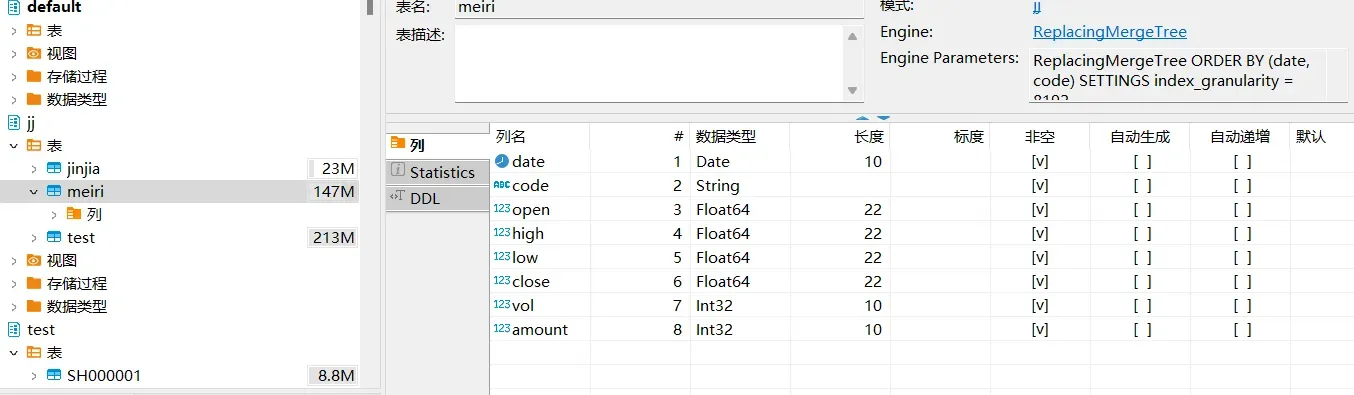
client.execute('CREATE TABLE IF NOT EXISTS meiri ( `date` Date, `code` String, `open` Float64,`high` Float64,`low` Float64,`close` Float64,`vol` Int32, `amount` Int32) ENGINE = ReplacingMergeTree ORDER BY (date,code)')
client.insert_dataframe('INSERT INTO meiri VALUES', df)
这里是每日的上传代码,上传后结果如下图所示
五分钟的代码下载链接如下:https://download.csdn.net/download/CBLXXX/87418923
历史的五分钟数据一般在tdx所属目录下面,建议自己去具体看一下,注意,通达信和很多方式一样无法获取所有的历史数据,建议通过类似tushare的方式获取
数据包含tdx,自2005年到2022年数据,最新的数据可以直接下载,通达信有下载时间的限制,同样akshare也有下载时间的限制
上传后,将以股票代码为表名
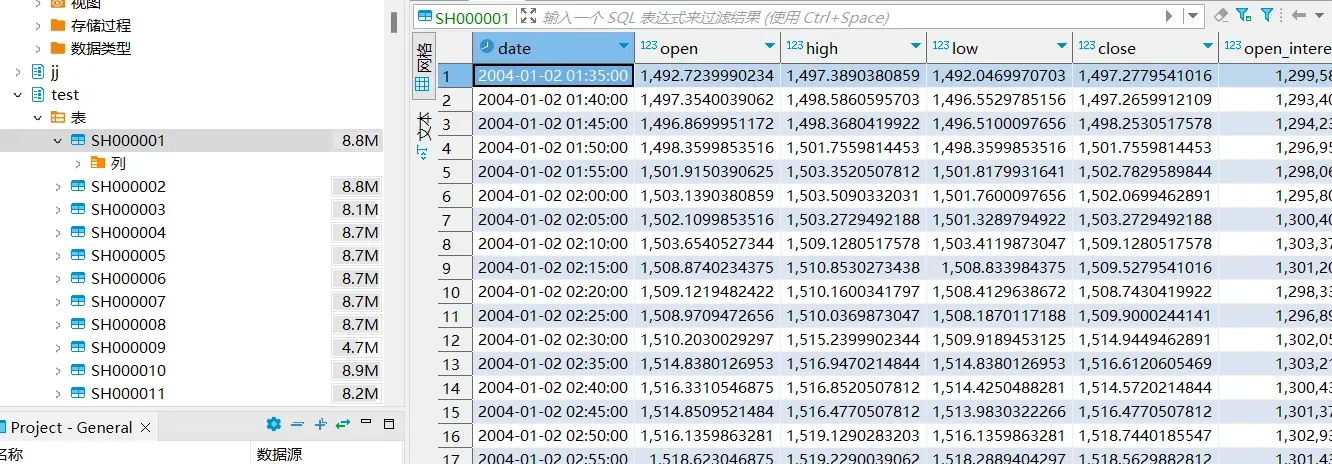
参考代码
股票分析: 使用python进行股票分析和选股 (gitee.com)
文章出处登录后可见!