爬取网页上所有链接
文章目录
- 爬取网页上所有链接
- 前言
- 一、基本内容
- 二、代码编写
- 1.引入库
- 2.测试网页
- 3.请求网页
- 4.解析网页并保存
- 三、如何定义请求头?
- 总结
前言
最近也学了点爬虫的东西。今天就先给大家写一个简单的爬虫吧。循序渐进,慢慢来哈哈哈哈哈哈哈哈哈哈哈
一、基本内容
主要是以下几部分(下文基本会按照这个步骤来写):
- 导入需要的库
- 要测试的网页
- 生成代理,请求网页
- 请求成功,解析网页,找到并保存想要的东西
- 请求失败,返回相应状态码
二、代码编写
1.引入库
代码如下:
import requests
from bs4 import BeautifulSoup
requests: 这是一个非常流行的 Python 库,用于发送 HTTP 请求。它可以方便地让我们获取网页内容、下载文件、提交表单等网络操作。
BeautifulSoup: 这是一个用于解析 HTML 和 XML 文档的 Python 库。它能够将复杂的HTML文档转换成树形结构,使得我们可以轻松地搜索、遍历和修改文档中的元素。
2.测试网页
代码如下:
# 目标网页地址
url = 'http://www.santostang.com/'
3.请求网页
代码如下:
# 定义请求头的浏览器代理,伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome'
'/114.0.5735.289 Safari/537.36',
'host': 'www.santostang.com'}
# 请求网页
response = requests.get(url, headers=headers)
print(response.text)
请求头header提供了关于请求、相应或其他发送实体的信息。总之一句话,这个很重要不能少。
不清楚这个请求头怎么搞的不要担心,下面我会另起一章节告诉大家怎么弄。
response.text 的内容如下图(下面会从这个里面检索获取我们想要的信息):

4.解析网页并保存
代码如下:
# 状态码为200,请求成功
if response.status_code == 200:
# 打印状态码
print('Status Code: ', response.status_code)
# 解析 HTML 文档
soup = BeautifulSoup(response.text, 'html.parser')
# 找到所有的 <a>, <img> 和 <form> 标签
elements = soup.find_all(['a', 'img', 'form'])
# 打开一个文本文档并写入
with open('url.text', 'w', encoding='utf-8') as f:
# 打印每个元素的 href、src 或 action 属性
for element in elements:
if element.name == 'a':
link = element.get('href')
elif element.name == 'img':
link = element.get('src')
elif element.name == 'form':
link = element.get('action')
if link is not None:
# 每写入一个链接另起一行
f.write(link + '\n')
else:
# 请求未成功,返回相应的状态码
print(f'Failed to fetch the page with status code {response.status_code}')
第一步:判断是否请求成功,成功则进行下一步,失败则返回相应的状态码。
第二步:先解析解析 HTML 文档(response.text)。
第三步:找到所有链接前面的标签都有啥。
第四步:根据标签定位到相应的链接,获取它们。
第五步:判定标签后面的不为空,写入这些链接。
下面是本人测试的效果图:

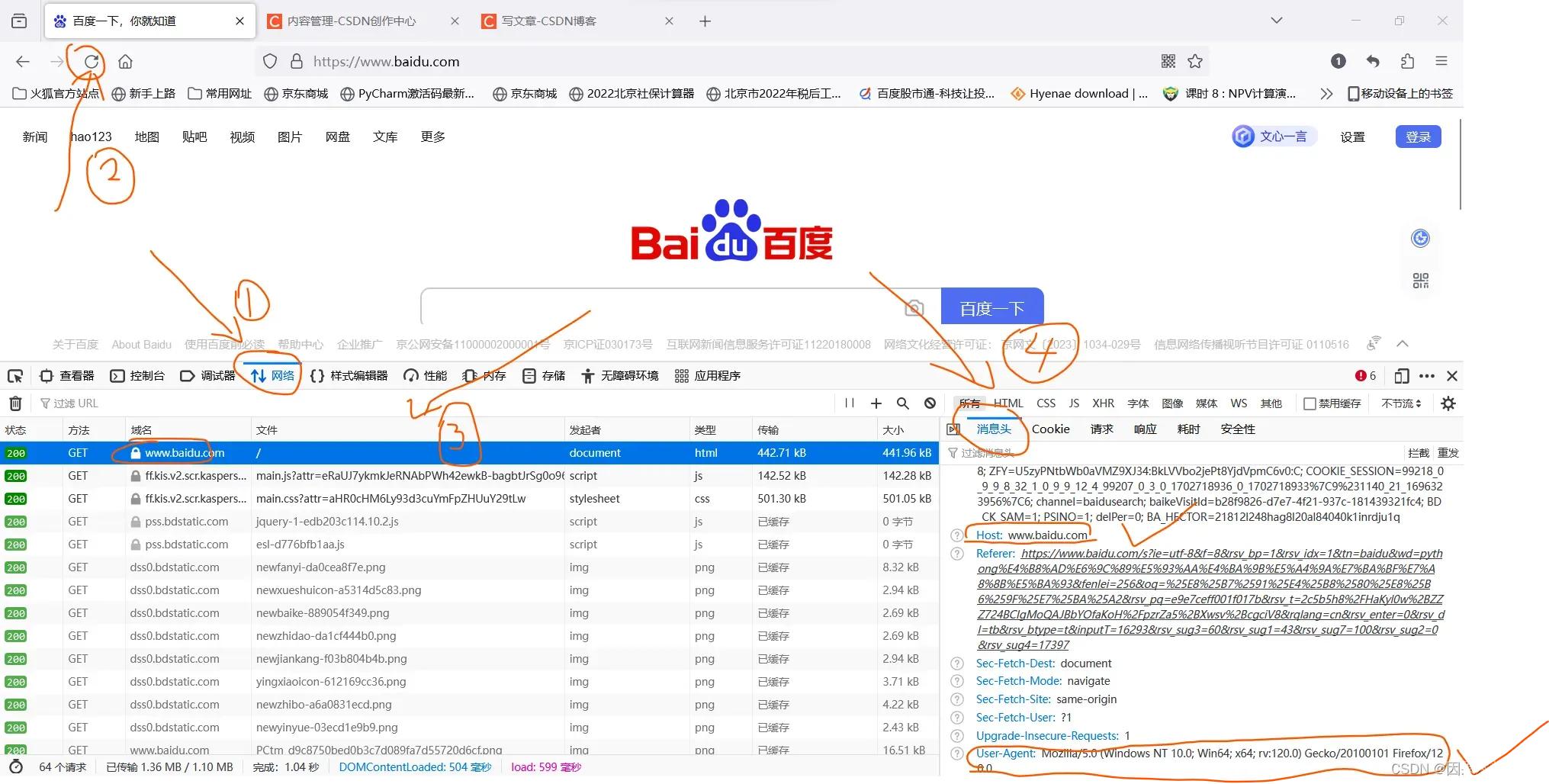
三、如何定义请求头?
很简单。首先,随便打开一个网页。然后按一下F12,接着按照下图上的步骤一步一步来,就可以得到想要的东西。
总结
这样,一个简单的爬虫小程序就搞定了。慢慢来吧,后续教大家爬一些有用的东西(# ^ . ^ #)。
文章出处登录后可见!
已经登录?立即刷新