dataframe类型是如何插入一行或一列数据的呢?这个需求在本文中将会进行讨论。相比较ndarray类型的同样的“数据插入”需求,dataframe的实现方式,则不是很好用。本文以一个dataframe类型变量为例,测试插入一行数据或者一列数据的方式方法。测试环境:win10,python@3.11.0,numpy@1.24.2,pandas@1.5.3。
某个位置插入列
因为dataframe的insert(),不走寻常路。
- 效果就是插入一列数据,并没有axis=这个参数来区分数据流的方向。
- 并且默认效果就是替换原变量,并不是return
新变量,并没有个inplace参数进行控制。
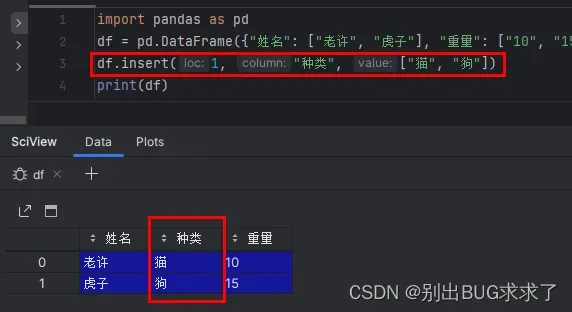
测试代码:
import pandas as pd
df = pd.DataFrame({"姓名": ["老许", "虎子"], "重量": ["10", "15"]})
df.insert(1, "种类", ["猫", "狗"])
print(df)
输出:
姓名 种类 重量
0 老许 猫 10
1 虎子 狗 15
这个dataframe将作为原始数据,参与本文后续的代码实验。
尾部插入列
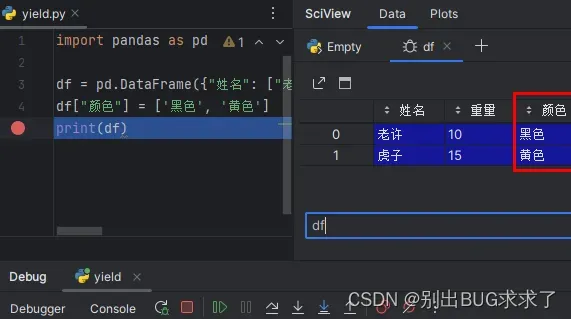
这个代码是最简单的,灰常简单。测试代码:
import pandas as pd
df = pd.DataFrame({"姓名": ["老许", "虎子"], "重量": ["10", "15"]})
df["颜色"] = ['黑色', '黄色']
print(df)
输出:
姓名 重量 颜色
0 老许 10 黑色
1 虎子 15 黄色
某个位置插入行
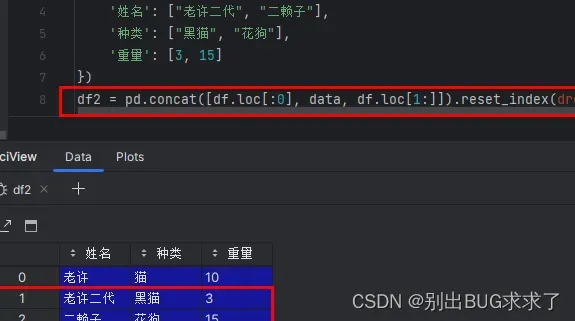
下面在第二行(编号1)位置插入两条数据。实际上先对dataframe在编号1位置进行了拆分,然后再在拆分的两部分中间放入了新的数据,最终执行合并操作。
import pandas as pd
df = pd.DataFrame({"姓名": ["老许", "虎子"],"种类": ["猫", "狗"], "重量": ["10", "15"]})
data = pd.DataFrame({
'姓名': ["老许二代", "二赖子"],
'种类': ["黑猫", "花狗"],
'重量': [3, 15]
})
df2 = pd.concat([df.loc[:0], data, df.loc[1:]]).reset_index(drop=True)
print(df2)
输出
姓名 种类 重量
0 老许 猫 10
1 老许二代 黑猫 3
2 二赖子 花狗 15
3 虎子 狗 15
尾部插入行
dataframe类型官方,对于插入新的一行数据的需求,就仅仅提供了一个append()操作,可以叠加新数据到尾部。
import pandas as pd
df = pd.DataFrame({"姓名": ["老许", "虎子"],"种类": ["猫", "狗"], "重量": ["10", "15"]})
data = pd.DataFrame({
'姓名': ["老许二代", "二赖子"],
'种类': ["黑猫", "花狗"],
'重量': [3, 15]
})
df3 = df.append(data, ignore_index=True)
print(df3)
输出
姓名 种类 重量
0 老许 猫 10
1 虎子 狗 15
2 老许二代 黑猫 3
3 二赖子 花狗 15

文章出处登录后可见!
已经登录?立即刷新